In diesem Beitrag wird gezeigt, wie ein relationales Datenmodell in einer Azure-SQL-Datenbank mit DeltaMaster angesprochen werden kann. Dafür dient der frei zugängliche Datensatz der „World Development Indicators“ (kurz WDI). Der Blog erläutert dabei auch die Modellierung mit DeltaMaster ETL und stellt drei Beispielberichte vor, die einen guten Ausgangspunkt für die Analyse der WDI in DeltaMaster bilden können.
Die kontinuierliche Weiterentwicklung von DeltaMaster umfasst insbesondere den Funktionsumfang bei der Analyse relationaler Datenquellen. Neben dem Demo-Datenmodell der Chair AG bietet sich mit frei zugänglichen Datasets die Möglichkeit, weitere Konzepte zu demonstrieren. In diesem Beitrag widmen wir uns einem solchen Beispiel.
Einführung: Neue Daten und Datenquellen
Mit der fortschreitenden Technisierung der Welt entstehen immer mehr neue Daten und Datenquellen. Damit steigt auch der Bedarf oder die Notwendigkeit, für diese Daten schnell Analysen zu erstellen und zur Verfügung zu stellen. Immer häufiger werden hierfür Cloud-Umgebungen eingesetzt, da diese Daten und Analysen weltweit verfügbar machen können.
In den letzten Jahrzehnten haben ausgereifte mehrdimensionale Datenmodelle, oft auf Basis von Millionen oder gar Milliarden Datensätzen, umfangreiche Einblicke ermöglicht. Umso schwerfälliger kann sich dann jedoch eine Erweiterung dieser Modelle gestalten. Daher ist ein Ansatz, neue Datenquellen auf relationaler Basis mit minimalem Modellierungsaufwand zu untersuchen.
Mit DeltaMaster ist es möglich, Berichte und Analysen unmittelbar nach Verbindung mit multidimensionalen Datenmodellen zu erstellen. Bei relationalen Datenquellen ist zuvor noch eine Modellierung in DeltaMaster selbst erforderlich. Hier bietet sich DeltaMaster ETL als Unterstützung an, welches nicht nur die Erstellung von OLAP-Modellen ermöglicht, sondern auch durch die Vorbereitung der relationalen Tabellen für die relationale Modellierung in DeltaMaster eine große Hilfe ist.
Um ein solches Vorgehen an einem Beispiel zu illustrieren, zeigen wir in im Folgenden das Laden der „World Development Indicators“ der Weltbank in eine Microsoft Azure-SQL-Datenbank und die anschließende Modellierung mit DeltaMaster ETL und DeltaMaster.
Die World Development Indicators als Datensatz
Die Weltbank ist eine Sonderorganisation der vereinten Nationen und verfügt über eine Sammlung von Indikatoren zur regionalen, nationalen und globalen Entwicklung aus offiziell anerkannten internationalen Quellen. Diese Sammlung liegt bildet den Datensatz der so genannten World Development Indicators (kurz WDI). Die Daten sind gemäß der Creative Commons Lizenz CC-BY 4.0 frei zugänglich und können mit einem Web-Tool der Weltbank untersucht werden. Das ZIP-Archiv enthält die folgenden Dateien:
| Datei (CSV) | Größe | Beschreibung |
| WDICountry | 0,1 MB | Eine Tabelle der Länder |
| WDICountry-Series | 1,0 MB | Eine Tabelle mit jahres- und landesspezifischen Hinweisen |
| WDIData | 196 MB | Eine Tabelle mit den verfügbaren Werten basierend auf Land und Indikator für jedes Jahr seit 1960 |
| WDIFootNote | 48 MB | Eine Tabelle mit ergänzenden Hinweisen zu Tupeln aus Land, Indikator und Jahr |
| WDISeries | 3,6 MB | Eine Tabelle der Indikatoren |
| WDISeries-Time | 0,04 MB | Eine Tabelle mit jahres- und indikatorspezfischen Hinweisen |
Tabelle 1: Dateien des WDI-ZIP-Archivs
In diesem Beitrag wird gezeigt, wie all diese Dateien in eine Azure-SQL-Datenbank importiert werden können. Im darauffolgenden Datenmodell werden alle Daten, ausgenommen derjenigen der „WDICountry-Series.csv“ und „WDISeries.csv“, verwendet.
Hinweis: Mind. seit 2018 hat sich die Struktur der Datei „WDIData.csv“ jährlich verändert. Arbeiten Sie mit Datensätzen aus vergangenen und zukünftigen Jahren, sind ggfs. Anpassungen an die hier gezeigte Lösung mit dem Datensatz aus 2020 notwendig.
Voraussetzungen
Zur Umsetzung aller Erläuterungen in diesem Beitrag werden folgende Komponenten benötigt:
- Eine Office-Software zur Bereinigung einer CSV-Datei, z. B. Microsoft Excel.
- Eine Azure-SQL-Datenbank als Ziel der importierten Tabellen. Hierfür ist ein Microsoft Azure Account notwendig, der mit einer 30-tägigen kostenfreien Variante gestartet werden kann.
- Sofern für die Azure SQL-Datenbank der Basic-Tarif und damit eingeschränkte Rechenkapaztiät verwendet wird, empfiehlt sich für die Entwicklung und das Trouble-Shooting eine lokale (kostenfreie) Installation des Microsoft SQL Servers.
- Für den Import der CSV-Dateien in die Azure SQL-Datenbank stehen unterschiedliche Wege zur Verfügung. In diesem Blogbeitrag wird vorgestellt, wie mittels der Flatfile-Import-Funktion im Microsoft SQL Server Management Studio (SSMS) gearbeitet werden kann. Diese Komponente ist auch als Erweiterung für das Azure Data Studio verfügbar.
- Eine DeltaMaster-ETL-Lizenz (Standard) zur Aufbereitung der relationalen Tabellen, die als Quelle für DeltaMaster dienen.
- Eine DeltaMaster-Lizenz vom Typ Reporting (RPT).
Ablauf
Der folgende schematische Ablauf zeigt zugleich die weitere Gliederung dieses Beitrags.

Abbildung 1: Schematischer Ablauf des Beitrags
- In Import der Rohdaten werden die Tabellen der CSV-Dateien nach der Azure-SQL-Datenbank importiert.
- In Definition der Logik werden Sichten auf diese Quellen definiert und teilweise materialisiert.
- In Materialisierung der Tabellen werden mit Hilfe von DeltaMaster ETL die Tabellen, die als Quelle für DeltaMaster dienen, definiert und befüllt.
- In Relationale Modellierung und Analyse wird das relationale Datenmodell in DeltaMaster definiert. Drei Beispielberichte visualisieren Teile der WDI-Daten, wobei für diese Berichte das Modell jeweils erweitert wird.
Die einzelnen Schritte decken sich grob mit den Titeln der folgenden Abschnitte. Abschließend fassen wir das Ergebnis zusammen, erläutern Limitationen und geben einen Ausblick.
Import der Rohdaten
Grundsätzlich ist in diesem Kapitel vorgesehen, die Rohdaten unverändert in die Azure-SQL-Datenbank zu transportieren. Für das vorgestellte Verfahren ist es eingangs notwendig, eine der Quelldateien vorzubereiten. Bei alternativen Verfahren ist dieser Schritt nicht nötig und es kann mit dem Abschnitt Konfigurieren der Azure SQL DB fortgefahren werden.
Vorbereiten der Rohdaten
Für den erfolgreichen Flatfile-Import via SSMS oder der passenden Extension für Azure Data Studio ist es zuvor notwendig, die Datei „WDIData.csv“ aufgrund inkompatibler Formatierungen anzupassen. Dies wird hier mit Hilfe von Microsoft Excel dargestellt. Von weiteren nicht notwendigen Transformationen vor dem Import wird an dieser Stelle abgesehen.
Öffnen Sie Excel und wechseln Sie in der Multifunktionsleiste auf „Daten“. Hier wählen Sie „Aus Text/CSV“ und dann die Datei „WDIData.csv“.
Abbildung 2: Funktion für den Import von CSV-Dateien in Excel
Nach Bestätigung zeigt sich der in Abbildung 3 dargestellte Dialog.
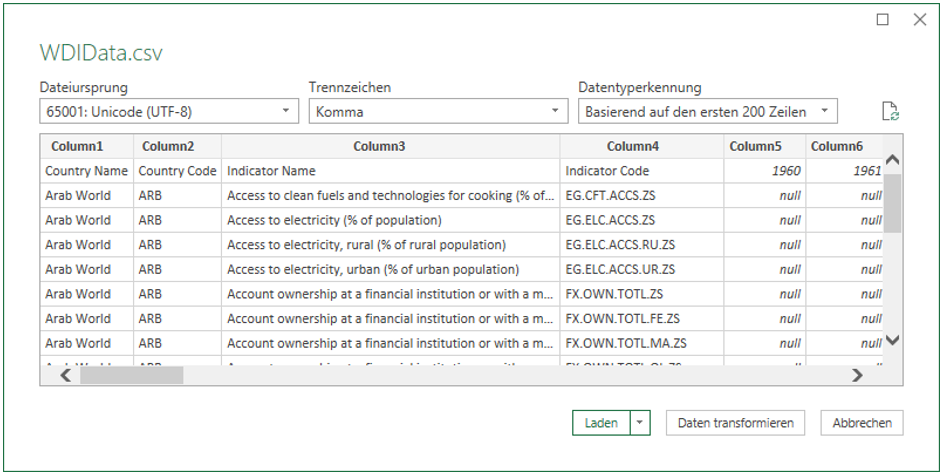
Abbildung 3: Initialer Dialog nach dem Import der Datei „WDIData.csv“
Dabei zeigt sich bereits das erste Problem: die erste Zeile wird nicht als Bezeichner für Spaltenköpfe erkannt, da die Jahre als Ganzzahlen interpretiert werden. Klicken Sie auf „Daten transformieren“, damit Sie sich u. a. diesem Verhalten widmen können. Scrollen Sie zudem ganz nach rechts, um zu sehen, dass auch eine unbenannte Spalte (Column 66) existiert, die optional gelöscht werden kann.
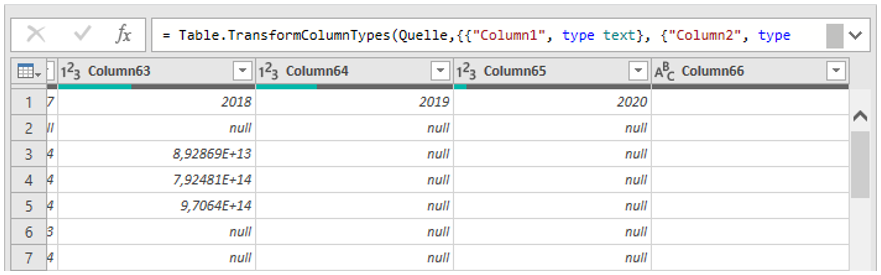
Abbildung 4: Die Spaltenbezeichner konnten nicht ermittelt werden und bilden so die erste Datenzeile
Zudem zeigt sich, dass Werte in der wissenschaftlichen Notation angezeigt und der Datentyp auf „int“ gesetzt wurde.
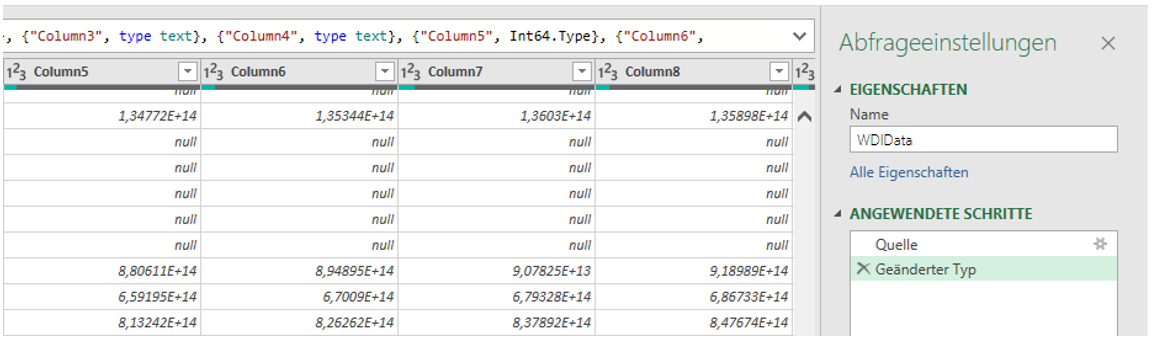
Abbildung 5: Automatische Änderungen von Datentypen können ggfs. hinderlich sein
Es gilt somit Folgendes zu tun:
- Die erste Zeile muss entfernt werden.
- Die Transformation „Geänderter Typ“ muss zurückgenommen werden.
- In den Spalten „Column 5“ bis „Column 65“ muss „.“ durch „,“ ersetzt werden.
- Optional kann die letzte Spalte entfernt werden.
Nach Durchführung dieser Transformationen (inkl. der Optionalen) sollten die letzten Spalten der ersten Zeilen dann wie in Abbildung 6 aussehen.
