In der Serie zur Rangfolge (iPod, PowerSearch) wurde bereits deutlich, dass in diesem so simpel erscheinenden Instrument weitaus mehr steckt, als man auf den ersten Blick vermuten würde. Nehmen wir uns nochmals die Formel-1-Daten vor. Diesmal bilden wir eine Rangfolge nicht über alle Dimensionen unserer Daten, sondern fragen gleichzeitig nach auffälligen Kombinationen der Merkmale. Immerhin ist die Formel 1 ein Sport, in dem der Sieg von mehr Faktoren bestimmt wird, als in vielen anderen Sportarten. Zwar geben unsere Daten nur einen Ausschnitt dieser Faktoren wieder, aber darüber will ich zugunsten einer einfachen Illustration hinwegsehen.
Die folgende Liste zeigt das Ergebnis für Zweier-Kombinationen:
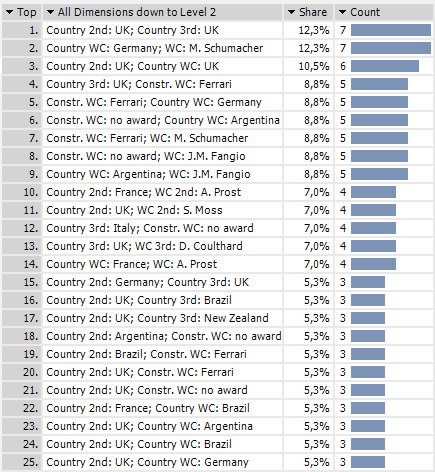
Interessant wird es ab der zweiten Zeile. Die Engländer stellten ebenso häufig gleichzeitig den zweiten und dritten Sieger wie Deutschland den Weltmeister. Kaum weniger häufig, nämlich sechs Mal stellten sie den Weltmeister und den Vize. Und das alles in einem Land, in dem noch heute so gefahren wie früher geritten wurde, links. Und Ferrari war mit niemand erfolgreicher als zusammen mit Michael Schumacher.
Bemerkenswert an diesem Vorgehen ist, dass es auf beinahe beliebige Fragestellungen angewandt werden kann. Das interessierende Kriterium ist immer der Analysewert, nach dem die Daten geordnet werden. Das können schlichte Umsatzgrößen oder auch komplexe zusammengesetzte Kennzahlen sein.
Man muss dabei nicht immer soweit gehen wie ein Kunde aus der Marktforschung. Um Ansätze für die Neuprofilierung einer Fluglinie zu finden, wurden Flugreisende nach ihrer Haltung zu Qualitätsmerkmalen befragt. Aus den gewonnenen Punktwerten wurde eine Kennzahl gebildet und gegen alle Merkmalskombinationen getestet. Da hier etliche Kriterien abgefragt und auch einiges über die Kundschaft bekannt war, enthielt das Modell etwa 40 Dimensionen mit fast 500 Merkmalen. Der entstehende Merkmalsraum weist in diesem Fall mehrere Millionen Merkmalskombinationen auf.
Ob ein solches Vorgehen gut verstanden wird, hängt dann nur noch davon ab, wie gut man den Analysewert erklärt, nach dem die Rangfolge bestimmt wird. Das Verfahren selbst ist schnell beschrieben und vermeidet damit den Black-Box-Effekt, der vielen anderen Verfahren anhaftet und die Kommunikation der Ergebnisse beeinträchtigt.
