Hokuspokus Ratzefatz, aus Kreuztabell’ mach’ Datensatz!
Wie schön wäre es, könnten wir diesen Zauberspruch das ein ums andere Mal auf sogenannte “Excel-Datengräber” anwenden. Diese liegen meist in Form von Kreuztabellen vor, die sich so nicht ohne weiteres zu einer OLAP-Analyse weiterverarbeiten lassen. Dass wir uns auf unsere magischen Fähigkeiten nicht verlassen können, ist uns aber leider spätestens klar geworden, seit wir verstanden haben, dass Bibi Blocksberg eine Comic-Figur ist. Von daher müssen wir uns anders weiterhelfen. Der Stein der Weisen ist der sogenannte “CrossTableConverter”. Dieser konvertiert Excel-Kreuztabellen in ein klassisches Datensatz-Format. Die daraus gewonnen Flatfiles können dann problemlos in Datenbanken eingelesen oder durch den DeltaMaster ImportWizzard direkt analysiert werden. Klingt zu schön um wahr zu sein? Ist es auch – lassen Sie uns zaubern!
Warum zaubern?
Mit Microsoft Excel ist man schnell und einfach in der Lage, Tabellen zu erstellen und sich kleine Analysen aufzubauen. Leider führt dies oft dazu, dass Excel als Datenbank missbraucht wird. So werden uns immer wieder Excel-Dateien vorgelegt, in denen beispielsweise die strategischen Plandaten einer Gesellschaft enthalten sind. Das ist erstmal nicht schlimm. Dramatische Züge nimmt es erst an, wenn die Daten nur in dieser Datei vorhanden sind und nirgends anders. Wird diese Datei aus irgendeinem Grund zerstört, ist die Planung verloren. Will man aus einer anderen Systemumgebung darauf zugreifen, ist man fast chancenlos. Bleibt man im Medium Excel, werden unzählige Verknüpfungen zwischen Dokumenten erstellt, die spätestens beim Verschieben einer Datei nicht mehr zu gebrauchen sind. Von daher tut man gut daran, Daten nicht allein in Excel zu speichern, sondern den Weg Richtung Datenbank anzutreten.
Diese Erkenntnis ist der erste Weg zur Besserung. Doch selbst wenn man die Reise in das Märchenschloss der Datenbanken gebucht hat, ist es noch völlig unklar wie man dort hinreist. Klassischerweise finden wir zwei Ausgangssituationen vor. Im einfachsten Fall ist in der Excel-Datei bereits ein Tabellenblatt mit flachen Datensätzen enthalten, so wie in nachfolgendem Beispiel gezeigt:
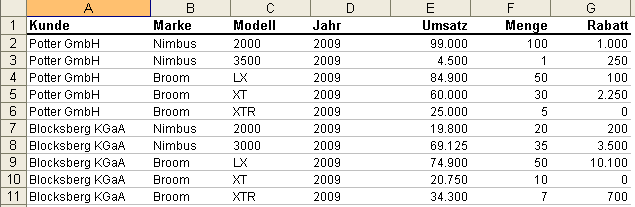
Dies ist meist gegeben, wenn bereits mit Excel-Pivot-Tabellen gearbeitet wurde. Dieses Tabellenblatt kann direkt weiterverarbeitet werden. Wir reisen in dem Fall auf einem gepflasterten Weg mit prächtigem Ross an. Diese Form der flachen Datensätze (auch “Flatfile” genannt) stellt also unser Ziel dar, wo wir in jedem Fall hin wollen.
