Der Blogbeitrag „Anonymisierung von kundenspezifischen Daten für DeltaMaster-Anwendungen“ (http://crew.bissantz.de/anonymisierung-von-kundenspezifischen-daten) hat bereits Stellen in DeltaMaster Modeler, der Datenbank und in der Analysesitzung beschrieben, die es bei der Anonymisierung von Datenmodellen zu beachten gilt. Die Bewegungsdaten werden mithilfe eines Zufallsfaktors verfälscht, ohne dabei den Zusammenhang zu verlieren.
In diesem Blogbeitrag lernen wir die Möglichkeit kennen, Tabellen zu befüllen und zu anonymisieren: mit SQL Data Generator von redgate. Dabei werden Fremdschlüssel beachtet und Tabellen in Abhängigkeit voneinander geändert. Bei unseren Datenmodellen bewirkt dies, dass Faktentabellen entsprechend der Stammdaten geändert werden.
Anmeldung an die relationale Datenbank
Starten können Sie den SQL Data Generator direkt im SQL Server Management Studio unter Extras. Dann öffnet sich der Anmeldedialog Project Configuration im Reiter Database, in dem Sie die Informationen zum Server, dem zugehörigen Anmeldeverfahren und zur Datenbank eintragen, deren Tabellen anonymisiert werden sollen.
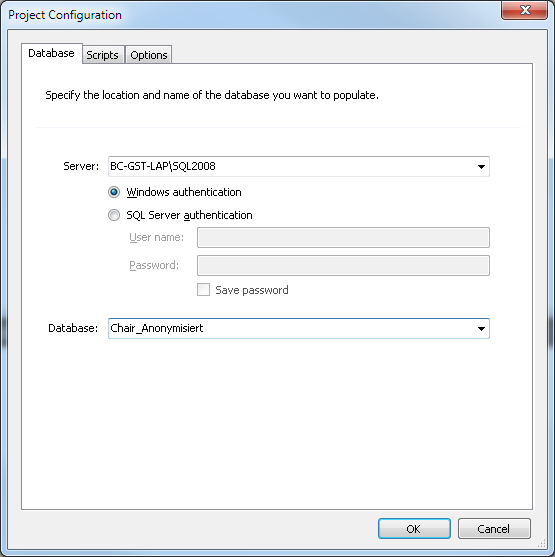
Abb. 1: Anmeldedialog des SQL Data Generator im Reiter Database
In den Reitern Scripts und Options können weitere Einstellungen vorgenommen werden. Hier kann man die Standardeinstellungen verwenden.
Abb. 2: Reiter Scripts
 Abb. 3: Reiter Options
Abb. 3: Reiter Options
Selektion der Tabellen
Nach Abschluss der Konfigurationseinstellungen werden alle Tabellen der Datenbank im linken Fenster aufgelistet. Das „+“ links vom Tabellennamen öffnet die Liste der zugehörigen Tabellenspalten. Im Fenster rechts unten erscheint nach Markierung der Tabelle eine Vorschau der anonymisierten Daten.
Im Anmeldedialog im Reiter Options wurde die Überprüfung von Abhängigkeiten durch die standardmäßig aktivierte Funktion Enforce check constraints bereits festgelegt. Da DeltaMaster Modeler die Schlüssel setzt, um Faktentabellen mit den darin verwendeten Dimensionen zu verknüpfen und auf Fehler zu überprüfen, erscheint an dieser Stelle ein Hinweis, wenn nur die Dimensionstabelle und nicht die Faktentabelle ausgewählt wird.