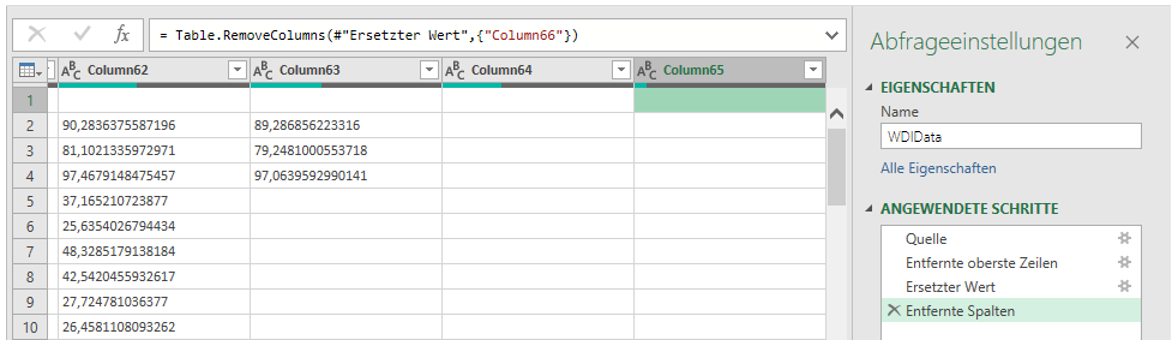
Abbildung 6: Bereinigte Tabelle
Wählen Sie nun „Schließen und Laden“. Das Laden der rund 380.000 Zeilen dauert einen Moment. Abschließend können Sie die Datei im CSV-Format speichern und für den Import im wie im Abschnitt Laden der Rohdaten nach der Azure-SQL-Datenbank verwenden.
Empfehlung: Speichern Sie die CSV-Datei als eine neue Datei ab und behalten Sie zudem die Excel-Datei, um die Unterschiede zum Original jederzeit feststellen zu können.
Konfigurieren der Azure-SQL-Datenbank
Erstellen Sie in Ihrem Azure-Account eine neue Ressource vom Typ SQL-Datenbank, in diesem Blog konfiguriert mit den folgenden Einstellungen:
- Datenbankname: „wdi2020“
- Server: (neu) deltamaster (Europa, Westen)
- Elastische SQL-Datenbanken: Nein
- Compute + Speicher: Basic (2 GB-Speicher)
Der gesamte Datenumfang (Roh-, Meta- und Modell-Daten) umfasst rund 1,6 GB, wodurch der maximale Datenbankdatenspeicher des Basic-Tarifs ausreichend ist.
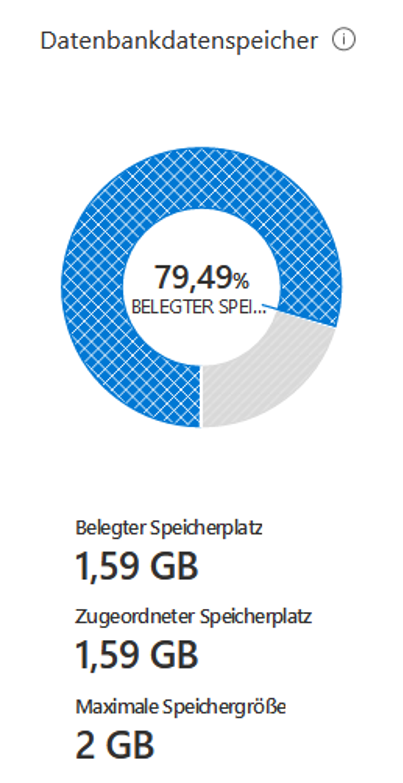
Abbildung 7: Genutzter Datenbankdatenspeicher des gesamten Modells
Hinweis: Der Basic-Tarif inkludiert nur stark eingeschränkte Rechenkapazitäten, wodurch die Dauer des Imports und späterer komplexer Abfragen sehr hoch ist (die Zeiten werden an den entsprechenden Stellen genannt). Verwenden Sie ggf. einen höherpreisigen Tarif für mehr Leistung.
Sobald die Ressource verfügbar ist, wechseln Sie zu den Firewall-Einstellungen und fügen Ihre Client-IP-Adresse als Ausnahme hinzu, um mit Tools wie SSMS auf Azure zugreifen zu können. Aktivieren Sie „Anderen Azure-Diensten und -Ressourcen den Zugriff auf diesen Server gestatten“, falls Sie Diensten wie Azure Data Factory Zugriff auf die Datenbank gewähren wollen. Dies ist im Rahmen dieses Beitrags jedoch nicht erforderlich.
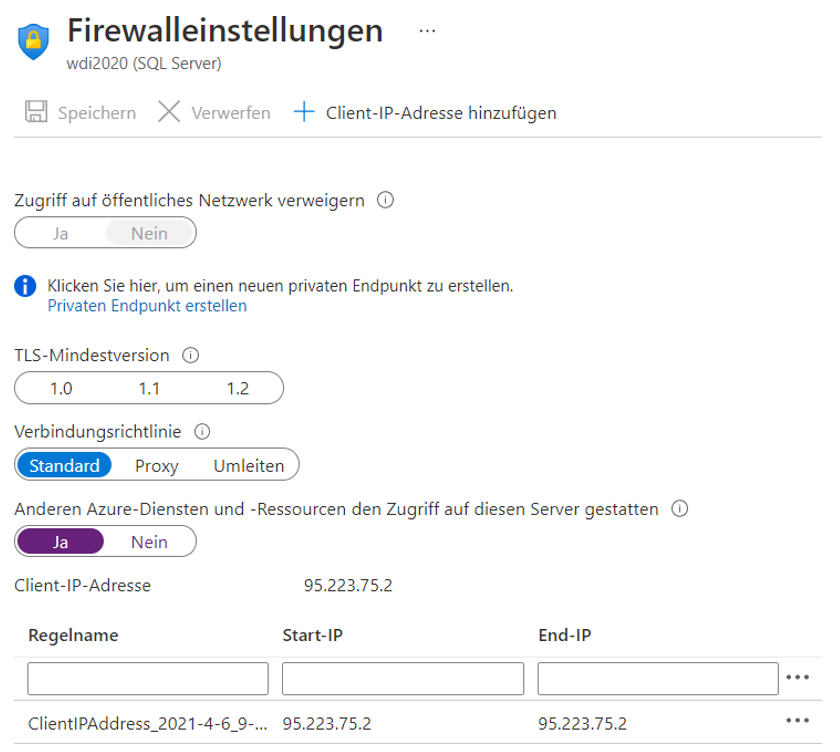
Abbildung 8: Firewall-Einstellungen des Azure-SQL-Datenbankservers
Hinweis: Sie können in der schlussendlichen DeltaMaster-Analysesitzung die SQL-Server-Authentifizierung verwenden, um Benutzer und Passwort fest in der Sitzung zu hinterlegen. In dieser Form braucht es keine weiteren Konfigurationen an der Azure-SQL-Datenbank und jeder Nutzer, der über die DeltaMaster-Anwendung verfügt, kann auf die Datenbank zugreifen.
Mit Verweis auf die Enterprise Architecture (die in vollem Umfang Daten und Zugriffe auf mehrere Datenbanken verteilt) werden in diesem Blog mehrere Schemata in einer Datenbank verwendet, die zudem grob an eine geläufige Terminologie im Transport und Bereinigung von Daten erinnert:
[staging]für die importierten Tabellen (Bronze-Tabellen),[entry]für manuell erfasste Daten,[logic]für die definierten Sichten (in etwa Silber-Tabellen),[dbo]für das Metadaten-Modell (Standard in DeltaMaster ETL) und[datamart]für das Datenmodell (Gold-Tabellen).
Wechseln Sie nun entweder zum „Abfrage-Editor (Vorschau)“ oder zu einem anderen Tool Ihrer Wahl und erstellen Sie Schemata, sofern Sie der Verwendung in diesem Block folgen:
CREATE SCHEMA [datamart] AUTHORIZATION [dbo] GO;
CREATE SCHEMA [entry] AUTHORIZATION [dbo] GO;
CREATE SCHEMA [logic] AUTHORIZATION [dbo] GO;
CREATE SCHEMA [staging] AUTHORIZATION [dbo] GO;
Laden der Rohdaten in die Azure-SQL-Datenbank
Im folgenden Abschnitt wird gezeigt, wie Sie mit Hilfe des Flatfile-Imports im SSMS die CSV-Dateien in die Azure-SQL-Datenbank kopieren. Unter Umständen weichen Konfigurationen bei der Verwendung anderer Tools ab.
Verbinden Sie sich mit Ihrer Datenbank und wählen Sie unter den „Tasks“ die Aufgabe „Flatfile importieren“ aus.
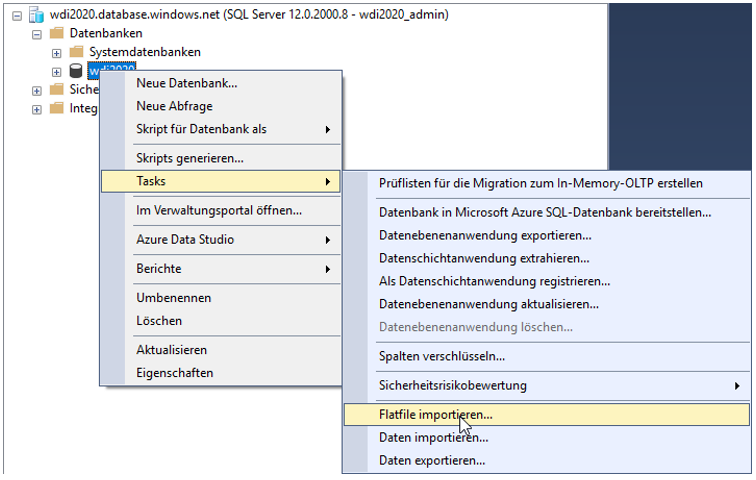
Abbildung 9: Funktion zum Importieren der CSV-Dateien nach der Datenbank
Wählen Sie auf dem ersten Bildschirm die Datei (z. B. „Countries.csv“) und als Schema [staging] aus. Den Namen können Sie wie vorgeschlagen belassen. Im darauffolgenden Fenster können Sie die Option zur Erkennung der Datentypen anhaken.
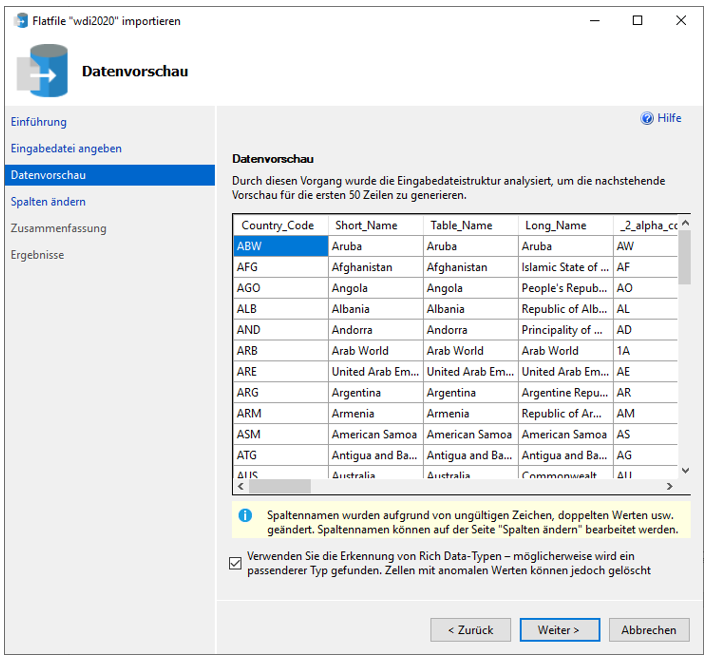
Abbildung 10: Dialog mit „Datenvorschau“ zur automatischen Erkennung von Datentypen
Nach weiteren Bestätigungen wird die Tabelle in wenigen Sekunden angelegt und kann im SSMS untersucht werden.
![Spalten der Tabelle „[staging].[WDICountry]“](https://www.bissantz.de/images/2021/05/2021-04-30-Data-Warehousing-Analyse-relationaler-Datenmodelle-aus-Azure-SQL-Datenbanken-11.png)
Abbildung 11: Spalten der Tabelle „[staging].[WDICountry]“
- Generell: Die Länge des
nvarchar-Typs ist ein Vielfaches von 50 - Ausnahme:
[PPP_survey_year], welches nurNULL-Werte hat und wahrscheinlich deshalb automatisch mit der Zeichenlänge 1 versehen wurde - Zudem noch
[column31], die ebenfalls nur mit ebenso nurNULL-Werte enthält
Ein Datei-Import nach Excel zeigt, dass tatsächlich noch eine unbenannte, leere Spalte vorliegt, die folglich auch beim Import nach der Azure-Datenbank berücksichtigt wird.