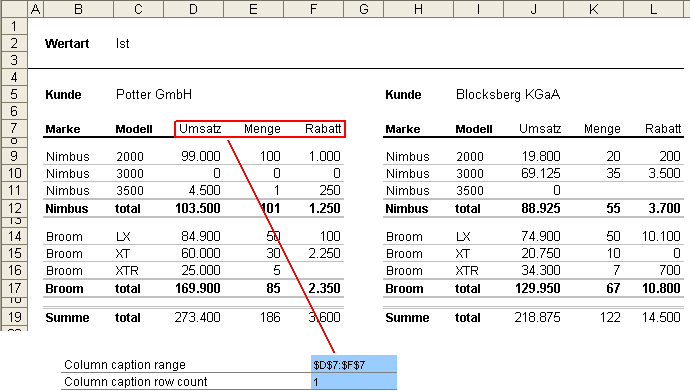
Gehen wir zurück zu dem oben erwähnten Planungsbeispiel. Niemand würde auf die Idee kommen, Planer ihre Daten in Datensatzform erfassen zu lassen. Daher werden hier meist Kreuztabellen erstellt, in denen die Daten erfasst werden. Das nachfolgende Beispiel zeigt eine klassische Kreuztabelle für eine Planung:
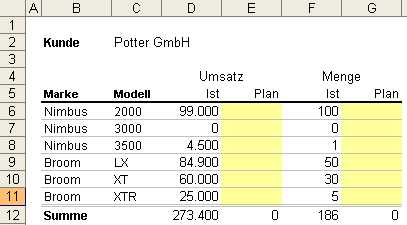
Handelt es sich dann noch um mehrere Tabellen (z. B. eine pro Grafschaft), haben wir einen ziemlich hügeligen und beschwerlichen Weg auf der Reise zum Märchenschloss vor uns. Würden wir versuchen die Daten manuell in Datensatzform zu bringen, käme das der Anreise auf allen Vieren mit schwerem Gepäck gleich. Genau an der Stelle kommt uns der “CrossTableConverter” zu Hilfe. Mit ein paar Handgriffen kann dem Werkzeug die Struktur der zugrundeliegenden Kreuztabelle beigebracht werden. Den Umbau der Daten erledigt der Converter dann automatisch. Von daher stellt uns der CrossTableConverter einen Hexenbesen bereit, auf dem wir bequem in die zauberhafte Datenbankwelt einschweben können.
Die Zauberutensilien
Schauen wir uns an, was wir tun müssen, um den Besen zum Fliegen zu bringen.
Die ersten Parameter, die hinterlegt werden müssen, sind die Quell- und Zieldateien. Die Quelle ist dabei immer eine Excel-Datei, das Ziel immer eine Textdatei. Der Quellpfad wird ganz normal mit Laufwerksbuchstabe, Backslashs und Datei-Erweiterung (hier also immer “.xls”) in den Parameter “Source path” eingetragen. Der Zielpfad kann entweder frei definiert oder leer gelassen werden (Parameter “Output path”). Wird kein Zielpfad definiert, übernimmt der CrossTableConverter den Pfad und Dateinamen aus der Quelle und hängt den Text “_converted” an den Dateinamen an. Die Endung des Ziels ist immer “.txt”. Nachfolgendes Bild zeigt eine Beispielkonfiguration mit entsprechendem Ergebnis:
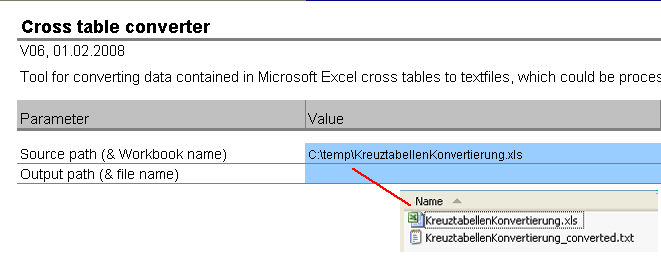
Der Zauberbesen hat aber auch noch ein unsichtbares Geheimnis in den Parametern versteckt. In der Quelle kann auch nur ein Ordner hinterlegt werden. In dem Fall werden alle Excel-Dateien konvertiert, die sich in dem betreffenden Ordner befinden. Unser Besen hat also auch noch einen Sodaspender an Bord…
Dass alle Dateien dann gleich strukturiert sein müssen, versteht sich von selbst. Der Pfad zum Ordner kann mit oder ohne abschließenden Backslash eingetragen werden, das Ziel bleibt leer. Die Zieldateinamen werden ebenfalls um den Text “_converted” ergänzt.
