Distinct Count Measures werden im Allgemeinen dazu verwendet, die Anzahl unterschiedlicher Elemente einer Dimension in der Faktentabelle zu bestimmen.
Beispielsweise wird in einem Auftrags-Cube bestimmt, wie viele unterschiedliche Aufträge es für die einzelnen Arbeitsschritte gibt.
Ein weiteres Beispiel: In einem Cube für die Zählung der Besuche unserer Kunden wird bestimmt, wie viele unterschiedliche Vertriebsmitarbeiter die Besuche durchgeführt haben. (Kunde A, B und C werden vom Vertriebsmitarbeiter Müller besucht. Somit ergibt sich zwar die Zahl 3 für die „Anzahl Besuche“, aber die Zahl 1 für die „Anzahl unterschiedlicher Mitarbeiter“.)
Implementierungsansätze in einem Data Warehouse (DWH)
Voraussetzung für die Erstellung eines Distinct Count (DC) Analysewertes ist das Vorhandensein einer numerischen Spalte in der Faktentabelle.
Nehmen wir das obige Beispiel mit den Aufträgen. Die Faktentabelle hierfür sieht folgendermaßen aus:
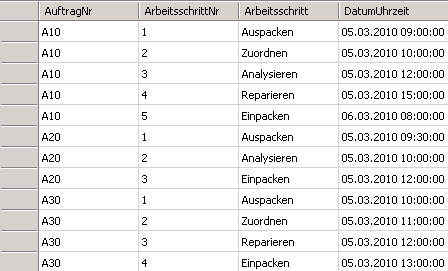
Wie schon erwähnt, geht es hier um Aufträge mit ihren Arbeitsschritten. Es ergeben sich 12 Datensätze für insgesamt 3 unterschiedliche (Distinct Count) Aufträge.
Wäre die Tabellenspalte „AuftragsNr“ numerisch, dann könnten wir umgehend mit der Erstellung des Distinct Count Analaysewertes in Analysis Services (SSAS) beginnen. Durch den alphanumerischen Spaltentyp und die oben beschriebene Voraussetzung für DC-Analysewerte müssen wir aber erst für eine numerische Spalte sorgen.
Folgende SQL-Funktion generiert für jedes einzelne Zeichen der Spalte „AuftragNr“ seinen dazugehörigen ASCII-Codewert:
Create Function [dbo].[f_Convert_Varchar_Bigint] (@inputvarchar varchar (50))
Returns bigint
as
Begin
Declare @len_zähler int
declare @outputvarchar varchar (100)
Declare @outputint bigint
set @len_zähler = 1
set @outputvarchar = ''
While len(@inputvarchar) >= @len_zähler
Begin
set @outputvarchar = @outputvarchar + Case When isnumeric (substring(@inputvarchar,@len_zähler,1)) = 1
then (substring(@inputvarchar,@len_zähler,1)) Else convert(varchar, ascii (substring(@inputvarchar,@len_zähler,1))) end
set @len_zähler = @len_zähler + 1
End
set @outputint = convert (bigint, left(@outputvarchar,18))
Return @outputint
End
Nun setzen wir diese Funktion ein, um bei der Erstellung der Fakt-View aus der Text-Spalte „AuftragNr“ eine neue numerische Spalte „AuftragNr_NEWID“ zu erzeugen:
CREATE VIEW V_IMPORT_FACT_Arbeitsschritte AS
SELECT [AuftragNr]
,[ArbeitsschrittNr]
,[Arbeitsschritt]
,[DatumUhrzeit]
,[dbo].[f_Convert_Varchar_Bigint]([AuftragNr]) AuftragNr_NEWID
FROM [dbo].[T_IMPORT_Basisdaten]
Die Datenquelle (Faktentabelle) sieht schließlich folgendermaßen aus:
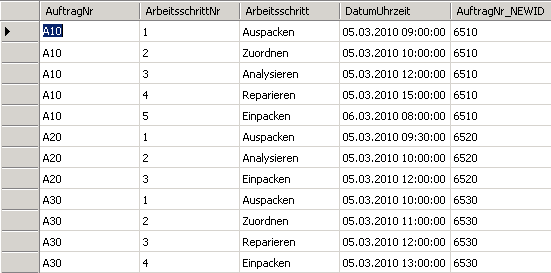
Die oben beschriebene Funktion „f_Convert_Varchar_Bigint“ ist eine limitierte Möglichkeit der „Num-Key“-Erstellung und ist nur bei kurzen Textspalten empfehlenswert. Denn bei jedem weiteren Zeichen wächst einerseits die Gefahr eines Typ-Überlaufs, man stelle sich E-Mail-Adressen als Keyspalte vor, andrerseits iteriert die Funktion Zeichen für Zeichen und mit zunehmender Textlänge leidet die Performanz.
