Hype oder nicht, Big Data ist die Auferstehung des Data Mining und die war überfällig. Das bringt neuen Schwung in die datengetriebene Unternehmenskultur. Für die gilt unser Schlachtruf: Sehen, verstehen, handeln. Wissen allein genügt uns nicht. Auf geht’s! Damit der Hype kein Flop wird.
Anhänger einer datengetriebenen Unternehmenskultur zittern derzeit, vor Angst und Freude gleichermaßen. Nie zuvor war die Begeisterung für Datenauswertung größer, nie zuvor waren die Erwartungen höher. Professor Peter Mertens hat 1995 und 2005 die Moden und Trends in der Wirtschaftsinformatik untersucht, die Bedeutung kumulativer Anstrengungen betont und benannt, was auch guten Ideen droht, wenn die Begeisterung zu früh nachlässt. Dr. Gerald Butterwegge, mein Kollege damals und heute, half bei Datenbeschaffung und –auswertung. Google gab es damals nicht, das Internet steckte in den Kinderschuhen, Auswerten bedeutete, tagelang in der Bibliothek zu sitzen, Zeitschriften durchzublättern und Strichlisten auf Papier zu führen. Ich forschte damals zum Data Mining und war mit meinem Thema damit im Zentrum eines Hypes.
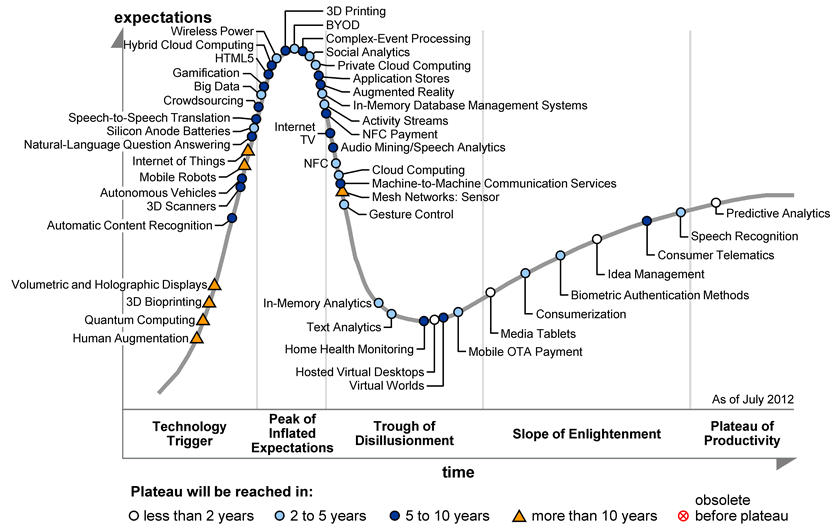
Ist Big Data die Wiederbelebung des Data Mining und gehört auf das Plateau der Produktivität oder ist das Tal der Enttäuschung nahe, wie es Gartner sieht? Ich finde, das hat man selbst in der Hand. Quelle: Gartner.
Anklicken zum Vergrößern.
Mertens sagt: Es braucht „Forschungsruhe“ und langfristige, ununterbrochene Lernkurven, wenn das Werk gelingen will. Hypes führen regelmäßig dazu, dass solide Erfolge außerhalb der Mode unbeachtet bleiben, man Scheinfortschritte vortäuscht („Alter Wein in neuen Schläuchen“) und Ressourcen vergeudet.
Deutet man Big Data als Wiederbelebung des Data Mining, dann könnten wir uns jetzt in der Phase der Produktivität befinden und zufrieden fortschreiten. Aber Vorsicht! Ein Motto der Forschung bei Mertens war stets: „Zufriedenheit ist die Feindin des Fortschritts“. Damit halten wir es lieber auch jetzt, wähnen Big Data vorsorglich auf dem Höhepunkt überzogener Erwartungen und grübeln, wie das Tal der Enttäuschung umgangen werden kann.
Inzwischen kennt die Euphorie kaum noch Grenzen, vielleicht auch weil Big Data den Sprung aus der IT-Presse in die Tageszeitungen geschafft hat. Der Eindruck, der dort beim eiligen Leser entsteht, ist: Man hat so viele Daten wie nie zuvor, da ist alles Wissen drin und jetzt gibt es auch die Software und Hardware dazu, um ganz automatisch dieses Wissen zu heben. Dieses Wissen wiederum verändert dann alles.* Nun ja. Wenn Software und Hardware nicht ungemein helfen würden, gäbe es keinen Grund für diesen Blog. Auf die Fortschritte in diesem Bereich lassen wir nichts kommen, nach all der eigenen Mühe damit und einigen Preisen und Patenten dafür. Jedoch, die Herausforderung an Big Data ist weniger das „Big“ als das „Data“.
Lassen wir einen Augenblick Phrasen und Phasen weg. Worum muss es gehen, wenn man sich mit Daten abplagt? Welche Erfahrungen haben wir die letzten 20 Jahre gemacht, wozu können wir raten? Welche Vorurteile im Big-Data-Hype könnten in die Irre führen? Wir möchten das anhand von Fallbeispielen erläutern.
