In den letzten Jahren wurde der Begriff „Big Data“ immer mehr zum Schlagwort und Hoffnungsträger in und für viele Unternehmen. Die Fähigkeit Massendaten auswerten zu können und dadurch neue Erkenntnisse zu erlangen, wird von Vielen als gewaltige Chance gesehen. Dabei werden interne Unternehmensdaten, wie Absatzzahlen und Kundeninformationen, mit externen Daten kombiniert. Diese stammen sowohl aus Web- und Social-Media-Quellen als auch von hardwarenahen Quellen, wie Sensoren von Produktionsanlagen und medizinischen Geräten.
Problem und Herausforderung zugleich dabei ist das immense Datenvolumen: Beispielsweise gab es im Jahr 2013 weltweit 1,23 Milliarden Facebook-Nutzer, von denen täglich 750 Millionen aktiv waren[1]. Dazu kommen am Tag 206 Milliarden verschickter E-Mails[2] und 400 Millionen Tweets von den 500 Millionen Twitter-Usern[3].
Der folgende Blogbeitrag gibt einen Überblick über das Thema Big Data. Neben der Begriffsdefinition werden auch Chancen und Ziele, Herausforderungen, Gefahren und Technologien untersucht.
Definition
Es gibt verschiedenste Definitionsformen des Begriffes „Big Data“. Um eine grobe Übersicht über das zu erhalten, was dahinter steckt, konzentrieren wir uns zunächst auf die Form der Daten (d. h. strukturiert, halbstrukturiert und unstrukturiert)[4]:
- Strukturierte Daten sind fest definierte Felder mit gleichartiger Struktur. Diese Dateien haben immer den gleichen Aufbau und liegen uns in gewohnter Tabellenform vor. Sie können einfach verarbeitet werden.
- Bei halbstrukturierten Daten sind zwar keine festen Felder definiert, sie sind dennoch mit Markern bzw. Tags (HTML-Dateien, XML-Dateien) versehen und können damit weiterverarbeitet werden. Dazu zählen u. a. E-Mails.
- Zu unstrukturierten Daten gehören Audio- und Video-Dateien, Daten aus Online Foren, Social-Media-Anwendungen und Kameras. Auch Gesundheitspläne, handschriftliche Notizen, biometrische Daten, genetische Informationen und sehr große Transaktionen, wie die Vielzahl einzelner Belege und Quittungen zählen dazu.
Die Form des Aufbaus ist frei definierbar. Datenquellen sind beispielsweise soziale Netzwerke, Web Protokolldateien, RFID-Chips und Kommunikationsergebnisse. Diese können zwischen Menschen, Menschen und Maschinen/Diensten oder zwischen Maschinen/Diensten (z. B. Sensoren) stattfinden.
Allerdings gibt es auch Definitionen, die das Augenmerk mehr auf andere Kriterien legen, wie den Umgang mit wachsendem Datenvolumen, Anforderung an erhöhte Verarbeitungsgeschwindigkeit und eine größere Vielfalt an Datenquellen und Informationen[5].
Generell sei gesagt: Man erhofft sich bei Big Data eine schnelle Analyse von großen und vielfältigen Datenmengen und eine anschließende Bereitstellung aller relevanten Informationen für aussagekräftige Prognosen. Die Datenaufbereitung sollte dabei möglichst in Echtzeit geschehen, sodass z. B. auf bestimmte Verhaltensweisen sofort mit entsprechenden Marketingaktionen reagiert werden kann.
Abgrenzung Big Data – Business Intelligence
Big Data und Business Intelligence lassen sich nach folgenden Kriterien unterscheiden: Datenmenge, Datenquellen, Verarbeitungszeit, Datensicherheit und Datenqualität[6].
Big Data
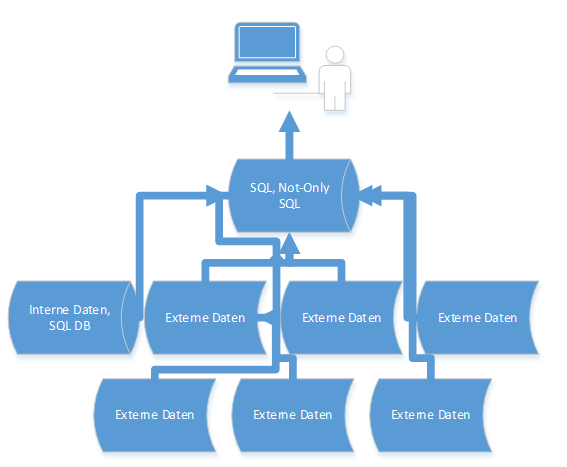
Abb. 1: Prozess Datenverarbeitung Big Data
- Datenmenge: extrem hohes Datenvolumen (ab mehreren Terabytes)
- Datenquellen/-format/-speicherung: Die Daten, die aus internen und externen Quellen stammen, liegen in strukturierter, halbstrukturierter und unstrukturierter Form vor und dabei in verschiedenen Formaten. Die gesamten Informationen werden in NoSQL-Datenbanken verarbeitet. Dabei werden sie nicht in Tabellenform zwischengespeichert.
