Seitdem wir die eleganten Möglichkeiten von Datenbank-Snapshots im Microsoft SQL Server kennengelernt haben, haben wir mal die Augen offengehalten, wie oft diese Funktion im Feld draußen verwendet wird. Die Erkenntnis war ernüchternd – ungefähr so oft wie der Chartbreaker „Schni Schna Schnappi“ bei Rock am Ring läuft – nämlich gar nicht. Das ist sehr schade, da es einige Vorteile gegenüber herkömmlichen Backups gibt. Welche das sind und wie man die Schnappschüsse zum Einsatz bringt, schauen wir uns in diesem Blogbeitrag an.
Snapshot beats Backup – zumindest in bestimmten Fällen
Dass Snapshots in der Praxis so selten eingesetzt werden, liegt sicherlich unter anderem an der Tatsache, dass es keinerlei Oberfläche oder Assistenten-Unterstützung für die Arbeit mit Snapshots gibt.
Aber bevor wir uns anschauen, wie man die Snapshots bedient, schauen wir erstmal, was ein Snapshot eigentlich ist und wofür man ihn sinnvollerweise einsetzen kann. Snapshot wird in Microsoft SQL Server mit dem unhandlichen Wort „Datenbank-Momentaufnahme“ übersetzt. Umgangssprachlich kann man auch von einem Schnappschuss sprechen. Im Prinzip handelt es sich dabei also um etwas Ähnliches wie ein Backup. Die Datenbank wird zu einem bestimmten Moment in einem Stand eingefroren. Diesen Stand kann man später genau wie beim Backup wiederherstellen.
Die Besonderheit bei den Momentaufnahmen liegt in der Art und Weise, wie die Daten gespeichert oder besser gesagt nicht gespeichert werden. Legt man einen Snapshot an, so wird von SQL Server zunächst einmal eine leere Datenbankhülle erstellt. Diese zeigt einfach 1:1 den Inhalt der Originaldatenbank. Wird dann an der Originaldatenbank etwas geändert, merkt sich der Snapshot lediglich zu dem geänderten Objekt den vorherigen Zustand, also quasi das Delta gegenüber der Änderung. Wenn man nun aus dem Snapshot Daten liest, wird der unveränderte Inhalt aus der Originaldatenbank übernommen und nur die im Original veränderten Objekte werden aus dem Snapshot gelesen. Im Microsoft Developer Network wird das Verhalten schematisch schön dargestellt:
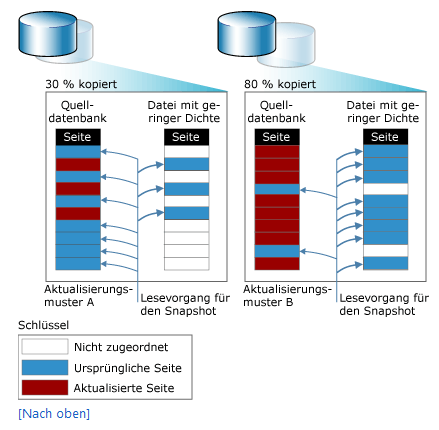
Abb. 1: Schematische Darstellung von Snapshots, Quelle MSDN, 05.09.2014: http://msdn.microsoft.com/de-de/library/ms175158.aspx
Das macht die Snapshots sehr speichereffizient . Was man in der Darstellung allerdings auch sieht, ist, dass das Ganze nur solange effizient ist, solange man nicht alle Objekte der Quelldatenbank verändert. Dann entspricht die Snapshot-Größe natürlich der Größe der Originaldatenbank. Trotz allem sollte man sich in großen Datenbanken also unbedingt an das Feature heranwagen. Allein schon wegen der geringen Zeit, die das Erstellen einer Momentaufnahme in Anspruch nimmt.
Ein weiterer wichtiger Vorteil gegenüber normalen Backups ist bereits im vorherigen Abschnitt versteckt: „Wenn man nun aus dem Snapshot Daten liest…“. Im Unterschied zu einem herkömmlichen Backup kann man auf einen Snapshot jederzeit zugreifen. Und das per Management Studio, per T-SQL und auch über beliebige Client-Anwendungen. Im Management Studio sieht das dann aus wie eine ganz normale Datenbank:
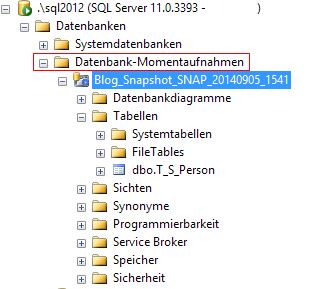
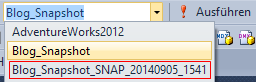
Abb. 2: Zugriff auf Datenbank-Momentaufnahmen
Das ist natürlich extrem praktisch, wenn man „mal eben“ etwas im Backup nachsehen will. Und auch Datenkopien aus dem Snapshot in die Originaldatenbank sind möglich.
