Die Nutzung von Partitionen zur Verbesserung der Abfrageperformance in Microsoft Analysis Server Modellen ist sicherlich jedem Berater/-in bekannt und wird auch intensiv in unseren Projekten genutzt.
Damit dieses Feature wunschgemäß arbeitet, bedarf es allerdings einer genaueren Betrachtung, da es dabei doch einige Dinge zu beachten gilt und dort der eine oder andere Stolperstein lauert.
Ausgangslage
Die Datenbank ist nach bestem Wissen und Gewissen aufgebaut, sämtliche Anforderungen an die Modellierung zur Abbildung der Kundenwünsche sind umgesetzt und nun geht es munter an die ersten Performancetests und Berichte in DeltaMaster.
Gerade bei großen Modellen oder speziell in Planungsprojekten kommt es auf jede Möglichkeit zur Optimierung an, damit die Antwortzeiten hervorragend sind und bleiben.
Ein großer Hebel kann hier die Partitionierung innerhalb einer Measuregruppe sein. Damit diese Partitionen auch performant sind und vor allem die richtigen Daten liefern, bedarf es einiger Sorgfalt.
Partitionen in Analysis Services
Im Folgenden werden wir uns dem Thema zunächst allgemeingültig über die allseits bekannte Adventure-Works-Datenbank von Microsoft nähern. In der Measuregruppe „Internet Sales“ sind 4 Partitionen nach den Jahren 2005-2008 definiert worden.
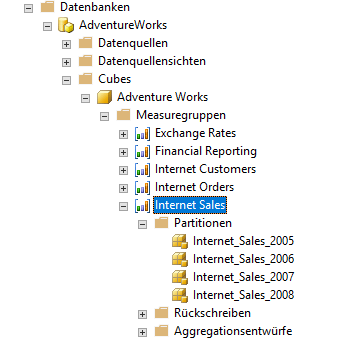
Abbildung 1: Measuregruppe Internet Sales
Damit die ganze Analyse nicht durch den Cache verfälscht wird, machen wir die Abfrage mit einem frisch gelöschten Cache:
<ClearCache >="https://docs.microsoft.com/en-us/openspecs/sql_server_protocols/ms-ssas/68a9475e-27d6-413a-9786-95bb19652b19"> <Object> <DatabaseID>AdventureWorks</DatabaseID> <CubeID>Adventure Works</CubeID> <MeasureGroupID>Fact Internet Sales 1</MeasureGroupID> </Object> </ClearCache>
Mit Hilfe einer simplen Abfrage auf ein Measure und einen Monat im Jahr 2008 wollen wir uns davon überzeugen, dass die Partitionierung dafür sorgt, dass der Server erwartungsgemäß auch nur in die 2008 Partition greift.
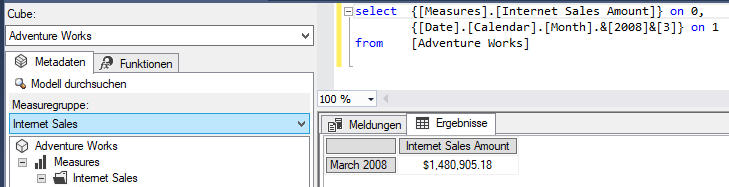
Abbildung 2: MDX Abfrage für einen Monat
Der geneigte Leser erwartet sicherlich über die Ablaufverfolgung im Profiler eine einzige Abfrage zu sehen. Doch weit gefehlt, der Server liest sämtliche Partitionen aus, obwohl in der Abfrage explizit ein Monat aus 2008 angegeben wurde.