- Verarbeitungszeit: Anforderung an die Verarbeitungszeit ist hoch; sie muss extrem kurz sein (Realtime Processing), um schnelle Reaktionen zu gewährleisten.
- Datensicherheit: Der größte Kritikpunkt ist allerdings die Datensicherheit. Das betrifft sowohl die Sicherheit vor unbefugten externen Zugriffen als auch den Schutz der Privatsphäre von personenbezogenen Daten.
- Datenqualität: Eines der größten Probleme ist noch das Thema Datenqualität, weil aus dieser Vielzahl an Daten zunächst passende und interessante Informationen ermittelt werden müssen.
Business Intelligence
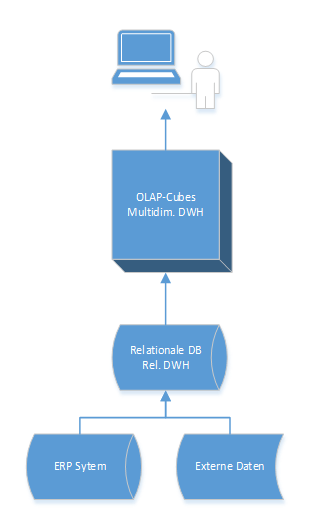
Abb. 2: Prozess Datenverarbeitung Business Intelligence
- Datenmenge: mittleres bis hohes Datenvolumen
- Datenquellen/-format/-speicherung: Daten aus unterschiedlichen internen und teilweise auch externen Datenquellen werden extrahiert, transformiert und in zentralen Datenlagern (Relationales Datawarehouse) abgelegt. Dabei liegen sie immer in strukturierter Form vor und werden in Tabellen zwischengespeichert. Auf OLAP Cubes können BI-Anwendungen über Schnittstellen zugreifen und Analysen und Reporting betreiben.
- Verarbeitungszeit: Die Aufbereitungszeiten selbst sind für die Anwendung weniger relevant, im Mittelpunkt steht hier die Abfrageperformance auf Informationen der Cubes.
- Datensicherheit: Auch hier müssen die Datenschutzrichtlinien berücksichtigt und die Informationen vor externen Zugriffen geschützt werden. Personenbezogenen Daten stehen aber von vornherein nur bedingt zur Verfügung.
- Datenqualität: Die Daten liegen immer im gleichen Format vor und sichern dadurch die Qualität.
Chancen und Ziele
Datenanalyse
Mithilfe schneller Auswertungen der großen Datenbestände können sofort Datenmuster erkannt und hilfreiche Vorhersagen getroffen werden. Das betrifft auch Bereiche, die bisher noch nicht ausgewertet werden konnten, weil die Informationen nicht in geeigneter Form vorlagen.
Außerdem können diese Daten nun in einen sinnvollen Zusammenhang gebracht werden, d. h. es findet zunächst eine Konsolidierung der vielen Inhalte statt. Anschließend werden die für eine gute Qualität der Ergebnisse entscheidungsrelevanten Informationen ermittelt.
Steigerung der Produktivität
Aufgrund der Echtzeitanalyse können Prozesse schnell angepasst und Reaktionszeiten verkürzt werden. Nach der Ermittlung eines Kundenverhaltens wird sofort eine Online-Werbemaßnahme geschaltet, die speziell auf die Anforderungen und Interessenten des Kunden angepasst ist.
Durch diese Transparenz werden Trends frühzeitig erkannt und neue Fragestellungen schneller beantwortet. Daraus sollen Wettbewerbsvorteile erzielt und Einsparungspotenziale gewonnen werden.
