Ab einer bestimmten Größe wird es sehr unhandlich, eine Faktentabelle bei jeder Aktualisierung komplett zu laden. In diesem Fall muss der Aktualisierungsprozess so verändert werden, dass möglichst nur neue oder geänderte Datensätze geladen werden. Das nennen wir „Inkrementelles Laden“. Solch ein Laden stellt neue Anforderungen an den verwendeten SQL-Code und die Performance-Optimierungen. War es z. B. beim Komplettladen möglich, die Faktentabelle mit dem sehr schnellen TRUNCATE-Befehl zu löschen, ist das jetzt nicht mehr möglich, da nur noch die Daten gelöscht werden dürfen, die sich geändert haben. Ein entsprechender DELETE-Befehl kann aber viele Ressourcen und viel Zeit kosten.
Ein weiteres Problem ist, dass die Zeilen, die sich geändert haben und diejenigen, die hinzukommen, nicht immer einwandfrei identifizierbar sind. Deshalb wird es in der Praxis meistens auf einen Kompromiss hinauslaufen. Ein Kompromiss könnte z. B. so aussehen: Für FIBU-Daten ist nicht er-kennbar, welche Datenzeilen geändert und welche hinzugefügt werden müssen. Was aber bekannt ist: Es können sich nur Datenzeilen im aktuellen Geschäftsjahr ändern. Also werden die Datenzeilen des aktuellen Geschäftsjahres komplett gelöscht (auch die, die sich gar nicht geändert haben) und das Geschäftsjahr wird komplett neu geladen, die alten Geschäftsjahre bleiben aber unberührt.
Das bei uns am häufigsten eingesetzte Verfahren für inkrementelles Laden, soll hier „Mehrere-Faktentabellen-Verfahren“ genannt werden. Dabei wird, um auf das gerade angesprochene Beispiel zurückzukommen, für jedes Geschäftsjahr eine Faktentabelle angelegt und in der multidimensionalen Datenbank kann dann für jede einzelne relationale Faktentabelle eine Partition angelegt werden. Das Verfahren wird auch wunderbar durch DeltaMaster Modeler unterstützt, der durch die Einstellung „PartitionPerSourceTable“ solch ein Modell schnell aufbaut. Für einen Nachteil dieses Verfahrens ist zu sehen, dass sobald z. B. ein neues Geschäftsjahr hinzukommt, eine neue Faktentabelle und der ganze zugehörige „Rattenschwanz“ neu angelegt werden muss. Das Modell muss also periodisch erweitert werden.
In diesem Blogbeitrag soll noch ein anderes Verfahren vorgestellt werden, dass einerseits etwas flexibler an die Anforderungen des jeweiligen Modells angepasst werden kann, andererseits aber auch das periodische Erweitern des Modells überflüssig macht. All das erfordert jedoch deutlich mehr Komplexität, wie noch ersichtlich sein wird.
Ausgangspunkt der theoretischen Überlegungen ist dabei eine Variation des Speichermodells einer multidimensionalen Measuregroup mit fester Anzahl von Partitionen. Die einzelnen multidimensionalen Partitionen sollen dabei Daten mit ähnlicher Abfragehäufigkeit bündeln. Stellt man möglich-erweise fest, dass die Daten der aktuellen Periode sehr häufig abgefragt werden, die restlichen Daten des aktuellen Jahres schon etwas weniger und die Vorjahresdaten nur noch sporadisch, macht es Sinn, die Daten nach diesen drei „Verwendungsklassen“ multidimensional zu partitionieren. Dadurch ist es möglich, häufig genutzte Daten in kleinen und schnell verfügbaren Partitionen zu platzieren und weniger häufig genutzte Daten in größeren Partitionen zu speichern.
Für jede der multidimensionalen Partitionen wird nun auch relational eine Quelltabelle angelegt. Die Anzahl der Quelltabellen ist also auch immer gleichbleibend.
Beim Aktualisieren der Daten muss nun auf zwei Aspekte reagiert werden: zum einen müssen immer noch alle aktualisierten und neuen Daten einfließen, zum anderen müssen aber auch die Daten entsprechend dem Nutzungsverhalten in den Faktentabellen gespeichert werden.
Um tiefer in das Thema einzusteigen, wählen wir jetzt ein bestimmtes Szenario, an dem man dann die Einzelheiten besser erläutern kann: Der Kunde hat herausgefunden, dass am häufigsten die Zahlen für den aktuellen Monat verwendet werden. Weniger häufig werden Zahlen der letzten 12 Monate verwendet (deckt z. B. auch die Vormonatswerte ab). Außerdem sollen insgesamt nur die Werte der letzten 36 Monate auswertbar sein. Alles, das älter ist, wird nicht mehr in der multidimensionalen Datenbank benötigt. Außerdem ist bekannt, dass sich nur die Werte für den aktuellen Monat ändern können. Alle älteren Daten bleiben in der Regel unverändert. Sollte jedoch der außerordentliche Fall auftreten, dass sich ältere Daten ändern, wird dies entsprechend bekannt sein und das Modell muss in der Lage sein, darauf zu reagieren.
Vorbereitungen
Zum Blog gehören zwei Gruppen von SQL-Scripts. Die erste Gruppe demonstriert konkret die Umsetzung dieses Beispiels und die zweite Gruppe soll als Vorlage verstanden werden, um selbst möglichst rasch solch ein Szenario aufbauen zu können.
