Ein Personaldienstleister möchte seine Bewerber auswerten. Bewerber können sich auf eine offene Stelle oder initiativ in einem Portal registrieren, werden dann von den Niederlassungen überprüft – und bald mit DeltaMaster von Marketing, der Personalabteilung, dem Vertrieb und den Niederlassungsleitern ausgewertet. Allerdings liefert das Vorsystem täglich nur den heutigen Stand eines Bewerbers, ohne dass ersichtlich ist, ob gestern ein Wechsel seiner Eigenschaften stattgefunden hat. Um Zeitperiodenvergleiche oder einen historischen Bestand auswerten zu können, müssen die Daten also erstmal historisiert werden. Wie das funktioniert, wird in diesem Beitrag beschrieben.
Ein Bewerberdatensatz hat mehrere Eigenschaften, z. B. eine BewerberID, ein Registrierungsdatum, eine Niederlassungszuordnung [z. B. Fulda, Darmstadt, Nürnberg, …], eine Qualifizierung [A, B, C], eine Art Gehaltsstufe (Entgeltgruppe) [1-9] und einen Status [wait, in, abgesagt, out].
Die Marketingabteilung will die Qualität ihrer Werbekampagne bewerten und wissen, wie viele Bewerber einer bestimmten Entgeltgruppe sich in einer bestimmten Region neu registriert haben (Kennzahl „Anzahl_neue_Bewerber“ in Fulda in KW 12/2016), der Vertrieb möchte wissen, wie viele Bewerber mit bestimmten Eigenschaften befinden sich gerade im Zugriff (Bestandskennzahl „Bewerber“ in Darmstadt, unabhängig vom Datum der Registrierung); weitere Anforderungen werden sicherlich folgen.
Die Daten des Vorsystems waren schnell in den bestehenden SQL-Server importiert und die Dimensionen aus den genannten Eigenschaften und Kennzahlen schnell modelliert. Fehlten nur noch historische Daten zum Befüllen und eine Prozedur P_APP_Historisierung_Bewerber die folgendes macht:
-
- Die Daten des Vorsystems werden per SSIS in die Tabelle T_Import_Bewerber_täglich geladen

Tabelle 1: Datenlieferung in T_Import_Bewerber_täglich vom 20.4.2016
- Alle neuen BewerberIDs, die noch nicht in der Historisierungstabelle T_D_Bewerber_Archiv enthalten sind, werden hinzugefügt. Dabei bekommen die Kennzahlen Anzahl_neue_Bewerber und Anzahl_Bewerber_Stichtag
jeweils den Wert 1.

Tabelle 2: Importergebnis neuer Bewerber in die Archivtabelle T_D_Bewerber_Archiv
- Alle Bewerber, die bereits in der Archivtabelle enthalten sind, aber einen anderen Status haben (im Beispiel ist der Bewerberstatus jetzt 2, vorher 1), müssen ebenfalls eingetragen werden. Weil sie vorher bereits enthalten waren (BewerberID 4711), wird die Kennzahl Anzahl_neue_Bewerber mit 0 importiert, die Kennzahl Anzahl_Bewerber_Stichtag mit 1.

Tabelle 3: Datenlieferung in T_Import_Bewerber_täglich vom 21.4.2016

Tabelle 4: Neu hinzugefügter Eintrag in Archivtabelle T_D_Bewerber_Archiv
- Der Blick auf die Archivtabelle zeigt, dass sich Bewerber 4711 am 1.4.16 sowohl im Bewerberstatus 1 als auch im Bewerberstatus 2 befindet. In Wirklichkeit ist der Bewerber allerdings aus Bewerberstatus 1 ausgetreten und befindet sich nur noch in Bewerberstatus 2. Deshalb muss der vorherige Eintrag ausgebucht werden. Dazu wird folgender neue Eintrag in die Archivtabelle geschrieben:

Tabelle 5: Ausbuchungsvorgang in T_D_Bewerber_Archiv
- Die Daten des Vorsystems werden per SSIS in die Tabelle T_Import_Bewerber_täglich geladen
Die Modellierung der Kennzahlen im Modeler erfolgte bei Anzahl_neue_Bewerber als Summenkennzahl und bei der Stichtagskennzahl als „LastNonEmpty“. So ist gewährleistet, dass eine Auswertung des Bewerbers 4711 bis zum 20.04.2016 mit seinen bis dahin geltenden Eigenschaften gewertet wird.
Die Prozedur, die die Historie erstellt, läuft nächtlich im P_Sys_Preprocess. Um zu vermeiden, dass mehrfache Ein- oder Ausbuchungen an einem Tag passieren, werden in der Prozedur zu Beginn alle Einträge mit heutigem Registrierungsdatum gelöscht. So kann die Prozedur bei Bedarf auch mehrmals täglich angestoßen werden und ist immer noch konsistent.
Und so sieht sie in T-SQL aus:
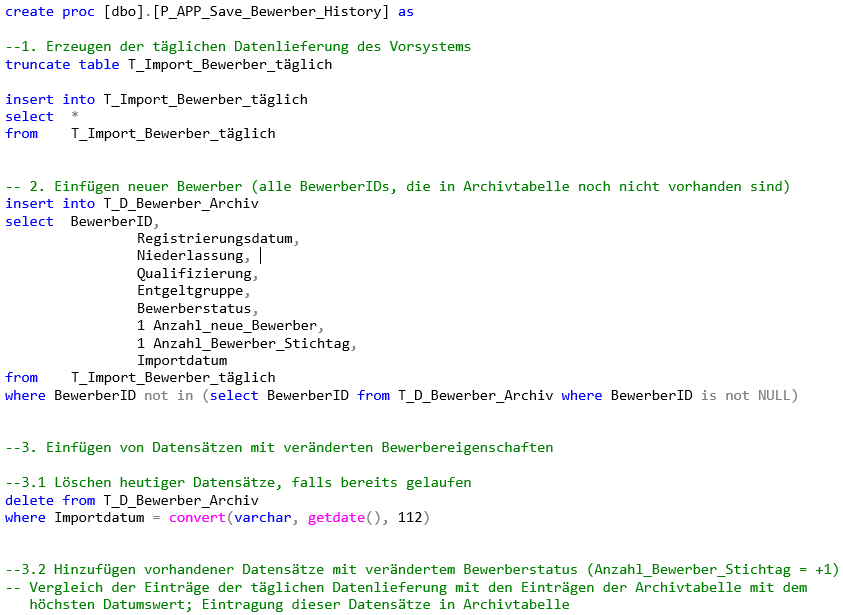