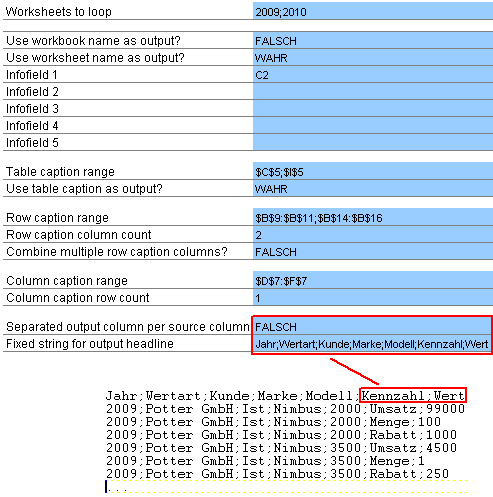
Im Parameter “Worksheets to loop” werden die Tabellenblätter definiert, die konvertiert werden sollen. Auch hier können eines oder mehrere verwendet werden, welche die gleiche Struktur aufweisen. Die Tabellenblätter müssen in allen konfigurierten Dateien enthalten sein. Die Liste der Blattnamen wird durch ein Semikolon (ohne Leerzeichen) getrennt:

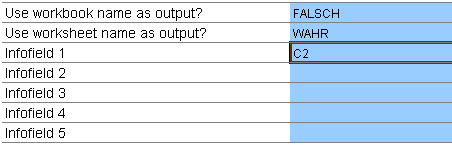
Der nächste Konfigurationsblock bestimmt, welche Spalten in den jeweiligen Datensatz mit aufgenommen werden. Teilweise gibt es globale Informationen pro Arbeitsblatt (wie beispielsweise die Wertart oder das Bezugsjahr) welche in jedem Datensatz wiederholt werden sollen, um die Daten korrekt zuordnen zu können. Die globalen Informationen können aus verschiedenen Quellen entnommen werden. Zunächst aus dem Dateinamen der Quelldatei (Parameter “Use workbook name as output?”) oder dem Tabellenblattnamen (Parameter “Use worksheet name as output?”). Soll eines der Kriterien mit ausgegeben werden, ist in den betreffenden Parametern auf einem deutschen Excel der Text “WAHR” einzutragen. Auf einem englischen System “TRUE”. Soll die Ausgabe vermieden werden dementsprechend “FALSCH” bzw. “FALSE”.
Weiterhin können frei definierbare Felder des Quellarbeitsblatts (“Infofield 1″ bis “Infofield 5″) zur Ausgabe konfiguriert werden. Das ist hilfreich wenn auf einem Arbeitsblatt eine entscheidende Information enthalten ist, die in den Kreuztabellen fehlt. Ein Beispiel für solche Informationsfelder liefert folgender Screenshot mit der Wertart in der Arbeitsblattüberschrift:
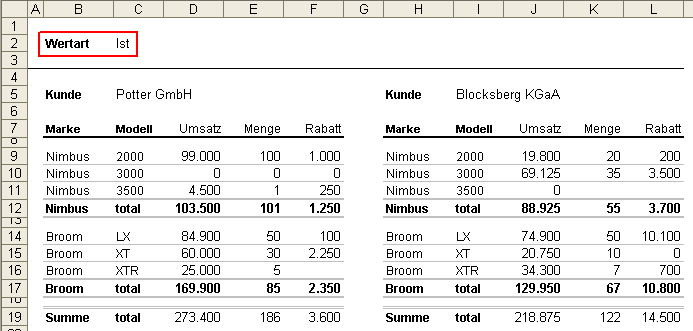
Die Wertart ist ein Merkmal, welches untrennbar mit den Daten verbunden ist und somit zwingend in die Ausgabedatensätze integriert werden muss.
Bis zu fünf solcher globaler Informationsfelder können neben Datei- und Tabellennamen hinterlegt werden. Dies geschieht einfach durch den Eintrag der Zelladresse, in der die jeweilige Information in der Quelltabelle zu finden ist. Wichtig ist, dass die Infofelder nur ein mal pro Arbeitsblatt gelesen werden.