Konkretes Beispiel
- Vorbereitungen.sql
- Create_rel_Partitions_01_Deckungsbeitragsrechnung.sql
- P_Partition_Transform_FACT_01_Deckungsbeitragsrechnung.sql
Verallgemeinerung
- Create_rel_Partions.sql
- P_Partition_Transform_FACT_XXX.sql
Für das Verfahren ist es wichtig, die „Aktuelle Periode“ zu definieren. Das kann mit einer Abfrage auf die Quelltabellen erfolgen. Dafür soll eine dedizierte Tabelle zur Verfügung gestellt werden (T_S_CurrentSlice mit Spalte CurrentSlice).
Damit durch den Modeler drei Faktentabellen und die entsprechenden multidimensionalen Partitionen erstellt werden können, werden entsprechende Import-Views angelegt. In denen wird die Definition der drei Partitionen umgesetzt:


--Erzeugen von 3 source-views für 3 Fact-Tabellen:
Create View V_Import_FACT_Partition1 as
Select *
from V_Import_FACT
where Month = (Select CurrentSlice from T_S_CurrentSlice)
go
Create View V_Import_FACT_Partition2 as
Select *
from V_Import_FACT
cross apply
(Select Convert(varchar(6),
DateAdd(month,-1,
Convert(datetime,
Cast(CurrentSlice as varchar(6)) + '01'
)
)
,112) BIS,
Convert(varchar(6),
DateAdd(month,-12,
Convert(datetime,
Cast(CurrentSlice as varchar(6)) + '01'
)
)
,112) VON
from T_S_CurrentSlice
) t
where Month between t.VON and t.BIS
go
Create View V_Import_FACT_Partition3 as
Select *
from V_Import_FACT
cross apply
(Select Convert(varchar(6),
DateAdd(month,-13,
Convert(datetime,
Cast(CurrentSlice as varchar(6)) + '01'
)
)
,112) BIS,
Convert(varchar(6),
DateAdd(month,-37,
Convert(datetime,
Cast(CurrentSlice as varchar(6)) + '01'
)
)
,112) VON
from T_S_CurrentSlice
) t
where Month between t.VON and t.BISIm Modeler wurde nun für die Measuregroup „Deckungsbeitragsrechnung“ die Option „Partition per src.tab.“ aktiviert…
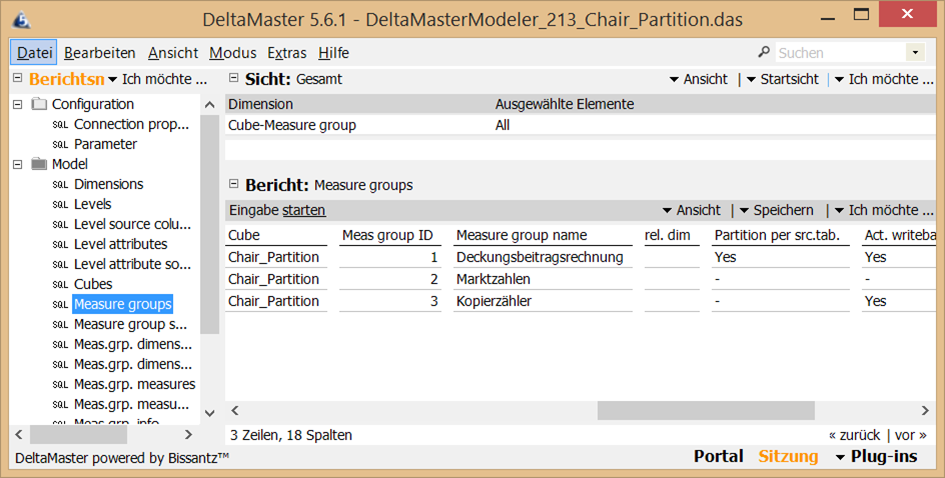
Abb. 1: Aktivierung „Partition per src.tab“ in DeltaMaster Modeler
…und in „Measure group source table“ für jede der drei Views eine Quelle angelegt. Da alle Sichten die gleiche Struktur haben, reicht es im weiteren Verlauf die Quellen für Dimensionsverknüpfungen und Measures nur einmal gültig für alle Partitionen festzulegen. Daher ist in allen Zeilen in Spalte „Def. Source table ID“ der Wert „1“ eingetragen.
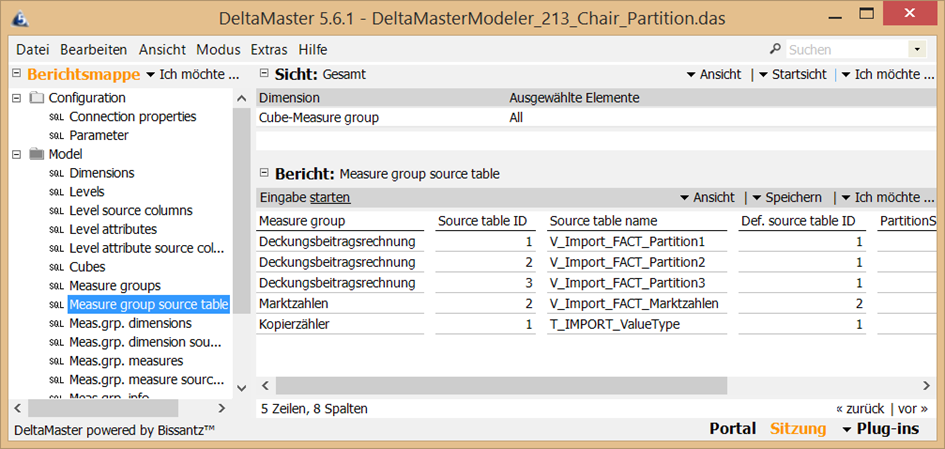
Abb. 2: Def.source table ID-Einträge in DeltaMaster Modeler
Nach Aufbau des Modells durch DeltaMaster Modeler sind die drei multidimensionalen Partitionen mit Referenz auf jeweils eine der drei Faktentabellen angelegt.
