Typische Situation im Prototypen-Design: Die Dimensionen, die inhaltlich in den Daten verfügbar sind, bieten relativ wenig Struktur und damit z. B. eine geringe Anzahl an Hierarchiestufen.
Wie also soll man auf Basis dieser Testdaten zeigen, was man analytisch aus Zahlen mithilfe von DeltaMaster herausholen kann? Die Möglichkeiten virtueller Hierarchien in Kombination mit verschiedenen Analysemethoden sind hier die Mittel der Wahl, um nebenbei auch gleich die Analysekettentechnik zu illustrieren.
Neben den informationsdichten Visualisierungsformen lebt DeltaMaster im Besonderen von automatisierten Analysemethoden, die bis hin zu Data-Mining-Verfahren reichen. Eine der größten Hürden, um in Testdaten ein paar interessante Nuggets zu finden, stellt oftmals (neben einer schlechten bzw. unvollständigen Datenqualität) die mangelnde Strukturierung von Daten dar. Das Ostereierparadoxon verstärkt das Problem nur noch: Wenn man nicht erst gute Strukturen aufbaut (also die Ostereier versteckt), kann man sie später auch gar nicht erst finden. Was aber tun, wenn zwar die Versteckfähigkeiten gegeben sind, aber aus den Daten definitiv keine Versteckmöglichkeiten erwachsen?
In dem Fall gilt es, sich auf die Möglichkeiten von DeltaMaster zu besinnen, der (abhängig von der zugrundeliegenden Datenbanktechnologie) die Definition von benutzerdefinierten, virtuellen Hierarchien erlaubt. Was bedeutet das inhaltlich? Strukturierungen können manuell (z. B. über plausible Annahmen bzw. existierende Elementattribute) zu Gruppierungen von Elementen führen oder aber, und das ist oft noch viel interessanter, auf Basis von Kennzahlen automatisch in Klassen/Gruppen eingeordnet werden. DeltaMaster bietet für die zweite Variante mit der ABC-Analyse, der Portfolioanalyse sowie mit Verteilungsanalysen verschiedene Möglichkeiten, auf Basis von Kennzahlen neue Strukturen dynamisch in Dimensionen einzuziehen.
Im Folgenden geben wir ein paar Beispiele für die Verwendung virtueller Dimensionen, die die verschiedenen Anwendungsfelder erläutern.
Virtuelle Hierarchie auf Basis einer ABC-Analyse
Konzentrationsanalysen, mit denen herauszufinden ist, wie abhängig eine Unternehmung z. B. von bestimmten Produkten, Kunden, Routen, Standorten ist, haben wir exemplarisch im letzten Artikel zur Lagerlogistikdemo erläutert. Dort wurden Produkte hinsichtlich der Häufigkeit, mit der sie in einem Versandauftrag vorkommen, untersucht. Es zeigte sich eine sehr starke Abhängigkeit von nur wenigen Produkten. Mithilfe einer virtuellen Hierarchie wurden die so identifizierten A-,B- und C-Artikel noch weiter hinsichtlich ihrer Charakteristika wie „Gewicht“ bzw. „Versandart“ bewertet. Im Ergebnis wurde also eine völlig neue Strukturierung der Produktdaten in DeltaMaster berechnet und dann für Folgeanalysen weitergenutzt.
Virtuelle Hierarchie auf Basis einer Verteilungsanalyse
Sicherlich wird gerade die ABC-Analyse und die daraus folgende virtuelle Hierarchie oftmals schon in Standard-DeltaMaster-Demos verwendet. Sehr viel seltener dagegen wird die Verteilungsanalyse als Ausgangspunkt für eine Neustrukturierung von Daten genutzt. Eigentlich schade, denn mit ihrer Hilfe können wir je nach Datenlage uns auf die Analyse von Problemfällen beschränken oder sogar eine gewisse Form von nachträglicher Anonymisierung von Daten erzielen. Zu beiden Aspekten jeweils ein kurzes Beispiel.
In einem Datenbestand aus dem Projektmanagement-Umfeld findet sich aufgrund der Demodaten eine größere Anzahl von Nutzern, deren nachgewiesene Arbeitszeiten als Faktendaten bereitstehen. Zum einen ist es relativ uninteressant das Verhalten der einzelnen Nutzer zu analysieren, zum anderen ist dies auch evtl. aus datenschutzrechtlichen Gründen sensibel (selbst wenn die Namen bereits anonymisiert wurden). Aus diesem Grund bietet es sich an, verschiedene Gruppen von Nutzern bezogen auf deren Arbeitszeiten zu bilden. Dafür eignet sich insbesondere die Verteilungsanalyse, da hier beliebig viele Klassen definiert und die Klassengrenzen sogar direkt (unabhängig vom Vorkommen der Werte) festgelegt werden können.