Für obiges Beispiel mit der Wertart werden die Parameter wie folgt ausgefüllt:
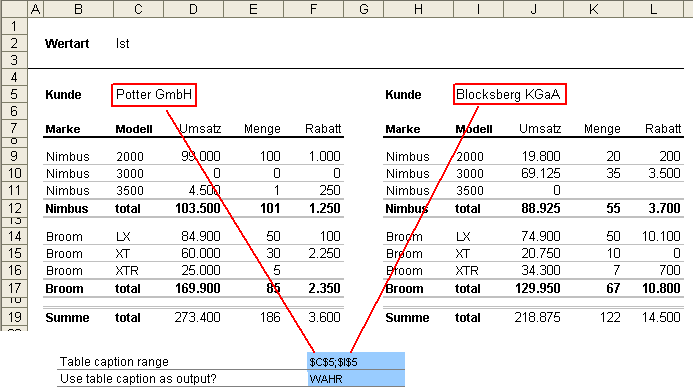
Nun müssen im Parameter “Table caption range” alle Tabellen identifiziert werden, die auf einem Arbeitsblatt zu konvertieren sind. Ja, richtig gelesen, es können sogar mehrere Kreuztabellen auf einem Arbeitsblatt konvertiert werden. Also neben Sodaspender auch noch Komfortsitze auf unserem Besen…
Aus den Zellen der ersten Tabelle wird eine Art Maske abgeleitet, die einfach auf jede andere Kreuztabelle übertragen wird (egal ob auf dem Arbeitsblatt, einem anderen Arbeitsblatt oder in einer anderen Datei). Zur Identifikation einer Kreuztabelle wird lediglich eine nichtleere Zelle herangezogen, welche in jeder Tabelle vorhanden ist. Von dieser Zelle ausgehend wird dann die oben erwähnte Maske errechnet, die auf jede Quelltabelle angewendet wird. Welche Zelle verwendet wird ist egal, üblicherweise wird die obere linke Zelle benutzt. Da die “Table caption” auch in den Datensatz ausgegeben werden kann, verwenden wir in unserem Beispiel den Kundennamen. Wenn nur eine Tabelle auf jedem Arbeitsblatt enthalten ist, wird in dem Parameter nur eine Zelle hinterlegt. Sind mehrere vorhanden, werden die Zelladressen durch ein Semikolon getrennt (siehe nächste Abbildung).
Im zweiten Parameter dieses Blocks kann der Inhalt der verwendeten Zelle an jeden Datensatz als Spalte angefügt werden. Auch hier sind wieder die booleschen Operatoren “WAHR” und “FALSCH” einzusetzen:
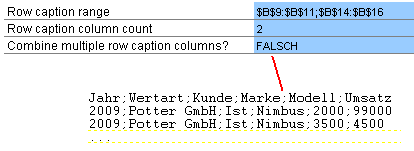
Anschließend folgen die Definition der Zeilen, sowie deren Überschriften. Im ersten Parameter des Blocks “Row caption range” werden alle Zeilen hinterlegt, welche exportiert werden sollen. Dies erfolgt in normaler Excel-Syntax: zusammenhängende Bereiche sind durch Doppelpunkt verbunden, getrennte durch Semikolon.
Man kann sich auch hier die Arbeit durch einen kleinen Zaubertrick vereinfachen. Man muss lediglich so tun, als würde man eine Excel-Verknüpfung einfügen. Durch Eingabe eines Gleichheitszeichens kann man Excel zur Mitarbeit bewegen und die betreffenden Zellen mit der Maus markieren. Anschließend kopiert man sich die Formel in einen Texteditor, entfernt die überflüssigen Zeichen (“=”, “[Mappe2]Tabelle1!”, …) und kopiert die übriggebliebenen Zelladressen zurück in das Parameterfeld. Hier eine Beispielbefüllung:
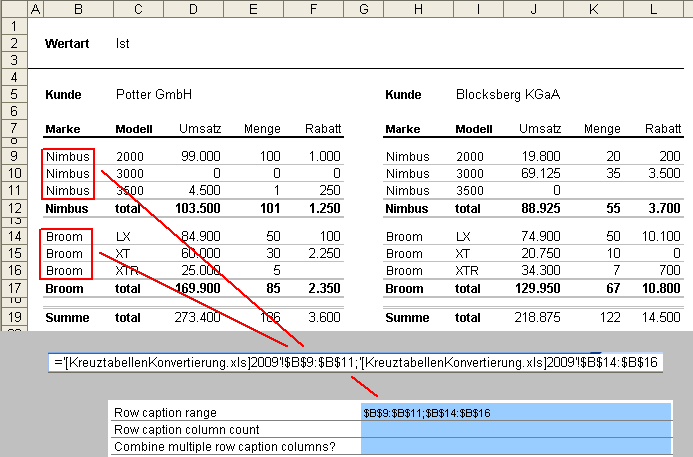
Wichtig ist, dass wieder nur die Koordinaten der ersten Tabelle und nur die erste Spalte der Zeilenüberschriften als Zellreferenz hinterlegt werden, auch wenn die Zeilenüberschriften über mehrere Spalten geschachtelt sind. Die Anzahl der Spalten wird im nächsten Parameter “Row caption column count” als normale Zahl hinterlegt. Sind die Zeilen nicht geschachtelt wird eine “1″ eingetragen.
