Strukturen bringen Ordnung in die Daten. Dies gilt nicht nur für die Modellierung, sondern auch für das Layout von Berichten. Diesem Thema widmet sich die Autoseparation in Pivottabellen (siehe hierzu auch die DeltaMaster clicks! 11/2012). Wie von Zauberhand werden Tabellen durch das Einfügen von Abständen formatiert und strukturiert. Die Logik, wann ein Abstand eingefügt wird, ergibt sich aus dem Aufbau der Pivottabelle und den verwendeten Strukturen. Was kann aber getan werden, wenn sich die gruppierenden Merkmale gar nicht im Modell befinden, sondern von individueller Natur sind? Lesen Sie hier, wie sich mit einem kleinen Kniff die Autoseparation auch in diesem Fall nutzen lässt.
Aufgabenstellung
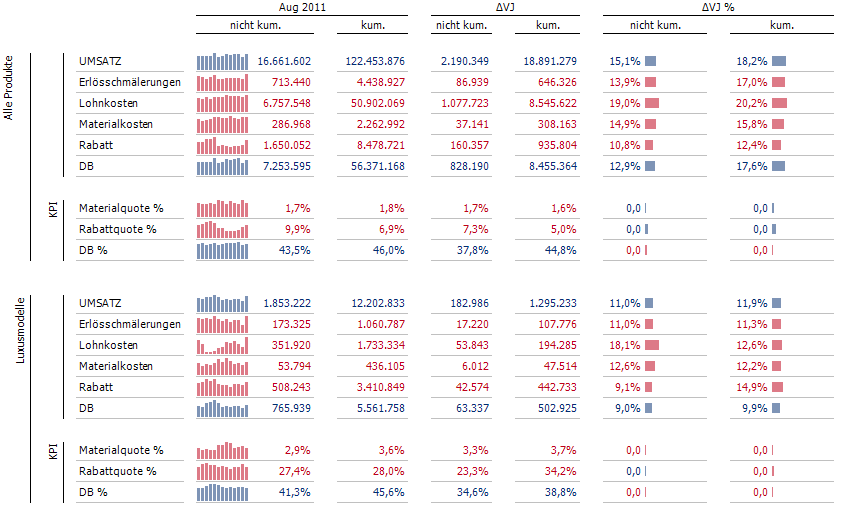
Ein Beispiel zur individuellen Nutzung der Autoseparation liefert ein typischer GuV- oder Bilanzbericht. Die hierarchische Kontenstruktur soll auf der Zeilenachse des Berichts gezeigt werden. Gedanklich nehmen wir die Konten als Kennzahlen war. In vielen Modellen, insbesondere auf Basis der Microsoft Technologie, werden derartige Konten aber nicht als Kennzahlen, sondern als Elemente einer Dimension abgebildet. Denn nur Dimensionen ermöglichen eine hierarchische Gliederung der Konten. Die Kennzahl, die in Verbindung mit einem Konto einen Wert liefert, ist dann eine Art „Technik-Kennzahl“. Diese muss stets in Verbindung mit der Kontendimension verwendet werden. Oft trägt sie den Namen „Kontenwert“ oder „Saldo“. Da die Kennzahl aus Sicht des Lesers überflüssig scheint und die Anzeige ihres Namens eher verwirrt als erhellt, wandert sie nicht in eine Achse, sondern in den Filterbereich der Pivottabelle. Ergänzt um unseren Standard-Spaltenkopf zur Monatsübersicht würde ein Kontenbericht wie folgt dargestellt.
Wenngleich der Spaltenkopf sauber separiert ist, so vermissen wir eine thematische Strukturierung der Konten. Beispielsweise könnten eine Gruppierung der Konten nach Umsatz, DB und Kosten erfolgen. Eine solche Abgrenzung kann die Autoseparation aus mehreren Gründen aber nicht leisten, denn
- Separatoren ergeben sich nur dann, wenn mindestens zwei Dimensionen auf einer Achse des Berichts verwendet werden. Dies ist im obigen Beispiel nicht der Fall.