Eine zweite weitaus elegantere Lösung ist der Einsatz einer sogenannten Zwischentabelle.
Sie beinhaltet zwei Spalten. Eine „Autowert“-Spalte und die unterschiedlichen Auftragsnummern.
Zuerst erzeugen wir uns die neue Tabelle „T_MAP_AuftragNr“:
SELECT [AuftragNr]
INTO [dbo].[T_MAP_AuftragNr]
FROM [dbo].[T_IMPORT_Basisdaten]
GROUP BY [AuftragNr]
Nun wird sie mit dem neuen „Autowert”-Feld angereichert:
ALTER TABLE T_MAP_AuftragNr ADD
AuftragNr_NEWID bigint NOT NULL IDENTITY (1, 1)
Folgende neue Tabelle steht nun zur Verfügung:

Jetzt wird die Faktensicht (Fact View) um die Spalte „AuftragNr_NEWID“ aus der Mappingtabelle erweitert:
Create View V_IMPORT_FACT_Arbeitsschritte AS
SELECT f.[AuftragNr]
,f.[ArbeitsschrittNr]
,f.[Arbeitsschritt]
,f.[DatumUhrzeit]
,map.[AuftragNr_NEWID]
FROM [dbo].[T_IMPORT_Basisdaten_SAJ] f
LEFT JOIN dbo.T_MAP_AuftragNr map on
f.[AuftragNr] = map.[AuftragNr]
Das Ergebnis steht nun bereit und ist die Quelle für die Befüllung des OLAP-Würfels:
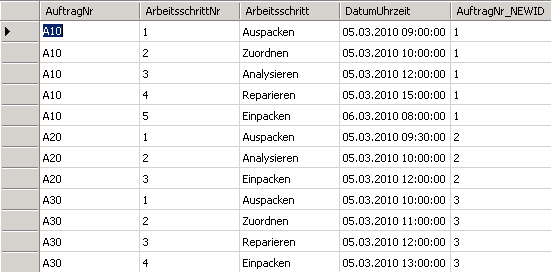
Für eine spätere Automatisierung, d. h. das Hinzufügen neuer AuftragNr in die Mappingtabelle sorgt folgendes SQL-Skript:
INSERT INTO dbo.T_MAP_AuftragNr
([AuftragNr])
SELECT [AuftragNr]
FROM [dbo].[T_IMPORT_Basisdaten_SAJ]
GROUP BY [AuftragNr]
HAVING [AuftragNr] NOT IN (SELECT [AuftragNr] FROM dbo.T_MAP_AuftragNr)
Erstellung einer regulären Measuregruppe
Nachdem alle notwendigen Anbindungen an die relationale Datenbank sowie die Anlage aller benötigten Dimensionen im „SQL Server Business Intelligence Development Studio“ (SSBIDS) erfolgt sind, kreieren wir zuerst die reguläre Measuregruppe. Diese beinhaltet lediglich den Analysewert „Anzahl Arbeitsschritte“, was der Analysis Services automatisch für uns anlegt. Wir benennen ihn nur um.
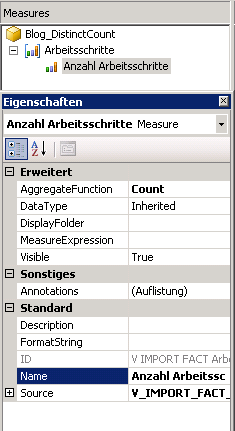
Für diese Kennzahl ändert SSBIDS die Eigenschaft „AggregateFunction“ in „Count“ um und zählt für uns jeden Datensatz. Das wäre äquivalent mit der Erstellung einer Spalte in DWH und ihrer Befüllung mit 1. Also ein einfacher Zähler.
Implementierung Distinct Count Measuregruppe
Empfehlungen zu „Best Practice“
Um die optimale Leistung zu erzielen, fassen wir in der Regel Measuregruppen, die über die gleiche Dimensionalität und Granularität verfügen, in einer Measuregruppe zusammen.
Measuregruppen, die Distinct Count Measures enthalten, dürfen jedoch nicht in einer Measuregruppe zusammengefasst werden. Um die bestmögliche Performanz zu gewährleisten, fügt man jedes Distinct Count Measure in eine eigene Measuregruppe ein. Jede (Distinct Count) Measuregruppe sollte über die gleiche Dimensionalität und Granularität wie die anderen Measures der betreffenden Faktentabelle verfügen.