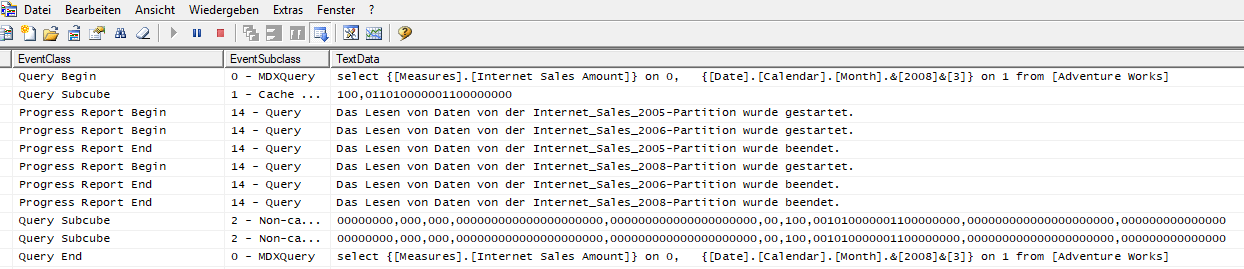
Abbildung 3: SQL Profiler Ergebnis
Das ist nicht das gewünschte Ergebnis und widerspricht im Grunde dessen, was wir gemeinhin von einer Partitionierung nach Jahren erwarten würden. Das Problem ist, dass der Server nicht weiß in welcher Partition welche Daten vorhanden sind. Der Monat könnte in allen Partitionen vorhanden sein, daher wird „sicherheitshalber“ auch jede Partition abgefragt.
Also machen wir uns auf die Suche, was hier passiert sein könnte. In den Eigenschaften für die Partition sieht alles ganz gut aus, allerdings ist hier kein Slice explizit angeben worden.
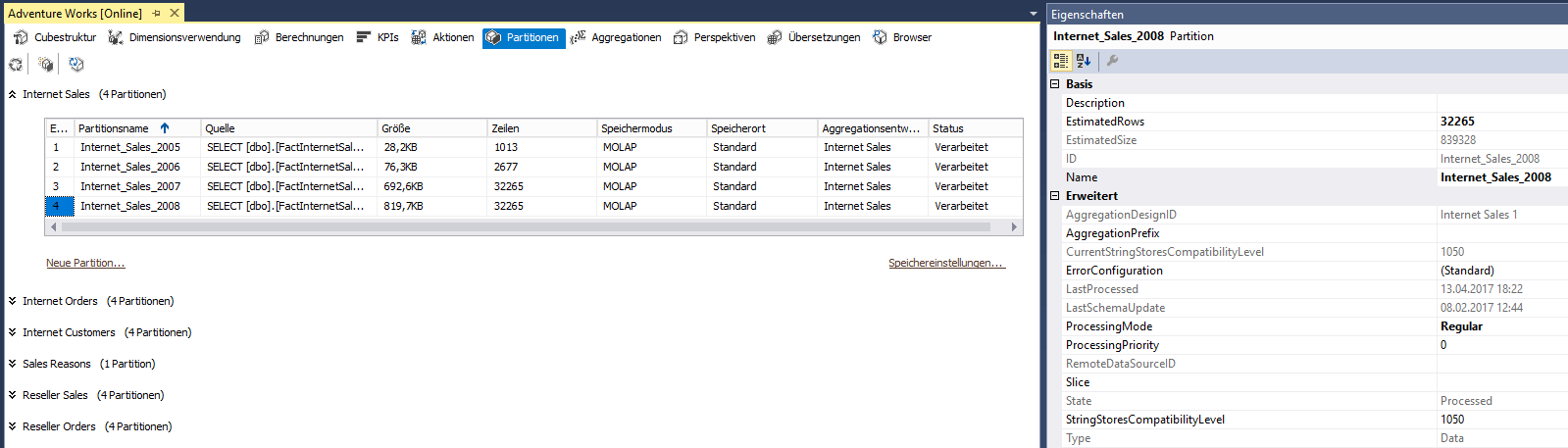
Abbildung 4: Eigenschaften der Internet_Sales_2008 Partition
Wenn kein expliziter Slice angegeben wird, so werden für SSAS Partitionen vom System automatische Daten Slicer angelegt. Diese Automatik unterliegt einigen Restriktionen.
Im konkreten Fall wurde kein automatischer Slice erstellt, weil die Anzahl der Zeilen in der Partitionstabelle zu klein war. Den Schwellwert dafür kann man in der Datei msmdsrv.ini (Program FilesMicrosoft SQL ServerOLAPConfig ) über die „IndexBuildThreshold“ Eigenschaft ändern. Der Default Wert ist 4096, was bedeutet, dass bei Partitionen mit weniger als 4096 Datensätzen kein automatischer Slicer erzeugt wird.
