Vor kurzem habe ich gezeigt, wie viel analytische Kraft in simplen Rangfolgen steckt, und sie als iPod des Datenanalysten bezeichnet. Die Verständlichkeit einer einfachen sortierten Liste kommt uns auch bei komplexeren Analysen zugute. Nehmen wir dazu nochmals die Formel-1-Daten zur Hand. Nach Weltmeistern hatten wir sie schon geordnet und uns gefreut, dass sie von einem Landsmann angeführt wird. Nach Ländern sieht die Sache anders aus. Da sind wir Deutschen auf dem dritten Platz, die heißblütigen Brasilianer sind knapp, die Engländer deutlich vor uns.
Derartige Listen können wir für alle Dimensionen erstellen, die unser Modell hergibt. Es enthält das Jahr, die Weltmeister, die Vizeweltmeister, die Dritten, deren Herkunftsländer und die Konstrukteurstitel nach Teams.
Würden wir alle Listen durchsehen, bekämen wir ein aussagekräftiges Bild, was den Kampf um die Titel in der Formel 1 seit Beginn geprägt hat, ob und wenn ja welche Fahrer, Länder und Teams dominierten.
Wesentlich für das Data Mining ist die Idee der Autonomie. Der Rechner soll alle Schritte selbsttätig ausführen, für die wenig Intelligenz nötig ist. In unserem Fall kann der Rechner für uns alle Rangfolgen bilden und sie zu einer einzigen Liste, einer Art Meta-Rangfolge zusammenführen.
In DeltaMaster erledigt diese Aufgabe das Modul PowerSearch. Das Ergebnis sieht so aus:
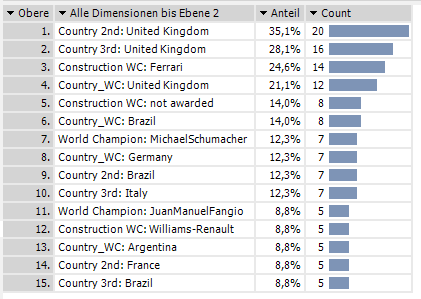
Wir erkennen, unsere Nachbarn jenseits des Kanals stellten nicht nur in Summe die erfolgreichsten Fahrer, sondern auch am häufigsten den Zweiten und Dritten der Meisterschaft. Den Italienern gelangen dafür mit Ferrari die meisten Konstrukteurstitel.
Das nächste Mal steigern wir unseren analytischen Anspruch und fragen nach der Häufung von Merkmalskombinationen.
