„Der Würfel ist heute Nacht nicht aufbereitet worden!“, meldet ein Kunde am frühen Morgen per Mail. Komisch, wir haben aber doch alle potenziellen Fallen mittels Modeler oder SQL-Prozeduren aufgefangen: Es gibt Defaults für leere Datensätze, wir haben dem Modeler erklärt, dass er Datensätze, die in den Fakten, aber nicht in den Dimensionsdaten geliefert werden, nachtragen soll, alle denkbaren Kombinationen von ungültigen Datensätzen werden bereits im Preprocess abgefangen…
Was wird dann jetzt wohl das Problem sein? Richtig! Der Transform-Prozess konnte nicht abgeschlossen werden, weil das Log vollgelaufen ist!
Was das Log eigentlich ist, wozu es benötigt wird und wie wir das System wieder zum Laufen kriegen, wird in diesem Blogbeitrag erläutert.
Logfile
Beim Erstellen einer neuen Datenbank im MS SQL-Server wird eine Datei mit der Endung .mdf als Datenbankdatei und zusätzlich eine Datei mit der Endung .ldf als Logfile angelegt. Diese wird als Transaction Log bezeichnet.
Immer wenn SQL-Code ausgeführt wird, bei dem Dateninhalte verändert werden, wird dadurch nicht nur die Datenbankdatei aktualisiert, sondern gleichzeitig auch Details über die Transaktion ins Logfile eingetragen. Dort steht dann die ID, der Start- und Endzeitpunkt der Transaktion sowie welche Daten wie manipuliert wurden.
Die zu manipulierenden Daten werden in Seiten des Cache verändert (sie werden dann dirty pages genannt) und gleichzeitig wird ein Log-Eintrag erzeugt. Immer dann, wenn ein checkpoint-Befehl (automatisch und periodisch durch einen Serverprozess) auf die Datenbank erfolgt, werden die dirty pages mit den Seiten der Datenbankdatei abgeglichen und erst dann die Seiten in der Datenbankdatei physisch verändert und aktualisiert.
Virtuelles Logfile
Transaction Logs sind sequenzielle Dateien. Der SQL-Server schreibt also einen neuen Datensatz hinter den letzten. Jeder dieser Datensätze hat eine Logical Sequence Number (LSN).
Wird eine Datenbank mit dem dazugehörigen Logfile angelegt, stellt der erste Eintrag im Log den Beginn der logischen (und in diesem Fall auch physischen) Logdatei dar. Jeder weitere Eintrag wird sequenziell hinzugefügt und erhält die nächst höhere LSN. Der zuletzt eingefügte Eintrag hat folglich die größte LSN. Alle diese Einträge, die mit Transaktionen in Zusammenhang stehen, befinden sich in einer sog. LSN-Kette, die einen Pointer zur zuletzt abgeschlossenen Transaktion und einen weiteren Pointer zur nächsten Transaktion besitzt.
Der MS SQL-Server zerteilt die Logdatei in einzelne Abschnitte, die virtuelle Logfiles (VLFs) genannt werden.
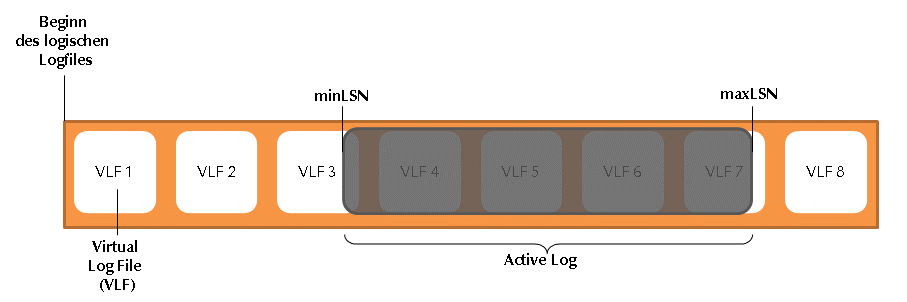
Die Abbildung zeigt ein virtuelles Logfile: Der Bereich zwischen der größten und kleinsten LSN (grau) ist das Active Log. Es enthält alle Anweisungen, die im Falle eines Crashes (unerwartetes Herunterfahren des Servers, Hardwareausfall,…) für ein Rollback der Datenbank notwendig sind. Bei einem Rollback wird das Active Log gelöscht, weil dort nicht abgeschlossene (not committed) Transaktionen enthalten sind, und die Datenbank in einen konsistenten Zustand überführt werden soll.
Zu beachten ist, dass das Active Log nicht aus nur einer aktiven Transaktion besteht.
Ein Beispiel: MinLSN steht bei Transaktion T1, die um 9:00 Uhr startet und 30 Minuten benötigt. Eine weitere Transaktion T2 startet um 9:10 Uhr und benötigt zwei Minuten. Dessen LSN ist größer als die von T1, weil das Log sequenziell geschrieben wird und T2 später startet als T1. Beide Transaktionen sind Teil des Active Logs. Am Ende von T1 liegt die minLSN bei einer Transaktion T3, die um 9:25 Uhr startet. Am Ende von T1 um 9:30 Uhr ist das Log zu T1 nicht mehr Teil des Active Log.
Man kann sich das Active Log deshalb vereinfachend als einen sich vergrößernden und verkleinernden Block vorstellen, der von Logstart links Richtung Logende rechts wandert.