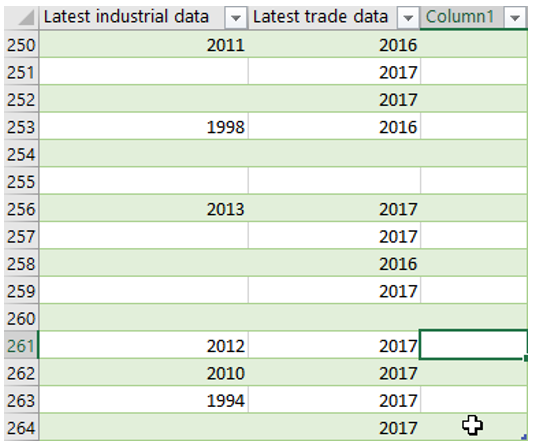
Abbildung 12: Ausschnitt der CSV-Datei mit leerer Spalte zum Ende der Tabelle
Dies kann im Sinne einer Bronze-Tabelle so belassen oder gemäß dem Abschnitt zum Vorbereiten der Rohdaten bereits im Vorfeld behoben werden.
Beim Import der Datei „Countries-Series.csv“ zeigt sich, dass die automatisch ermittelte Feldlänge des [DESCRIPTION]-Felds zu kurz ist. Für ein erfolgreiches Importieren kann es auf nvarchar(MAX) umgestellt werden.
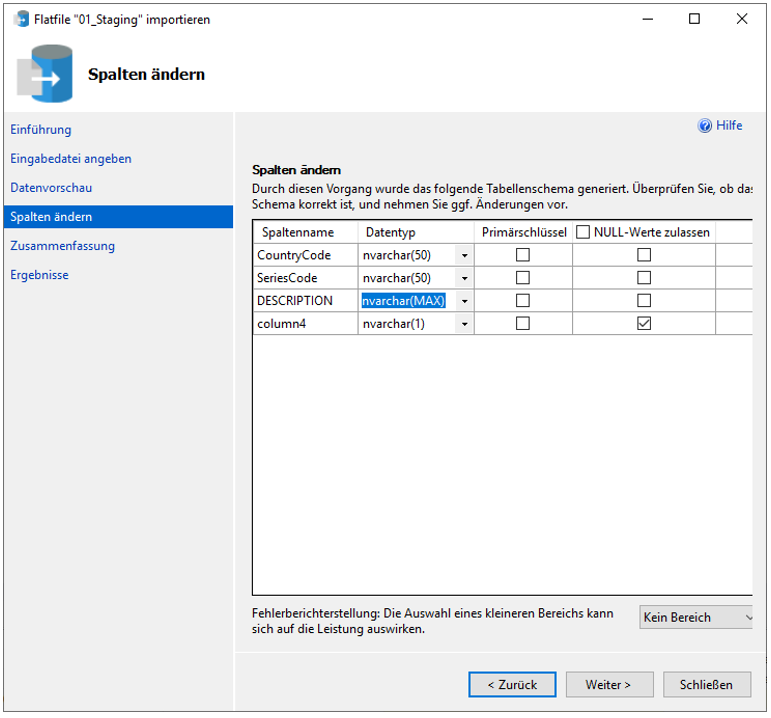
Abbildung 13: Verwendung von „nvarchar(MAX)“ für den initialen Import
Um Probleme bei Verkettungen von Spalten mit maximaler Feldlänge zu vermeiden, sollte nach dem erfolgreichen Import die Feldlänge reduziert werden, beispielsweise auf die maximal ermittelte Länge über alle Werte dieser Spalte. Eine mögliche Abfrage zur Ermittlung der Spaltenlänge lautet:
SELECT MAX(LEN([DESCRIPTION])) AS Spaltenlänge
FROM [staging].[WDICountry-Series]
Beim Import der Datei „WDIData.csv“ ist darauf zu achten, dass die Spalten mit numerischen Werten als nvarchar(21) importiert werden, da bei dem automatisch ermittelteten float das Komma ignoriert wird. Unter Berücksichtigung der maximalen Spaltenlängen bietet es sich somit an, alle Spalten mit dem Typ nvarchar und den folgenden Längen zu importieren:
[Country Name]: 52[Country Code]: 3[Indicator Name]: 140[Indicator Code]: 25[1960]bis[2020]: 20- Falls leere Spalte vorhanden: 1
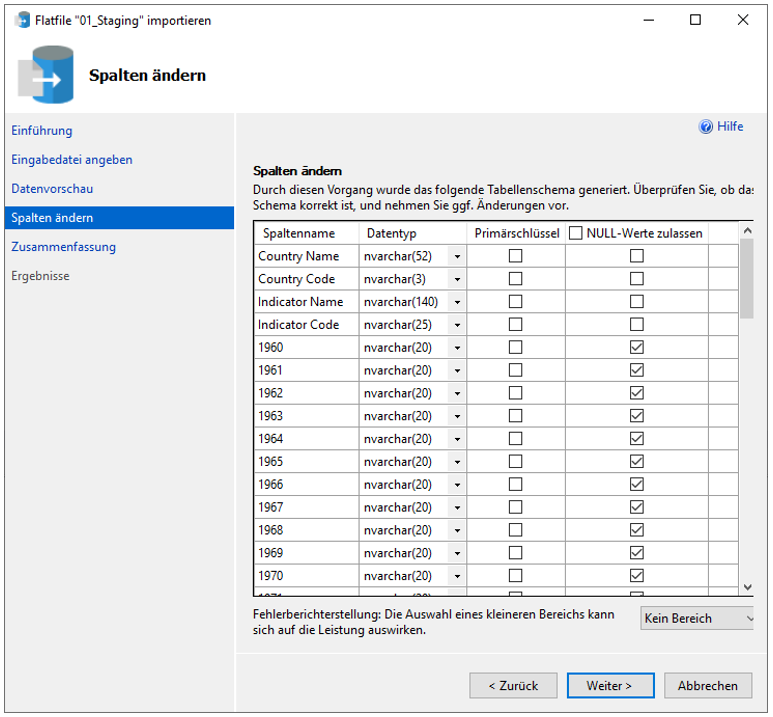
Abbildung 14: Vor Allem bei den Jahresspalten ist der initiale Import als „nvarchar“ hilfreich
Da die Datei „WDIData.csv“ rund 190 MB groß ist, kann der Upload etwas Zeit beanspruchen.
Mit dem Import der Rohdaten wird Bronze-Qualität erreicht.
Definition der Logik
Die wesentliche Transformationslogik wird in Sichten festgehalten. Im Folgenden werden zuerst die Logiken für die Dimensionen und anschließend für die MeasureGroups beschrieben. Die Objekte werden vorrangig im Schema [logic] erstellt; lediglich Tabellen, die manuell erfasste Daten enthalten, verwenden das [entry]-Schema.
Da der Datensatz grundsätzlich vollständig ist (mit Ausnahme der im letzten Teil dieses Beitrags genannten Limitationen), bietet es sich an, Spaltengrößen auf maximal ermittelte Feldlängen zu reduzieren, um auch den belegten Speicher so gering wie möglich zu halten.
Sichten der Dimensionen
Ausgangspunkt für die Dimension der Länder ist die Tabelle „[staging].[WDICountry]“. Zu beachten ist dabei, dass sich darin auch „Aggregate“ (Bezeichnung laut Weltbank) befinden, die Zusammenfassungen mehrerer Länder sind. Beispielsweise besteht die „Arab World“ aus 22 Ländern (vgl. Worldbank Website). Dieser Beitrag konzentriert sich auf die Verwendung der Werte zu den Ländern und lässt die Werte der Aggregate außen vor, zumal das m:n-Verhältnis zwischen Land und Aggregat Stoff für einen separaten Beitrag über Modellierung liefert.
Die Aggregate können durch die Filterung in der WHERE-Klausel ausgeschlossen werden, da sie über keine Werte in der Spalte [Income_Group] verfügen. Die Länder können in Regionen zusammengefasst werden, die damit eine Ebene über den Ländern darstellen. Auf weitere Attribute und Hierarchien wird verzichtet.
CREATE VIEW [logic].[V_IMPORT_DIM_Country] AS
SELECT
-- Primary hierarchy
RegionID = CONVERT(varchar(26),[Region]),
CountryID = CONVERT(varchar(3),[Country_Code]),
CountryNAME = CONVERT(varchar(30),[Short_Name])
FROM [staging].[WDICountry]
WHERE [Income_Group] IS NOT NULL
| RegionID | CountryID | CountryNAME | |
| 1 | Latin America & Caribbean | ABW | Aruba |
| 2 | South Asia | AFG | Afghanistan |
| 3 | Sub-Saharan Africa | AGO | Angola |
| 4 | Europe & Central Asia | ALB | Albania |
| 5 | Europe & Central Asia | AND | Andorra |
| 6 | Middle East & North Africa | ARE | United Arab Emirates |
| 7 | Latin America & Caribbean | ARG | Argentina |
| 8 | Europe & Central Asia | ARM | Armenia |
| 9 | East Asia & Pacific | ASM | American Samoa |
| 10 | Latin America & Caribbean | ATG | Antigua and Barbuda |
Tabelle 2: Ausschnitt der Inhalte der Sicht „[logic].[V_IMPORT_DIM_Country]“
Einige der Indikatoren sind „positiv“ besetzt, d. h. ein höherer Wert beschreibt einen guten Umstand (z. B. Index der menschlichen Entwicklung). Andere wiederum haben eine i. d. R. negative Bedeutung (z.B. Rate der Arbeitslosigkeit). Dieser „BI-Factor“ wird in DeltaMaster zur Unterscheidung zwischen positiven (blauen) und negativen (roten) Werten verwendet, wobei die Kennzahl gemäß dem BI-Factor des Indikators gefärbt wird. Der in diesem Beitrag aufgeführte Beispielbericht #3 verwendet diese Information.
Die Unterscheidung in „positiv“ und „negativ“ liegt nicht in den Rohdaten vor und muss für einfacheres Analysieren separat erfasst werden. Zu diesem Zweck wird eine „T_S“-Tabelle im Schema [entry] mit zwei Spalten („[IndicatorID]“ und „[BIFactor]“) angelegt. In diese Tabelle werden Indikatoren und ihre entweder positive oder negative Bedeutung eingetragen. Dabei reicht es im Rahmen dieses Beitrags aus, nur die negativ besetzten Indikatoren anzugeben, da keine weiteren Attribute gepflegt werden und der Default in der Sicht positiv ist.
Mit der folgenden Abfrage wird die Tabelle erstellt.
CREATE TABLE [entry].[T_S_Indicator](
[IndicatorID] [varchar](25) NOT NULL,
[BIFactor] [smallint] NULL,
CONSTRAINT [PK_T_S_Indicator] PRIMARY KEY CLUSTERED ([IndicatorID] ASC)
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
Für den in diesem Beitrag aufgeführten Beispielbericht #2 wird die Tabelle außerdem mit den folgenden Werten befüllt:
| IndicatorID | BIFactor |
| SL.UEM.1524.NE.ZS | -1 |
| SL.UEM.BASC.ZS | -1 |
| SL.UEM.INTM.ZS | -1 |
| SL.UEM.ADVN.ZS | -1 |
| SL.UEM.TOTL.ZS | -1 |
Tabelle 3: Zeilen der Tabelle „[entry].[T_S_Indicator]“
In der Sicht wird nun auch auf diese Tabelle verwiesen. Zudem wird eine Hierarchie der Indikatoren über zwei künstliche Ebenen (Domain und Topic) mit Hilfe von Transformationen wie LEFT und CONCAT erreicht.
CREATE VIEW [logic].[V_IMPORT_DIM_Indicator] AS
SELECT
-- Primary hierarchy
[IndicatorDomainID] = CONVERT(varchar(42), IIF(CHARINDEX(':',[Topic]) = 0,
[Topic],
LEFT([Topic],CHARINDEX(':',[Topic])-1))
),
[IndicatorTopicID] = CONVERT(varchar(86), IIF(CHARINDEX(':',[Topic]) = 0,
CONCAT([Topic], ': ',[Topic]),
RIGHT([Topic],LEN(Topic)-CHARINDEX(':',[Topic])-1))
),
[IndicatorID] = CONVERT(varchar(25),[Series_Code]),
[IndicatorNAME] = CONVERT(varchar(140),[Indicator_Name]),
-- Attributes
[IndicatorBIFactor] = ISNULL([T_S_Indicator].[BIFactor],1)
FROM [staging].[WDISeries] AS [ind]
LEFT JOIN [entry].[T_S_Indicator]
ON [ind].[Series_Code] = [T_S_Indicator].[IndicatorID]
Im Ausschnitt der Abfrage dieser Sicht zeigt sich, dass der Standard der Spalte [IndicatorBIFactor] 1 ist.
| DomainID | TopicID | ID | NAME | BI Factor |
|
| 1 | Environment | Agricultural production | AG.LND.CREL.HA | Land under cereal production (hectares) |
1 |
| 2 | Economic Policy & Debt |
Balance of payments: Current account: Goods, services & income | BM.GSR.MRCH.CD | Goods imports (BoP, current US$) |
1 |
| 3 | Economic Policy & Debt |
Balance of payments: Current account: Goods, services & income | BM.GSR.NFSV.CD | Service imports (BoP, current US$) |
1 |
| 4 | Environment | Land use | AG.LND.CROP.ZS | Permanent cropland (% of land area) |
1 |
| 5 | Environment | Land use | AG.LND.EL5M.RU.K2 | Rural land area where elevation is below 5 meters (sq. km) |
1 |
| 6 | Environment | Land use | AG.LND.EL5M.RU.ZS | Rural land area where elevation is below 5 meters (% of total land area) |
1 |
| 7 | Environment | Land use | AG.LND.EL5M.UR.K2 | Urban land area where elevation is below 5 meters (sq. km) |
1 |
| 8 | Environment | Land use | AG.LND.EL5M.UR.ZS | Urban land area where elevation is below 5 meters (% of total land area) |
1 |
| 9 | Environment | Land use | AG.LND.EL5M.ZS | Land area where elevation is below 5 meters (% of total land area) |
1 |
| 10 | Environment | Land use | AG.LND.FRST.K2 | Forest area (sq. km) |
1 |
Tabelle 4: Ausschnitt der Inhalte der Sicht „[logic].[V_IMPORT_DIM_Indicator]“
Schlussendlich muss noch die Zeit vorbereitet werden. Da alle Indikatoren auf Jahresebene vorliegen und die ersten Messungen bis 1960 zurückgehen, ist wieder eine „T_S“-Tabelle im Schema [entry] anzulegen.