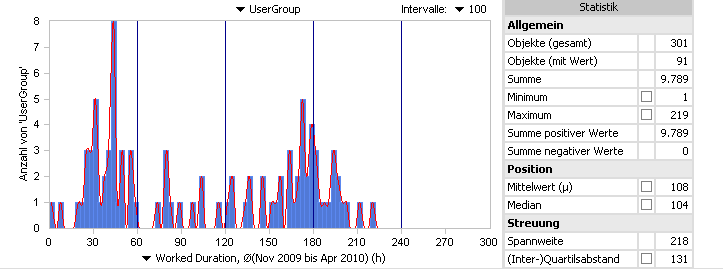
Abb. 1: Verteilungsanalyse über Nutzer nach Arbeitszeit pro Monat
Im Ergebnis sind hier mehrere Nutzergruppen erstellt worden, die dann für weitere Auswertungen zur Verfügung stehen.
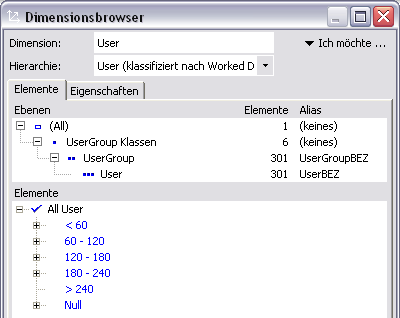
Abb. 2: Klassifikationsergebnis in einer virtuellen Hierarchie auf Basis der Verteilungsanalyse
Im Beispiel zeigt sich, dass die kumulierte Anzahl Arbeitsstunden in der Gruppe 120-180 mit 4429 am höchsten ist.
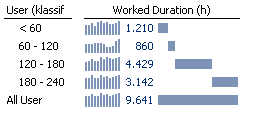
Abb. 3: Nutzung der virtuellen Hierarchie in einer Pivottabelle
In einem ganz anderen Fall lagen Downloadinformationen von einem Webserver vor, die nach diversen Kriterien wie z. B. der Serverlokation oder der einzelnen Webseite unterschieden werden. Die Aufgabenstellung bestand darin, insbesondere die Seiten zu identifizieren und zu beschreiben, die besonders lange Ladezeiten haben und damit zu Unzufriedenheit bei Kunden führen.
Im ersten Schritt wird mithilfe der Verteilungsanalyse die „Gesamt-Netzwerkzeit je Transaktion“ analysiert. Vorbedingung dafür ist, dass die einzelnen Transaktionen als Elemente in einer separaten Transaktionsdimension verfügbar sind. In der Analyse wird deutlich, dass durchaus einzelne Transaktionen sehr lange dauern, auch wenn der Großteil der Transaktionen maximal 10 Sekunden benötigt.
![]()
Abb. 4: Verteilungsanalyse über Downloadzeiten pro Transaktion
Mithilfe der Klassengrenzen (hier auf 6,4 Sekunden manuell eingestellt) wird eine Virtuelle Hierarchie definiert, die dann Aufschluss über die unterschiedlichen Ladezeiten (heruntergebrochen nach Teilzeiten) gibt. Im Beispiel ist der Anteil des Content-Downloads für die „langsamen“ Seiten besonders hoch.
![]()
Abb. 5: Ladezeiten im Detail für schnelle und langsame Transaktionen
Im nächsten Schritt werden die Testseiten im Vergleich zu den Produktivseiten untersucht, hierbei interessiert besonders die Anzahl der tatsächlichen Transaktionen für langsame Transaktionen, denn mit deren Hilfe lässt sich dann eine Kennzahl „Anteil langsamer Transaktionen“ ausrechnen, die als Inputgröße für eine Ursachenanalyse mithilfe des PowerSearch-Verfahrens dient.
![]()
Abb. 6: Anzahl Transaktionen nach virtuellen Transaktionsklassen
PowerSearch zeigt dann auf, dass offenbar bestimmte Seiten mit Login sowie die Uhrzeit „4 pm“ zu besonders langsamen Transaktionen führen. Letztlich war diese gesamte Analysekette nur dadurch möglich, dass initial eine virtuelle Hierarchie mithilfe der Verteilungsanalyse definiert wurde.