Neues Know-how braucht das Land
Der Bereich Big Data ist Neuland für viele Unternehmen und deshalb ist hier Fachpersonal sehr gefragt. Das führt zu einer Nachfragesteigerung an externen Dienstleistern, aber auch zu neuen Arbeits-
plätzen. Berufsbezeichnungen wie Data Scientist, Data Analyst und Data Change Agents decken den Bedarf an Konzeption, Umsetzung, Analyse und der anschließenden Integration der Big Data Auswertungen in den Unternehmensprozess ab[1].
Herausforderungen
Die vielen neuen Anforderungen stellen Mitarbeiter und auch technische Ressourcen vor große Herausforderungen. Eine schnelle Verfügbarkeit von Daten und große Datenbanken im Multi-Terabyte-Bereich erfordern eine schnelle Speicherung, leistungsstarke Server und viele CPU-Lizenzen[2].
Daten aus unterschiedlichen Quellen, mit wechselnden Formaten und enormer Spaltenanzahl müssen erfasst, konsolidiert und in Beziehung zueinander gesetzt werden. Um die Datenqualität zu garantieren, sind Datenbanksysteme und Analyse-Tools notwendig. Für die anschließende parallelisierte Verarbeitung müssen extrem viele Prozessoren zu Verfügung stehen, welche die Daten mit neuen statistischen und mathematischen Algorithmen aufbereiten.
Die IT-Fachkräfte erwarten hohe Anforderungen an Know-how und Spezialkenntnisse in Bereichen wie Cloud Computing, Datenschutz und IT-Sicherheit. Vor allem bei Mittelständlern besteht häufig ein Mangel an IT-Ressourcen, bezogen auf Serverleistung, Speicherplatz und Analysesoftware.
Bei der Einführung eines solchen Systems empfiehlt es sich zunächst die interne Infrastruktur zu überprüfen und In-house-Lösungen miteinzubeziehen. Außerdem sollte Unterstützung beim Thema Datenschutz und Anonymisierung gesucht werden.
Im Falle von Outsourcing von Hardware und/oder Software, müssen Auswertungen und Datenaustausch schnellstmöglich zwischen Firmenrechenzentrum und Data Center von Dienstanbietern stattfinden, ohne dabei die Datensicherheit zu gefährden.
Gefahren
Datenschutz und Privacy-Regelungen
Die Schwierigkeiten beim Schutz der Daten vor dem Zugriff Unbefugter und die Bedrohung der Privatsphäre gehören zu den entscheidenden Kritikpunkten[3]. Geeignete Verfahren zur Anonymisierung sind unumgänglich, um dies zu gewährleisten. Es ist außerdem fraglich, ob Unternehmen und Regierungen verantwortungsbewusst mit Daten umgehen bzw. ob diese Daten tatsächlich freigegeben werden sollten. Patientendaten oder sehr persönliche Informationen können zur Diskriminierung aufgrund der Analyseergebnisse führen[4].
Ein weiterer Aspekt ist die Sicherung von Datenqualität
Massendaten aus den verschiedensten Quellen garantieren nicht unbedingt eine gute Qualität. Irrtümliche Interpretationen bzw. falsches Vertrauen in die Prognosefähigkeit können zu Fehlentscheidungen führen.
Technologien
Bisherige SQL-Datenbanken stoßen bei diesen Anforderungen an Datenvolumen und Aufbereitungsgeschwindigkeit an ihre Grenzen. Deshalb gibt es neue Datenbankkonzepte und Technologien[5].
- Not-only-SQL-Datenbanken (NoSQL): Hierbei handelt es sich um eine geordnete Ablage von Daten und Dateien, die sich nicht in typischen Tabellen abbilden lassen[6].
- External Tables: Allgemeine Datenbanksysteme (Oracle, Microsoft, Teradata Aster, EMC, Greenplum) ermöglichen den Zugriff auf Dateien über SQL, dabei werden die Dateien jedoch nicht in relationale Datenbanken importiert. Das relationale Schema wird nur als virtuelle Struktur über die Dateien gelegt (Schema-on-Read).
- Apache Hadoop[7]: Eine der bekanntesten Technologien im Bereich von Big Data ist Apache Hadoop. Dabei handelt es sich um eine auf Java basierte Open-Source-Technik, die auch mit herkömmlichen SQL-Datenbanken verknüpft werden kann. Idee ist hier, ähnlich dem Algorithmus von Google, Rechenaufträge stark zu parallelisieren und auf viele Rechnerknoten zu verteilen. Dadurch sollen extrem schnelle Verarbeitungszeiten möglich sein und die Fehleranfälligkeit aufgrund von Serverausfällen reduziert werden.