CREATE TABLE [entry].[T_S_Year](
[YearID] [smallint] NOT NULL,
CONSTRAINT [PK_T_S_Year] PRIMARY KEY CLUSTERED ([YearID] ASC)
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
Anschließend ist diese mit den Werten zwischen 1960 und 2020 zu füllen.
Hinweis: DeltaMaster ETL erstellt während der Erzeugung des Meta-Modells die Tabelle „[dbo].[Periode]“, in die die Tage des Zeitraums eingefügt werden. Basierend darauf ließe sich eine simple Abfrage erstellen.
In der Sicht auf die Tabelle wird zudem noch das Jahrzehnt als darüberliegende Ebene bestimmt. Da die Tabelle nicht auf importierten Daten beruht, wird nicht die Namenskonvention V_IMPORT, sondern V_S verwendet.
CREATE VIEW [logic].[V_S_DIM_Year] AS
SELECT DISTINCT
-- Primary hierarchy
DecadeID = LEFT(YearID,3) + '0s',
YearID = YearID
FROM [entry].[T_S_Year]
Zuletzt der Ausschnitt aus der Sicht.
| DecadeID | YearID | |
| 1 | 1960s | 1960 |
| 2 | 1960s | 1961 |
| 3 | 1960s | 1962 |
| 4 | 1960s | 1963 |
| 5 | 1960s | 1964 |
| 6 | 1960s | 1965 |
| 7 | 1960s | 1966 |
| 8 | 1960s | 1967 |
| 9 | 1960s | 1968 |
| 10 | 1960s | 1969 |
Tabelle 5: Ausschnitt der Inhalte der Sicht „[logic].[V_S_DIM_Year]“
Damit sind die Logiken der Dimensionen festgehalten.
Sicht der MeasureGroup
Wie bereits im Abschnitt zum Laden Rohdaten in die Azure-SQL-Datenbank festgestellt, liegen die Werte der Tabelle „[staging].[WDIData]“ pivotisiert vor. Das bedeutet, dass für jedes Jahr eine Spalte besteht, wobei die Werte pro Zeile für diese Jahresspalten nicht gefüllt sein müssen. Da diese pivotisierte Form Schwierigkeiten bei der Modellierung erzeugt, empfiehlt es sich, mit Hilfe des Befehls UNPIVOT diesen Umstand zu beseitigen.
Bei der Arbeit mit der Tabelle zeigt sich, dass ein paar wenige Zeilen nicht korrekt importiert werden können. Um weiteren Aufwand zu umgehen, werden diese in der Unterabfrage der Sicht aus dem Ergebnis genommen. Zudem reduziert sich der Umfang in diesem Beitrag auf die Messungen der Länder, womit auch Zeilen für die Aggregate ausgeschlossen werden.
TRY_CONVERT() liefert bei unmöglichen Konvertierungen NULL zurück. Während in der finalen Definition alle Zeilen Werte aufweisen, kann dies während der eigenständigen Entwicklung der Sicht hilfreich sein.
Zur Vollständigkeit wird auch die Tabelle „[staging].[WDIFootNote]“ angebunden.
CREATE VIEW [logic].[V_IMPORT_FACT_Measurements] AS
SELECT
-- Dimensions
[YearID] = CONVERT(smallint,[YearID]),
[CountryID] = CONVERT(varchar(3),[data].[CountryID]),
[IndicatorID] = CONVERT(varchar(25),[data].[IndicatorID]),
-- Measures
[Value] = TRY_CONVERT(float,REPLACE([data].[Value],',','.')),
-- Infos
[FootNote] = CONVERT(varchar(1245),[FootNote].[DESCRIPTION])
FROM (
SELECT
[CountryID] = [u].[Country Code],
[IndicatorID] = [u].[Indicator Code],
[YearID] = [u].[YearID],
[Value] = [u].[Value]
FROM [staging].[WDIData] AS t
UNPIVOT (
[Value] FOR YearID IN (
[1960],[1961],[1962],[1963],[1964],[1965],[1966],[1967],[1968],[1969],
[1970],[1971],[1972],[1973],[1974],[1975],[1976],[1977],[1978],[1979],
[1980],[1981],[1982],[1983],[1984],[1985],[1986],[1987],[1988],[1989],
[1990],[1991],[1992],[1993],[1994],[1995],[1996],[1997],[1998],[1999],
[2000],[2001],[2002],[2003],[2004],[2005],[2006],[2007],[2008],[2009],
[2010],[2011],[2012],[2013],[2014],[2015],[2016],[2017],[2018],[2019],
[2020])
) AS [u]
WHERE [u].[Country Code] IN (
SELECT [Country_Code]
FROM [staging].[WDICountry]
WHERE [Income_Group] IS NOT NULL
)
AND [u].[Value] NOT IN ('EN.CLC.DRSK.XQ')
AND [u].[Indicator Code] <> '5=best)"'
) AS [data]
LEFT JOIN [staging].[WDIFootNote] AS [FootNote]
ON [data].[CountryID] = [FootNote].[CountryCode]
AND [data].[IndicatorID] = [FootNote].[SeriesCode]
AND [data].[YearID] = RIGHT([FootNote].[Year],4)
WHERE [data].[Value] IS NOT NULL
Ein Auszug der aufbereiteten Daten der Sicht zeigt, dass die Konvertierung nach float Werte gegebenenfalls mit Nachkommastellen anzeigt. Auch legen die FootNotes die Grenzen möglicher Werte fest.
| YearID | CountryID | IndicatorID | Value | FootNote | |
| 1 | 2020 | AGO | HD.HCI.OVRL.UB.FE | 0,377216368913651 | NULL |
| 2 | 2014 | AGO | SE.ADT.1524.LT.FE.ZS | 70,5851287841797 | NULL |
| 3 | 2003 | AGO | SH.HIV.ARTC.ZS | 0 | Plausible bound is 0 – 0 |
| 4 | 2004 | AGO | SH.HIV.ARTC.ZS | 0 | Plausible bound is 0 – 0 |
| 5 | 2008 | AGO | SH.HIV.ARTC.ZS | 6 | Plausible bound is 6 – 8 |
| 6 | 2010 | AGO | SH.HIV.ARTC.ZS | 10 | Plausible bound is 9 – 12 |
| 7 | 2017 | AGO | SH.HIV.ARTC.ZS | 25 | Plausible bound is 21 – 29 |
| 8 | 2018 | AGO | SH.HIV.ARTC.ZS | 27 | Plausible bound is 23 – 32 |
| 9 | 2001 | AGO | SH.HIV.PMTC.ZS | 0 | Plausible bound is 0 – 0 |
| 10 | 2002 | AGO | SH.HIV.PMTC.ZS | 0 | Plausible bound is 0 – 0 |
Tabelle 6: Ausschnitt der Inhalte der Sicht „[logic].[V_IMPORT_FACT_Measurements]“
Da die Abfrage von UNPIVOT langsam ist, bietet es sich an, diese Sicht zu materialisieren. Dabei wird die Zieltabelle im [logic]-Schema erstellt. Das Erstellen der materialisierten Sicht dauert jedoch sehr lange, da rund 6 Millionen Zeilen erzeugt werden.
SELECT *
INTO [logic].[TMV_IMPORT_FACT_Measurements]
FROM [logic].[V_IMPORT_FACT_Measurements]
Hinweis: Sollte die Materialisierung aufgrund fehlender Rechenkapazitäten der Azure-SQL-Datenbank fehlschlagen und entwickeln Sie parallel auf einer lokalen Umgebung, können Sie auch die lokal materialisierte Tabelle nach der Azure-SQL-Datenbank importieren. Folgen Sie dazu dem Dialog, den Sie über den Task „Daten importieren“ der Datenbank erreichen. In einem Test hat das Kopieren etwa 2,5 Stunden gedauert, wobei die „Compute utilization“ in diesem Zeitraum im Schnitt bei 25 Prozent lag.
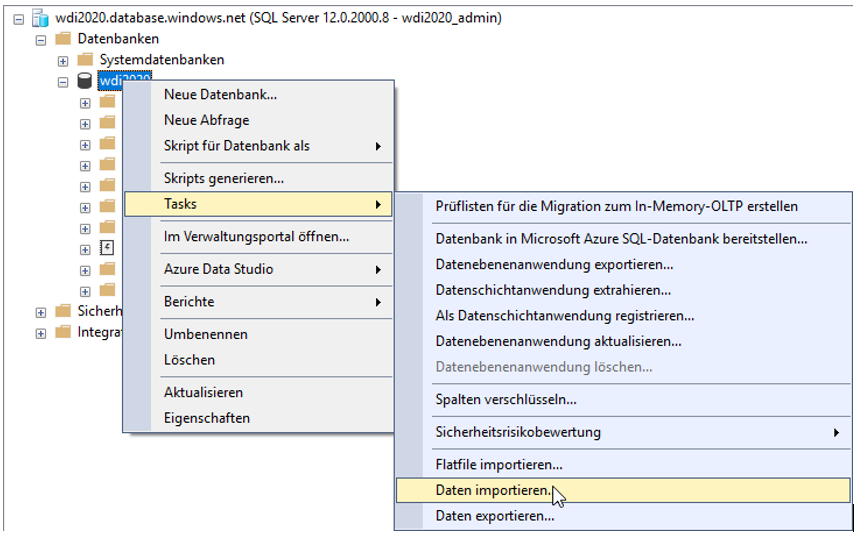
Abbildung 15: Möglichkeit zum Import von Tabellen nach Azure, auch von lokalen Systemen
Übersicht über bestehende Objekte
Schlussendlich sollten nun die folgenden Tabellen existieren:
[entry].[T_S_Indicator][entry].[T_S_Year][logic].[TMV_IMPORT_FACT_Measurements][staging].[WDICountry][staging].[WDICountry-Series][staging].[WDIData][staging].[WDIFootNote][staging].[WDISeries][staging].[WDISeries-Time]
Wie auch diese Sichten:
[logic].[V_IMPORT_DIM_Country][logic].[V_IMPORT_DIM_Indicator][logic].[V_IMPORT_FACT_Measurements][logic].[V_S_DIM_Year]
Mit der Definition der Logiken, die viele notwendige Transformationen enthalten, wird eine vergleichbare Silber-Qualität erreicht. Damit kann der zweite Teil der Aufbereitung der relationalen Tabellen mit DeltaMaster ETL fortgeführt werden.
Materialisierung in Tabellen
Mit DeltaMaster ETL können aus Tabellen und Sichten neue Tabellen erstellt werden, die Schlüssel verwenden und so für Konsistenz sorgen. Sie dienen auch auch als Hilfe für weitere Tools wie DeltaMaster, die diese Schlüssel für die relationale Modellierung auslesen.
In den folgenden Abschnitten wird zunächst gezeigt, wie das Metadaten-Modell erstellt wird, mit dessen Hilfe das Datenmodell definiert werden kann. Anschließend geht es um die Modellierung und die Generierung der oben beschriebenen Tabellen, um den Gold-Standard zu erreichen.
Erstellen des Meta-Modells mit „ETL.exe“
Öffnen Sie „DeltaMaster ETL.exe“ und doppelklicken Sie auf den Wert in der Zeile „Server“. Daraufhin öffnet sich der Dialog „Connect to Database“, in dem Sie in der Zeile „Server“ den Datenbanknamen eingeben. Im Bereich „Authentification“ wählen Sie „SQL Server Authentification“ und geben Login und Password ein. Zu guter Letzt wählen Sie die WDI-Datenbank aus und bestätigen die Eingabe.