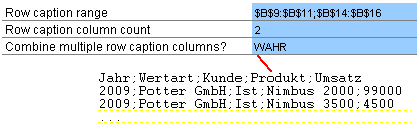
Der letzte Parameter des Blocks “Combine multiple row caption columns?” bestimmt, wie geschachtelte Zeilenüberschriften, welche auf mehrere Spalten verteilt sind, in den Zieldatensatz überführt werden. Es gibt zwei denkbare Szenarien. Entweder man möchte die Zeilenüberschriften zu einer Information im Zieldatensatz zusammenfügen (Parameter auf “WAHR”) oder man möchte sie getrennt ausgeben (Parameter auf “FALSCH”). Nehmen wir wieder unsere Beispieltabelle. In einer Zeilenüberschrift sind die Marken von Hexenbesen hinterlegt, in der zweiten die Modelle.
Szenario 1 würde die Inhalte kombinieren und zu folgendem Ergebnis führen:
Szenario 2 würde die Inhalte getrennt ausweisen und zu folgendem Ergebnis führen:
Analog zu den Zeilen müssen auch die Spalten definiert werden. Wiederum werden zunächst die Zellbereiche im Parameter “Column caption range” definiert (analog zu Parameter “Row caption range”). Auch hier ist nur die erste Zeile der Spaltenüberschriften zu verwenden. Im nächsten Parameter “Column caption row count” wird dann die Anzahl der Spalten definiert:
Die Wahl zwischen Kombination oder Trennung der Spalteninhalte ist hier nicht möglich. Die Inhalte werden immer kombiniert ausgegeben.
Der vorletzte Parameterblock bestimmt das Ausgabeformat der Textdatei. Fakteninformationen kann man in zwei gängigen Formaten speichern. Entweder wird pro Kennzahl eine getrennte Spalte generiert (Vorteil: wenig Datensätze, Nachteil: unflexibel zu verarbeiten) oder es gibt eine Spalte mit dem Kennzahlennamen und eine Spalte mit dem Kennzahlenwert. Im Parameter “Separated output column per source column” wird definiert, wie die Spalten ausgegeben werden. Wird der Parameter auf “WAHR” gestellt, wird jede Spalte der Quelltabelle auch in einer getrennten Spalte im Zieldatensatz ausgegeben (also analog zu dem ersten beschriebenen Format). Bei “FALSCH” wird das zweite Format generiert.
Folgende Beispiele mit der gewohnten Tabelle verdeutlichen die Wirkung des Parameters. Zunächst die Einstellung “WAHR”. Folgender Datensatz wird erzeugt:

Bei Konfiguration auf “FALSCH” wird folgender Datensatz ausgegeben:
Mit dem “Fixed string for output headline” wird schließlich die Überschrift für das Flatfile definiert. In Abhängigkeit von der zuvor beschriebenen Parametrierung wird hier entweder die komplette Überschrift hinterlegt oder die Überschrift bis zu den jeweiligen Spaltenüberschriften. Wird im vorherigen Parameter definiert, dass pro Quellspalte eine Spalte im Zieldatensatz generiert werden soll, ergänzt der Converter die Überschriften für die dynamisch ermittelten Spalten automatisch.
Um die Überschrift zu ermitteln, müssen einfach nacheinander alle Parameter, welche in den Zieldatensatz mit ausgegeben werden, geprüft und in der entsprechenden Reihenfolge eingetragen werden. Im einfachsten Fall sind das Zeileninhalt, Spalteninhalt und Kennzahlen. Im komplexesten Fall Inhalt Quelldateiname, Inhalt Arbeitsblattname, Inhalt Tabellenidentifikator, Inhalt Informationsfeld 1 – 5, Zeileninhalt, Spalteninhalt und Kennzahlen. In den zuvor gezeigten Beispielen sind jeweils die “Fixed strings” mit angezeigt und verdeutlichen die Funktionsweise.
Final kann im Parameter “Do export zero values?” noch definiert werden, ob Nullwerte exportiert werden sollen oder nicht. Auch hier wieder einfach “WAHR” oder “FALSCH” hinterlegen.