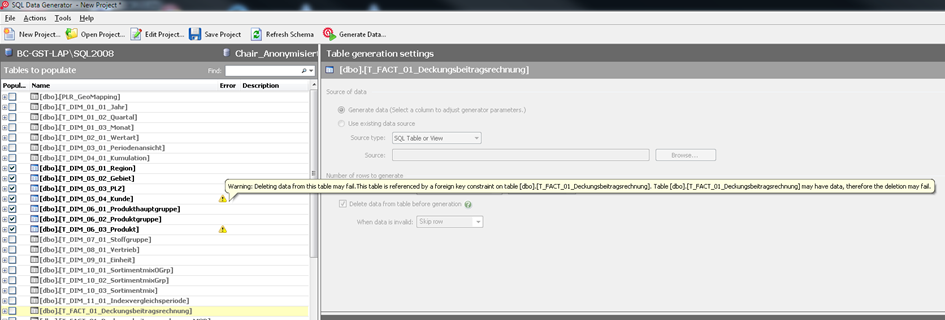 Abb. 4: Warnung bei Schlüsselverletzungen
Abb. 4: Warnung bei Schlüsselverletzungen
Bearbeitung der Stammdaten
Nun möchten wir die Dimensionstabelle für die Kunden überarbeiten. Dazu markiert man die Tabelle, um die einzelnen Spalten zu ändern. Für jede Spalte werden Einträge je nach Datentyp vorgeschlagen. In unserem Fall möchte man die Namen und die zugehörigen Kundennummern anonymisieren. Die anderen Spalten behalten wir bei, da diese keine kritischen Bezeichnungen haben. Die Einträge der vorhandenen Tabelle sollen zunächst vollständig übernommen werden. Dazu greift man auf eine Quelltabelle zu. Da die anonymisierte Datenbank separat zur produktiven Datenbank läuft, kann die Zieltabelle T_DIM_05_04_Kunde der Datenbank Chair_Anonymisiert auf die Quelltabelle T_DIM_05_04_Kunde der Datenbank Chair verweisen.
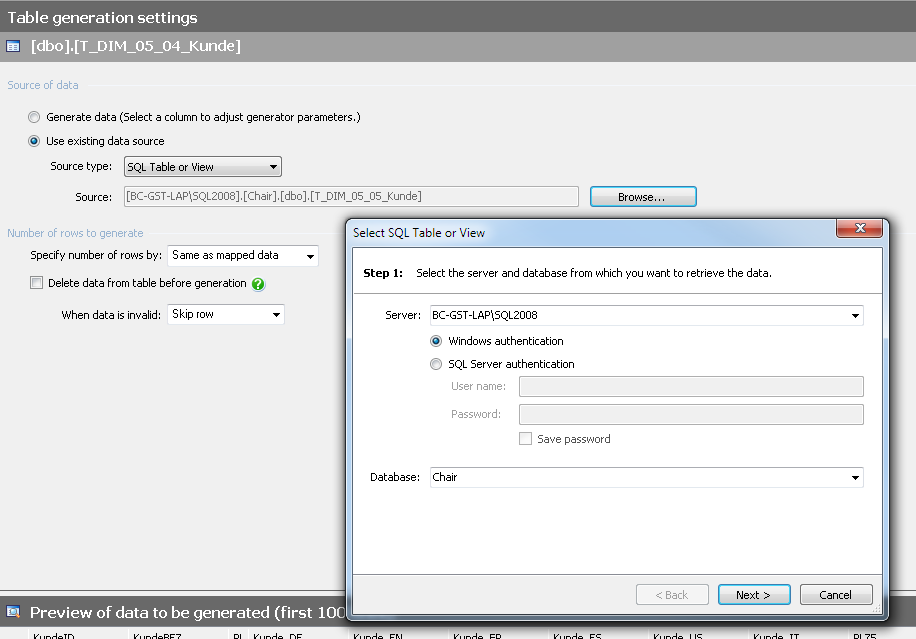 Abb. 5: Einträge aus einer bestehenden Quelltabelle übernehmen
Abb. 5: Einträge aus einer bestehenden Quelltabelle übernehmen
Im Anschluss sind alle Einträge aus der Quelltabelle in die Zieltabelle übernommen. Möchte man nun einzelne Spalten verändern (wie in unserem Beispiel Name und Kundennummer), werden diese nachträglich bearbeitet. Dazu markiert man die einzelnen Spalten links in der Auswahlliste, z. B. Kunde_ES. Im rechten oberen Fenster erscheinen neben Generator die verschiedenen Möglichkeiten die Daten zu verändern.