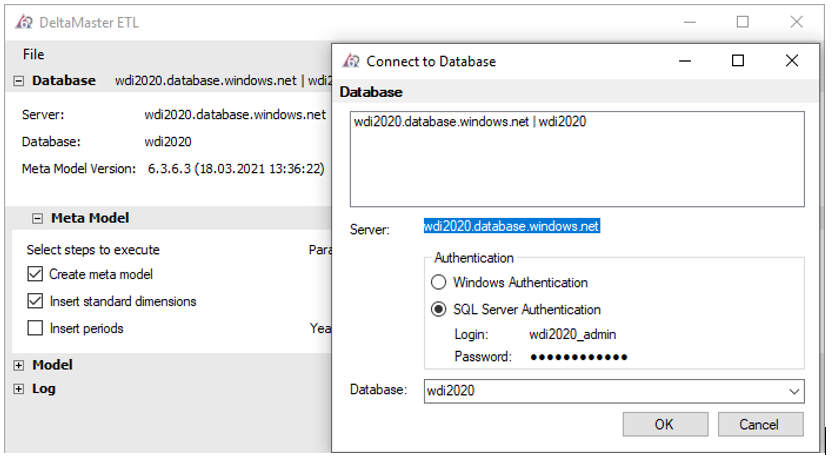
Abbildung 16: Ausgefüllter Verbindungsdialog der „ETL.exe“
Klicken Sie im Hauptbereich oben rechts auf „Show meta model“, um den Bereich „Meta Model“ anzuzeigen. Wählen Sie hier die ersten beiden Optionen an und klicken Sie auf der Höhe des Schriftzugs von „Meta Model“ auf „Execute“, um das Meta-Modell in der Datenbank zu erstellen.
Hinweis: Üblicherweise wählen Sie auch die dritte Option, um die Tage der angegebenen Jahre hinzuzufügen. Dies ist in unserem Beispiel aber nicht notwendig, da wir zuvor bereits eine Tabelle mit den Jahren erstellt und befüllt haben.
Nach erfolgreicher Erstellung der Objekte des Meta-Modells erscheinen die Meldungen „Meta model created successfully“ und „No valid license found“. Ohne eine DeltaMaster-ETL-Lizenz ist die Modellierung auf fünf Dimensionen begrenzt, das Eintragen der Lizenz wird im folgenden Abschnitt erläutert. Die Arbeit mit „DeltaMaster ETL.exe“ für den Moment abgeschlossen.
Verbindung und initiale Konfiguration mit „ETL.das“
Öffnen Sie DeltaMaster und wählen Sie die ETL-Anwendung aus. Um Zugriff auf die Datenbank zu erhalten, passen Sie den Dialog zur Anmeldung der relationalen Datenbank, wie in Abbildung 17 zu sehen, an. Die wesentlichen Änderungen sind:
- Der Wert für „Integrated Security“ muss auf „False“ gesetzt werden.
- Die Zeilen für „User“ und „Password“ müssen hinzugefügt und mit Ihren Anmeldedaten ausgefüllt werden.
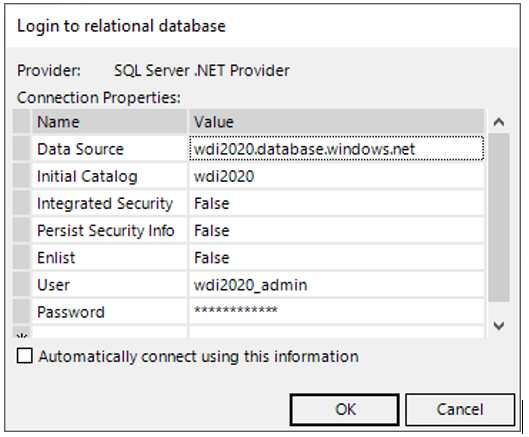
Abbildung 17: Ausgefüllter Anmeldedialog der „ETL.das“
Hinweis: Die Zeile „Application Name“ wurde in diesem Beispiel entfernt. Dies ist grundsätzlich nicht notwendig.
Bestätigen Sie Ihre Eingabe mit „OK“ und wechseln Sie in den Bericht „Licensing“, wo Sie Ihren DeltaMaster-Lizenzschlüssel eingeben.
Die folgenden beiden Einstellungen sind optional, erleichtern aber die Bedienung. Sie können angepasst werden, da in diesem Beispiel keine OLAP-Datenbank verwendet wird.
- Wechseln Sie zu dem Bericht „Global Parameters“ und setzen Sie den Wert „Enable Create OLAP database“ zu „-“. Dieser verhindert, dass eine OLAP-Datenbank erstellt werden kann.
- Wechseln Sie zu dem Bericht „Application Parameters“ und setzen Sie den Wert „Show warning when OLAP objects are renamed“ auf „-“, da auch diese Einstellung nur bei der Verwendung von OLAP-Datenbanken relevant ist.
Sofern Sie der Schema-Verwendung in diesem Beitrag folgen, wählen Sie den Bericht „Relational Object Parameters“. In der Zeile für „Data mart schema“ geben Sie den Wert „datamart“ ein und bestätigen Ihre Eingabe. Falls Sie ein konsistentes Sprachschema wünschen, bietet es sich an, im Bericht „Global Parameters“ den Wert für „Standard content language“ auf „EN“ für Englisch zu setzen. Im weiteren Verlauf dieses Beitrags wird angenommen, dass der Sprachparameter auf Englisch gesetzt ist.
Modellierung mit „ETL.das“
Nun folgt die Modellierung, auf deren Grundlage im nächsten Abschnitt die Goldtabellen generiert werden. Alle Berichte in diesem Beispiel sind Teil des Ordners „Define Model“. Sofern nicht anders angegeben, werden in den Einträgen, die Sie in den Berichten tätigen, stets die Standard-Werte von ETL übernommen.
Erstellen der Dimensionen
Im Bericht „Dimensions“ fügen Sie Zeilen für die Länder und die Indikatoren hinzu. Da es sich bei der primären Hierarchie um eine reguläre und keine vom Typ Parent-Child handelt, wählen Sie „Regular“. Der „AllMemberName“ ist üblicherweise die Kombination aus „All“ und dem Ebenennamen unterhalb der All-Ebene.
| Name | Type | AllMemberName |
| Country | Regular | All regions |
| Indicator | Regular | All indicators |
Tabelle 7: Modifizierte Zeilen des Berichts „Dimensions“
Im Bericht „Levels“ fügen Sie die Ebenen der Länder und Indikatoren hinzu. Zudem fügen Sie eine neue Ebene für das Jahrzehnt hinzu. Da nur die Ebenen „Country“ und „Indicator“ sowohl über IDs wie auch Bezeichner verfügen, ist ein „Long Name Attribute“ nur für diese beiden sinnvoll. Die Datentypen sind an die maximal ermitteltenen Feldlängen angepasst.
| Dimension | LevelID | Name | Key Data Type | Key Default | Name Default | Use Name As | Long Name Attribute |
| Period | 1 | Decade | varchar(5) | – | – | Name | – |
| Period | 2 | Year | smallint | 2079 | 2079 | Name | – |
| Country | 1 | Region | varchar(26) | – | – | Name | – |
| Country | 2 | Country | varchar(3) | – | – | Attribute | Yes |
| Indicator | 1 | Indicator
Domain |
varchar(42) | – | – | Name | – |
| Indicator | 2 | Indicator
Topic |
varchar(86) | – | – | Name | – |
| Indicator | 3 | Indicator | varchar(25) | – | – | Attribute | Yes |
Tabelle 8: Modifizierte Zeilen des ETL.das Berichts „Levels“
Im Bericht „Level Source Columns” geben Sie die Quell-Objekte an.
| Dimension | Level | Source Table | Key Source Column | Name Source Column | Include Attributes |
| Period | Decade | logic.V_S_DIM_Year | DecadeID | DecadeID | – |
| Period | Year | logic.V_S_DIM_Year | YearID | YearID | – |
| Country | Region | logic.V_IMPORT_DIM_Country | RegionID | RegionID | – |
| Country | Country | logic.V_IMPORT_DIM_Country | CountryID | CountryNAME | – |
| Indicator | Indicator
Domain |
logic.V_IMPORT_DIM_Indicator | Indicator
DomainID |
Indicator
DomainID |
– |
| Indicator | Indicator
Topic |
logic.V_IMPORT_DIM_Indicator | Indicator
TopicID |
Indicator
TopicID |
– |
| Indicator | Indicator | logic.V_IMPORT_DIM_Indicator | IndicatorID | IndicatorNAME | Yes |
Tabelle 9: Modifizierte Zeilen des Berichts „Level Source Columns“
Im Bericht „Attributes” reicht aus, den [IndicatorBIFactor] hinzuzufügen.
| Dimension | Level | Name | Data Type | Default |
| Indicator | 03 – Indicator | IndicatorBIFactor | smallint | 1 |
Tabelle 10: Modifizierte Zeile des Berichts „Attributes“
So auch im Bericht „Attribute Source Columns“:
| Dimension | Level | Attribute | Source Table | Source Column |
| Indicator | 03 – Indicator | IndicatorBIFactor | Logic.V_IMPORT_DIM_Indicator | IndicatorBIFactor |
Tabelle 11: Modifizierte Zeile des Berichts „Attribute Source Columns“
Erstellen der Measure Group
Die Konfiguration der Measure Group fasst sich kurz:
- Im Bericht „Cubes“ reicht es aus, eine neue Zeile hinzuzufügen und die Spalte „Name“ auszufüllen, z. B. mit „WDI2020“.
- Auch im Bericht „Measure Groups“ fügen Sie einen neuen Datensatz ein, wobei Sie in der Spalte „Name“ den Wert „Measurements“ eintragen.
- Im Bericht „Measure Group Source Tables/ Partitions” reicht ein weiterer Eintrag, wobei Sie hier die Measure Group „Measurements“ verwenden und als Source Table die materialisierte Sicht „logic.TMV_IMPORT_FACT_Measurements“ auswählen.
Der Bericht „Measure Group Dimensions“ sollte automatisch wie folgt konfiguriert sein:
| Measure Group | Dimension | Hierarchy | Level |
| Measurements | Period | H00 – Period | 02 – Year |
| Measurements | ValueType | H00 – ValueType | 01 – ValueType |
| Measurements | PeriodView | H00 – PeriodView | 01 – PeriodView |
| Measurements | Cumulation | H00 – Cumulation | 01 – Cumulation |
| Measurements | Country | H00 – Country | 02 – Country |
| Measurements | Indicator | H00 – Indicator | 03 – Indicator |
Tabelle 12: Übersicht der Zeilen des Berichts „Measure Group Dimensions“
Im Bericht „Measure Group Dimension Source Columns” sind die Werte der Source Column gegebenenfalls anzupassen.
| Measure Group | Dimension | Hierarchy | Level | Source Column |
| Measurements | Period | H00 – Period | 02 – Year | YearID |
| Measurements | ValueType | H00 – ValueType | 01 – ValueType | 1 |
| Measurements | PeriodView | H00 – PeriodView | 01 – PeriodView | 1 |
| Measurements | Cumulation | H00 – Cumulation | 01 – Cumulation | 1 |
| Measurements | Country | H00 – Country | 02 – Country | CountryID |
| Measurements | Indicator | H00 – Indicator | 03 – Indicator | IndicatorID |
Tabelle 13: Übersicht der Zeilen des Berichts „Measure Group Dimension Source Columns“
Im Bericht „Measures” wird nur der Datensatz für den Wert aus der Faktentabelle benötigt, wie sich später in der relationalen Modellierung mit DeltaMaster zeigen wird. Der bestehende Zähler kann somit entfernt werden, sodass der Bericht wie folgt aussehen sollte.
| Measure Group | Measure ID | Name | Data Type | AggregateFunction |
| Measurements | 1 | Value | float | Sum |
Tabelle 14: Übersicht der Zeilen des ETL.das Berichts „Measures“
Im Bericht „Measure Source Columns” sollte für den bestehenden Datensatz in der Spalte „Source Columns“ der Wert „Value“ eingetragen sein.
Optional können Sie die Fußnotizen als Informationsfeld hinzufügen. Wählen Sie dafür den Bericht „Infos“ und fügen Sie eine neue Zeile mit dem Namen „FootNote“ und dem Datentyp „varchar(1245)“ ein. Im Bericht „Info Source Columns“ wählen Sie die passende Source Column aus, sofern sie nicht automatisch korrekt ermittelt wurde.
Damit ist die Modelierung in „DeltaMaster ETL.das“ abgeschlossen.
Erstellen des Datenmodells mit „ETL.exe“
Wechseln Sie zurück zu „DeltaMaster ETL.exe“. Führen Sie nun die beiden ersten Schritte im Bereich „Model“ aus. Im darunterliegenden Bereich „Log“ können Sie den Fortschritt verfolgen.