![]()
Abb. 7: Ursachenanalyse für hohen Anteil an langsamen Transaktionen
Virtuelle Hierarchie auf Basis einer Portfolioanalyse
Virtuelle Hierarchien lassen sich auch mithilfe der Portfolioanalyse erstellen. Hierbei werden zugleich zwei Kriterien (die ggf. auch jeweils wieder eine aggregierte Kennzahl darstellen können) zur Klassifizierung herangezogen. Im folgenden Beispiel ist aufgrund einer Befragung eine Gruppe von Personen nach ihren Fähigkeiten und ihren Motivationsgründen befragt worden. Sowohl in den Fähigkeits- als auch in den Motivationsindex sind mehrere Kennzahlen eingegangen. Im Ergebnis sollen vier Gruppen von Befragten herausgearbeitet werden, die sich hinsichtlich ihrer Motivation und Fähigkeit ähneln. Da in der befragten Gruppe offenbar niemand zugleich hohe Fähigkeiten und hohe Motivation in sich vereint, bleibt diese Gruppe leer.
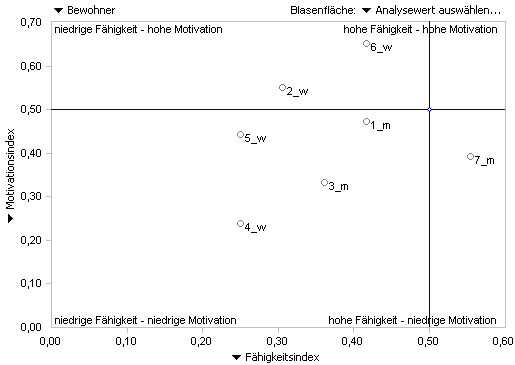
Abb. 8: Portfolioanalyse zur Definition von Gruppen
Für die drei verbleibenden Gruppen können nun Unterschiede in der Beantwortung einzelner Fragen herausgearbeitet werden, so ist z. B. die Identifikation mit einem Stadtteil bei den Befragten mit hohen Fähigkeiten und niedriger Motivation am geringsten.

Abb. 9: Unterschiede im Antwortverhalten je Gruppe von Befragten
Benutzerdefinierte Hierarchien auf Basis von Elementeigenschaften
In manchen Situationen liegt evtl. bereits ein Cube vor, der aber evtl. nicht über ausreichende Strukturierungen in Form von Hierarchien verfügt, dafür aber eine mehr oder minder große Anzahl von Attributen in einer Dimension bietet. In diesem Fall lassen sich mithilfe der Funktion „Hierarchie aus Elementeigenschaften erstellen“ neue parallele Hierarchien definieren, die dann für Analysen und Pivottabellen zur Verfügung stehen. Im folgenden Beispiel bietet der existierende Demodatenbestand der Oracle OLAP-Option einige Attribute an, mit deren Hilfe neue Strukturen definiert werden können.
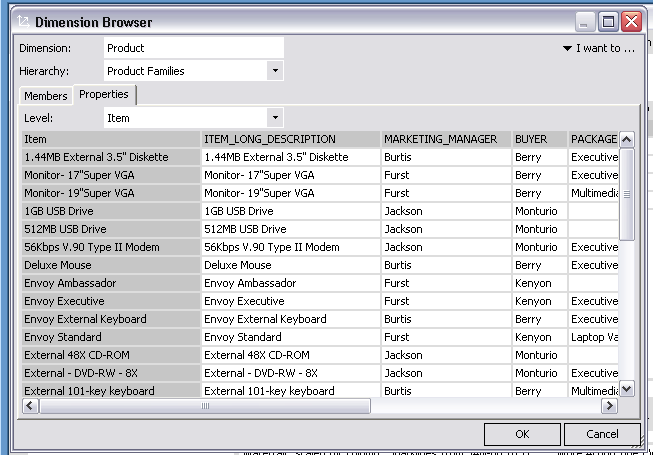
Abb. 10: Attribute in existierendem Demo-Cube
So lassen sich auf Basis der Attribute „Marketing Manager“ und „Packagings“ in einem Dashboard völlig neue Informationen strukturiert darstellen: Die Aufspaltung der Verkäufe und des Gewinns pro Stück nach Verantwortlichkeiten (Marketing Manager) und nach Angebotsbündeln (Packagings).
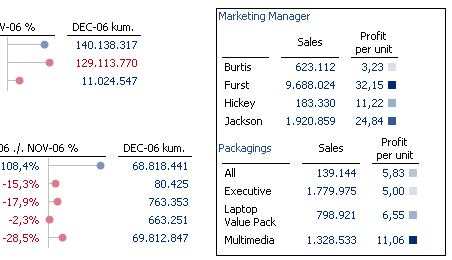
Abb. 11: Neue Auswertungen auf Basis einer Hierarchie, die auf Attributen basiert
Die Beispiele zeigen: viele Strukturen sind gut versteckt und es gilt sie, gerade auch in Demo-Datenbeständen, mit einer gewissen Kreativität aufzudecken. Hierzu bietet DeltaMaster mit den Konstrukten der benutzerdefinierten, virtuellen Hierarchien ein Methodenrepertoire, das es gerade auch in Pre-Sales-Situationen zu nutzen gilt.