Dies ist allerdings nicht unser präferierter Weg, sondern wir setzen in unseren Projekten die Slice Eigenschaft explizit. Dazu mehr im nächsten Kapitel.
Slices innerhalb von Partitionen
„Ein Datenslice ist eine wichtige Optimierungsfunktion, die Ihnen dabei hilft, Abfragen an Daten der entsprechenden Partitionen weiterzuleiten. Das explizite Festlegen der Slice-Eigenschaft kann die Abfrageleistung verbessern, indem die für MOLAP- und HOLAP-Partitionen generierten Standardslices überschrieben werden. Darüber hinaus bietet die Slice-Eigenschaft bei der Verarbeitung der Partition eine zusätzliche Überprüfungsmöglichkeit.“[1]
Schauen wir uns ein Beispiel aus der bekannten ChairInternational an und betrachten die vorhandenen Partitionen.
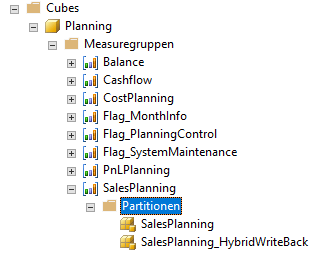
Abbildung 5: Partitionen der Datenbank
Aus Performancegründen versucht man bekanntermaßen bei einer Planung die Partitionen in reine Lese- und Schreibpartition aufzuteilen. Zur Vereinfachung betrachten wir nur die Slices der beiden Partitionen. Die erste Partition enthält die Ist-Daten mit Valuetype 1 (Actual) und Valuetype 20 (Projektion).
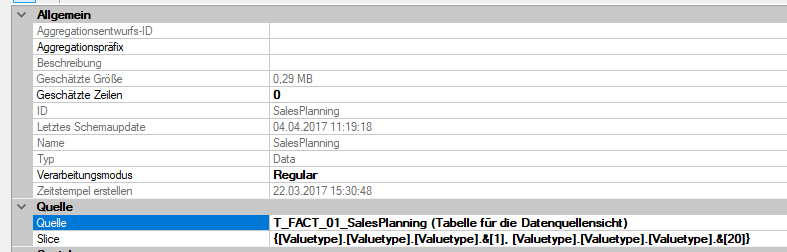
Abbildung 6: Partition SalesPlanning
In der nächsten Partition sind die Plandaten enthalten mit Valuetype 2 (Budget) und Valuetype 30 (YearToEnd). Der Slice zeigt auf die beiden Plan Valuetypen, alles sieht soweit korrekt aus.
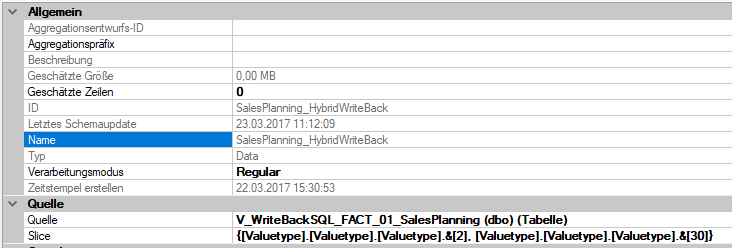
Abbildung 7: Partition SalesPlanning_HybridWriteBack
Schauen wir doch über den View auf die Faktentabelle sicherheitshalber nach, wo wirklich (physikalisch) Daten vorhanden sind.
Im PlanningCycle 2017 werden die Monate 201701 bis 201712 geplant und im PlanningCycle 2018 die Monate 201801-201812.
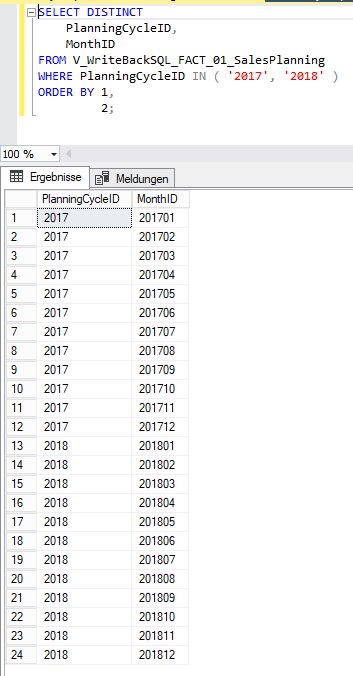
Abbildung 8: V_WriteBackSQL_Fact01_SalesPlanning
Gehen wir ins Frontend und prüfen, welche Daten uns in DeltaMaster angezeigt werden.