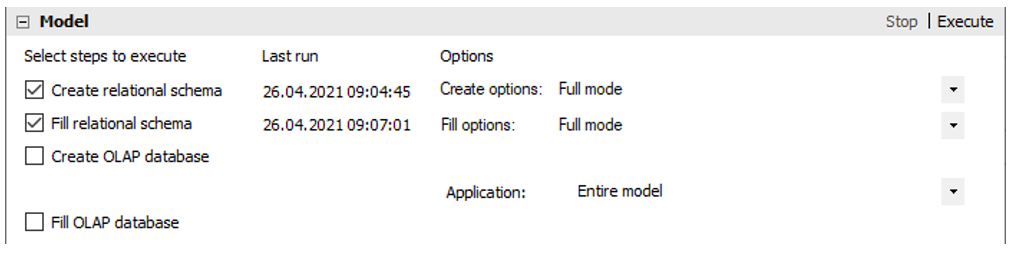
Abbildung 18: Schritte für die Erstellung der Tabellen des relationalen Modells in DeltaMaster ETL
Hinweis: Falls der zweite Schritt „Fill relational schema“ aufgrund nicht ausreichender Rechenkapazitäten Ihrer Azure SQL Datenbank fehlschlägt, existiert folgender Workaround: Führen Sie die „[datamart].[P_DIM_…]“ und „[datamart].[P_FACT_…]“-Prozeduren manuell nacheinander (in separaten Batches) aus. Da es sich hierbei um zwölf Prozeduren handelt, ist der Aufwand dafür gering. Selbst bei diesem Verfahren wird das Ausführen der „[datamart].[P_FACT_…_TMV_IMPORT_FACT_Measurements]“ aber einige Zeit in Anspruch nehmen. In einem Test hat der Abschluss der Prozedur mit dem Basic-Tarif in der Azure-Umgebung rund 80 Minuten gedauert, während die Ausführung auf einem lokalen Gerät (i7-8650U, 16 GB RAM) lediglich 2 Minuten beanspruchte.
Nach Abschluss der beiden Schritte bestehen die Dimensionstabellen „[datamart].[T_DIM_…]“ sowie die Tabelle für die Fakten „([datamart].[T_FACT_01_Measurements])“, die die Quell-Objekte für DeltaMaster bilden.
Relationale Modellierung und Analyse mit DeltaMaster
Nachdem die Transformationen bestimmt und die Tabellen erstellt sind, kann nun die damit sehr kurz gehaltene Modellierungsarbeit in DeltaMaster beginnen, bevor Sie die Daten wie gewünscht analysieren können.
Im Folgenden wird zunächst die relationale Modellierung in DeltaMaster erläutert und im Anschluss daran drei Beispielberichte zum Datenmodell vorgestellt.
Auswahl der Quelle
Erstellen Sie eine neue DeltaMaster-Anwendung. Wählen Sie dazu als Datenquelle „Microsoft Azure SQL Database“ aus. Verbinden Sie sich in dem folgenden Dialog mit Ihrer Datenbank und bestätigen Sie Ihre Eingabe.
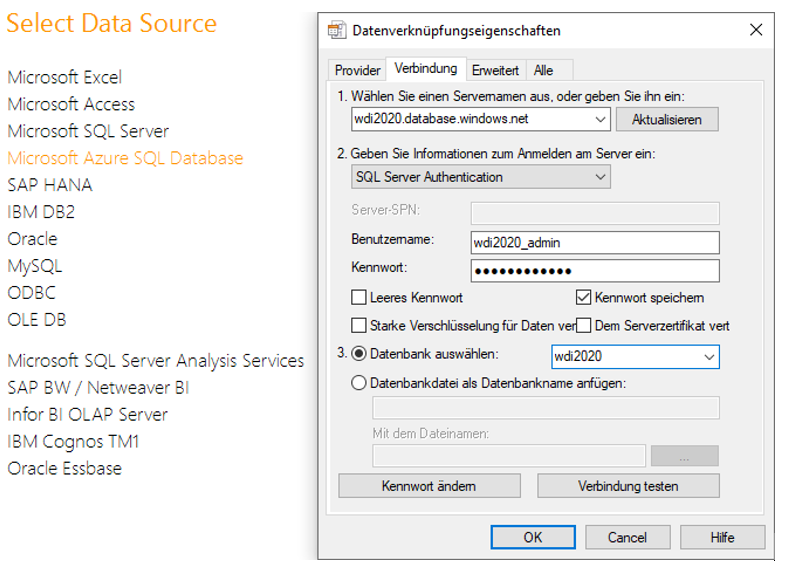
Abbildung 19: Verbindungsoptionen bei einer neuen DeltaMaster-Anwendung
Sie erhalten daraufhin einen Hinweis, dass für eine erfolgreiche automatische Verbindung der Benutzer und das Kennwort in der Anwendung gespeichert wird. Sie können dies entweder im Moment bestätigen oder ablehnen und zu einem späteren Zeitpunkt wieder konfigurieren.
Anschließend gelangen Sie in die Auswahl der Quell-Tabellen. Hier ist die „T_FACT_01_Measurements“ orange gefärbt, da DeltaMaster diese automatisch als Faktentabelle identifiziert hat. Klicken Sie sie an, sodass ein Haken vor die Tabelle gesetzt wird, und wählen Sie im unteren Berich „Modell“ aus. Wenn Sie anschließend mit dem Mauszeiger über den Tabellentitel fahren, sehen Sie, dass in der Auswahl neben der Faktentabelle auch sämtliche Dimensionstabellen auftauchen. Diese konnte DeltaMaster dank der Schlüsselbeziehungen zwischen Fakten- und Dimensionstabellen automatisch ermitteln.
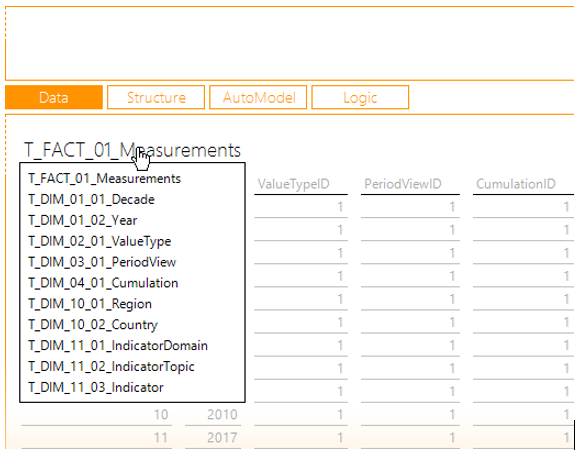
Abbildung 20: Zusammenhängende Dimensiontabellen zu der Faktentabelle
Grundsätzliche Modellierung
Klicken Sie nun auf die Schaltfläche „AutoModel“, sodass automatisch Dimensionen und Kennzahlen angelegt werden. Das Ergebnis sollte wie in Abbildung 21 aussehen.
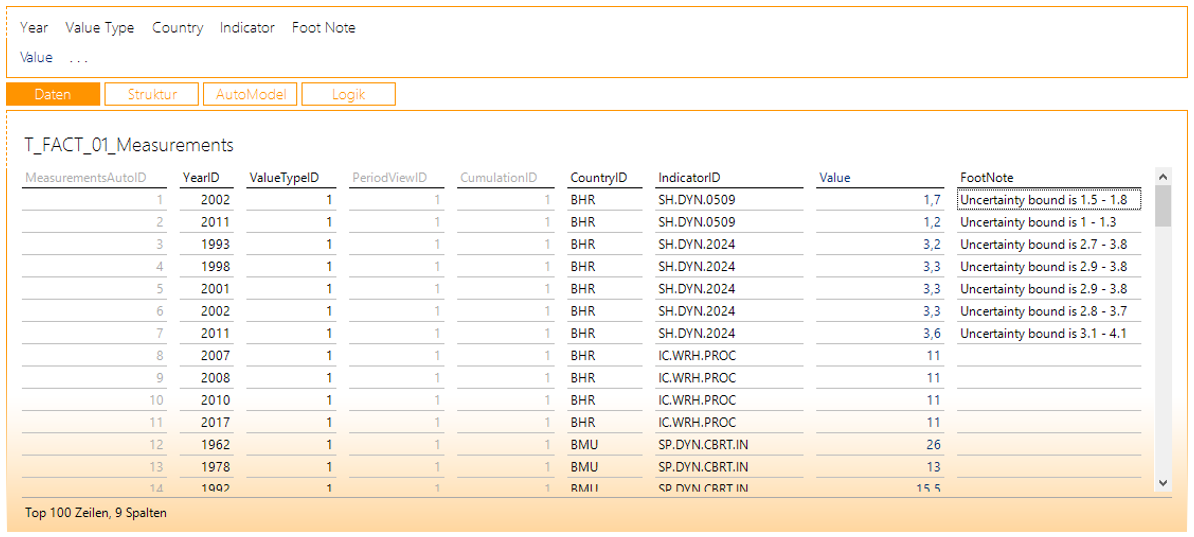
Abbildung 21: Ergebnis nach der Verwendung des Magic Buttons „AutoModel“
In der Dimensionsleiste tauchen zwei Einträge auf, die nicht benötigt werden oder inkorrekt sind. Der „Value Type“ (Wertart) unterscheidet üblicherweise zwischen Ist- und Planzahlen. Die Werte im vorliegenden Datensatz sind ausschließlich Ist-Zahlen. Sofern Sie nicht manuell weitere Vergleichswerte auf mit einer anderen Wertart hinzufügen, können Sie diese Dimension also deaktivieren. Zum anderen sind die „FootNotes“ als Dimension modelliert. Das ist inkorrekt (sie sind Informationen der MeasureGroup), weshalb Sie auch diese Dimension entfernen sollten. Das Deaktivieren/Entfernen erreichen Sie, indem Sie die Dimension aus der Filterleiste per Drag-and-drop in den Tabellenbereich ziehen.
Hinweis: Die Funktionen von „Value Type“ (Wertart), „Period View“ (Periodenansicht) und „Cumulation“ (Kumulation) werden in relationalen Modellen nicht durch die Verwendung separater Dimensionen, sondern als Elemente in der Zeit-Dimension ermöglicht. Die in DeltaMaster ETL erzeugten Tabellen dienen auch als Grundlage für multidimensionale Modelle, die die hier ausgegrauten Spalten als Quellen für die Dimensionen verwenden.
Nach dem Entfernen der beiden unerwünschten Dimensionen sollte Ihr Bildschirm nach Klick auf die Schaltfläche „Struktur“ wie in Abbildung 22 aussehen.
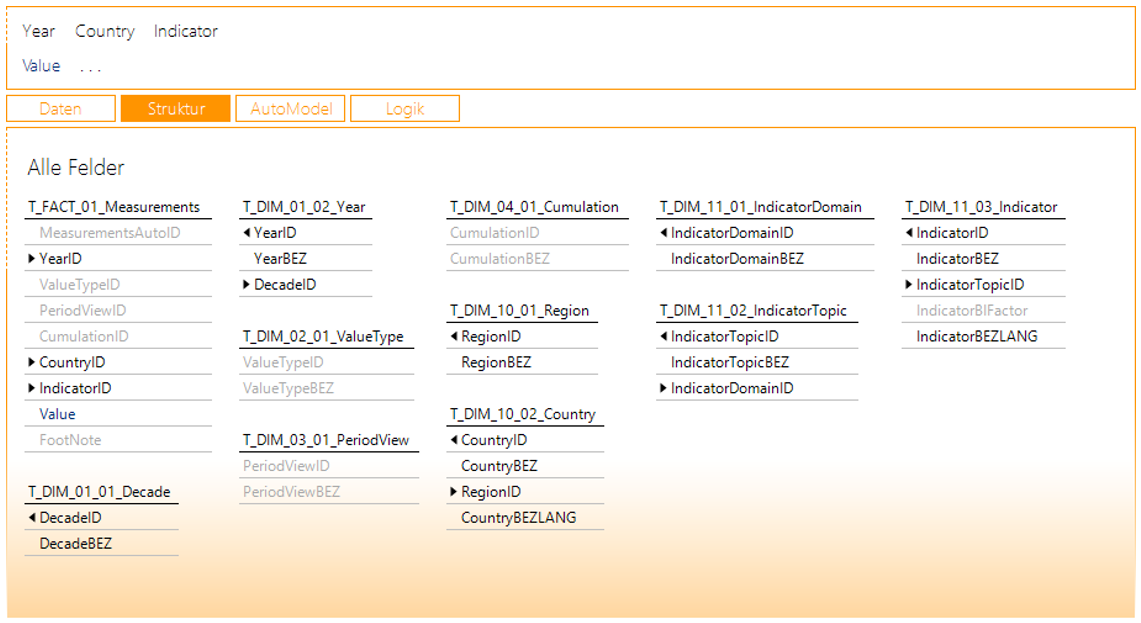
Abbildung 22: Beziehungen der Tabellen nach Bereinigung der Dimensionen
Die Grundlagen für den Berichtsbau sind damit gelegt. In den Abschnitten werden für die jeweiligen Berichte nochmals Erweiterungen am Datenmodell vorgenommen.
Beispielbericht #1: Umfang des Datensatzes
Ein erster Beispielbericht soll die Anzahl der Elemente der Dimensionen (Zeit, Länder, Indikatoren) sowie die Anzahl der Zeilen der Faktentabelle darstellen. Bleiben Sie dafür beim „Modellieren“ und wechseln Sie auf die Tabelle der Jahre:
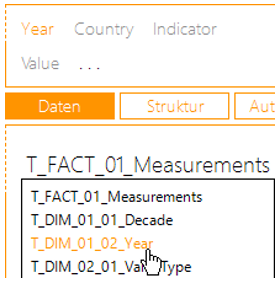
Abbildung 23: Aufruf anderer Quelltabellen
Rufen Sie nun das Modelliermenü rechts auf und wählen Sie dort „Zählwert hinzufügen“.