Weitere Anmerkungen zur Integration des hier vorgestellten Modells bzw. zum inkrementellen Laden in das Modeler-Umfeld sind im Kapitel 5 „Modeler-Integration“ zu finden.
Theoretische Vertiefung
Gegeben sind jetzt drei relationale Tabellen für den Inhalt der drei multidimensionalen Partitionen. Gegeben ist nun auch die Möglichkeit, diese drei Tabellen mittels Komplettladen zu füllen. Dieses Komplettladen soll durch ein inkrementelles Laden ersetzt werden. Und das soll folgendermaßen funktionieren:
Wenn die aktuelle Periode (die in der T_S_CurrentSlice-Tabelle) mit der Periode in der Faktentabelle 1 übereinstimmt, braucht nur diese aktualisiert werden.
Ändert sich die aktuelle Periode, muss nun wesentlich mehr passieren: Die Daten, die sich jetzt noch in Faktentabelle 1 befinden, müssen in Faktentabelle 2 verschoben werden, da hier Platz für die neue Periode geschaffen werden muss. Dadurch wären jetzt aber 13 Perioden in Faktentabelle 2, d. h. es muss auch eine Periode von Faktentabelle 2 in Faktentabelle 3 wandern und die allerletzte Periode in Faktentabelle 3 muss gelöscht werden.
Mittels Delete- und Insert-Befehlen sind diese Aufgaben garantiert nicht in akzeptabler Zeit zu bewältigen. Dafür werden die relationalen Tabellen partitioniert. Jede Periode bekommt ihre eigene Partition innerhalb einer der drei Faktentabellen. Mit dem Switch-Befehl können dann diese Partitionen mit geringstem Zeitaufwand hin- und hergeschoben werden, da nur ein Zeiger für jede Partition geändert werden muss. Es werden nicht wirklich Daten kopiert.
Für die Partitionen in multidimensionalen Measuregroups gibt es recht konkrete Empfehlungen von Microsoft. D. h. es ist jedem selbst überlassen, die Auswirkungen von Partitionen auf die Performance zu untersuchen. Es ist aber auf keinen Fall selbstverständlich, dass sich Partitionen positiv auf die Performance auswirken. Durch etwas mehr Komplexität in den Abfragen kann dieses Ergebnis aber erzielt werden. Wir möchten an der Stelle auf das legendäre CrossApply-Video von Itzik Ben-Gan in Microsofts Virtual Academy hinweisen ).
Praktische Umsetzung
Löschen der Faktentabellen: Die drei Faktentabellen müssen also so umgebaut werden, dass sie mit Partitionen arbeiten. Tatsächlich ist es besser, die im Moment eh noch leeren Tabellen direkt zu löschen und mit Partitionen wieder zu erstellen. Vor dem Löschen ist es hilfreich, sich ein Create-Script für eine Tabelle zu sichern. Der Aufbau der Tabelle mit Partitionen unterscheidet sich nur geringfügig vom Aufbau der Tabelle ohne Partition. Das Script ist also später noch von Nutzen. Rein technisch werden für das Vorgehen insgesamt vier Tabellen benötigt. Die vierte mit dem Zusatz _Garbage wird nur zum Löschen der nicht mehr benötigten Partitionen verwendet.
Erzeugen der Partition-Functions und Partition-Scheme: Die technischen Grundlagen für das Partitionieren von relationalen Tabellen sollen nicht Bestandteil dieser Abhandlung sein. Wer sich noch mal in die Thematik einarbeiten möchte, kann dazu in den Online-Books von Microsoft nachlesen.
Als erstes müssen die Partition-Functions für die einzelnen Tabellen erzeugt werden. Hier müssen die Grenzen zwischen den Partitionen festgelegt werden. Das kann man im Kopf tun und dann die CREATE PARTITION FUNCTION-Statements „von Hand“ erzeugen. Wir haben ein SQL-Script verwendet, welches dieselben Bedingungen verwendet, wie die am Anfang erzeugten Import-Views um automatisch das CREATE PARTITION FUNCTION-Statement zu erzeugen und auszuführen.
Ein Hinweis für die Partitionen der Faktentabelle 3: Es ist wichtig, dass die letzte Partition, die in der Faktentabelle 2 existiert, auch in der Faktentabelle 3 als erste Partition eingerichtet wird. In dieser, der ersten Partition der Faktentabelle 3, dürfen nie Daten enthalten sein. Sie dient nur dazu, eine untere Grenze für die erste echte Partition in Tabelle 3 zu definieren, sodass der SWITCH der letzten Partition der Tabelle 2 mit der „ersten echten“ Partition von Tabelle 3 funktioniert. Auf das Thema wird später näher eingegangen.