Fallbeispiel 1: Der Mensch kann die Welt mit Daten erklären, aber Daten können dem Menschen nicht die Welt erklären.
Im Auftrag eines Pharmariesen nahmen wir uns die Daten seines gewaltigen Außendienstes vor. Uns interessierten vor allem die regionalen Marktanteile für eine Handvoll Präparate und die Besuchsfrequenz des Außendienstes. Im Pharmavertrieb geht man davon aus, dass die Besuchsfrequenz bei den Ärzten einen positiven Einfluss auf den Marktanteil hat. Wir waren im Daten-Schlaraffenland: Interne und externe Daten waren leicht verfügbar und wurden zusammengeführt, alle üblichen Formathürden wurden im Eilschritt genommen.
Dann der erste Blick auf die Daten. Er offenbarte bereits, was Data-Mining‑ und Statistik-Verfahren später nur bestätigten konnten: Kein Zusammenhang zwischen Besuchsfrequenz und Marktanteil! Die Informatiker und Statistiker im Team waren geschockt. Sie fragten sich: Wie kann eine ganze Branche Heerscharen von Außendienstlern nach Marktanteilen provisionieren – wo doch die Daten überdeutlich zeigen, dass Besuchsfrequenz und Marktanteil nicht korrelieren? Sollte man allen Ernstes ein neues Provisionsmodell vorschlagen? Worauf könnte es fußen, auf der absoluten Anzahl der Besuche, sozusagen auf dem Fleiß? Das klang alles nicht plausibel. Am besten gar nichts mehr empfehlen. Mit gesenktem Haupt war man drauf und dran, eine datenanalytische Niederlage einzugestehen. Trotz bester Methodik, schneller Rechner, sauberer Daten, sogar aus verschiedenen Quellen, Big Data reinster Prägung gewissermaßen. Nur das Ergebnis schien nicht Big.
Die Betriebswirte im Team konnten die Kollegen beruhigen. Die Lösung ist: Wenn die Besuchshäufigkeit eine Rolle spielt, dann auch die Besuchshäufigkeit der Konkurrenten, ergo kann der eigene Marktanteil ohnehin nur die relative Besuchshäufigkeit widerspiegeln. Hat man Marktanteile verloren, dann war der Kollege vom Wettbewerb öfter da. Da man die Einsatzpläne der Konkurrenten nicht kennt, ist die eigene Besuchshäufigkeit eine Variable und die sorgfältige Beobachtung der eigenen Marktanteile hilft dabei, sie zu justieren.
Angesichts solcher Erfahrungen sollte einem ein wenig blümerant werden, wenn in der Begeisterung für Big Data die Daten allzu freudig zum Subjekt, Botschafter, Lehrer und Erklärer und am Ende zum Boss erklärt werden. Man lasse die Manager im Fahrersitz, auch wenn es um Big Data geht.
Fallbeispiel 2: Warum in der Informationsflut oft genau die Daten fehlen, die man braucht, und man gute Daten manchmal selbst erzeugen muss
Der Kostenstellencontroller eines Betriebs, in dem massenhaft Müll aus unterschiedlichsten Quellen anfällt, vermutete Kostensenkungspotenzial durch Investitionen in eine noch sorgfältigere Mülltrennung. Er zog sich einen Blaumann an, nahm ein Klemmbrett und machte sich auf den Weg zur Frühschicht. Sein Ziel war, den händischen Prozess der Mülltrennung zu beobachten, Zeiten zu erfassen, Sorten und Mengen zu zählen und sich eine statistische Basis für seine anschließenden Analysen zu schaffen. Was er dabei erlebte, lässt mich noch vehementer nach Informationssystemen streben, die Vorstände stärker mit dem verzahnen, was wirklich passiert. Die Werker vermuteten das Schlimmste und machten dem tapferen Kostenstellencontroller das statistische Leben schwer. Die Vermutung der Basis: Da will einer aufs Tempo und auf den Lohn drücken. Die Mittel der Gegenwehr waren Blockade, milde Formen von Sabotage und weniger milde Formen von Mobbing. Der Kostenstellencontroller bediente sich aller psychologischen Tricks, die er kannte, um erst einige Anführer zu überzeugen und schließlich zur Mithilfe zu bewegen. Am zweiten und dritten Tag lief die Sache besser und irgendwann verbreiteten die verbesserten Abläufe auch Freude. Als die Daten standen, zeigte die anschließende Analyse auch Erfreuliches für das Gesamtunternehmen: Eine Million Euro pro Jahr Kosteneinsparung konnten realisiert werden.
Mir gefällt diese Anekdote außerordentlich und sie macht etwas Wichtiges deutlich: Man sollte nicht den Blick dafür verlieren, dass in Unternehmen Daten nicht der Zweck, sondern das Mittel dazu sind. An den Anfang jeder Datenanalyse gehören nicht die Analysedaten, sondern der Analysezweck.
Mehr Fallbeispiele das nächste Mal.
* Vgl. statt vieler: „Big Data! Die nächste Revolution“, WAMS vom 03.03.2013, S. 52.

{kind=link}