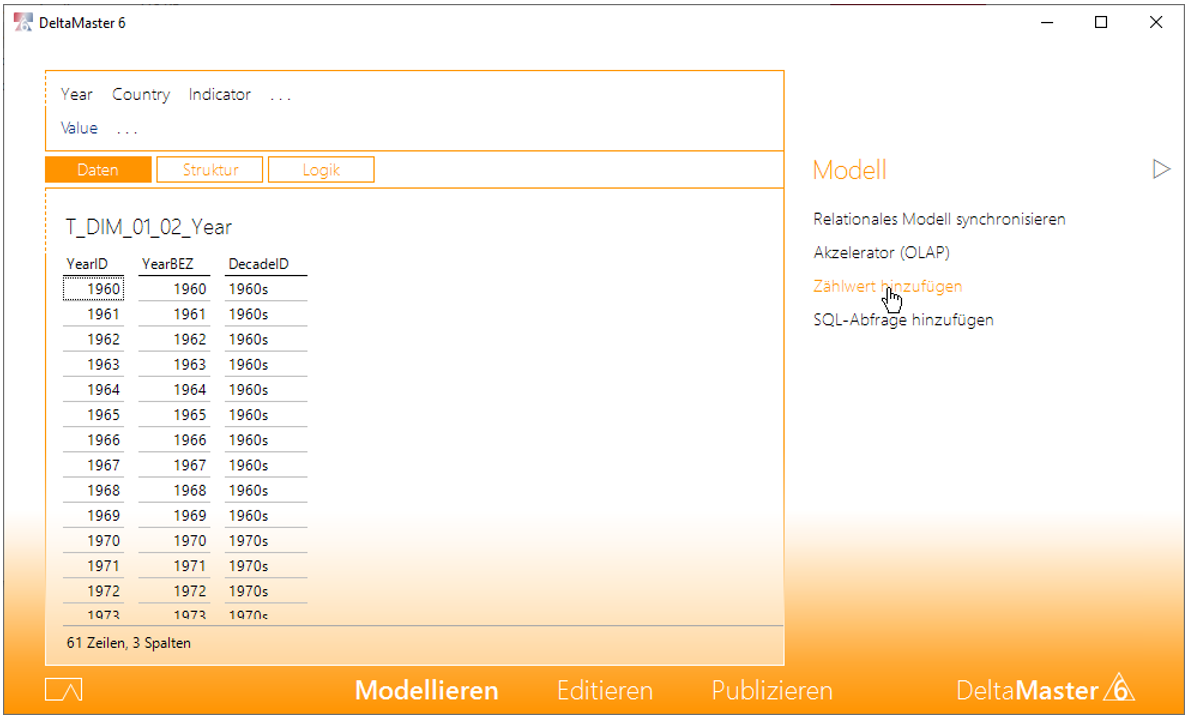
Abbildung 24: Darstellung des Modelliermenüs zum Hinzufügen von Zählwerten
Dadurch erscheint eine neue Kennzahl mit dem Bezeichner „Anzahl“. Da diese Funktion weitere Male genutzt wird, ändern Sie den Bezeichner dieser Kennzahl ab, z. B. in „# Year“. Verfahren Sie so auch für die Tabellen der Länder und Indikatoren und benennen Sie die neuen Kennzahlen analog. Führen Sie dies auch für die Faktentabelle „T_FACT_01_Measurements“ durch und benennen Sie den Zähler in „# Value“ um.
Die Filter- und Kennzahlenleiste sollte anschließend wie in Abbildung 25 aussehen.

Abbildung 25: Kennzahlen-Leiste mit neu erstellten Kennzahlen
Wechseln Sie zum „Editieren“ und erstellen Sie nun einen neuen Bericht vom Berichtstyp „Kachelnavigation“. Verwenden Sie für jeden der eben erzeugten Kennzahlen eine eigene Kachel, so dass Sie den in Abbildung 26 dargestellten Beispielbericht #1 gestalten können. Dieser gibt Berichtsempfängern Aufschluss über den Umfang des Datasets.
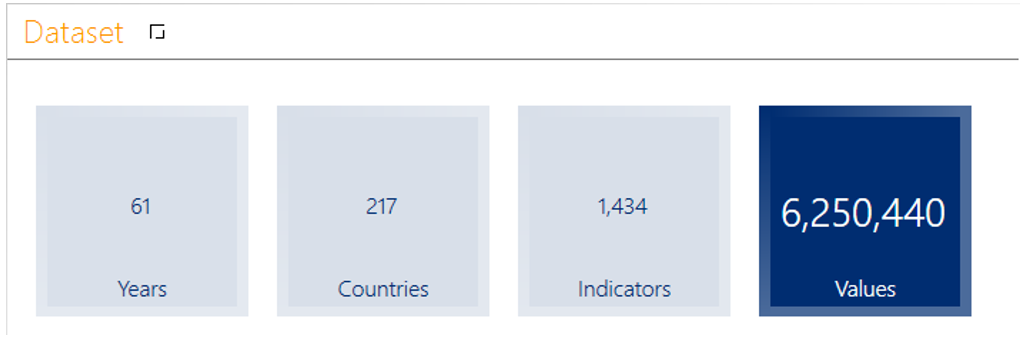
Abbildung 26: Screenshot des Beispielberichts #1
Beispielbericht #2: Indikatoren für Deutschland
In diesem Bericht sollen die Indikatoren nach Themen gruppiert auf der Zeilenachse und der Wert für das Jahr 2020 – mit Sparklines der letzten zehn Jahre – auf der Spaltenachse gezeigt werden. Dabei sollen nur die für Deutschland relevanten Indikatoren verwendet werden, also jene mit Werten.
Erstellt man den Bericht gemäß diesen Anforderungen, zeigen sich zwei Probleme:
- Die Werte der Indikatoren werden für das Thema, d. h. die darüberliegende Ebene, summiert, was fachlich falsch ist.
- Mindestens ein Indikator hat eine üblicherweise als negativ betrachtete Bedeutung (z. B. die Arbeitslosenquote).
Beide Probleme können im Modellieren behoben werden.
Für den ersten Fall wird eine neue Kennzahl erstellt, die nur Werte zeigen soll, wenn die Zeile im Bericht auf der Ebene der Indikatoren ist, nicht auf einer anderen Ebene. Dafür wird folgender SQL-Ausdruck verwendet.
IIF(GROUPING([datamart].[T_DIM_11_03_Indicator].[IndicatorID]) <> 1,
#1,
''
)
Beachten Sie dabei: #1 referenziert nur in DeltaMaster den „Value“, der exakte Tabellenname (hier: „T_DIM_11_03_Indicator“) ist auch abhängig von der Nummerierung der Dimension (hier: 11).
Der Dialog zum Anlegen eines Analysewerts kann somit wie in Abbildung 27 aussehen.
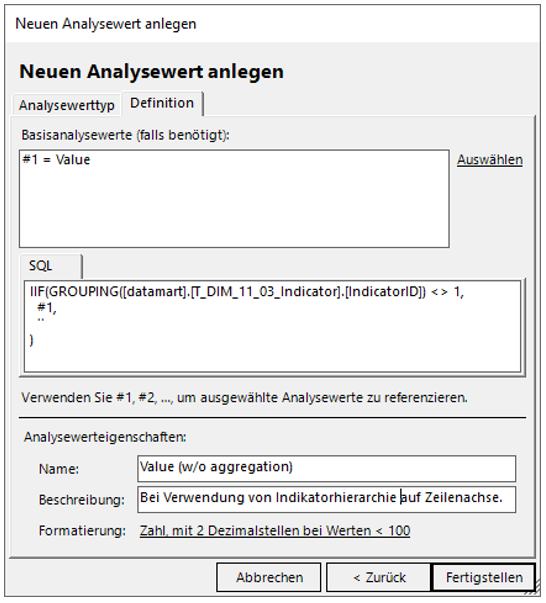
Abbildung 27: Neuer Analysewert, der Werte nicht für Ebenen oberhalb der Indikatoren anzeigt
Diese neue Kennzahl soll statt der bestehenden im Bericht verwendet werden. Belässt man es bei diesen Einstellungen, so sieht ein das Ergebnis wie in Abbildung 28 aus.
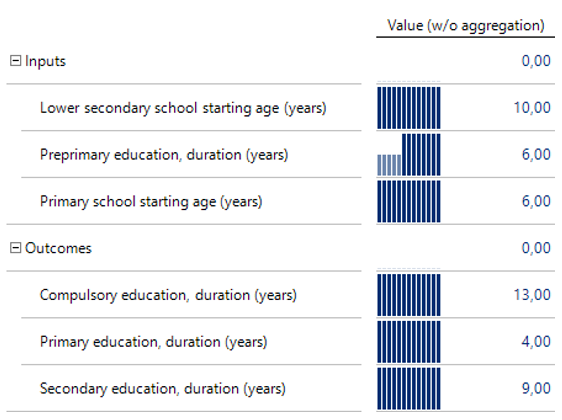
Abbildung 28: Demonstration des Analysewerts ohne Aggregation für das Indikatoren-Thema
Dabei ist zu sehen, dass die beiden Themen „Inputs“ und „Outcomes“ wie gewünscht die Werte der darunter befindlichen Elemente nicht summieren. Noch besser ist es, wenn für diese Themen nicht „0“ angezeigt wird. Um das zu erreichen, hilft die eine benutzerdefinierte Formatierung der Kennzahl, die im Reiter „Formatierung“ der Kennzahl eingegeben werden kann:
###,###,###0.##;-###,###,###0.##;''
Fügt man diese in dem passenden Dialog ein, sieht das wie in Abbildung 29 aus.
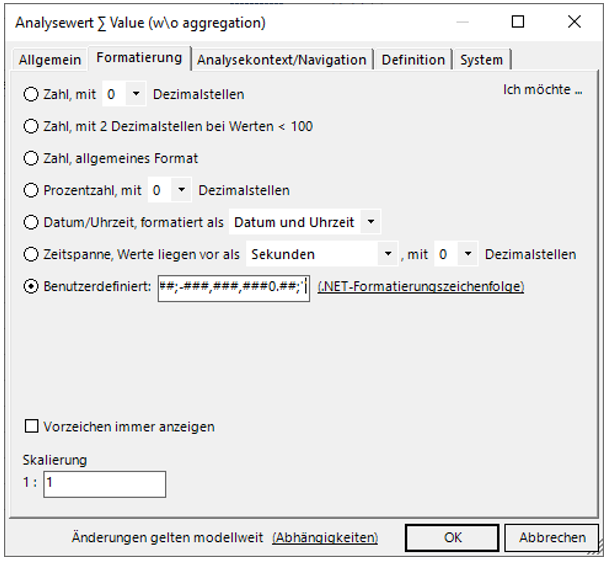
Abbildung 29: Reiter zum Festlegen der Formatierung einer Kennzahl
Anschließend kann das zweite Problem, die Darstellung der negativen Bedeutung von Werten, angegangen werden. Diese sollen wie in DeltaMaster üblich in rot dargestellt werden. Klicken Sie dazu beim „Modellieren“ auf die Dimension „Indicator“ und wählen Sie im Dialog die Option „Ich möchte …“ und dann „Hierarchieeigenschaften“ aus.
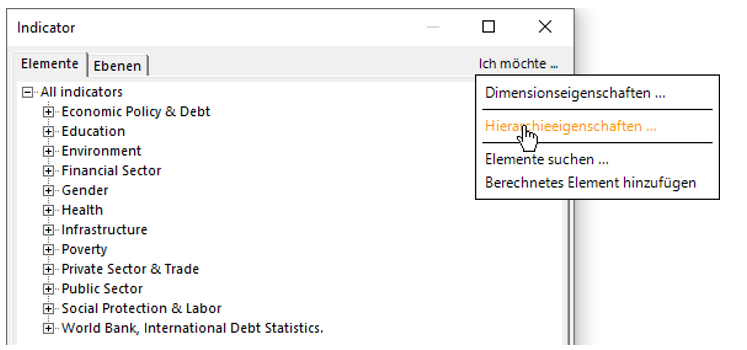
Abbildung 30: Hierarchieeigenschaften
Wählen Sie dann an der Stelle „Faktor“ das Feld „IndicatorBIFactor“ aus und bestätigen Sie die Eingabe.
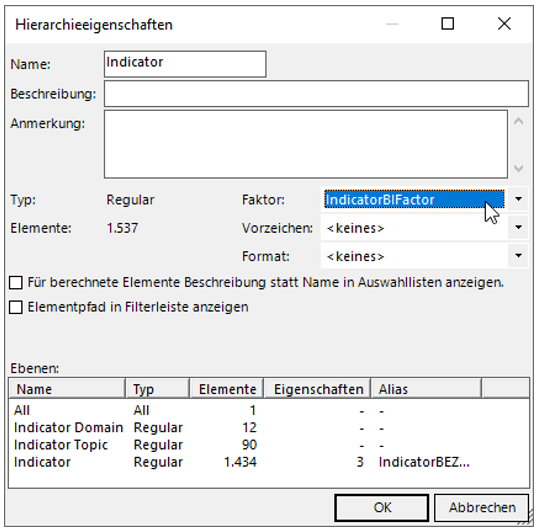
Abbildung 31: Neben dem Faktor lässt sich z. B. auch das Format abhängig von der Dimension steuern
Wechseln Sie zurück zum „Editieren“. Den Beispielbericht #2 erstellen Sie wie folgt:
- Ziehen Sie die Ebenen „Indicator“ und „Indicatortopic“ auf die Zeilenachse.