Wir wählen also im Kontextmenü der vorhandenen Measuregruppe „Arbeitsschritte“ den Punkt „Neues Measure…“ aus.
Folgende Dialogbox erscheint:
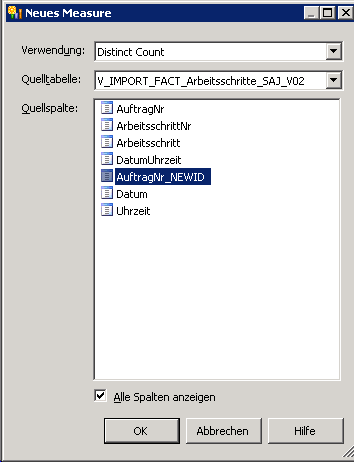
In der Listbox „Verwendung“ selektiert man die Aggregatfunktion „Distinct Count“ und aus der „Quellspalte“ das Feld „AuftragNr_NEWID“, das wir mit Hilfe der Mapping-Tabelle in DWH erzeugt hatten.
Nach Bestätigung der Dialogbox, legt SSBIDS automatisch sowohl eine neue Measuregruppe als auch eine neue Measure an. Beide nennen wir passend um:
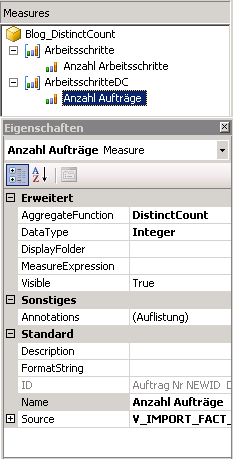
Für die neue Kennzahl „Anzahl Aufträge“ ändert SSBIDS die Eigenschaft „AggregateFunction“ in „DistinctCount“ um und zählt für uns jeden eindeutigen Auftrag.
Vorteil dieser Vorgehensweise ist, dass SSBIDS automatisch eine neue Measuregruppe anlegt, sobald die Option „Verwendung“ auf „DistinctCount“ eingestellt wird. Das entspricht dem „Best Practice“-Konzept.
Werfen wir nun einen Blick auf die Registerkarte „Dimensionsverwendung“:
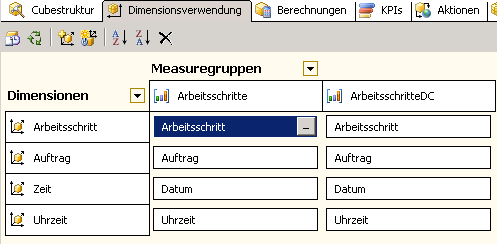
Wie schon weiter oben erwähnt, verfügt unsere Distinct Count-Measuregruppe über die gleiche Dimensionalität und Granularität wie der Analysewert „Anzahl Arbeitsschritte“ in der Measuregruppe „Arbeitsschritte“ mit der gemeinsamen Faktentabelle.
Zur Veranschaulichung erstellen wir in DeltaMaster eine neue Analysesitzung und kreieren folgendes Pivot-Cockpit:
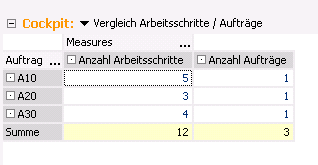
Das Cockpit präsentiert uns den Vergleich. In der Tat haben wir insgesamt 12 Datensätze in unserer Faktentabelle, die die Arbeitsschritte darstellen. Diese wurden aber in nur drei unterschiedlichen (Distinct) Aufträgen erzeugt.
- Alternativer Ansatz
Grundsätzlich ist es möglich, über eine FactView, die die Aufträge gruppiert, in Kombination mit „m:n-Measuregroups“ (vgl. Blog: m:n-Dimensionsbeziehungen in Microsoft Analysis Services definieren) identische Ergebnisse zu erhalten. Dabei ist jedoch unbedingt zu beachten, dass zum Beispiel abweichendes Datum/Uhrzeit das Detailverhalten und somit die Zählung beeinflussen.
In unserem Beispiel hat die Gruppierung über Aufträge zur Folge, dass wir uns für ein Datum und eine Uhrzeit entscheiden müssen (Min oder Max).
Wenn später in SSBIDS diese Dimensionen in der Registerkarte „Dimensionsverwendung“ des Cube-Editors der Measuregruppe „Aufträge“ zugeordnet werden, weicht der Analysewert „Anzahl Aufträge“ der Measuregruppe mit m:n-Zuordnung von der entsprechenden Kennzahl der Distinct Count Measuregruppe ab, weil die sogenannten „Non-Matching“ Datensätze nicht gezählt werden.