Hier der SQL-Code zum Erstellen der Partition-Function für die Faktentabelle 3:


-- SELECT#3: Ermitteln von Anfang und Endwerte für die Tabelle:
SELECT @v_To =
Convert(varchar(6),
DateAdd(month,-12,
Convert(datetime,
Cast(CurrentSlice as varchar(6)) + '01'
)
),112
)
, @v_From =
Convert(varchar(6),
DateAdd(month,-37,
Convert(datetime,
Cast(CurrentSlice as varchar(6)) + '01'
)
),112
)
, @v_dtTo =
DateAdd(month,-12,
Convert(datetime,Cast(CurrentSlice as varchar(6)) + '01'))
FROM T_S_CurrentSlice
-- SELECT#4: Slicergrenzen berechnen
Select @v_sql = y.x
from
( Select Cast(x.m as varchar) + ', '
from
(Select Distinct
YEAR(DateAdd(day, -1 *
(-1 + ROW_NUMBER() over (order by object_id)), @v_dtTo)) * 100
+ MONTH(DateAdd(day, -1 *
(-1 + ROW_NUMBER() over (order by object_id)), @v_dtTo)) m
from sys.all_objects ) x
where x.m between @v_From and @v_To
order by x.m
FOR XML Path('')
)y (x)
Set @v_sql = LEFT(@v_sql, Len(@v_sql) - 1)
Set @v_sql = 'Create Partition function PF_T_FACT_01_Deckungsbeitragsrechnung_03 (int) as range left for values (' + @v_sql + ')'
print @v_sql
--Wenn vorhanden, Scheme löschen:
if exists (Select * from sys.partition_schemes
where name = 'PS_T_FACT_01_Deckungsbeitragsrechnung_03')
drop partition scheme PS_T_FACT_01_Deckungsbeitragsrechnung_03
--Wenn vorhanden, Function löschen:
if exists(select * from sys.partition_functions
where name = 'PF_T_FACT_01_Deckungsbeitragsrechnung_03')
drop partition function PF_T_FACT_01_Deckungsbeitragsrechnung_03
--Partition Function anlegen
exec sp_executesql @v_sqlSobald die Partition-Function angelegt ist, kann diese verwendet werden, um die Partition-Scheme anzulegen:

--Partition Scheme anlegen
Create partition scheme PS_T_FACT_01_Deckungsbeitragsrechnung_03
as partition PF_T_FACT_01_Deckungsbeitragsrechnung_03 all to ([PRIMARY])Partition-Function und Partition-Scheme müssen für alle Tabellen erzeugt werden, die mehr als eine Partition enthalten sollen. Das gilt nicht für Tabelle 1, in der ja nur die aktuelle Periode gespeichert ist und auch nicht für die Garbage-Tabelle, in der nur eine Periode vorliegt, nämlich die, die gelöscht werden soll.
Anlegen der Tabellen mit Partitionen: Nun müssen die Faktentabellen mit den Partitionen-Definitionen wieder erstellt werden. Für Tabelle 1 ändert sich die Definition des Primärschlüssels. Ursprünglich besteht der Primärschlüssel nur aus der AutoID-Spalte der Tabelle. Da die Spalte, welche das Partitionskriterium enthält, auch immer Bestandteil des Primärschlüssels sein muss, wird hier die Spalte [MonatID] mit in den PK aufgenommen:
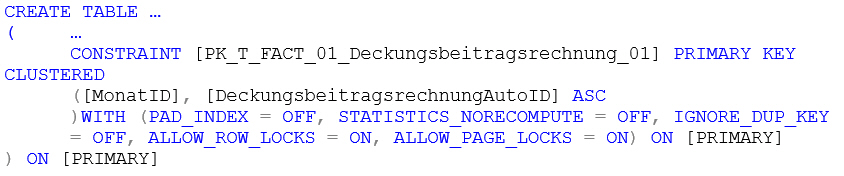
CREATE TABLE …
( …
CONSTRAINT [PK_T_FACT_01_Deckungsbeitragsrechnung_01] PRIMARY KEY CLUSTERED
([MonatID], [DeckungsbeitragsrechnungAutoID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]Tabelle 1 hat keine Partitionen, daher erscheint das auf den ersten Blick überflüssig. Da diese Tabelle aber später mit der SWITCH-Anweisung mit partitionierten Tabellen interagiert, muss der Primär-schlüssel auch wie in den partitionierten Tabellen aufgebaut werden. Beim Anlegen dieser Tabelle dürfen auch die Fremdschlüssel-Referenzen auf die Dimensionstabellen nicht vergessen werden, sowie alle weiteren Einschränkungen (Constraints), welche auf die Tabellenspalten wirken sollen.
