In den meisten OLAP-Modellen, die wir mit unserem DeltaMaster Modeler oder auch direkt im BI-Studio erstellen, gibt es die Möglichkeit, Kennzahlen kumuliert darzustellen. Die Kumulation wird meistens per MDX im Cubescript angelegt, zum Beispiel über eine Aggregate-Anweisung wie in folgendem Beispiel, in welchem die bisher nicht kumulierten Kennzahlen auf Jahresebene aggregiert werden:
![]()
Aggregate(PeriodsToDate([Period].[Period].[Year], [Peri-od].[Period].CurrentMember),[Cumulation].[Cumulation].[Cumulation].&[1])
Alternativ können kumulierte Kennzahlen auch bereits auf der relationalen Datenbank ermittelt werden wie es im Blogbeitrag „SUM-Where OVER the rainbow“ schon sehr anschaulich von Torsten Krebs beschrieben wurde.
Mitunter ist es aber erforderlich kumuliert gelieferte Daten wieder zu dekumulieren.
Auch dies lässt sich mit MDX-Anweisungen im Cubescript lösen. Diese werden dann jeweils zur Laufzeit ausgeführt. Müssen nun sehr viele Kennzahlen dekumuliert werden, kann das bei Ausführung zur Laufzeit sehr schnell zu Performanceproblemen führen. Diese werden dann häufig und zu Unrecht Delta-Master angelastet. Um dem Anwender unnötige Wartezeiten durch solche Berechnungen zu ersparen, ist es sinnvoll, so viele Berechnungen wie nur möglich in der relationalen Datenbank auszuführen. Das gilt generell und nicht nur für die hier angesprochene Dekumulation. Nur gab es bis zur SQL-Server-Version 2008r2 für die Dekumulation auf relationaler Ebene nur sehr eingeschränkte Möglichkeiten.
Ab der Version SQL Server 2012 jedoch gibt es Funktionen, sogenannte Fensterfunktionen, die uns genau dabei unterstützen können.
In diesem Blogbeitrag soll es speziell um die Möglichkeit der Dekumulation von Kennzahlen mithilfe der LAG()-Funktion gehen. Im Blogartikel „Per LAG und LEAD von der Bilanz zum Cash Flow Statement“ wird eine Anwendungsmöglichkeit dieser Funktion bereits beschrieben.
Wie funktioniert LAG()?
Die Funktion LAG() ist denen, die mit MDX arbeiten, geläufig. Mit Referenzelement.LAG(n) wird das Element ermittelt, welches n Elemente vor dem Referenzelement liegt. Ist n positiv wird ein Vorgängerelement zurückgegeben, ist n negativ ein nachfolgendes Element.
Beispiel:

SELECT
[Measures].[Umsatz] ON 0,
{[Periode].[Periode].[Jahr].&[2015], [Periode].[Periode].[Jahr].&[2015].LAG(1)} ON 1
FROM [Chair]
Das Ergebnis ist der Gesamtumsatz der Jahre 2015 und des Vorjahres 2014, wobei das Jahr 2014 als Vorgänger zum Jahr 2015 ermittelt wird:
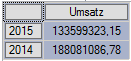 Abbildung 1 Ergebnis der MDX-Abfrage
Abbildung 1 Ergebnis der MDX-Abfrage
Die Syntax der LAG()-Funktion in SQL Server ist ein wenig anders, wie im folgenden Beispiel gezeigt wird.
Diese Funktion „greift im gleichen Resultset auf Daten in einer vorherigen Zeile zu, ohne dass ein Selbst-join in SQL Server 2012 verwendet wird“, so die Beschreibung aus der Microsoft-MSDN-Library.
Lag() verwendet folgende Parameter:
LAG (scalar_expression [,offset] [,default]) OVER ( [ partition_by_clause ] order_by_clause )
Scalar expression – die numerische Spalte einer Datenbanktabelle, deren Vorgänger ermittelt werden soll.
Offset – der Abstand des Vorgängerwertes zum aktuellen Wert, immer ein ganzzahliger nicht negativer Wert.
Default – Der Wert, der zurückgeben werden soll, wenn es keinen Vorgänger gibt oder dieser NULL ist.
OVER
partition_by_clause – Angabe der Tabellenspalten, nach denen unterteilt werden soll.
order_by_clause – Angabe der Tabellenspalten, nach denen sortiert werden soll.
Beispiel:
![]()
LAG(Umsatz_kum, 1, 0) OVER (PARTITION BY Wertart, Kunde, Produkt, Stoffgruppe ORDER BY Monat)
Der direkte Vorgänger der Spalte Umsatz_kum soll pro Wertart, Kunde, Produkt und Stoffgruppe er-mittelt und nach Monat sortiert werden. Der default-Wert, wenn kein Vorgänger vorhanden ist, ist „0“.