Warum gibt es dann überhaupt noch Backups? Weil ein Snapshot nicht zur echten und dauerhaften „Sicherung“ von Daten oder Datenbanken gedacht oder geeignet ist. Ein Snapshot funktioniert immer nur gemeinsam mit der Originaldatenbank. Sollte diese beschädigt sein, lässt sich das Original aus dem Snapshot nicht wiederherstellen (bei dem gezeigten Schema aus dem MSDN eigentlich auch logisch). Daher ist ein Snapshot kein Ersatz für Sicherungs- und Wiederherstellungsstrategien. Um mögliche „große“ Ausfälle, wie korrupte Datenbanken oder defekte Laufwerke, beheben zu können, sollten auf jeden Fall weiterhin „weichei-mäßig“ assistentengesteuerte Backups erstellt werden!
Wofür sind Snapshots dann also in BI-Systemen geeignet? Zum einen können die Snapshots den Datenbankentwickler oder Adminstrator vor Fehlern schützen. Wenn man vor jeder Systemänderung schnell einen Snapshot anlegt, ist man immer auf der sicheren Seite. Da dies, wie oben beschrieben, auch bei großen Datenbanken schnell geht und die Platte nicht sprengt, ist die Option also im Gegensatz zum Backup jederzeit praktizierbar. Weiterhin könnte man mehrere Datenstände einer Datenbank historisieren und ggfs. in einem Reporting verwenden. Um die Ausfallsicherheit zu erhöhen, könnte man prinzipiell auch vor jeder Transformation zuerst einen Snapshot erstellen und beim Auftreten von Fehlern diesen wiederherstellen. So könnte man immer einen konsistenten Datenstand garantieren. Die letzte Idee ist die Nutzung von Snapshots für Test- oder Trainingssysteme. Vor jeder neuen Test- oder Trainingsrunde könnte man so die Datenbanken auf den gleichen Datenstand zurücksetzen und könnte ohne großen Aufwand die neuen Runden initialisieren.
Die wunderbare Welt der Datenbank-Momentaufnahmen hat aber auch zwei kleine, aber feine Restriktionen. Zum einen sind die Momentaufnahmen immer schreibgeschützt. Es kann also nur die Originaldatenbank weiterhin beschrieben werden. Weiterhin sind Snapshots nur in der Enterprise Edition von SQL Server verfügbar.
Tooltime – houw, houw, houw!
Also holen wir die Binford-Kreissäge mal aus dem Schrank. Zunächst erstellen wir eine hundsgewöhnliche SQL-Server-Datenbank und erzeugen uns eine Testtabelle. Wir verwenden dabei die Datenbank „Blog_Snapshot“ und die kleine Tabelle „T_S_Person“. Die Version von SQL Server ist dabei relativ egal, die Funktion gibt es schon seit SQL Server 2005:
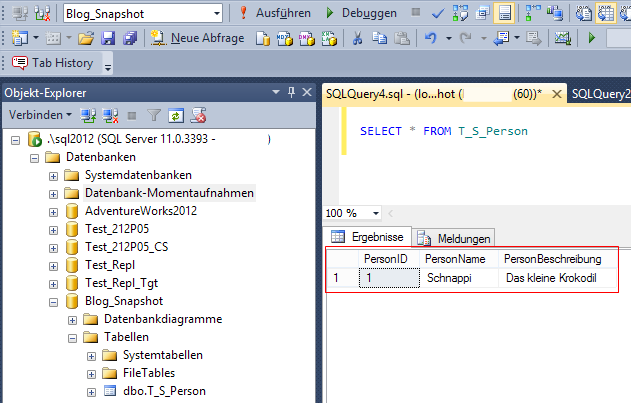
Abb. 3: Testtabelle auf der Datenbank
In die Tabelle haben wir bereits einen Testdatensatz eingefügt. Sonst ist die Datenbank leer. Jetzt kommt gleich der komplizierteste Teil an dem ganzen Spiel – das Erstellen des Snapshots. Hierfür brauchen wir ein T-SQL-Kommando nach dem folgenden Schema:
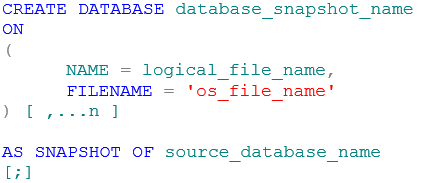
CREATE DATABASE database_snapshot_name
ON
(
NAME = logical_file_name,
FILENAME = 'os_file_name'
) [ ,...n ]
AS SNAPSHOT OF source_database_name
[;] Die Variablen des Statements sind fast selbsterklärend:
- database_snapshot_name: Name des zu erstellenden Snapshots
- logical_file_name: Logischer Dateiname der Datendatei der Originaldatenbank
- os_file_name: Vollständige Pfadangabe der neuen Datendatei des Snapshots (Endung „.ss“)
- source_database_name: Name der Datenbank, auf der der Snapshot basiert
Dann mal los – Stecker in die Dose und Gerät einschalten. Wenn wir die Variablen ausfüllen, sieht das Statement (bei mir zumindest) so aus:
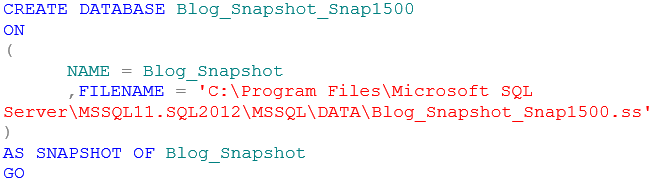
CREATE DATABASE Blog_Snapshot_Snap1500
ON
(
NAME = Blog_Snapshot
,FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL11.SQL2012\MSSQL\DATA\Blog_Snapshot_Snap1500.ss'
)
AS SNAPSHOT OF Blog_Snapshot
GONach Ausführung des Statements findet man den Snapshot inklusive aller Datenbankobjekte wie erwartet in dem Ordner „Datenbank-Momentaufnahmen” (in einer englischen Serverversion „Database snapshots”):
Abb. 4: Neu angelegter Snapshot
Nun kann man lesend alles auf der Datenbank tun, was man auch auf der Originaldatenbank tun könnte, zum Beispiel unsere Tabelle T_S_Person abfragen. Das Ergebnis entspricht logischerweise dem der Originaldatenbank:
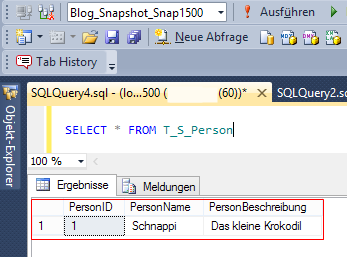
Abb. 5: Abfrage auf dem Snapshot
Zur Demonstration der gigantischen Leistungsfähigkeit des soeben erzeugten Snapshots fügen wir nun eine neue Spalte „PersonGeburtsjahr“ sowie zwei neue Datensätze in die Tabelle der Originaldatenbank „Blog_Snapshot“ ein:
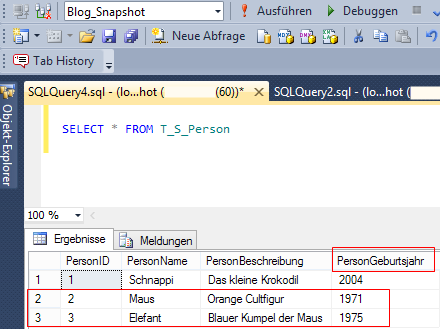
Abb. 6: Änderung in der Originaldatenbank
Und nun Achtung – die Abfrage auf den Snapshot liefert nach wie vor die alten Ergebnisse:
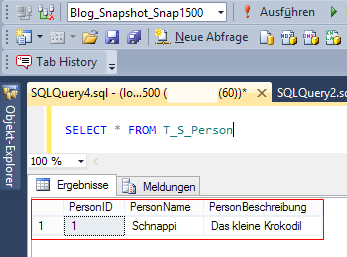
Abb. 7: Abfrage auf dem Snapshot
Damit haben wir auch gleich eine wichtige Erkenntnis gewonnen – die Snapshots funktionieren also sowohl für strukturelle Änderungen an der Originaldatenbank (neue Tabellenspalte) als auch für Tabelleninhalte (die beiden neuen Datensätze). Gerade der Punkt mit den strukturellen Änderungen ist wirklich sehr spannend für Neuentwicklungen auf Systemen. Insbesondere, da einige Entwickler tatsächlich auf Produktiv-Systemen entwickeln.
Wird nun ein neuer Snapshot erstellt und wieder ein neuer Datensatz eingefügt, so wird natürlich der Datenstand zu diesem Zeitpunkt eingefroren. Das Spiel kann man beliebig weiter treiben.
Alles kaputt – ich will zurück!