Hex, hex
Wenn alle Einstellungen vorgenommen sind, ist der Besen flugfertig. Nun fehlt nur noch die Betätigung des Knopfes “Start transformation” um allen Nicht-Magiern ein ungläubiges Staunen ins Gesicht zu zaubern:

Folgende Meldung quittiert den erfolgreichen Abschluss der Transformation:
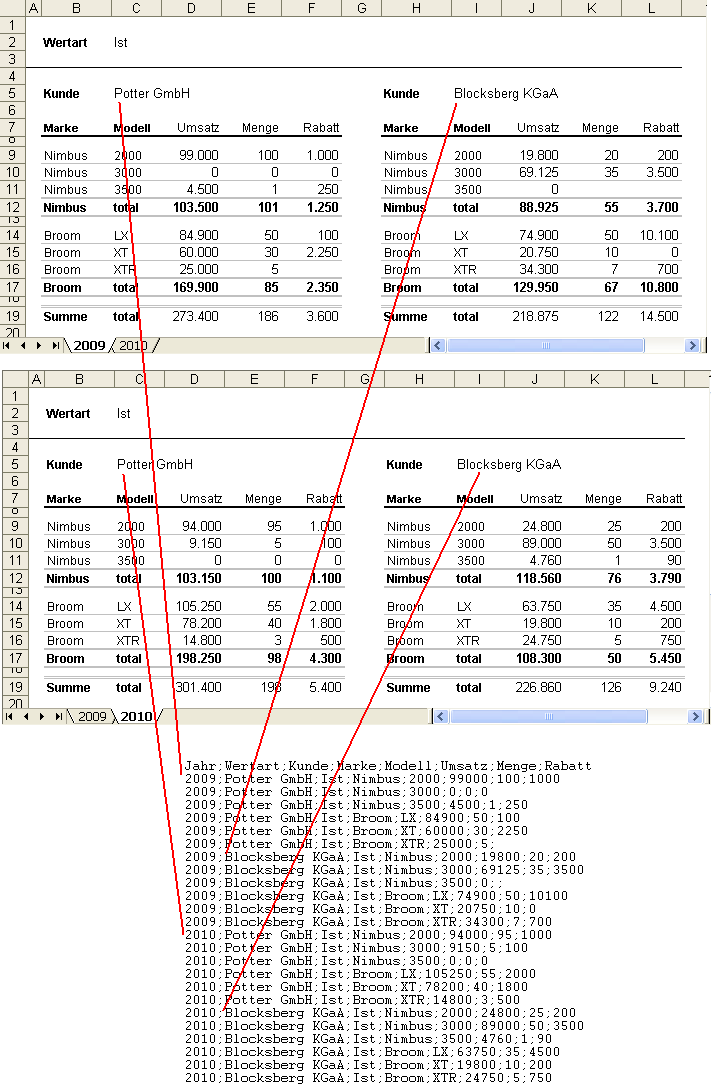
Abschließend hier noch mal die Basistabellen mit dem gesamten Output, konfiguriert mit der Ausgabe einer Spalte pro Kennzahl:
Das Zauberlexikon
Die Wahrscheinlichkeit, dass sie den ganzen Zauber wiederholen müssen ist relativ hoch. Entweder auf demselben Dateiformat oder auf einer komplett neuen Datei. Deswegen besteht im CrossTableConverter die Möglichkeit alle zuvor vorgenommen Einstellungen in einer Konfigurationsdatei abzuspeichern und später wieder zu laden. Die Konfigurationen werden in einer Datei mit der Endung CCC (= CrosstableConverterConfiguration) abgespeichert. Die beiden Knöpfe, um selbiges zu tun, sollten selbsterklärend sein:

Damit sind wir am Ende unserer kleinen Zauberstunde. Wenn auch Sie in den erlauchten Kreis der Magier aufgenommen werden wollen, sprechen Sie einfach Ihren Bissantz-Zauberer des Vertrauens an. Gern stellen wir Ihnen alle notwendigen Utensilien zur Verfügung.
Ach ja, um zum Großmagier aufzusteigen, muss man übrigens die Planung in Excel komplett hinter sich lassen. Denn DeltaMaster hält derart mächtige Planungszaubereien bereit, dass alles bisher Geschriebene davor verblasst. Stöbern Sie doch mal in unserem Online-Almanach nach den Geheimnissen der DeltaMaster Planung…
