Da programmiert man schon Jahrzehnte lang T-SQL und erlebt doch noch Überraschungen bei vermeintlich einfachen Befehlen. Jüngst haben wir in einer Kundenumgebung verschiedene Optimierungen durchgeführt und unter anderem NOT IN Befehle durch LEFT JOINs ausgetauscht. Erwartet haben wir ein identisches Abfrageergebnis bei deutlich besserer Performance. Aber weit gefehlt. Aus einem uns zu dem Zeitpunkt noch nicht bekannten Grund lieferte die „linke Verbindung“ ein vollkommen anderes Ergebnis als das zuvor verwendete IN-Kommando. Nach einer langwierigen Suche, mit wiederholten Zweifeln an der eigenen Fachkompetenz, haben wir den Grund schließlich gefunden. Und wie sich herausgestellt hat, ist dieser selbst für viele „alte Hasen“ überraschend. Also lassen auch Sie sich überraschen.
Die stark vereinfachte Ausgangslage
Um das Phänomen nachzustellen, genügen zwei einspaltige Tabellen mit wenigen Inhalten.
Wir erzeugen uns eine Tabelle „_Test“, aus der wir nur die Datensätze sehen wollen, die in unserer Referenztabelle „_TestRef“ nicht enthalten sind – ein ganz typischer Anwendungsfall:
--Drop & Create test tables
IF object_id('_TestRef') IS NOT NULL DROP TABLE _TestRef
IF object_id('_Test') IS NOT NULL DROP TABLE _Test
CREATE TABLE _TestRef (Col varchar(1) NULL)
CREATE TABLE _Test (Col varchar(1) NULL)
go
Anschließend fügen wir ein paar Datensätze in unsere Tabellen ein:
--Insert test contents
INSERT INTO _Test VALUES('A')
INSERT INTO _Test VALUES('B')
INSERT INTO _Test VALUES('X')
go
INSERT INTO _TestRef VALUES('A')
INSERT INTO _TestRef VALUES('B')
INSERT INTO _TestRef VALUES('C')
INSERT INTO _TestRef VALUES(NULL)
go
Dem aufmerksamen Leser ist sicherlich schon aufgefallen, dass unser gesuchter Datensatz, jener mit dem Inhalt „X“ ist. Das ist der einzige Wert, welcher in der Referenztabelle nicht vorhanden ist. So-weit so gut.
Der überraschende Test
Erstellen wir nun unseren einfachen SQL-Befehl, um den Datensatz zu finden, und geben gleichzeitig die Testtabellen mit aus:
--Check result SELECT * FROM _Test WHERE Col NOT IN (SELECT Col FROM _TestRef) SELECT * FROM _Test SELECT * FROM _TestRef
Führen wir das Skript nun aus, zeigt sich das unerwartete Ergebnis, unser X-Datensatz wird nicht gefunden:
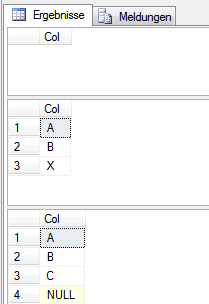
Wäre ich nun gemein, würde ich den Blogbeitrag nun beenden und in einem zweiten Teil die Lösung präsentieren. Da mir aber nichts ferner liegt, helfe ich etwas auf die Sprünge.
Der Grund für dieses durchaus seltsame Verhalten liegt in dem NULL-Datensatz in der Referenztabelle. Wenn dieser Datensatz entfernt wird, liefert der Befehl auch das gewünschte Ergebnis, probieren Sie es selbst aus.
Das ist eine überraschende und gleichzeitig entscheidende Erkenntnis:
Wann immer Ihre Referenztabelle NULL-Werte enthält, liefert ein einfacher NOT IN Befehl kein Ergebnis zurück, selbst wenn es Datensätze gibt, die in der Referenztabelle nicht existieren!
An der Stelle muss ich kurz schmunzeln, weil Sie vermutlich, genau wie ich, gerade im Geiste all Ihre Implementierungen durchgehen und überlegen wo Sie genau in diese Falle getappt sein könnten…
So und wer jetzt denkt: „Mensch, dass hätte Microsoft uns ja auch ruhig mal sagen können“ liegt wiederum daneben. Einen halbwegs verständlichen Hinweis dazu gibt es tatsächlich im MSDN. Hier wird sogar schon von dem „unerwarteten Ergebnis“ gesprochen:

Aber sind wir mal ehrlich, wer hat schon den Hilfetext zum IN-Befehl gelesen…
Im Übrigen hat das Verhalten auch nichts mit der Referenztabelle zu tun. Auch wenn man IN mit einer statischen Liste verwendet, in der ein NULL-Wert enthalten ist, kommt man zum selben Ergebnis:
--Check with static list
SELECT * FROM _Test WHERE Col NOT IN ('A', 'B', 'C', NULL)
Die Lösungsalternativen
Schauen wir uns also an, was wir alternativ tun können, um zu dem erwarteten Ergebnis zu kommen.
ANSI_NULLS
Zunächst mal hat das Ganze etwas mit der Interpretation der NULL-Werte innerhalb des SQL-Servers zu tun. Der kleinste Eingriff, der noch nicht mal eine Veränderung der Abfrage nach sich zieht, wäre also die Veränderung des NULL-Verhaltens. Dafür existiert im SQL-Server die Eigenschaft „ANSI_NULLS“. Diese ist im Standard immer auf ON konfiguriert. Stellt man das Verhalten mit folgendem Befehl auf OFF um, funktioniert die oben erstellte Abfrage fehlerfrei:
SET ANSI_NULLS OFF SELECT * FROM _Test WHERE Col NOT IN (SELECT Col FROM _TestRef)
Zu einfach um wahr zu sein, oder? Richtig, auf das Pferd können wir leider nicht mehr setzen. Liest man zu dieser Option wiederum sorgfältig die Beschreibung im Microsoft Developer Network findet man wiederum solch eine gelbe Box mit einem Warnhinweis, dass dringend davon abgeraten wird, diese Option in Anwendungen zu verwenden:

Folglich müssen wir die naheliegende Lösung mit dem geringsten Änderungsaufwand leider streichen.

ISNULL
Wir müssen also unsere Abfrage umbauen. Auch hier wählen wir zunächst die Variante mit dem geringsten Aufwand. In dem Fall die Verwendung von ISNULL in dem Subselect:
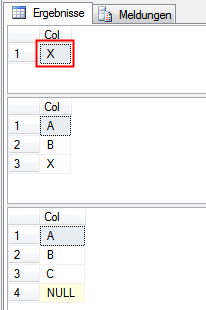
SELECT * FROM _Test WHERE Col NOT IN (SELECT isnull(Col,'') FROM _TestRef)
Die gezeigte Veränderung liefert uns nun tatsächlich den gesuchten X-Datensatz:
Allerdings möchte ich an der Stelle dazu aufrufen, sich auch mit dieser Lösung noch nicht zufrieden zu geben. Üblicherweise sind Tabellen in einer Echtumgebung ein kleines bisschen größer als unsere Testtabellen und in diesem Umfeld zeigt das IN- bzw. NOT IN-Konstrukt kein optimales Laufzeitverhalten. Um also die Performance hoch zu halten bietet sich die Nutzung des allseits beliebten LEFT JOINs an.
LEFT JOIN
Der LEFT JOIN zeigt bei großen Tabellen teilweise sehr deutliche Performanceverbesserungen im Vergleich zu dem IN-Befehl. Obendrein liefert er in unserem Testfall auch noch ein korrektes Ergebnis. Folglich ist dies die optimale Lösung für unser Problem.
Die Verknüpfung funktioniert so, dass unsere Testtabelle die linke Tabelle des JOINs darstellt. Rechts wird die Referenztabelle „drangejoint“. Alle Datensätze, die dann in der rechten Tabelle keine Entsprechung finden, sind unsere gesuchten. Die folgende Darstellung verdeutlicht dies:

Wichtig zu verstehen ist, dass das NULL der Referenztabelle dabei nicht dem NULL entspricht, welches ohnehin in der Referenztabelle enthalten ist. Jeder Datensatz der linken Tabelle, welcher in der rechten Tabelle keine Entsprechung findet, wird grundsätzlich als NULL dargestellt. Unabhängig davon, ob in der Referenztabelle ein NULL-Datensatz existiert oder nicht
In T-SQL übersetzt muss der LEFT JOIN folgendermaßen aufgebaut werden:
SELECT t.* FROM _Test t LEFT JOIN _TestRef tr ON t.Col = tr.Col WHERE tr.COL IS NULL
Das Ergebnis sieht analog zu dem Lösungsansatz 2 aus. Nur wie gesagt mit deutlich besserem Laufzeitverhalten.
Damit sind wir auch schon am Ende des heutigen Themas. Wir hoffen wir konnten den ein oder anderen ein wenig überraschen und dafür sorgen, dass künftig nur noch fleißig gejoint wird.
Wie immer anbei das Skript zum Download.
