Jetzt ist ein Würfel schon nach allen Regeln der Kunst modelliert, aber hier und da zwickt´s noch ein bisschen. Denn oftmals sehen sich die Anwender mit langen Abfragezeiten konfrontiert und die Berichte stehen nicht schnell genug zur Verfügung. Zum Glück bietet Microsoft Analysis Services hier und da ein paar Stellschrauben, um die Performance zu verbessern. Ein eigenes Tuning-Kit ist also mit an Bord.
Eine Leistungssteigerung erreicht der MS SSAS durch vorher berechnete Ergebnisse im Cubespeicher, da die Daten aus der Datenbank nicht bei jeder Abfrage erneut berechnet werden müssen.
Um die effektivsten Aggregationen für die Abfrage-Arbeitsauslastung auszuwählen, werden die Aggregationen entworfen. Dabei gilt es zu beachten, dass die Abfragevorteile von Aggregationen im Vergleich zum Zeitaufwand für das Erstellen und Aktualisieren der Aggregationen berücksichtigt werden. Die Abfragezeit kann sich auch verschlechtern, wenn z.B. nicht benötigte Aggregationen hinzugefügt werden. Merkmalskombinationen, welche selten verwendet werden, landen so im Dateicache und andere Elemente werden dadurch entfernt.
Um Aggregationen zu entwerfen, muss das SQL Server Business Intelligence Development Studio mit dem Würfel verbunden sein. Die Reiterkarte Aggregationen zeigt die einzelnen Measuregruppen des Würfels.
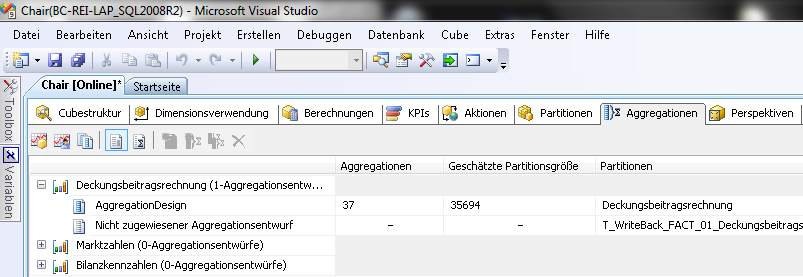
Durch Rechtsklick auf eine Measuregruppe finden sich im Kontextmenü zwei Einträge:
- Aggregation entwerfen
- verwendungsbasierte Optimierung
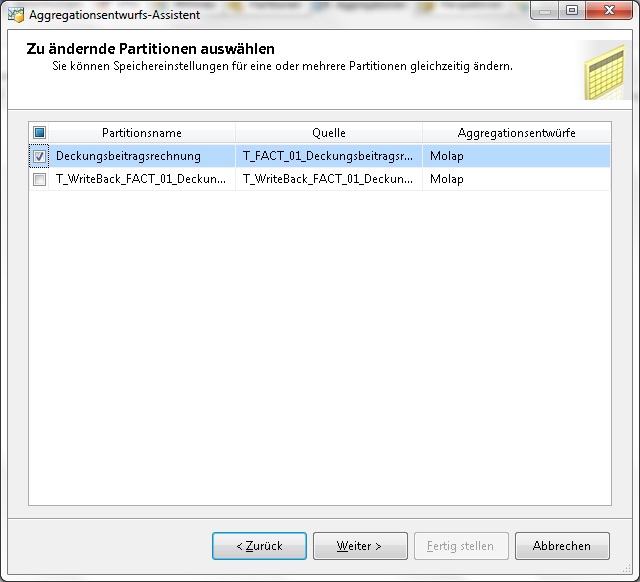
Im ersten Schritt soll eine Aggregation entworfen werden. Dazu wird die zu verwendende Partition ausgewählt:
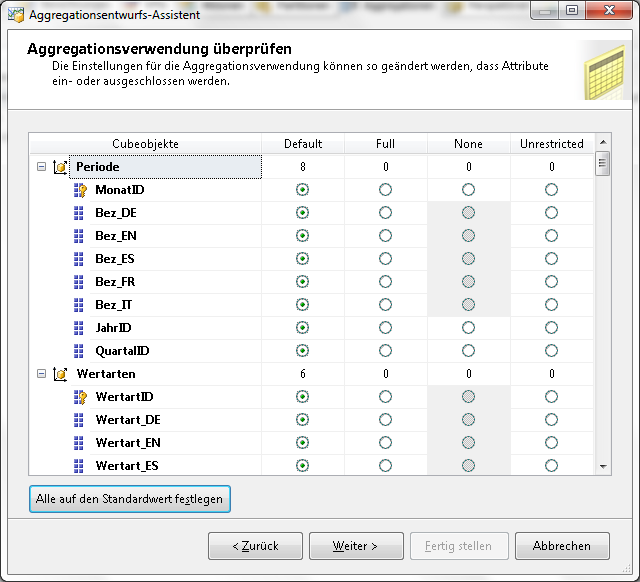
Im Fenster Aggregationsverwendung kann im Normalfall die Einstellung auf Default verbleiben. Hierbei wird eine Standardregel basierend auf dem Typ des Attributs und der Dimension angewendet. Eine Beschreibung der weiteren Optionen findet sich unter
- Standard
Wählen Sie diese Option aus, um die Einstellung der Aggregationsverwendung für das Attribut auf den Standard festzulegen. Bei dieser Einstellung wendet der Designer eine Standardregel basierend auf dem Typ des Attributs und der Dimension an.