Das Prinzip ist die Kombination aus Hadoop File System (HDFS) und MapReduce, einer Programmbibliothek für die parallele Verarbeitung der im HDFS abgelegten Dateien. MapReduce besteht dabei aus zwei Phasen.
- Die Map-Phase teilt Dateien in Fragmente, die jeweils einem Task zugeordnet werden. Für jeden Prozessschritt werden eigene Betriebssystemprozesse gestartet, Dateien im Batch gelesen und verarbeitet.
- Die Zwischenergebnisse werden dann in der Reduce-Phase verteilt und daraus das Gesamtergebnis berechnet.
Diese Technologie ist allerdings nur für die Speicherung und Vorverarbeitung von Big Data einsetzbar, interaktive Analysen auf relationale Datenbanken sind nicht möglich.
Um Hadoop aber mit relationalen SQL-Datenbanken zu verbinden, wird die Zusatzsoftware Hive benötigt. Diese übersetzt klassische SQL-Abfragen in MapReduce-Code. Anschließend kann über Open Database Connectivity (ODBC) und Java Database Connectivity (JDBC) auf die Daten zugegriffen werden.
Apache Hadoop lockt zwar mit geringen Lizenz- und Hardwarekosten, in der Basisversion fehlen allerdings Überwachungs- und Sicherheitskonfigurationen. Es müssen noch weitere Lizenzkosten und Wartungsgebühren für zusätzliche Tools berücksichtigt werden.
Es gibt noch weitere Modelle von Datenbanken:
- Dokumentenorientierte Datenbanken: Für halbstrukturierte Daten geeignet; es werden Dokumenteninhalte durchsucht, z. B. MongoDB, Apache CouchDB.
- Graphen-Datenbanken: Speichern von Beziehungen zwischen Entitäten, z. B. Neo4j, ArangoDB.
- Key-Value-Datenbanken: Speichern beliebiger Werte unter einem Schlüssel; Entweder In-Memory, d. h. im Arbeitsspeicher und deshalb hohe Leistung, oder On-Disk, der Festplatte als nichtflüchtiger Datenspeicher. Beispiele sind hier u. a. Apache Cassandra, BigTable
Ausblick
Zukünftige Investitionen werden vermutlich im Bereich der Systemintegration anfallen, weil vorhandene Strukturen angepasst werden müssen. Außerdem werden laufend neue Datenquellen, z. B. aus Gesichts- und Gestenerkennung dazukommen[8]. Diese müssen dann wieder gesammelt und verarbeitet werden. Um dieses steigende Datenvolumen zu bewältigen, werden fortlaufend geeignete Speicher- und Rechencluster entwickelt. Möglich wären zukünftig hybride Ansätze, d. h. eine Kombination aus In-Memory- und Big Data Datenquellen mit anschließender unternehmensinterner Verarbeitung in NoSQL-Datenbanken kombiniert mit Cloud Computing[9].
[1] http://www.faz.net/aktuell/wirtschaft/wirtschaft-in-zahlen/10-jahre-seit-gruendung-facebooks-unglaubliches-nutzerwachstum-12777220.html
[2] http://de.statista.com/statistik/daten/studie/247225/umfrage/schaetzung-zur-zahl-der-taeglich-verschickten-e-mails/
[3] http://blog.wishpond.com/post/58272859187/infographic-twitter-by-the-numbers-20-amazing
[4] http://www.computerwoche.de/a/9-punkte-fuer-die-big-data-strategie,2537831
[5] http://www.gi.de/nc/service/informatiklexikon/detailansicht/article/big-data.html
[6] http://www.gi.de/nc/service/informatiklexikon/detailansicht/article/big-data.html
[7] http://www.computerwoche.de/a/jobmaschine-big-data,2539798
[8] http://www.gi.de/nc/service/informatiklexikon/detailansicht/article/big-data.html
[9] http://www.computerwoche.de/a/bewusstsein-muss-wachsen,2547132
[10]
[11] http://www.computerwoche.de/a/hadoop-und-sql-ruecken-enger-zusammen,2549475
[12] http://www.computerwoche.de/a/bewusstsein-muss-wachsen,2547132
[14] http://www.gi.de/nc/service/informatiklexikon/detailansicht/article/big-data.html
[15] http://www.derwesten.de/wirtschaft/digital/microsoft-greift-auf-der-synopsis-2014-trendthemen-wie-big-data-und-cloud-auf-id9338312.html