Zusätzlich wird noch eine weitere Einschränkung auf die [MonatID]-Spalte (also die Spalte mit dem Partitionskriterium) angelegt:
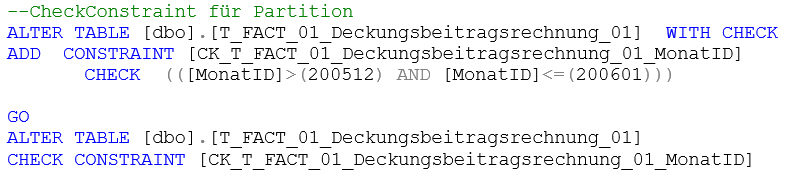
--CheckConstraint für Partition
ALTER TABLE [dbo].[T_FACT_01_Deckungsbeitragsrechnung_01] WITH CHECK
ADD CONSTRAINT [CK_T_FACT_01_Deckungsbeitragsrechnung_01_MonatID]
CHECK (([MonatID]>(200512) AND [MonatID]<=(200601)))
GO
ALTER TABLE [dbo].[T_FACT_01_Deckungsbeitragsrechnung_01]
CHECK CONSTRAINT [CK_T_FACT_01_Deckungsbeitragsrechnung_01_MonatID]Diese Einschränkung ist eine weitere Bedingung, dass später das SWITCH zwischen Tabelle 1 (un-partitioniert) und Tabelle 2 (partitioniert) erfolgreich ausgeführt werden kann. Diese Einschränkung sorgt dafür, dass alle Daten in der Tabelle 1 später auch in die neue Partition der Tabelle 2 passen.
Wenn so viel Aufwand für das Speichern der Daten in den Tabellen betrieben wird, kann man da-von ausgehen, dass die Tabellen so groß sind, dass sich eine Komprimierung der Daten lohnen wird, notwendig ist das aber nicht. Da alle Tabellen identisch aufgebaut werden müssen, müssen dann auch die Tabellen (z. B. Tabelle 1) komprimiert werden, die möglicherweise nicht sehr viel Platz einnehmen.

Alter Table [dbo].[T_FACT_01_Deckungsbeitragsrechnung_01]
REBUILD Partition = ALL WITH (DATA_COMPRESSION = PAGE)Etwas anders verhält es sich mit Tabellen 2 und 3. Diese werden zunächst auch mit dem gesicherten CREATE-TABLE-Statement erzeugt. Zusätzlich müssen natürlich noch irgendwie die Tabellen partitioniert werden. Dies geschieht, in dem als Speichermedium für Primärschlüssel und Tabelle nicht „ON PRIMARY“ angegeben wird, sondern der Verweis auf das Partition-Scheme inklusive der Zuweisung der Spalte, in dem das Partitionskriterium steckt:
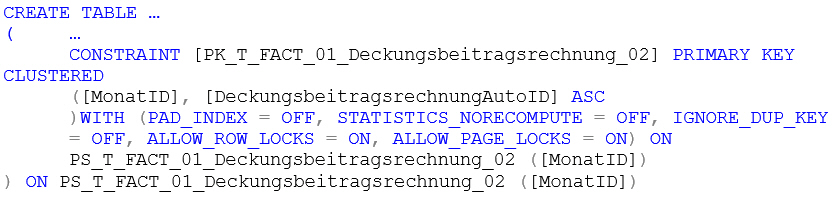
CREATE TABLE …
( …
CONSTRAINT [PK_T_FACT_01_Deckungsbeitragsrechnung_02] PRIMARY KEY CLUSTERED
([MonatID], [DeckungsbeitragsrechnungAutoID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON PS_T_FACT_01_Deckungsbeitragsrechnung_02 ([MonatID])
) ON PS_T_FACT_01_Deckungsbeitragsrechnung_02 ([MonatID])Die Fremdschlüssel-Referenzen auf die Dimensionstabellen werden bei diesen Tabellen weggelassen. Grund dafür ist das Aktualisierungsmodell des DeltaMaster Modelers. Dieses Modell sieht vor, zuerst die Faktentabellen zu löschen, dann die Dimensionstabellen. Anders herum würde es zu einem Fehler führen, da die referenzierten Datensätze der Dimensionstabellen nicht gelöscht werden können. Wenn zuerst die Faktentabellen gelöscht werden, werden keine Datensätze in den Dimensionstabellen referenziert. Es können alle gelöscht werden.
Nun befinden wir uns aber in einem Szenario, in dem die Datensätze bestimmter Faktentabellen (konkret im Beispiel: Faktentabelle 2 und 3) eben nicht gelöscht werden sollen. Welche Auswirkung gäbe es, wenn die FK-Referenzen beibehalten werden sollen? Gelöscht werden müssen sie trotzdem, für den Zeitraum, in dem die Dimensionstabellen leer sind. Danach müssen diese wieder neu angelegt werden. Aber das kostet Zeit, genau das, was wir durch das Verfahren ja einsparen wollen.
Zwei Auswege sehe ich aus dieser Lage. Der eine ist im derzeitigen Aktualisierungsmodell umsetzbar, der andere Ausweg wäre der bessere.
Ausweg 1 besteht darin, die Referenzen auf die Dimensionstabellen wegzulassen. Man kann argumentieren, dass ja alle Faktendaten in älteren Perioden bereits einmal in der Faktentabelle 1 waren und somit auch auf Konsistenz geprüft wurden. Dabei muss sichergestellt werden, dass alle, auch die nur historisch relevanten, Dimensionsdaten, wieder hergestellt werden.