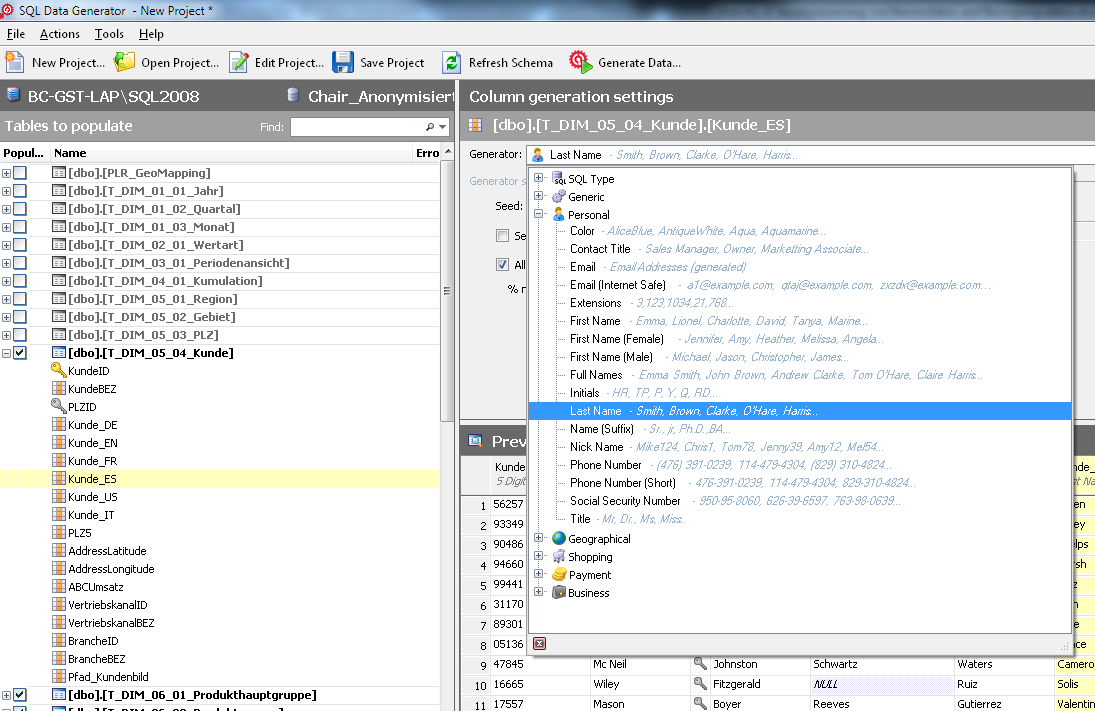 Abb. 6: Auswahl für die Einträge je Spalte
Abb. 6: Auswahl für die Einträge je Spalte
Dabei werden die Einträge erkannt und je nach Datentyp passende Optionen dafür aufgelistet. Möchte man bei Bezeichnungen oder Namen selbst erstellte Daten eintragen, muss eine Liste in Form einer Textdatei angelegt werden, die dann als Quelle für diese Spalte definiert wird. In der folgenden Abbildung werden die Kundennamen aus einer selbst definierten Textdatei befüllt.
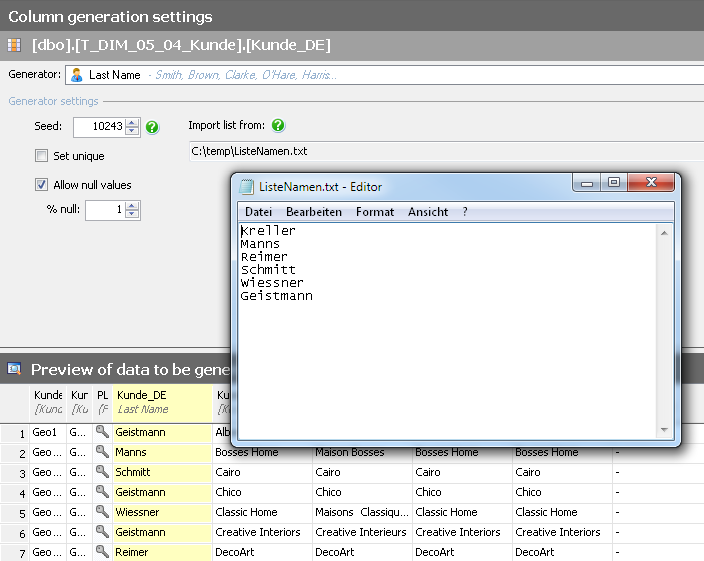 Abb. 7: Kundennamen aus einer selbst definierten Textdatei
Abb. 7: Kundennamen aus einer selbst definierten Textdatei
Bearbeitung der Bewegungsdaten
Nachdem in den Stammdaten die Einträge überarbeitet wurden, möchten wir auch die Bewegungsdaten ändern. Die Abhängigkeiten zwischen T_DIM- und T_FACT-Tabellen wurden bereits erkannt und beim Aufruf dieser Tabelle als Schlüssel in den Dimensionsspalten dargestellt.