Um die Funktion auszuprobieren, können wir uns in unserer bekannten Demo-Datenbank Chair eine Tabelle mit einem nicht-kumulierten Umsatz und einem kumulierten Umsatz mit folgendem SQL-Statement aus der Tabelle T_Import_Deckungsbeitragsrechnung anlegen:

-- SELECT Beispieltabelle LAG()
SELECT
REPLACE(deb.Customer,'Geo','Kunde') Kunde
, deb.Product Produkt
, deb.Color Stoffgruppe
, deb.[Month] as Monat
, CASE WHEN deb.Valuetype = 'I' THEN 'Ist' ELSE 'Plan' END AS Wertart
, deb.Revenues as Umsatz
, SUM(deb.Revenues) OVER (PARTITION BY deb.Customer, deb.Product, deb.Color, deb.Valuetype ORDER BY [Month]) Umsatz_kum
INTO T_Deckungsbeitrag_kum
FROM
T_Import_Deckungsbeitragsrechnung deb
WHERE
[Month] BETWEEN 201301 and 201312
and deb.Customer IN ('Geo1','Geo10')Die Funktion SUM() OVER () berechnet uns über die Felder Customer, Product, Color und ValueType und sortiert nach der Spalte Month den kumulierten Umsatz auf Basis der Kennzahl Revenues.
Oder wer wie in diesem Beispiel die Bezeichnungen anstelle der IDs verwenden möchte, hängt die entsprechenden Tabellen-Joins zu den Tabellen mit den Bezeichnungen in das Statement mit ein:
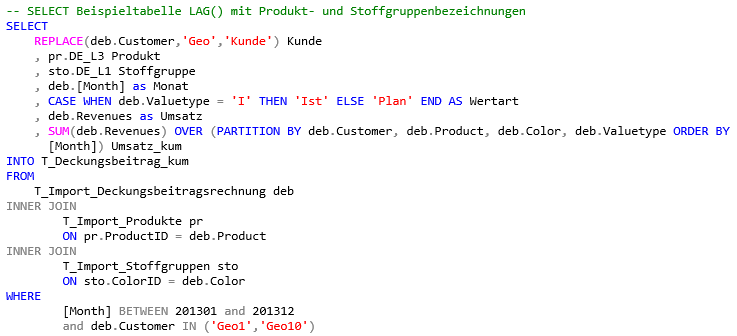
-- SELECT Beispieltabelle LAG() mit Produkt- und Stoffgruppenbezeichnungen
SELECT
REPLACE(deb.Customer,'Geo','Kunde') Kunde
, pr.DE_L3 Produkt
, sto.DE_L1 Stoffgruppe
, deb.[Month] as Monat
, CASE WHEN deb.Valuetype = 'I' THEN 'Ist' ELSE 'Plan' END AS Wertart
, deb.Revenues as Umsatz
, SUM(deb.Revenues) OVER (PARTITION BY deb.Customer, deb.Product, deb.Color, deb.Valuetype ORDER BY
[Month]) Umsatz_kum
INTO T_Deckungsbeitrag_kum
FROM
T_Import_Deckungsbeitragsrechnung deb
INNER JOIN
T_Import_Produkte pr
ON pr.ProductID = deb.Product
INNER JOIN
T_Import_Stoffgruppen sto
ON sto.ColorID = deb.Color
WHERE
[Month] BETWEEN 201301 and 201312
and deb.Customer IN ('Geo1','Geo10')Das Ergebnis zeigt folgender Select (Select1), bei welchem bewusst das Ergebnis mit der WHERE-Bedingung eingeschränkt wird, um die Anzahl zurückgegebener Zeilen aus Platzgründen etwas einzuschränken:

-- SELECT Anzeige Datensätze für Kunde1, Wertart=Ist aus Tabelle T_Deckungsbeitrag_kum
SELECT
*
FROM T_Deckungsbeitrag_kum
WHERE Kunde = 'Kunde1'
AND Wertart = 'Ist'
ORDER BY Wertart, Kunde, Produkt, Stoffgruppe, Monat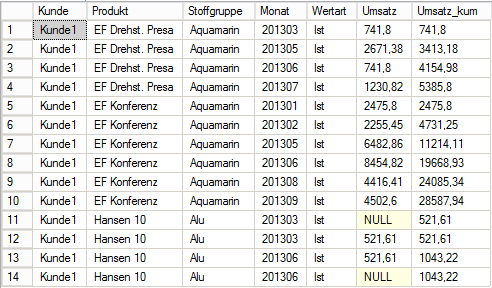
Abbildung 2 Ergebnis Select 1
Nun kommt die LAG()-Funktion zum Einsatz, um aus den zuvor kumulierten Werten wieder die nicht-kumulierten Werte zu erhalten.
