Ein Histogramm zeigt die Verteilung einer Größe. Ist die Klasseneinteilung zu fein, so gaukelt das eine Genauigkeit vor, die einer näheren Betrachtung nicht standhält. Unser Algorithmus startet mit einer feinen Einteilung und findet dann eine Einteilung, die zur Anzahl der Beobachtungen passt. Deutliche Unterschiede in den Häufigkeiten werden berücksichtigt, eher als zufällig anzusehende Unterschiede werden nivelliert.
Das Histogramm zeigt die Verteilung von ca. 4000 Werten auf 50 Klassen. Sind die 95 Beobachtungen, die in das erste Intervall fallen, wirklich so viel größer als die 93 des zweiten Intervalls? Hätte es bei einer weiteren Stichprobe der Größe 4000 nicht genau umgekehrt aussehen können?
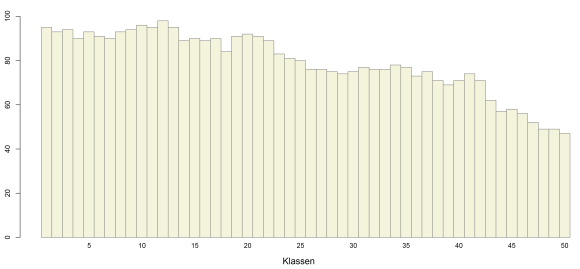
Das Originalhistogramm mit 50 Klassen
Es liegt nun in der Natur von relativen Anteilen, dass ihre Streuung mit wachsender Stichprobengröße sinkt. Es kann deshalb durchaus der Fall sein, dass die gleichmäßige Verteilung der Häufigkeiten von benachbarten Intervallen mit ähnlichen Werten eine stabilere Darstellung verspricht als das Festhalten an den ursprünglichen Werten. Wir haben dazu ein vollautomatisches Verfahren der Modellauswahl entwickelt, das ausgehend von der ursprünglichen feinen Einteilung benachbarte Intervalle optimal zusammenfasst und dabei auch die zur Stichprobengröße gehörende Variation einbezieht.
Für obenstehendes Histogramm wird die folgende optimale Aufteilung gefunden, die aus insgesamt 4 Bereichen besteht.
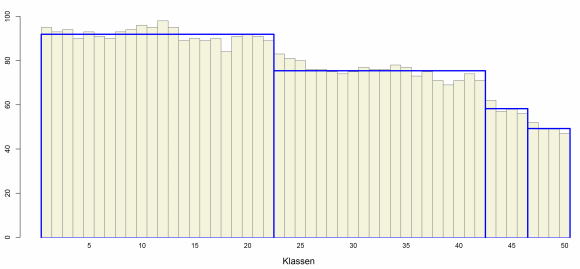
Optimale Aufteilung in 4 Bereiche
Was passiert, wenn die Stichprobe wächst? Nehmen wir einmal in folgendem Gedankenexperiment an, dass alle auftretenden Häufigkeiten exakt 10-mal so groß sind wie bisher, d.h. statt 95 haben wir nun 950 Beobachtungen im ersten Intervall und statt 93 sind es 930 im zweiten Intervall. Die relative Verteilung hat sich nicht geändert, aber die gewonnene Genauigkeit durch die größere Stichprobe lässt den Algorithmus eine feinere Einteilung in 11 Bereiche wählen:
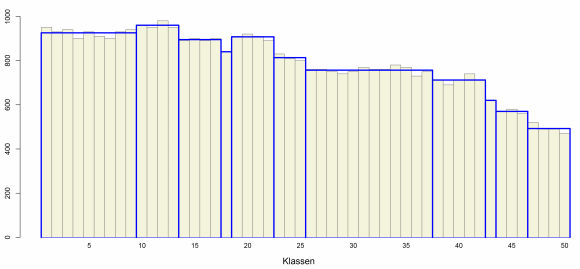
Optimale Aufteilung bei angenommener Verzehnfachung der Häufigkeiten
Bei einer weiteren Verzehnfachung der Häufigkeiten werden auch kleine sichtbare Unterschiede relevant und nun werden bereits 29 Bereiche ausgewählt und 16 von ihnen bestehen bereits aus einem einzigen Intervall. Diese optimale Aufteilung wird in etwa 1/3 Sekunde gefunden.
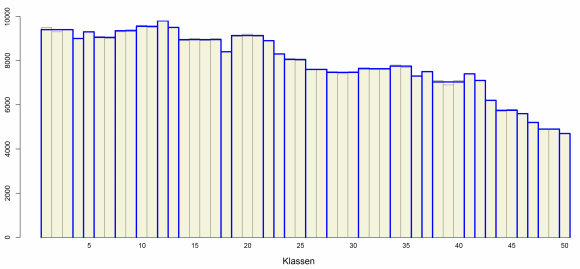
Optimale Aufteilung bei weiterer Verzehnfachung der Häufigkeiten
Bei unserem Algorithmus passt sich die Detailliertheit an die Stichprobengröße an: Zeige nur die Feinheit, die durch die Daten gedeckt ist.