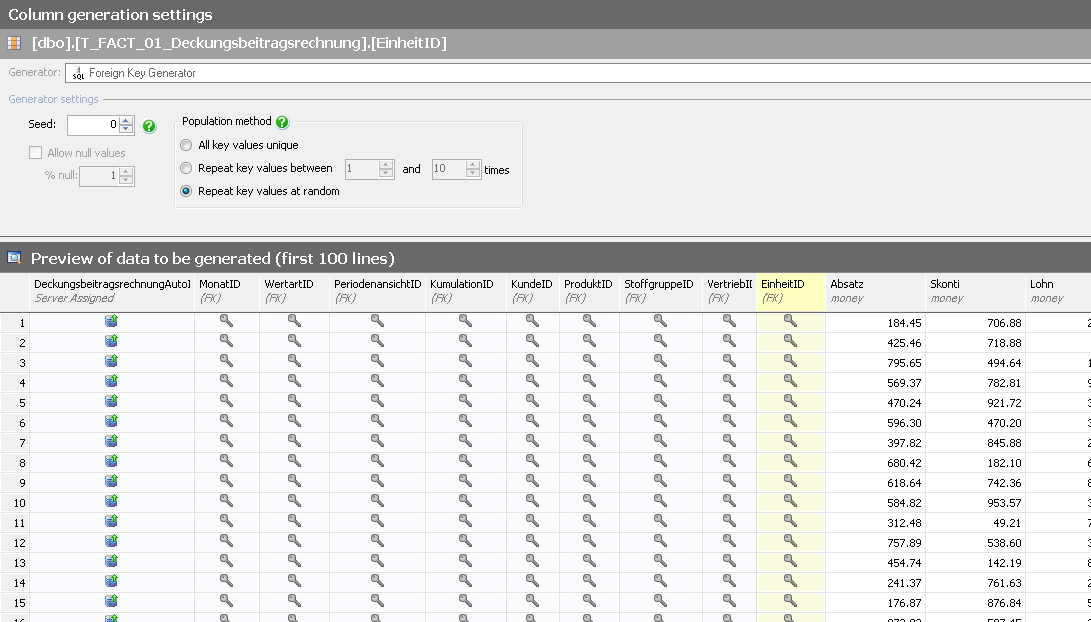 Abb. 8: Fremdschlüsselbeziehungen zwischen Dimensions- und Faktentabellen
Abb. 8: Fremdschlüsselbeziehungen zwischen Dimensions- und Faktentabellen
Bei den Werten werden wieder die Datentypen erkannt und vorhandene Werte ersetzt. Möchte man vorerst die Zahlen aus der ursprünglichen Tabelle beibehalten, so verknüpft man die Zieltabelle T_FACT_01_Deckungsbeitragsrechnung aus der Datenbank Chair_Anonymisiert mit der Quelltabelle T_FACT_01_Deckungsbeitragsrechnung aus der Datenbank Chair. Die Werte können anschließend per Zufallsprinzip je Spalte geändert werden. Dafür können Minimal- und Maximalwerte eingegeben werden, um eine bestimmte Spanne einzuhalten.