Dafür erstellen wir folgende SQL-Anweisung (Select2) mit der gleichen einschränkenden WHERE-Bedingung wie im vorhergehenden Select:
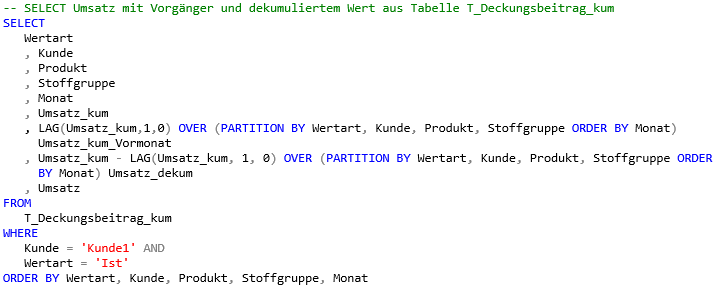
-- SELECT Umsatz mit Vorgänger und dekumuliertem Wert aus Tabelle T_Deckungsbeitrag_kum
SELECT
Wertart
, Kunde
, Produkt
, Stoffgruppe
, Monat
, Umsatz_kum
, LAG(Umsatz_kum,1,0) OVER (PARTITION BY Wertart, Kunde, Produkt, Stoffgruppe ORDER BY Monat)
Umsatz_kum_Vormonat
, Umsatz_kum - LAG(Umsatz_kum, 1, 0) OVER (PARTITION BY Wertart, Kunde, Produkt, Stoffgruppe OR-DER
BY Monat) Umsatz_dekum
, Umsatz
FROM
T_Deckungsbeitrag_kum
WHERE
Kunde = 'Kunde1' AND
Wertart = 'Ist'
ORDER BY Wertart, Kunde, Produkt, Stoffgruppe, Monat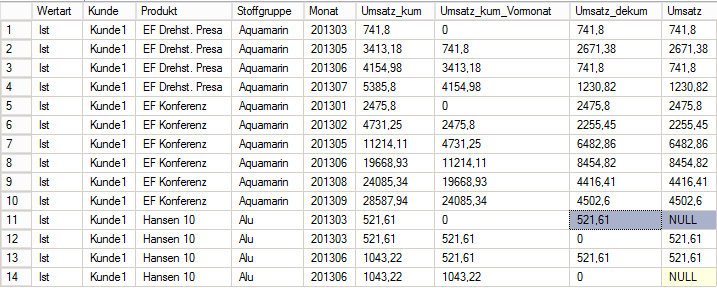
Abbildung 3 Ergebnis Select 2
Um eine bessere Vergleichbarkeit zu erhalten, habe ich die originale Umsatz-Kennzahl als letzte Spalte in der Tabelle neben den neu berechneten Wert Umsatz_dekum gestellt.
Sehr schön zu erkennen ist, dass die LAG-Funktion zunächst den Vorgänger des kumulierten Umsatzes auf der Ebene Wertart, Kunde, Produkt und Stoffgruppe sortiert nach Monat ermittelt – Spalte „Um-satz_kum_Vormonat“. Die Dekumulation ergibt sich dann erst durch die Subtraktion des so ermittelten Vorgängers vom kumulierten Wert. So enthält die Spalte „Umsatz_dekum“ die gleichen Werte wie die Spalte „Umsatz“. Hoppla, aber nur beinah – was ist denn in Zeile 11 passiert?
Wenn man sich die Tabelle in Abb. 3 oder auch in Abb. 2 anschaut, erkennt man, dass hier jeweils 2 Datensätze zu einer Monat-Kunde-Produkt-Stoffgruppe-Wertart-Kombination existieren. Der Grund hierfür ist, dass es in der Ursprungstabelle T_Import_Deckungsbeitrag u. a. für diesen Kunden (Geo1 = Kunde1) 2 Datensätze pro Customer, Valuetype, Product, Color und Month gibt, wobei nur ein Datensatz einen Wert für Revenues = Umsatz aufweist:

Abbildung 4 Datensätze für Kunde1(Geo1), Produkt Hansen10(P16), Wertart Ist(I) und Monat 201303
Die Daten werden bei der Kumulation mit OVER bzw. beim Ermitteln des Vorgängerwertes mit LAG() nicht automatisch gruppiert – das müssen wir schon selbst erledigen.