create proc [dbo].[P_APP_Save_Bewerber_History] as
--1. Erzeugen der täglichen Datenlieferung des Vorsystems
truncate table T_Import_Bewerber_täglich
insert into T_Import_Bewerber_täglich
select *
from T_Import_Bewerber_täglich
-- 2. Einfügen neuer Bewerber (alle BewerberIDs, die in Archivtabelle noch nicht vorhanden sind)
insert into T_D_Bewerber_Archiv
select BewerberID,
Registrierungsdatum,
Niederlassung,
Qualifizierung,
Entgeltgruppe,
Bewerberstatus,
1 Anzahl_neue_Bewerber,
1 Anzahl_Bewerber_Stichtag,
Importdatum
from T_Import_Bewerber_täglich
where BewerberID not in (select BewerberID from T_D_Bewerber_Archiv where BewerberID is not NULL)
--3. Einfügen von Datensätzen mit veränderten Bewerbereigenschaften
--3.1 Löschen heutiger Datensätze, falls bereits gelaufen
delete from T_D_Bewerber_Archiv
where Importdatum = convert(varchar, getdate(), 112)
--3.2 Hinzufügen vorhandener Datensätze mit verändertem Bewerberstatus (Anzahl_Bewerber_Stichtag = +1)
-- Vergleich der Einträge der täglichen Datenlieferung mit den Einträgen der Archivtabelle mit dem
höchsten Datumswert; Eintragung dieser Datensätze in Archivtabelle
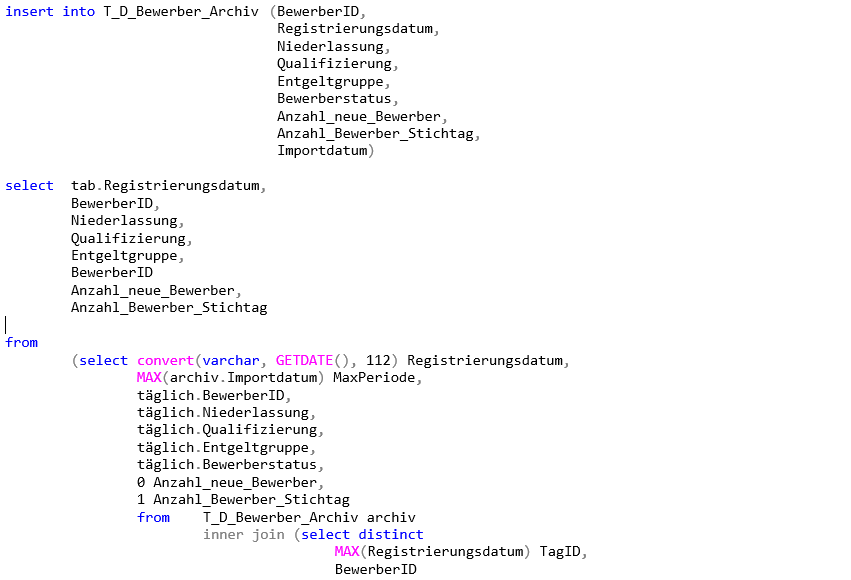
insert into T_D_Bewerber_Archiv (BewerberID,
Registrierungsdatum,
Niederlassung,
Qualifizierung,
Entgeltgruppe,
Bewerberstatus,
Anzahl_neue_Bewerber,
Anzahl_Bewerber_Stichtag,
Importdatum)
select tab.Registrierungsdatum,
BewerberID,
Niederlassung,
Qualifizierung,
Entgeltgruppe,
BewerberID
Anzahl_neue_Bewerber,
Anzahl_Bewerber_Stichtag
from
(select convert(varchar, GETDATE(), 112) Registrierungsdatum,
MAX(archiv.Importdatum) MaxPeriode,
täglich.BewerberID,
täglich.Niederlassung,
täglich.Qualifizierung,
täglich.Entgeltgruppe,
täglich.Bewerberstatus,
0 Anzahl_neue_Bewerber,
1 Anzahl_Bewerber_Stichtag
from T_D_Bewerber_Archiv archiv
inner join (select distinct
MAX(Registrierungsdatum) TagID,
BewerberID
from
T_D_Bewerber_Archiv
where
Anzahl_Bewerber_Stichtag = 1
group by
BewerberID) maxdatum
on archiv.BewerberID = maxdatum.BewerberID
and archiv.Registrierungsdatum = maxdatum.TagID
and archiv.Anzahl_Bewerber_Stichtag = 1
INNER join T_Import_Bewerber_täglich täglich
on archiv.BewerberID = täglich.BewerberID
where (archiv.Bewerberstatus <> täglich.Bewerberstatus
or archiv.Qualifizierung <> täglich.Qualifizierung)
group by
täglich.BewerberID,
täglich.Niederlassung,
täglich.Qualifizierung,
täglich.Entgeltgruppe,
täglich.Bewerberstatus) tab
--5. Ausbuchen von Datensätzen mit veränderter Kundenphase aus alter Kundenphase (An-zahl_Bewerber_Stichtag = -1)
---5.1 Erzeugen einer Temporären Tabelle, in der die auszubuchenden Datensätze eingetragen werden (Erzeugung nach dieser Proc hinterlegt)
exec P_BC_Generate_TMV 'V_D_Bewerber_Ausbuchung'
---5.2.Löschen der Ausbuchungen falls Prozedur heute bereits gelaufen
delete from arc
from T_D_Bewerber_Archiv arc
inner join TMV_D_Bewerber_Ausbuchung aus
on arc.BewerberID = aus.BewerberID
and arc.Registrierungsdatum = aus.Registrierungsdatum
and arc.Niederlassung = aus.NiederlassungAusbuchen
and arc.Qualifizierung = aus.QualifizierungAusbuchen
and arc.Entgeltgruppe = aus.EntgeltgruppeAusbuchen
and arc.Bewerberstatus = aus.BewerberstatusAusbuchen
and arc.Anzahl_Bewerber_Stichtag = aus.BewerberStichtagAusbuchen
--5.3. Hinzufügen der auszubuchenden Datensätze
insert into T_D_Bewerber_Archiv (BewerberID,
Registrierungsdatum,
Niederlassung,
Qualifizierung,
Entgeltgruppe,
Bewerberstatus,
Anzahl_neue_Bewerber,
Anzahl_Bewerber_Stichtag,
Importdatum)
select BewerberID,
Registrierungsdatum,
NiederlassungAusbuchen,
QualifizierungAusbuchen,
EntgeltgruppeAusbuchen,
BewerberstatusAusbuchen,
BewerberStichtagAusbuchen,
getdate()
from TMV_D_Bewerber_Ausbuchung
--0. Erzeugung einer temporären Tabelle die auszubuchenden Datensätze enthält (wird in [P_APP_Save_Bewerber_History] benötigt
create view [dbo].[V_D_Bewerber_Ausbuchung] as
With bewerberarc (Bewerbe-rID,Registrierungsdatum,Niederlassung,Qualifizierung,Entgeltgruppe,Bewerberstatus,Anzahl_Bewerber_Stichtag,Rowx) As
(
SELECT distinct
BewerberID,
Registrierungsdatum,
Niederlassung,
Qualifizierung,
Entgeltgruppe,
Bewerberstatus,
Anzahl_Bewerber_Stichtag,
ROW_NUMBER() over (partition by bewerber.BewerberID order by bewerber.Registrierungsdatum) rowx
FROM T_D_Bewerber_Archiv bewerber
WHERE bewerber.Anzahl_Bewerber_Stichtag = 1
)
select distinct
t.BewerberID,
t.Registrierungsdatum,
rowtab.Niederlassung NiederlassungAusbuchen,
rowtab.Qualifizierung QualifizierungAusbuchen,
rowtab.Entgeltgruppe EntgeltgruppeAusbuchen,
rowtab.Bewerberstatus BewerberstatusAusbuchen,
-1 BewerberStichtagAusbuchen
from
bewerberarc t
left join (select BewerberID,
Registrierungsdatum,
Niederlassung,
Qualifizierung,
Entgeltgruppe,
Bewerberstatus,
Anzahl_Bewerber_Stichtag,
rowx from bewerberarc
group by BewerberID,
Registrierungsdatum,
Niederlassung,
Qualifizierung,
Entgeltgruppe,
Bewerberstatus,
Anzahl_Bewerber_Stichtag,
Rowx) rowtab
on t.rowx = rowtab.rowx + 1
and t.BewerberID = rowtab.BewerberID
where (rowtab.Niederlassung is not null or
rowtab.Qualifizierung is not null or
rowtab.Entgeltgruppe is not null or
rowtab.Bewerberstatus is not null)