- Separatoren leiten sich von den Strukturen des Datenmodells ab. Obiger Gruppierungsvorschlag ist aber individueller Natur und nicht Bestandteil des Datenmodells.
Es soll also ein Weg gefunden werden, der eine Gruppierung der Konten ohne den Umbau des Datenmodells, sondern rein auf Basis der Formatierung mittels Autoseparation ermöglicht.
Lösung
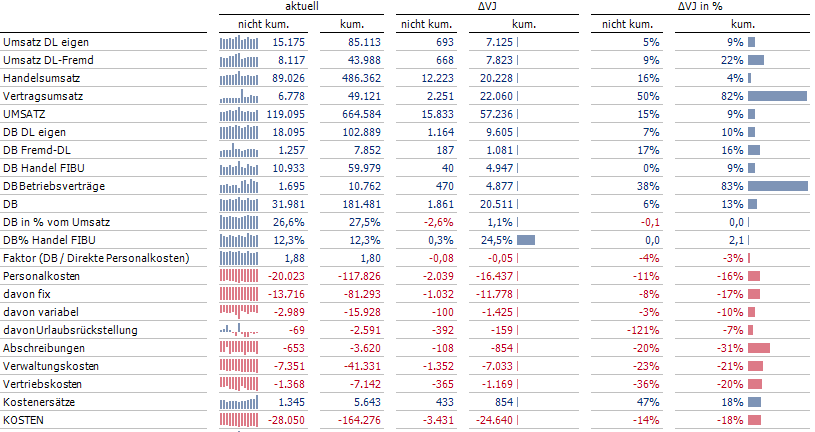
Bei einem Lösungsansatz müssen wir sicherstellen, dass sowohl das Erscheinungsbild der Pivottabelle als auch die Art und Weise, wie diese definiert wird, sich nicht vom Standard unterscheidet. Konzentrieren wir uns daher auf die grundlegende Funktionsweise der Autoseparation. Diese bewirkt, dass auf einer Berichtsachse mit zwei verschachtelten Dimensionen bei jedem Wechsel des Elements der äußeren Achse eine Separation erfolgt. Die gewünschte Strukturierung der Konten muss also durch Verschachtelung zweier Achsen herbeigeführt werden. Die Definition der inneren Berichtsachse unseres Beispiels ist denkbar einfach, da wir hier nur mehrere Mengen (bzw. named-sets) mit Konten im Sinne der gewünschten Gruppierung definieren müssen. Für jede dieser Mengen muss es genau ein Element, das gewissermaßen als Textbaustein fungiert, auf der äußeren Berichtsachse geben.
Als Textbaustein eignen sich Elemente aus denjenigen Dimensionen, die bis dato noch nicht in den Achsen der Pivottabelle verwendet werden. Alternativ eignen sich auch Analysewerte. Alle diese Elemente oder Analysewerte sollten eine identische und meist auch neutrale Wirkung auf die Konten der inneren Achse haben. Ein typisches Element, das diese Eigenschaft besitzt, wäre die Datenart „Ist“. Würden wir dieses Element im Dimensionsbrowser mehrmals kopieren und die Kopien wie gewünscht benennen, so hätten wir die Klammern für die äußere Achse geschaffen. Leider hat dieses Vorgehen einen unschönen Nebeneffekt. Mit der Zeit steht zu befürchten, dass sich die Datenart-Dimension mit vielen dieser Textbausteine füllt. Eine andere Möglichkeit speziell in unserem Beispiel wäre die Nutzung von Analysewerten als Gruppierungsmerkmal. Der Vorteil gegenüber der Verwendung von Dimensionselementen liegt darin, dass die als Textbausteine verwendeten Analysewerte im Analysewertbrowser besser versteckt sind. Zudem können sie durch Bildung entsprechender Analysewertgruppen von den „echten“ Kennzahlen leicht separiert werden. Der originäre Analysewert sollte grundsätzlich nicht umbenannt und im Bericht verwendet werden. Stattdessen erzeugen wir so viele Kopien des Analysewerts, wie Gruppierungen benötigt werden. Die Zeilenachse der Pivottabelle müsste dann um die Analysewerte erweitert werden. Im Spalten-/Zeileneditor lassen sich die Kontenmengen den jeweiligen Textbausteinen leicht zuordnen. Das Ergebnis dieses Vorgehens zeigt einen sauber strukturierten Bericht, der ausschließlich durch den Standard der Autoseparation erzeugt wird.