- Vollständig
Wählen Sie diese Option aus, um die Aggregationsverwendung für das Attribut auf Full festzulegen. Bei Verwendung dieser Einstellung muss jede Aggregation für den Cube dieses Attribut oder ein verknüpftes Attribut enthalten, das sich weiter unten in der Attributkette befindet. Die Einstellung Full für die Aggregationsverwendung sollte vermieden werden, wenn ein Attribut viele Elemente enthält. Falls diese Einstellung für mehrere Attribute oder für Attribute definiert ist, die über viele Elemente verfügen, kann hierdurch aufgrund einer Größenüberschreitung der Entwurf von Aggregationen verhindert werden.
- Keine
Wählen Sie diese Option aus, um keine Aggregationsverwendung für das Attribut festzulegen. Wird diese Einstellung verwendet, kann keine Aggregation für den Cube dieses Attribut enthalten.
- Uneingeschränkt
Wählen Sie diese Option aus, um die Aggregationsverwendung für das Attribut auf Unrestricted festzulegen. Bei Verwendung dieser Einstellung werden keine Einschränkungen auf den Aggregations-Designer angewendet, das Attribut muss aber dennoch ausgewertet werden, um festzustellen, ob es sich um einen wertvollen Aggregationskandidaten handelt.
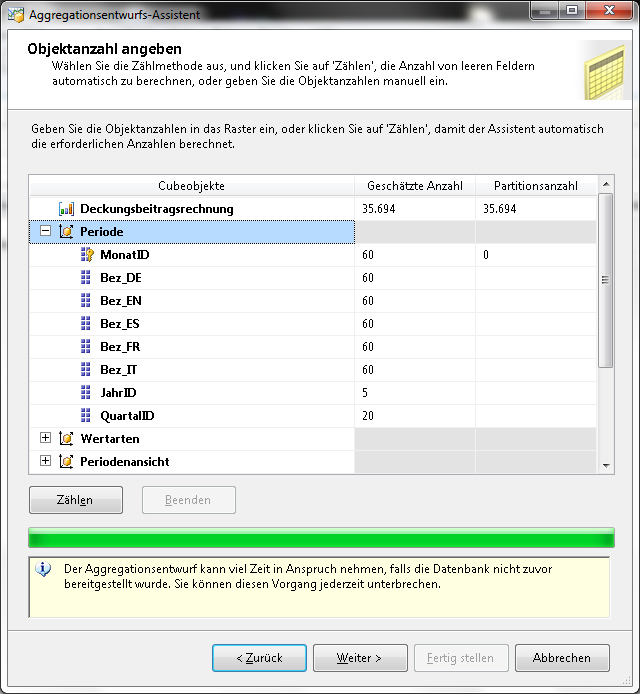
Im darauffolgenden Fenster wird die geschätzte Anzahl der Objekte angezeigt. Es muss eine geschätzte Anzahl der Zeilen in der Measuregruppe und die Anzahl der Attributelemente in den Dimensionen eingegeben werden. Dieser Schritt kann manuell erfolgen oder automatisch durch MS SASS.