Aber als geübte SQL-er fällt uns das nicht schwer. Beachten müssen wir dabei nur, dass Fensterfunktionen zu denen LAG() gehört, nicht im Kontext einer anderen Funktion oder eines anderen Aggregats verwendet werden können. D.h.: ![]() funktioniert nicht.
funktioniert nicht.
MAX(LAG(Umsatz_kum,1,0) OVER (PARTITION BY Wertart, Kunde, Produkt, Stoffgruppe ORDER BY Monat)So sieht das korrekte SQL-Statement (Select 3) wie folgt aus:
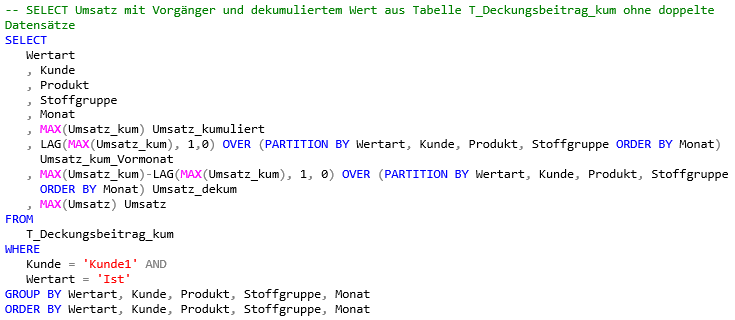
-- SELECT Umsatz mit Vorgänger und dekumuliertem Wert aus Tabelle T_Deckungsbeitrag_kum ohne doppel-te Datensätze
SELECT
Wertart
, Kunde
, Produkt
, Stoffgruppe
, Monat
, MAX(Umsatz_kum) Umsatz_kumuliert
, LAG(MAX(Umsatz_kum), 1,0) OVER (PARTITION BY Wertart, Kunde, Produkt, Stoffgruppe ORDER BY Mo-nat)
Umsatz_kum_Vormonat
, MAX(Umsatz_kum)-LAG(MAX(Umsatz_kum), 1, 0) OVER (PARTITION BY Wertart, Kunde, Produkt, Stoff-gruppe
ORDER BY Monat) Umsatz_dekum
, MAX(Umsatz) Umsatz
FROM
T_Deckungsbeitrag_kum
WHERE
Kunde = 'Kunde1' AND
Wertart = 'Ist'
GROUP BY Wertart, Kunde, Produkt, Stoffgruppe, Monat
ORDER BY Wertart, Kunde, Produkt, Stoffgruppe, MonatDamit erhalten wir dann auch das korrekte Ergebnis:
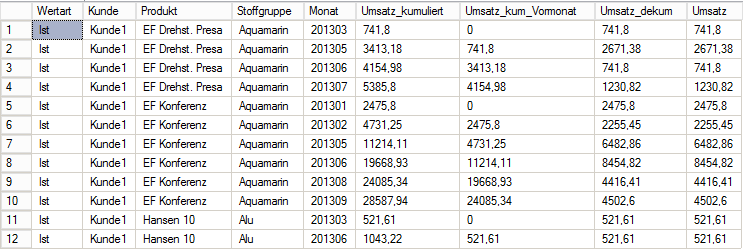
Abbildung 5 Ergebnis Select 3
Was bringt uns das Dekumulieren mithilfe der SQL-Funktion LAG()?
Wenn wie hier im gezeigten Bespiel die Kennzahl Umsatz bereits als Monatswert vorliegt natürlich nichts. Aber es gibt Praxisfälle, bei denen man nur kumulierte Kennzahlen geliefert bekommt, plötzlich aber vor der Aufgabe steht, diese dekumulieren zu müssen um mit den nicht-kumulierten Werten weite-re Berechnungen durchzuführen.
Man kann die Dekumulation im Cubeskript ausführen, wenn sich dadurch die Performance der Abfra-gen und der Berichte im DeltaMaster nicht signifikant verschlechtert. Wir haben aber mit der Verlagerung der Dekumulation in die relationale Datenbank eine deutliche Performanceverbesserung erzielen können. Berichte, die im DeltaMaster zuvor 20 – 30 Minuten gedauert haben, konnten nun in 15 – 20 Sekunden ausgeführt werden.
Natürlich erhöht sich mit jeder Berechnung in der relationalen Datenbank die Zeit der Datenaufbereitung (Transform_All) – in diesem konkreten Fall um fünf Minuten. Aber dies ist durch die enorme Zeitersparnis in DeltaMaster mehr als gerechtfertigt.