Ausweg 2 wäre, auf das komplette Löschen der Dimensionsdaten zu verzichten. Eigentlich ist dafür nicht viel notwendig. Bereits in den P_DIM-Prozeduren enthalten ist ja, dass nur Dimensionselemente importiert werden, die es in der Dimensionstabelle noch nicht gibt. Auch das Ändern von vorhandenen Dimensionselementen kann man bereits einstellen (Flag „Update by KEY“ in Bericht Level source columns). Was noch fehlt ist die Möglichkeit, Dimensionstabellen vom Löschen auszuschließen (DoDeleteTable in Bericht Levels). Dies ist dort zum jetzigen Zeitpunkt nur als Hidden-Feature vorhanden. Zur Not kann man sich dieses Flag (DoDeleteTable) einbinden oder gleich von Hand einstellen. Ich möchte aber an der Stelle folgende Überlegung zu Diskussion stellen: Warum nicht die Dimensionstabellen standardmäßig gefüllt lassen und Insert und Update (schon vorhan-den) laufen lassen? Besser ist dieser Weg, weil die FK-Referenzen nicht mehr gelöscht werden müssen. Diese könnten die ganze Zeit bestehen bleiben. Die referentielle Integrität der Daten in Tabelle 2 und Tabelle 3 würden dann wieder vom SQL Server garantiert.
Die vierte Tabelle (Garbage) ist der ersten Tabelle ähnlich, da diese auch ohne Partitionsdefinitionen auskommt. Allerdings sind auch keinerlei Einschränkungen notwendig, weder Fremdschlüssel noch Check-Constraints.
Prozeduren für den Ladevorgang
Beim letzten Ausführen des „Create Snowflake“ im Modeler, nach den genannten Einstellungen wei-ter oben, wurde für jede der drei Faktentabellen eine P_FACT-Prozedur angelegt. Diese sollten nicht ausgeführt werden und daher aus dem P_FACT-Zeichenraum entfernt werden, z. B. durch Umbe-nennen in P_ALT_FACT_XXX.
Anstelle dieser Prozeduren tritt eine neue, die die Logik des Partition-Switchens enthält. Wir haben diese Prozedur P_Partition_Transform_FACT_01_Deckungsbeitragsrechnung genannt.
Diese Prozedur muss manuell in die P_Transform_All eingefügt werden.
P_Partition_Transform_FACT_XXX (~.sql)
Im Script P_Partition_Transform_FAXT_XXX.sql liegt die Prozedur, die nun beschrieben wird. Einige Bezeichnungen (z. B. SELECT#3, Abschnitt Tabelle 3) beziehen sich auf bestimmte Stellen im SQL-Code. Es ist deshalb sinnvoll, gleichzeitig zum Blog die Datei zu öffnen.
Die Prozedur verschiebt nun, sobald notwendig, alle Partitionen an ihren neuen Platz. Notwendig wird das immer dann, wenn in der Datenquelle Daten vorliegen, für die eine neue Partition erstellt werden muss. Im vorliegenden Beispiel also, immer wenn eine neue MonatID auftaucht.
Deshalb stehen ganz am Anfang der Prozedur das Extrahieren des neuen PartitionSlice und des PartitionSlice der Tabelle 1 in die Variablen @v_curr_SliceID und @v_prev_SliceID und der Ver-gleich der beiden Variablen.
Der Großteil der weiteren Prozedur wird nur ausgeführt, wenn diese beiden Variablen unterschied-lich sind, von dem wir ausgehen.
SELECT#3, SELECT#4, SELECT#5 füllt weitere SliceID-Variablen, die im weiteren Verlauf benötigt werden. Dafür werden DataManagementViews (DMVs) verwendet, die Informationen über den Partitionen-Inhalt enthalten. Es gibt eine ganze Reihe von DMVs, die sehr hilfreich sind. Es soll hier darauf verzichtet werden, diese einzeln vorzustellen, aber als Beispiel hier noch ein SQL-Statement mit Informationen zu den hier beispielhaft partitionierten Tabellen:

Select t.name, p.partition_number, p.rows,
p.data_compression_desc, v.boundary_id, v.value
FROM sys.TABLES t
JOIN sys.indexes i ON t.object_id = i.object_id
JOIN sys.partitions p on p.object_id = t.object_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON ps.function_id = pf.function_id
LEFT JOIN sys.partition_range_values v
on pf.function_id = v.function_id
and p.partition_number = v.boundary_id
where t.name like 'T_FACT_01_Deckungsbeitragsrechnung_0[1,2,3]'
order by t.name, p.partition_number desc- t.name: Name der Tabelle
- p.partition_number: Nummer der Partition. In der zweiten Zeile des Ergebnisses ist zu sehen, dass es pro Tabelle eine Partition gibt, die keine Grenze hat (v.boundary_id is null und v.value is null). Das liegt daran, dass für alle Daten in einer Tabelle Platz sein muss. Da alle Partitionen durch die eigene Grenze und die Grenze der nächsten Partition definiert sind, bleiben aber Datenbereiche verwehrt, die über der letzten Grenze liegen. Wenn also die letzte Partition mit „Monat <= 200602“ definiert ist, muss es doch eine Partition geben, die Daten mit Monat = 200603 oder darüber aufnimmt.
- p.rows: Anzahl der Datenzeilen in der Partition
- v.boundary_id: Grenz-ID, entspricht der partition_number
- v.value: Grenzwert
Abschnitt Tabelle 3. Das Verschieben der Partitionen beginnt von hinten. Der erste Schritt ist also, die letzte Partition der Tabelle 3 in die Tabelle 4 zu schieben und diese mit einem TRUNCATE-TABLE-Statement zu löschen. Vor dem SWITCH-Befehl wird sicherheitshalber die Tabelle 4 auch geleert, da sollte aber sowieso nichts drinstehen.
