A while back I talked about the analytic power of simple rankings – or the iPod for data analysts as I like to call them. But did you know that a simple, sorted list can even make complex analyses easier to understand? Let’s take our Formula 1 example again. As a German who’s crazy about cars, I am pleased to see that my fellow countryman Michael Schumacher leads the list of world champions. When I sort the world champions by countries, however, we Germans only rank at #3, the Brazilians have a slight lead at #2, and the British are in a league of their own.
We can create these kinds of lists for all the dimensions available in our model, in this case: year, champion, #2, #3, nationality and constructor’s champion by team.
If we reviewed each list, we would see which factors have historically influenced the race for the Formula 1 title as well as which pilots, countries and teams have dominated the circuit – if at all.
The most important concept in data mining is autonomy. The computer should complete all of the mindless work for us – in this case, create the rankings and merge them into a single meta- ranking. The PowerSearch module in DeltaMaster does just that and produces the following results:
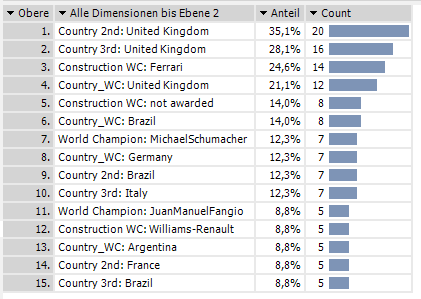
Our ranking of rankings shows that the UK has produced the best drivers in the history of F1 racing. British pilots have not only won the world championship the most times, but they have also placed second or third more times than those of other nationalities. Italy, or better said Ferrari, is the hands-down winner for the constructor championship.
Speaking of Ferraris, let’s shift our analytic expectations up another gear to explore the frequency of characteristic combinations. Stay tuned for more!