Grenzen
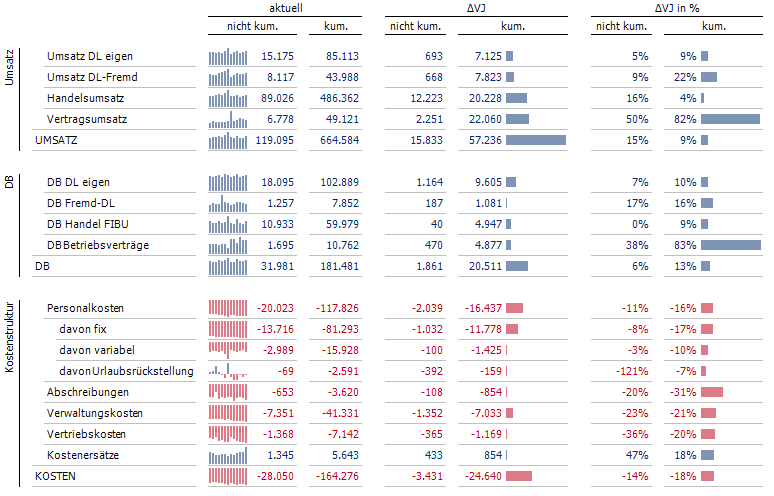
Es gibt zahlreiche Szenarien, in denen eine individuelle Autoseparation erforderlich sein kann. Allerdings hat dieses Vorgehen auch seine Grenzen. Ein weiteres Beispiel aus dem Projektalltag soll dies verdeutlichen.
Wir benötigen einen Bericht, der pro Produktgruppe die wichtigsten Konten und einige berechnete Indikatoren zeigt. Konten (mit absoluten Werten) und Indikatoren (mit prozentualen Werten) sollen thematisch getrennt werden. Konten sind echte Analysewerte, sodass wir auf eine Dimension zum Anlegen der Textbausteine zurückgreifen müssen. Eine echte Herausforderung dieses Beispiels besteht darin, dass sich der individuelle Textbaustein in der Mitte zwischen der äußeren und der inneren Zeilendimension befindet. Dadurch und durch den Umstand, dass zu jedem Textbaustein unterschiedliche Konten gehören, kann die Zeilenachse nicht wie üblich als „kartesisches Produkt“ aus allen Dimensions- bzw. Analysewerten definiert werden. Praktisch bedeutet dies, dass wir jedes einzelne Segment des Berichts von Hand im Spalten-/Zeileneditor definieren müssten. Ab einer gewissen Berichtskomplexität ist dies daher keine Lösung. Alternativ kann man auf MDX ausweichen, wodurch die Achsendefinition ein wenig kompakter gehalten werden kann. Hier müssten lediglich die manuell zu gruppierenden Bereiche (Textbaustein je Kennzahlliste) per Crossjoin definiert und dann mit den Elementen der äußersten Achse (Produkte) ausmultipliziert werden. Aber auch hier sei darauf hingewiesen, dass ab einer gewissen Berichtskomplexität viel MDX-Code geschrieben werden muss.
Die Lösung für unser Beispiel sieht schematisch wie folgt aus:
{Produktliste}
*
{
Crossjoin({[Textbaustein].[1]}, {Kennzahlliste_1}),
Crossjoin({[Textbaustein].[2]}, {Kennzahlliste_2})
}
Auf Basis dieser Achsendefinition ergibt sich folgender Bericht. Man beachte, dass auch Textbausteine ohne Bezeichnung (mit n-Leerzeichen im Namen) angewandt werden können.