Nun ist diese letzte Partition der Tabelle 3 überflüssig geworden und wird mit einem MERGE-Befehl entfernt. Soll eine neue Partition in einer Tabelle erstellt werden, muss vorher mit „ALTER PARTITION … NEXT USED…“ festgelegt werden, in welche Filegroup die neue Partition kommt. Des letzte Statement im Abschnitt „Tabelle 3“ legt eine neue Partition in Tabelle 3 an. Dazu noch ein Hinweis:
Überlappung der Tabellen-Partitionen. Folgendes Beispiel soll das noch einmal verdeutlichen. Gegeben ist eine Situation, in der die erste Partition (Partition mit den ältesten Daten) der Tabelle 2 Werte des Monats 200501 enthält und die letzte Partition der Tabelle 3 Werte des Monats 200412. Wenn jetzt die Werte des Monats 200501 in die Tabelle 3 verschoben werden sollen, muss natürlich erst einmal eine solche Partition angelegt werden. Nun ist jedoch die Partition in Tabelle 2 die erste Partition, d. h. hier würden auch Daten < 200501 reinpassen. Deshalb ist ein Verschieben dieser Werte in Tabelle 3 nicht möglich, da dort eine weitere Grenze für die Partition existiert, nämlich die Grenze der nächsten Partition (200412). Es muss also in Tabelle 2 noch eine Partition 200412 angelegt sein, damit die Partition mit den Werten für 200501 auch 2 Grenzen hat, eine eigene und eine „darunter“. Das ist der Grund für die Überlappung der Tabellen-Partitionen der Tabellen 2 und 3.
Abschnitt Tabelle 2. Der erste Befehl im Abschnitt Tabelle 2 verschiebt nun die erste Partition (Partition mit den ältesten Daten) der Tabelle 2 an die letzte Stelle in Tabelle 3 (Partition 2 auf Partition 25 -> siehe „Überlappung der Tabellen-Partitionen“). Dann wird diese erste Partition mit einem Merge-Befehl gelöscht, die Filegroup für die nächste Partition festgelegt und eine neue letzte Partition in Tabelle 2 mittels SPLIT-Befehl angelegt.
Dann wird der Inhalt der Tabelle 1 in die letzte (neue) Partition der Tabelle 2 verschoben. Dadurch ist auch die Tabelle 1 leer. Die restlichen beiden Befehle sind Tabelle 1-Befehle: die Check-Einschränkung auf der Tabelle wird gelöscht und so wieder angelegt, dass die neuen Daten in die Tabelle 1 passen.
Rest der Prozedur P_Partition_Transform_FACT_XXX (~.sql)
Wenn sich am aktuellen Slice nichts ändert, wird einfach nur die Tabelle 1 gelöscht.
Als letzter Befehl wird die P_FACT-Prozedur der Tabelle 1 aufgerufen, um die Tabelle mit den neu-en Daten zu füllen. Damit dieser erfolgreich läuft, wird vorher das entsprechende Fill-table-Flag gesetzt aber danach auch wieder gelöscht.
Modeler-Integration
Die hier vorgestellte Vorgehensweise zum Füllen der Faktentabellen wird vom DeltaMaster Modeler nicht unterstützt. Der Modeler bietet aber genügend Möglichkeiten für Freiraum, in dem diese Vorgehensweise Platz hat.
Wie am Anfang erläutert, sollen die regulären Prozeduren zum Laden der Faktentabellen durchaus erstellt werden. Für ein vollständiges Laden können diese herangezogen werden. Jedoch sollen diese auf gar keinen Fall innerhalb der P_Transform_All ausgeführt werden. Daher ist dies im Modeler im Bericht „Measure group source table“ einzustellen (Del.table und Fill table auf „-“ stellen):
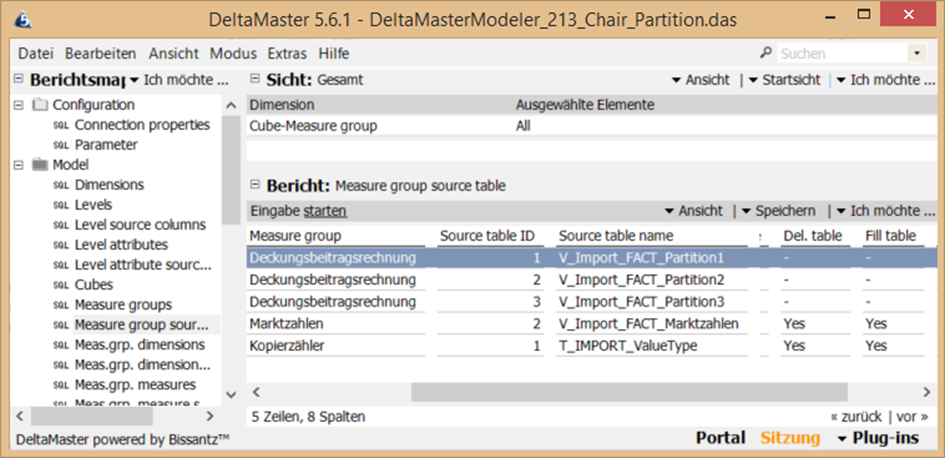
Abb. 3: Einstellungen innerhalb des Berichts „Measure group source table“
Innerhalb der P_Partition_Transform_FACT_XXX wird dann die P_FACT_XXX_01 aufgerufen. Deshalb wird mit einem Update-Befehl an der Stelle kurzzeitig das Fill-table-Flag eingeschalten.