Im Dialog Aggregationsoptionen festlegen können folgende Einstellungen getroffen werden:
- Geschätzter Speicherplatz erreicht
Es kann ein Limit in Megabyte (MB) oder Gigabyte (GB) festgelegt werden, wann die Generierung von Aggregationen beendet werden soll
- Leistungsgewinn erreicht
Es kann ein Limit (maximaler Prozentsatz des Leistungsgewinns) festgelegt werden.
- Es wird auf ‘Beenden’ geklickt
Das Limit kann bestimmt werden, wenn während des Entwurfs Beenden geklickt wird.
- Keine Aggregationen entwerfen (0 %)
Hier können vorhandene Aggregationsentwürfe gelöscht werden.
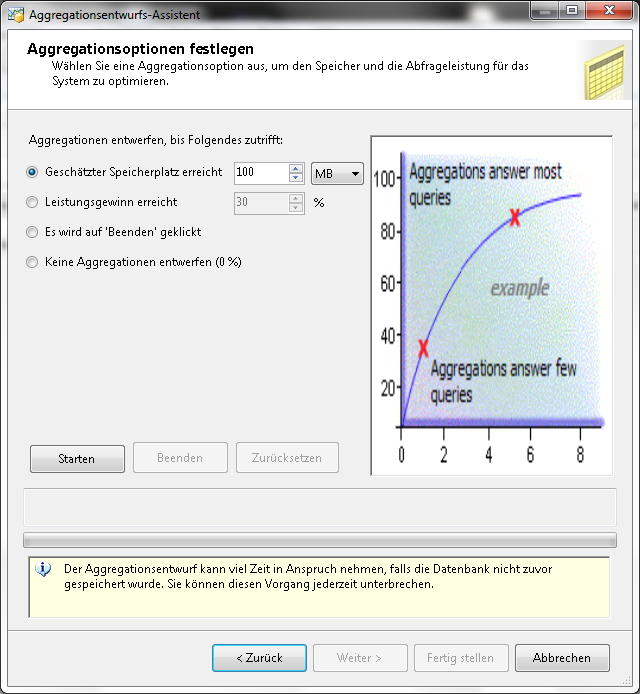
Durch Starten werden die Aggregationen berechnet.
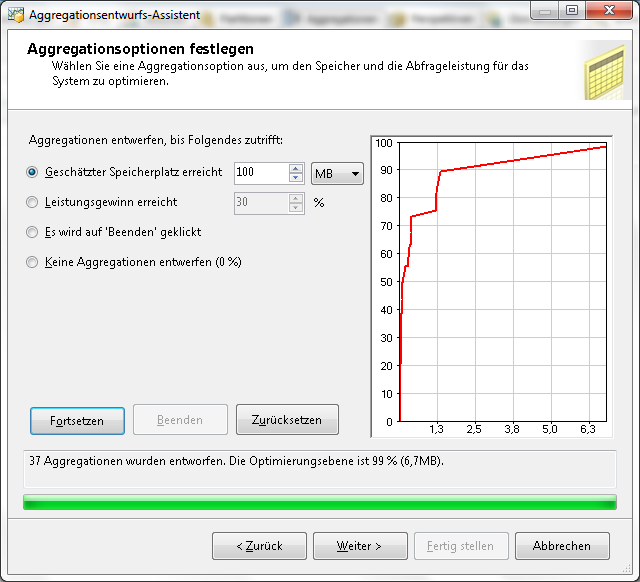
Diesem Aggregationsentwurf kann jetzt noch ein individueller Name gegeben werden. Um die Aggregation nutzen zu können, muss diese verarbeitet werden. Das kann nach dem Erstellen oder aber zu einem späteren Zeitpunkt geschehen.