- Ziehen Sie die neu erstellte Kennzahl auf die Spaltenachse.
- Verwenden Sie die Magischen Knöpfe „Historie“ für das Einfügen von Sparklines und „Layout“ für Weißraum.
- Wählen Sie im Modelliermenü rechts unter „Sparklines“ und „Trendbarometer“ die Eigenschaft „Trendbarometer (Steigung wie Anzeige)“ an.
- Filtern Sie auf das Jahr „2020“ und das Land auf „DEU – Germany“.
- Vergeben Sie den dynamischen Berichtstitel: „Indicators for “, wobei Sie das X durch die ID der „Country“-Dimension ersetzen. Die ID erfahren Sie, indem Sie mit gedrückter ALT-Taste mit dem Mauszeiger über die Dimension in der Filterleiste fahren.
Falls gewünscht, können Sie noch den Berichtstitel in die Filterleiste integrieren, um weiteren Platz zu sparen. Tätigen Sie dazu einen Rechtsklick auf den Bericht in der Berichtsleiste und wählen Sie die Berichtseigenschaften.
Abbildung 32: Berichtseigenschaften
Haken Sie „Berichtstitel und Steuerleiste in Filterleiste integrieren“ an.
Abbildung 33: Option für die Integration von Berichtstitel und Steuerleiste in Filterleiste
Nun sollte Ihr Bericht wie in Abbildung 34 aussehen.
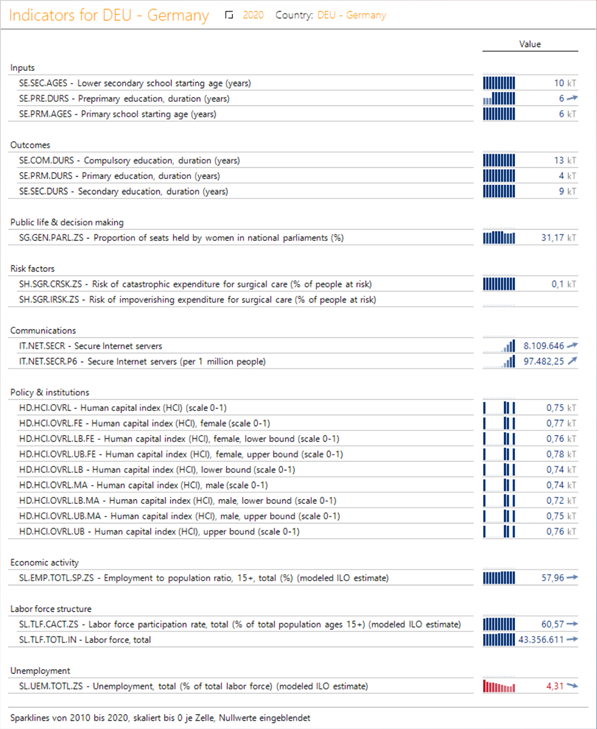
Abbildung 34: Screenshot des Beispielberichts #2
Beispielbericht #3: Arbeitslosigkeit weltweit
Zuletzt soll eine Kreuztabelle aus den Regionen und deren All-Element auf der Zeilenachse und mehreren Indikatoren zur Arbeitslosigkeit auf der Spaltenachse erstellt werden.
Hierfür ist eine weitere Vorbereitung nötig. Während im Bericht des vorherigen Unterkapitels eine Aggregation ausgeschlossen werden sollte, sollen in dem Fall dieses Unterkapitels Durchschnitte errechnet werden. Wechseln Sie dazu zum „Modellieren“ und erstellen Sie den Quotientenwert „Ø Value“ mit dem Dividenden „Value“ und dem Divisor „# Value“ (vgl. Abbildung 35).
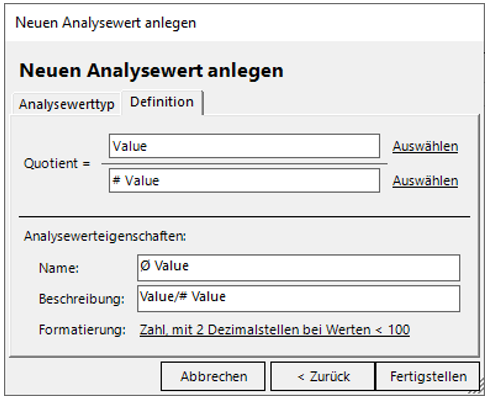
Abbildung 35: Definition des neuen Analysewerts „Ø Value“
Wechseln Sie zurück zum „Editieren“ und erstellen Sie den Bericht wie folgt:
- Ziehen Sie die Ebenen „Region“ und „All“ der Dimension „Country“ auf die Zeilenachse. Wechseln Sie in die Achseneigenschaften der Zeilenachse und dort auf den Reiter „Optionen“, um im Präsentationsmodus den Drill-Down bis zur Country-Ebene zu ermöglichen.
- Ziehen Sie die Indicator-Elemente, die Sie beim Sichten der Dimensionen in die „T_S“-Tabelle eingetragen haben, auf die Spaltenachse für eine fixe Auswahl. Alternativ können Sie auch eine Ebenenauswahl verwenden.
- Ziehen Sie den Quotientenwert „Ø Value“ in den Filterbereich des Berichts.
- Filtern Sie auf das Jahr 2019.
- Fügen Sie Sparklines mit dem Magischen Knopf „Historie“ hinzu. Setzen Sie Anzahl der Sparkline-Säulen auf „10“. Fügen Sie ein „Trendbarometer (Steigung wie Anzeige)“ ein.
- Nutzen Sie den Magischen Knopf „Zoom“, um alle Sparklines zu vergrößern.
- Wählen Sie abschließend die Bissantz Numbers aus dem Magnischen Knopf „Grafik“.
- Vergeben Sie einen passenden Berichtstitel.
Mit dem nun vorliegenden Beispielbericht #3, wie in Abbildung 36 dargestellt, haben Sie eine Vorlage für weitere fachlich stimmige Analysen.
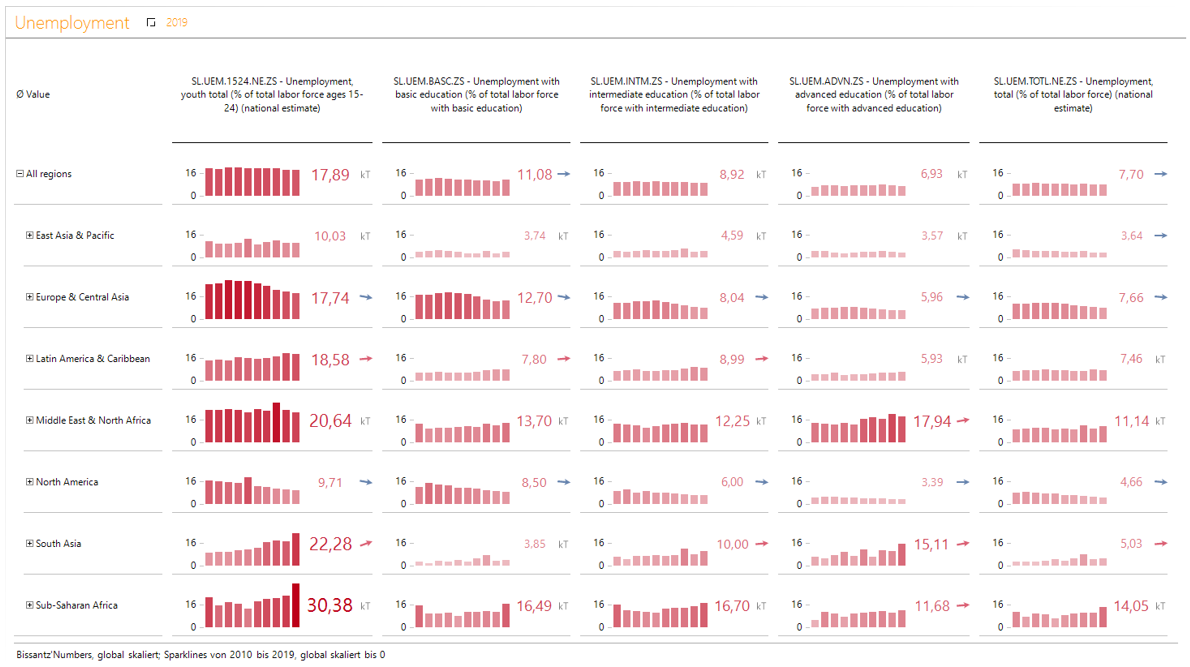
Abbildung 36: Screenshot des Beispielbericht #3
Zusammenfassung
Haben Sie die Schritte dieses Beitrags umgesetzt, sind mit Sicherheit einige Stunden an Arbeit in die Ihnen nun vorliegende DeltaMaster-Anwendung zu den World Development Indicators geflossen. Im Folgenden fassen wir die Ergebnisse noch einmal zusammen, gehen auf Limitationen ein und geben Anregungen zur weiteren Auseinandersetzung mit relationalen Daten in Azure-SQL-Datenbanken.
Ergebnis
Dieser Beitrag hat gezeigt,
- wie ein Open Source-Dataset, am Beispiel der World Development Indicators der Weltbank, in eine Azure-SQL-Datenbank importiert werden kann,
- dass mit Hilfe von Software wie dem Microsoft SQL Server Management Studio Logiken in Sichten abgebildet werden können und
- mit DeltaMaster ETL konsistente Tabellen inkl. Schlüssel erstellt werden können, auf deren Grundlage in DeltaMaster
- eine schnelle, relationale Modellierung und Analyse des Datasets möglich ist.
Dabei sei darauf hingewiesen, dass der dritte Schritt optional ist – denkbar wäre gewesen, die [logic]-Objekte für DeltaMaster als Quelle zu verwenden. Dies hätte wiederum den Modellierungsaufwand in DeltaMaster erhöht.
Bei der Verwendung des Basic-Tarifs der Azure-SQL-Datenbank bietet sich eine parallele Entwicklung auf einem lokalen System an. Insbesondere der Aufruf von Prozeduren und das Ausführen von Abfragen, die viele Datensätze schreiben (z. B. die Materialisierung der Sicht „[logic].[V_IMPORT_FACT_Measurements]“ oder die durch „ETL.exe“ aufgerufene Prozedur „[dbo].[P_Transform_All]“), beanspruchen viel Rechenkapazität. In lokalen Tests zeigte sich das Phänomen, dass diese Vorgänge abbrechen können. Workarounds wurden in den Abschnitten zur Sicht der MeasureGroup und Erstellen des Datenmodells mit „ETL.exe“ gezeigt.
Limitationen
Wie eingangs bei den Erläuterungen zum Datensatz und zu den Sichten der Dimensionen erwähnt, wurde in diesem Beitrag nicht das gesamte Dataset untersucht. Auch die Beispielberichte kratzen nur an der Oberfläche der Analysepotenziale, die dieses Dataset bietet. Weitere, nicht in diesem Blog dokumentierte Analysen ergaben, dass zudem einige Datensätze für das Jahr 2020 unvollständig sind (Stand Ende April 2021). Es ist somit denkbar, dass der Datensatz mit fortschreitender Zeit noch etwas an Umfang gewinnt, wodurch auch der benötigte Speicherplatz zunehmen kann – oder gar eine Aktualisierung des Modells bei einer Strukturänderung des Datensatzes notwendig werden könnte.
Inspiration aus diesem Beitrag
Aufbauend auf dem Ergebnis dieses Beitrags sind u. a. folgende Modifikationen denkbar:
- In diesem Beitrag wurde gezeigt, wie die Quell-Dateien von einem lokalen System geladen wurden. Reduziert man den Einsatz auf eine Cloud-Umgebung, so sollte es möglich sein, die Dateien in einem Azure-Storage-Konto zu speichern und die Tabellen mit der Azure Data Factory in die Azure-SQL-Datenbank zu laden.
- Auch weitere, grundsätzliche Modellierungsthemen können mit dem Datensatz untersucht werden. Neben dem erwähnten m:n-Verhältnis zwischen Land und Aggregat (vgl. Abschnitt Sichten der Dimensionen) bietet sich zumindest das Thema der Bridge-MeasureGroups an, die aus den beiden nicht verwendeten Dateien „WDICountry-Series.csv“ und „WDISeries-Time.csv“ resultieren würden.
- Die mit DeltaMaster ETL erstellten Tabellen sind auch Grundlage für OLAP-Datenmodelle, z. B. für die Azure Analysis Services. Bei der Verwendung des mehrdimensionalen Modells können Wertart, Periodenansicht und Kumulation als separate Dimensionen verwendet werden und auch die Abfragesprache, z. B. bei der Erstellung neuer Kennzahlen, unterscheidet sich (MDX/DAX statt SQL).
- DeltaMaster bietet Möglichkeiten der Geo-Analyse an. Für diese werden Kartendateien verwendet, deren Speicherpfad in DeltaMaster konfiguriert werden muss. Insbesondere eine Weltkarte ist fachlich stimmig mit den Inhalten des vorliegenden Datasets.