Die P_Partition_Transform_FACT_XXX-Prozedur muss in die P_Transform_All integriert werden, entweder vor oder nach dem Ausführen der anderen P_Fact-Prozeduren.

ALTER proc [dbo].[P_Transform_All] as
exec dbo.P_SYSLOG_StartTransformation
exec dbo.P_SYSLOG_Reset
exec P_SYSLOG_Exec 'dbo.P_Transform_10_DeleteFactTables'
exec P_SYSLOG_Exec 'dbo.P_Transform_11_DeleteDimTables'
exec P_SYSLOG_Exec 'dbo.P_Transform_12_P_DIMs_Ausfhren'
exec P_SYSLOG_Exec 'dbo.P_Transform_13_P_FACTs_Ausfhren'
exec P_SYSLOG_Exec 'dbo.P_Partition_Transform_FACT_01_Deckungsbeitragsrechnung'
exec dbo.P_SYSLOG_StopTransformationSehr wichtig ist auch, die großen Tabellen beim Ausführen des „CreateSnowflake“ vor dem Löschen zu bewahren. Für solche Fälle gibt es die Modeler-Prozeduren P_BC_CreateSnowflake_PreProcess und P_BC_CreateSnowflage_PostProcess. Darin wird (auskommentiert) angeboten, die Prozedur P_BC_Backup_SnowflakeSchema bzw. P_BC_Restore_SnowflakeSchema zu nutzen. Die Prozeduren würden alle Dimensions- und Faktendaten sichern und wiederherstellen. Da sie dafür den SWITCH-Befehl für die gesamte Tabelle verwenden, sind sie gerade für das hier vorgestellte Verfahren nicht hilfreich. Das funktioniert nur mit Tabellen, die nicht partitioniert sind. Dafür gibt es ab Modeler Version 213 die Prozedur P_BC_Rename_Table, mit der eine Tabelle inklusive aller Constraints umbenannt werden kann. Mit der kann man die P_BC_CreateSnowflake_PreProcess bspw. so füllen:
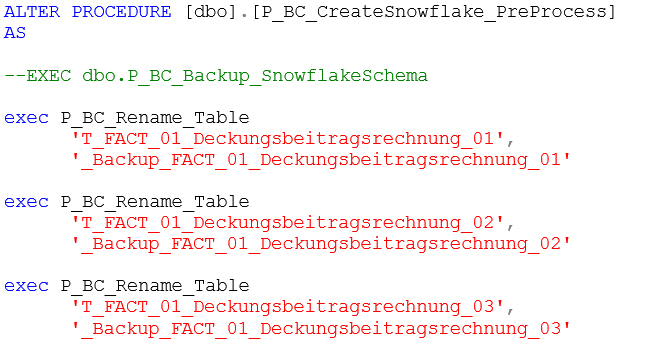
ALTER PROCEDURE [dbo].[P_BC_CreateSnowflake_PreProcess]
AS
--EXEC dbo.P_BC_Backup_SnowflakeSchema
exec P_BC_Rename_Table
'T_FACT_01_Deckungsbeitragsrechnung_01',
'_Backup_FACT_01_Deckungsbeitragsrechnung_01'
exec P_BC_Rename_Table
'T_FACT_01_Deckungsbeitragsrechnung_02',
'_Backup_FACT_01_Deckungsbeitragsrechnung_02'
exec P_BC_Rename_Table
'T_FACT_01_Deckungsbeitragsrechnung_03',
'_Backup_FACT_01_Deckungsbeitragsrechnung_03'Und die P_BC_CreateSnowflake_PostProcess entsprechend so:

ALTER PROCEDURE [dbo].[P_BC_CreateSnowflake_PostProcess]
AS
--EXEC dbo.P_BC_Restore_SnowflakeSchema
if exists (Select * from sys.tables where name = 'T_FACT_01_Deckungsbeitragsrechnung_01')
drop table T_FACT_01_Deckungsbeitragsrechnung_01
if exists (Select * from sys.tables where name = 'T_FACT_01_Deckungsbeitragsrechnung_02')
drop table T_FACT_01_Deckungsbeitragsrechnung_02
if exists (Select * from sys.tables where name = 'T_FACT_01_Deckungsbeitragsrechnung_03')
drop table T_FACT_01_Deckungsbeitragsrechnung_03
exec P_BC_Rename_Table
'_Backup_FACT_01_Deckungsbeitragsrechnung_01',
'T_FACT_01_Deckungsbeitragsrechnung_01'
exec P_BC_Rename_Table
'_Backup_FACT_01_Deckungsbeitragsrechnung_02',
'T_FACT_01_Deckungsbeitragsrechnung_02'
exec P_BC_Rename_Table
'_Backup_FACT_01_Deckungsbeitragsrechnung_03',
'T_FACT_01_Deckungsbeitragsrechnung_03'Änderungen, die direkt an diesen T_FACT-Tabellen vorgenommen werden sollen (z. B. Hinzufügen neuer Measures), müssen dann von Hand mit Alter-Table-Statements erfolgen.
Der Blog zeigt, dass dieses Verfahren eine gewisse Komplexität beinhaltet. Der große Vorteil ist aber, dass außer beim Laden der Tabelle 1 keine nennenswerte Zeit in Anspruch genommen wird. Es ist daher im periodischen (meist täglichen) Laden der Daten sehr schnell. Mit den zugehörigen SQL-Scripten hoffen wir, dass eine Implementierung in anderen Projekten vereinfacht werden kann.