Sollte man nun tatsächlich die Produktion gekillt haben und alle Änderungen wieder zurückdrehen wollen, so geschieht dies mit einem sehr einfachen Befehl:
![]()
RESTORE DATABASE FROM DATABASE_SNAPSHOT = „Database_name“ ist der Name der Originaldatenbank, und „database_snapshot_name“ entspricht einfach dem Namen des Snapshots. In meinem Beispiel also:
![]()
RESTORE DATABASE Blog_Snapshot FROM DATABASE_SNAPSHOT = 'Blog_Snapshot_Snap1500'OK, Befehl ausführen – alles gerettet – Entspannung… von wegen – ein Fehler treibt uns die ersten Schweißperlen auf die Stirn:

Abb. 8: Fehlermeldung I
Bei genauer Begutachtung ist die Meldung aber halb so wild. Wir dürfen lediglich keine Verbindung zur wiederherstellenden Datenbank offen haben. Letztlich das gleiche, als wenn man ein Backup einspielen möchte. Also führen wir den Befehl einfach mit einer Verbindung zur Master-Datenbank aus. Aha, SQL-Server rechnet – sehr gut – Liegestuhl, Cocktail, Hawaiihemd – alles in greifbarer Nähe… och nö – der nächste Fehler (das ist üblicherweise der Moment, in dem der genervte Leiter der Fachabteilung hinter einem auftaucht und wissen will, wann er denn endlich wieder mit seinem geliebten DeltaMaster weiterarbeiten kann):

Abb. 9: Fehlermeldung II
Doch jetzt bloß eins nicht machen – in Panik schnell die Meldung wegklicken. Wenn man diese nämlich genau liest, kommt man auf die Fehlerursache. Das Wiederherstellen eines Snapshots geht (leider) nur, wenn nur noch ein Snapshot zu der Originaldatenbank auf dem Server existiert. Da wir vorhin zwei Snapshots zum Testen erstellt haben, muss einfach einer der beiden Snapshots gelöscht werden. Wir entscheiden uns für den zweiten, um den anfänglichen Zustand mit dem einen Datensatz und ohne Geburtsjahr-Spalte wiederherzustellen. Dafür muss jetzt folgender, total komplizierter SQL-Befehl ausgeführt werden:
![]()
DROP DATABASE Blog_Snapshot_Snap1530Dass der Name des Snapshots an die jeweilige Umgebung anzupassen ist, versteht sich von selbst, denke ich. Nach der Aktion klappt’s dann auch mit dem Restore endlich. Ein prüfender Blick auf die Originaldatenbank bestätigt die Erfolgsmeldung:
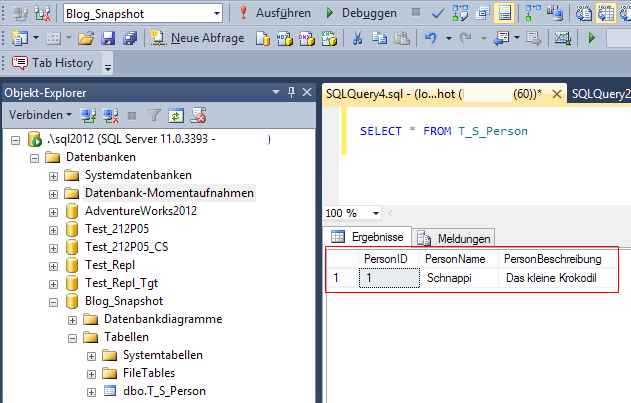
Abb. 10: Letztlich erfolgreiche Abfrage
Gefahr gebannt! Der Snapshot bleibt beim Wiederherstellen im Übrigen weiterhin bestehen. Diesen müsste man mit einem ähnlich komplexen DROP-Befehl dann separat löschen.
Das Goodie zum Schluss
Im Großen und Ganzen ist der Umgang mit Snapshots also gar nicht kompliziert und bietet zahlreiche Vorteile, insbesondere bei der Entwicklung von Datenbanksystemen. Da dies, wie am Anfang erwähnt, ja aber offensichtlich nicht auszureichen scheint, haben wir uns ein kleines Goodie einfallen lassen. DeltaMaster Modeler ist auch hier wieder sehr hilfreich. Damit man sich die Syntax zum Erstellen eines Snapshots nicht merken muss und das Feature öfter zum Einsatz bringen kann, wird es im DeltaMaster Modeler 213 eine fertige Prozedur zum einfachen Erstellen von Snapshots geben. Ist zwar nicht so „fancy“ wie ein Assistent, dafür geht’s noch schneller. Datenbankname und Suffix kann man einfach weglassen. DeltaMaster Modeler kümmert sich dann um den Rest und erzeugt für die gerade verbundene Datenbank einen Snapshot mit aktuellem Datum und Zeitstempel im Suffix.
Hier der Beweis aus den Tiefen des Sourcecodes von DeltaMaster Modeler:
Abb. 11: Sourcecode-Ausschnitt DeltaMaster Modeler