In den Zeilen stehen die einzelnen Monate für 2017 und 2018 und in den Spalten stehen die beiden PlanningCycle 2017 und 2018. Alles prima, so soll es sein.
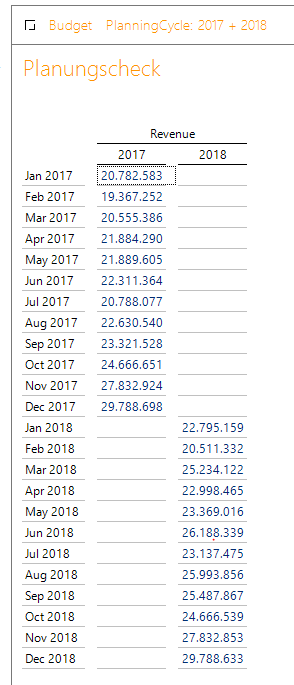
Abbildung 9: DeltaMaster Checkbericht I
Nun könnte man aus modellierungstechnischen Gründen auf die Idee kommen, dass eine Trennung in einzelne PlanningCycle Sinn machen könnte. Schränken wir doch den Slice mal nur auf Planning-Cycle 2017 ein und prüfen das Ergebnis in DeltaMaster.
![]()
Abbildung 10: Geänderter Slice auf PlanningCycle 2017
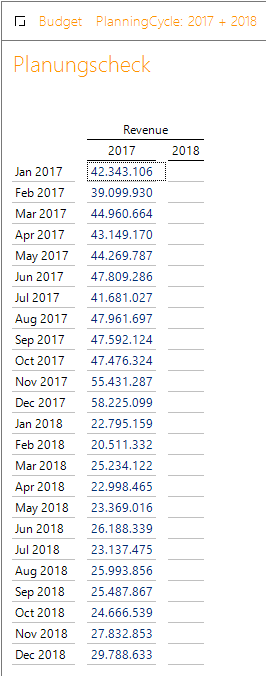
Abbildung 11: DeltaMaster Checkbericht II
Das entspricht nicht dem erwarteten Ergebnis. Der Analysis Server „beamt“ die Daten, die physikalisch in den Monaten des Jahres 2018 stehen, vom PlanningCycle 2018 auf den PlanningCycle 2017.
Erst wenn beide PlanningCycle im Slice stehen, ist die Zuordnung wieder korrekt.
![]()
Abbildung 12: Erweiterter Slice mit beiden PlanningCycle
Nun sind auch in DeltaMaster die Daten wieder korrekt.
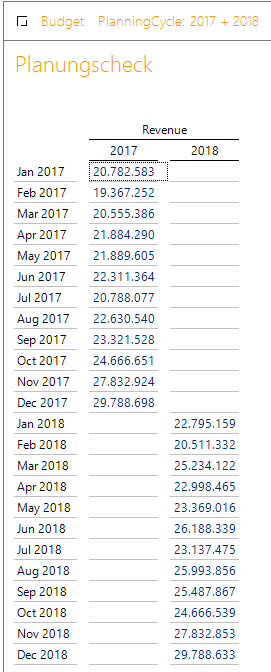
Abbildung 13: DeltaMaster Checkbericht III
Aus der Projekterfahrung wissen wir, dass Partitionen ein mächtiges Optimierungswerkzeug sein können. Die Erkenntnisse aus diesem Blogbeitrag zeigen, dass dies mit Bedacht eingesetzt werden sollte und gerade die Slices eine entscheidende Rolle spielen.
Im Zweifel lieber einmal mehr testen und ggf. über die Erzeugung von dynamischen Slices per XMLA nachdenken, damit eine Anwendung zukunftssicher und stabil bleibt. Dazu mehr in einem späteren Artikel.
[1] https://docs.microsoft.com/de-de/sql/analysis-services/multidimensional-models/set-the-partition-slice-property-analysis-services