Neben diesem automatischen Ansatz kann auch eine verwendungsbasierte Aggregation stattfinden. Dabei werden sämtliche Anfragen an den MS SSAS in einer Log-Tabelle mitgeschrieben und aus dieser Datenbasis bzw. Teile der Daten können Aggregationen auf bestimmte Verwendungsmuster ausgerichtet werden. Hierzu sind folgende Einstellungen in den Eigenschaften für Analysis-Server zu treffen:
- Der Wert Log \ QueryLog \ CreateQueryLogTable muss auf True gesetzt werden
- Unter Log \ QueryLog \ CreateQueryConnectionString wird die Datenbank eingetragen, in der die Tabelle OlapQueryLog angelegt werden soll. In diese Tabelle werden die Abfragen geloggt:
Um nun verwendungsbasierte Aggregationen zu erstellen muss im Kontextmenü der Measuregruppe des Würfels die verwendungsbasierte Optimierung ausgewählt werden. Auch hier muss die Partition angegeben werden, für welche die Aggregationen vorberechnet werden sollen. Nun besteht die Möglichkeit, die Abfragekriterien festzulegen:
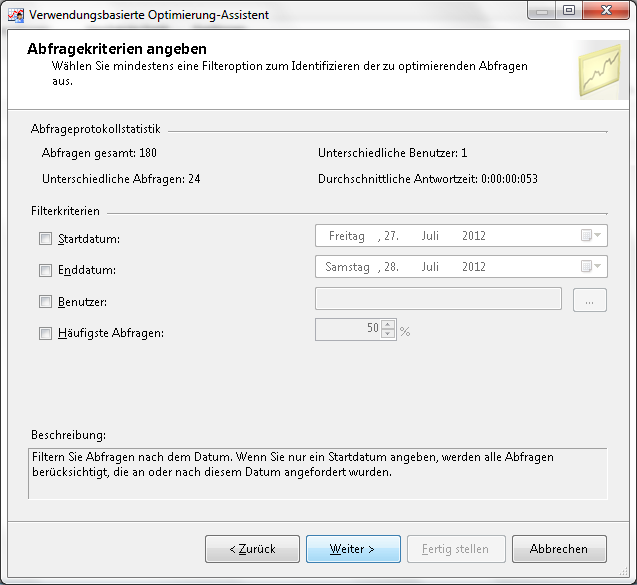
- Startdatum
Die Abfragen im Protokoll werden anhand des Startdatums und der Startzeit gefiltert.
- Enddatum
Die Abfragen im Protokoll werden anhand des Enddatums und der Beendigungszeit gefiltert.
- Benutzer
Die Abfragen können nach einzelnen oder mehreren Benutzern gefiltert werden.
- Häufigste Abfragen
Die Abfragen werden nach dem höchsten Prozentanteils der am meisten ausgeführten unterschiedlichen Abfragen gefiltert.
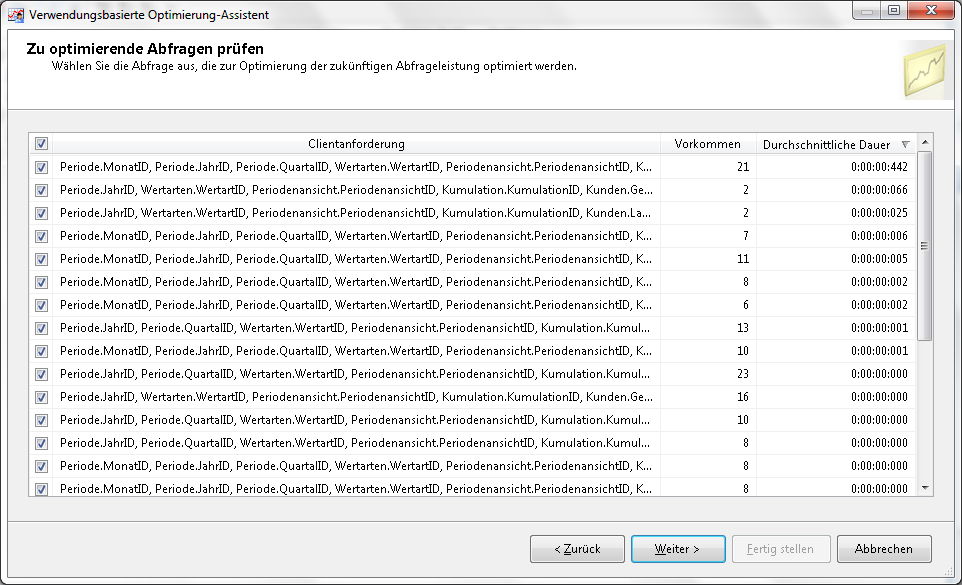
Der Dialog Zu optimierende Abfragen prüfen zeigt die Abfragen aus dem Protokoll. Hier können einzelne Abfragen, die nicht zur Aggregation herangezogen werden sollen, noch abgewählt werden.
Die Vorgehensweise ist ab hier analog zu der zuvor beschriebenen Erstellung einer Aggregation.