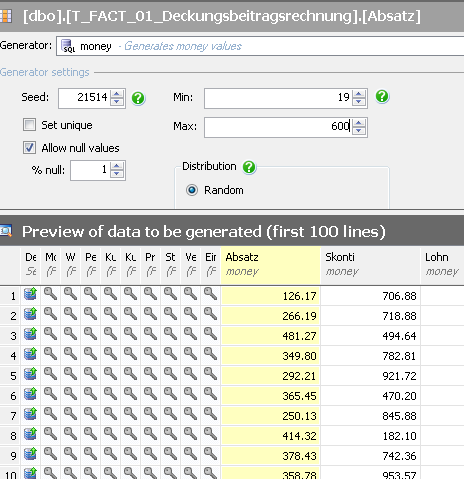 Abb. 9: Aktualisierung der Zahlen
Abb. 9: Aktualisierung der Zahlen
Erstellung der neuen Datensätze
Wurden die Tabellen überarbeitet, zeigt eine Übersicht an, auf welchem Server und welcher Datenbank welche Tabellen geändert werden. Die Schaltfläche Generate Data erstellt die neuen Datensätze.
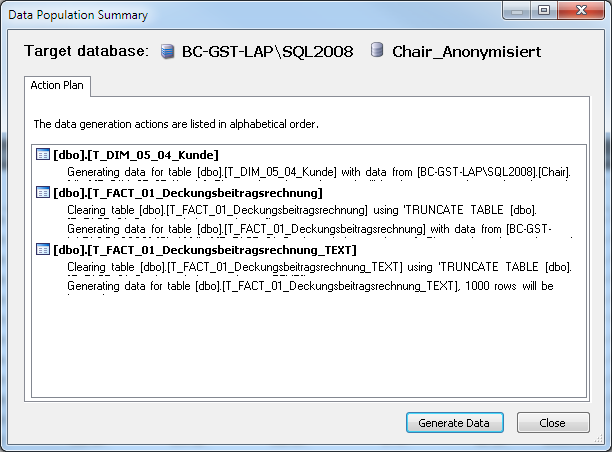 Abb. 10: Überblick über die zu ändernden Tabellen
Abb. 10: Überblick über die zu ändernden Tabellen
 Abb. 11: Datensätze erstellen
Abb. 11: Datensätze erstellen
Nach Erstellung der Datensätze öffnet sich automatisch ein Statusbericht, der die Zeilenanzahl der betroffenen Tabellen anzeigt. Sollte es zu Fehlern kommen, z. B. wegen Schlüsselverletzungen, so werden hier auch die Fehlermeldungen aufgelistet.
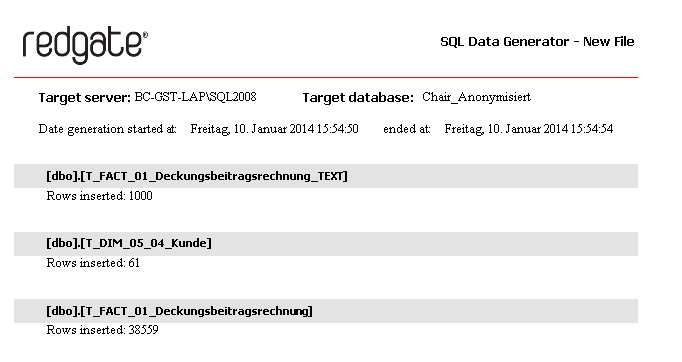 Abb. 12: Statusbericht
Abb. 12: Statusbericht
Wirft man einen Blick in die Tabellen im SQL Server Management Studio, sieht man, dass die Kunden andere Namen haben, und in der Faktentabelle erscheinen die geänderten Kundennummern.
SQL Data Generator bietet uns eine sehr schnelle und einfache Möglichkeit Daten zu anonymisieren, ohne dabei alle Änderungen der Stammdaten in den Bewegungsdaten manuell nachziehen zu müssen. Einziger Nachteil ist, dass bei den Kennzahlen die Zufallszahlen je Spalte gebildet werden. So geht ein möglicher Zusammenhang zwischen den Kennzahlen verloren. Um dies zu umgehen, könnte man zuerst die Prozedur aus dem Blogbeitrag „Für Präsentationszwecke: Daten kräftig durchmischen“ (http://crew.bissantz.de/updatetablewithrandomfactor) auf der Faktentabelle ausführen und anschließend die Zahlen aus der Tabelle ohne Änderung übernehmen.
Alle Einstellungen zu den Änderungen werden als Projekt gespeichert und können nach Bedarf jederzeit wieder ausgeführt werden.
