Im Blogbeitrag von April 2012 ging es um das Transaction Log. Wir haben gelesen, was es bewirkt und wie wir die Protokolldatei verkleinern können. Heute wollen wir aufzeigen, welche weiteren Möglichkeiten wir haben,
Wie groß ist eine Tabelle?
Mit dem TSQL-Befehl sp_spaceused ‚Tabellenname‘ wird angezeigt, wie viele Zeilen eine Tabelle enthält und wie viel Speicherplatz sie belegt. Die Tests zu diesem Artikel haben wir mit einer Tabelle vorgenommen, die größer als der Arbeitsspeicher war. Erste Erkenntnis: Bei Tabellen, die in den Arbeitsspeicher passen, bringt die Komprimierung nur wenig. Übrigens haben wir nicht wirk-lich mit einer Tabelle getestet, die größer ist als der Arbeitsspeicher, vielmehr haben wir dem SQL Server erklärt, dass er ab sofort nur noch 2 GB Arbeitsspeicher zur Verfügung hat. Den minimalen und maximalen Serverarbeitsspeicher kann man im SQL Server Management Studio auf Serverebe-ne in den Servereigenschaften unter Arbeitsspeicher einstellen. Oder viel schneller über die Befehle
sp_configure ‚min server memory‘, 1024
reconfigure (stellt die Mindestgröße des Serverarbeitsspeichers ein) und
sp_configure ‚max server memory‘, 2048
reconfigure (stellt die maximale Größe des Serverarbeitsspeichers ein).
Schließlich kann man sich mit sp_configure die aktuellen Servereingeschaften ansehen.
Wie wird komprimiert?
Bei der Tabellenkompression wird zunächst eine Schattentabelle in der Datenbank erzeugt, die die Daten in komprimierter Form aufnimmt. Ist die Kompression abgeschlossen, wird die originale Tabelle umbenannt und die komprimierte Tabelle bekommt den Namen der originalen Tabelle. Da-nach wird die Ursprungstabelle gelöscht. Wie groß der zusätzlich während der Kompression benö
tigte Plattenplatz sein muss, ergibt sich aus der Größe der originalen Tabelle plus der geschätzten Größe der komprimierten Tabelle.
Eine derartige Schätzung gibt es mit dem Befehl sp_estimate_data_compression_savings. Damit ermittelt der Server, wie viel Speicherplatz nach einer Komprimierung zur Verfügung steht und es lassen sich die größten Ressourcenverschwender ausfindig machen.
Welche Tabellen soll ich komprimieren?
Die Entscheidung ist recht einfach: es sollten die Tabellen komprimiert werden, die mit minimalem Aufwand die maximale Kompressionsrate hervorbringen. Aber wie finde ich raus, welche Tabellen das sind?
Die maximale Kompressionsrate liefert laut Microsoft der oben beschriebene Schätzungsbefehl. Das Prinzip ist schnell erklärt: Eine Auswahl an Datensätzen aus der Tabelle wird komprimiert, die Kompressionsrate vom Server berechnet und auf die Gesamtanzahl von Datensätzen dieser Tabelle hochgerechnet.
Für die Ermittlung des minimalen Aufwandes muss folgendes abgewogen werden: Komprimierung kostet Arbeitsspeicher und CPU-Last. Eine komprimierte Tabelle benötigt zwar meistens weniger Speicherplatz, aber die CPU wird mitunter ganz ordentlich beschäftigt. Die Jungs (und Mädels) bei Microsoft haben festgestellt, dass bei der Komprimierung einer Tabelle 2 bis 5 mal so viel CPU als bei der Erzeugung eines Index auf diese Tabelle benötigt wird. Und ein weiterer wichtiger Aspekt bei der Suche nach der zu komprimierende Tabelle ist ihr Nutzungsverhalten. Komprimierte Dateien müssen, bevor sie gefiltert, sortiert oder gejoint werden, erst wieder dekomprimiert werden. Bei derart genutzten Tabellen brauchen wir über Komprimierung also gar nicht erst nachdenken.
Gut, dass wir in unserem Transform_All so viele inserts machen!
Die ausführlichen Ergebnisse des Tests wollen wir natürlich niemandem vorenthalten.
Ausgangspunkt war eine Tabelle T1 mit über 4 Mio. Datensätzen. Die erste Spalte beinhaltete einen Datensätzzähler, in der zweiten und dritten Spalte stand jeweils ein Text.
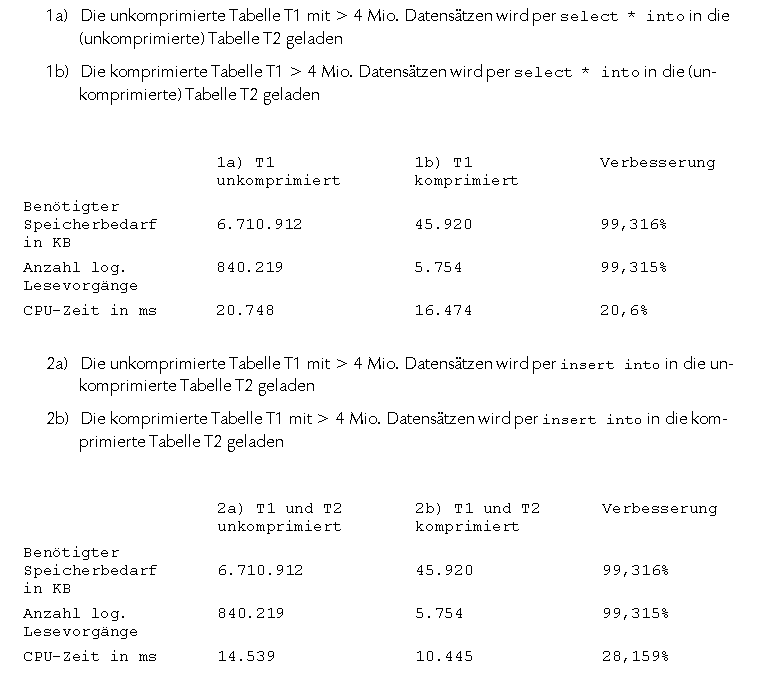
Fazit
Immer dann, wenn wir großen Tabelleninhalt in andere Tabellen laden wollen (also zum Beispiel beim Laden von materialisierten Faktendaten von TMV_Import_Fact_Umsätze in T_Fact_01_Umsätze), kann eine Tabellenkompression zu schnellerem Laden und geringerem Speicherbedarf führen. Leeren wir die Zieltabelle nicht, sondern wird sie mit einem täglichen Delta beladen, lohnt sich auch die Kompression der Zieltabelle. Allerdings gilt dies nur dann, wenn keine der komprimierten Tabellen an anderer Stelle gejoint werden muss. Wer selbst testen will, setzt einfach vorher die Befehle Set STATISTICS TIME ON und Set STATISTICS IO ON ab, dann werden nach der Abfrage noch informative Meldungen zu Lesevorgängen und Zeitdauer ausgegeben.