Verkleinern des Logs
Die kleinste Einheit, die in einem Logfile verkleinert werden kann, ist nicht etwa ein Logeintrag oder ein Block, sondern ein VLF. Enthält ein VLF einen Logeintrag der Teil des Active Logs ist, kann kein Verkleinern erfolgen.
Ein VLF kann sich in folgenden vier Zuständen befinden:
Active: Das VLF enthält mindestens einen Eintrag der Teil des Active Logs ist und ist somit für eine mögliche Wiederherstellung notwendig.
Recoverable: Das VLF ist inaktiv aber nicht geleert oder gesichert. Der Speicherplatz kann nicht wiederverwendet werden.
Reusable: Das VLF ist inaktiv. Es wurde geleert oder gesichert, der Speicherplatz kann wiederverwendet werden.
Unused: Das VLF ist inaktiv und enthielt noch nie Logeinträge.
Der Statuswechsel von Recoverable zu Reusable wird als log truncation (Abschneiden) bezeichnet. Um zu verstehen, wann ein solcher Statuswechsel passiert, müssen wir uns zunächst mit den unterschiedlichen Wiederherstellungsmodellen einer Datenbank im MS SQL-Server auseinandersetzen.
Wiederherstellungsmodelle
SQL-Server bietet drei unterschiedliche Wiederherstellungsmodelle: vollständig, massenprotokolliert und einfach.
Beim vollständigen Wiederherstellungsmodell führt SQL-Server eine lückenlose Protokollierung aller Ladeoperationen der Datenbank mit. Dadurch ist es möglich, eine Wiederherstellung zu einem beliebigen Zeitpunkt (z. B. vor einem Anwender- oder Benutzerfehler) hergestellt werden. Das Logfile wird immer größer und sollte deshalb regelmäßig gesichert werden.
Das massenprotokollierte Wiederherstellungsmodell ergänzt das vollständige und ermöglicht schnellere Massenkopiervorgänge. Beim Kopieren von Datensätzen mittels insert-Statement werden diese sofort in die Datenbankdatei, ohne Umweg über das Transaction Log, geschrieben. Von anderen Vorgängen (z. B. update- oder delete-Statements) wird aber auch hier das Logfile immer größer und muss regelmäßig gesichert werden.
Beim einfachen Wiederherstellungsmodell wird der Protokollspeicherplatz nach einer bestimmten Zeit wieder freigegeben (database checkpoint). Muss das System wiederhergestellt werden, sind alle Änderungen nach der letzten Sicherung nicht geschützt. Das ist trotzdem genau der Modus, der für unsere Projekte völlig ausreicht! Denn wir starten in einem Fehlerfall einfach den SSIS-Job erneut und importieren und verarbeiten einfach die Daten seit der letzten Sicherung. Die Speicherplatzanforderungen werden dabei möglichst geringgehalten und die Verwaltung von Protokollspeicherplatz sowie das Sichern des Logfiles entfällt.
Logfile abschneiden
In einer Datenbank mit einfachem Wiederherstellungsmodell kann ein Statuswechsel der VLFs zwischen Recoverable und Reusable mit einem checkpoint erfolgen. Dabei werden im Cache durch eine Transaktion veränderte Seiten in das Datenbankfile geschrieben und der Speicherplatz im Log wird zur Wiederverwendung geleert.
Bei den anderen beiden Wiederherstellungsmodellen kann der Log-Speicherplatz nur durch ein Backup des Logfiles geleert werden. Nach erfolgtem Backup werden die VLFs als wiederverwendbar markiert.
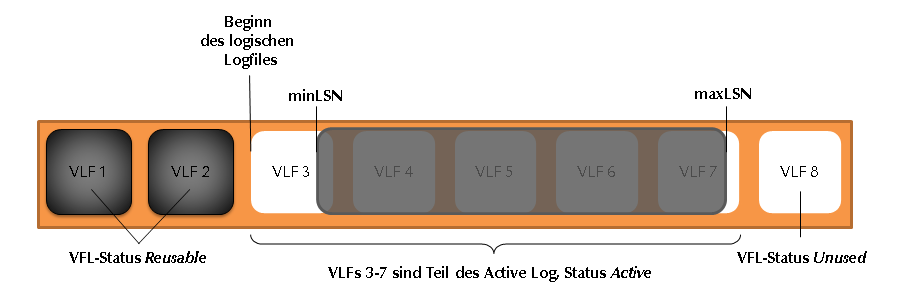
VLF 1 und 2 sind inaktiv und können wiederverwendet werden, in den VLFs 3 bis 7 befindet sich das Active Log.
Erreicht das Active Log das Ende von VLF 7, sucht der SQL-Server das nächste inaktive VFL. In Abbildung 2 wäre das VLF 8. Erst wenn das physische Ende des Logs erreicht ist, sucht der SQL-Server nach dem nächsten inaktiven VLF und landet bei VLF 1 und 2. Ist kein weiteres freies VLF verfügbar, will der SQL-Server das Logfile automatisch vergrößern (z. B. um 10%, wie wir es standardmäßig bei der Erstellung einer Datenbank in unseren Projekten angeben). Schlägt dieses Vergrößern fehl, z. B. weil die automatische Vergrößerung deaktiviert wurde oder kein weiterer physischer Speicherplatz mehr verfügbar ist, meldet der Server die „9002: Das Transaktionsprotokoll für die ‘Name’-Datenbank ist voll.“ und der Kunde, dass das System heute Nacht nicht durchgelaufen ist.
Im Regelfall bestimmt SQL-Server die optimale Größe und Anzahl VLFs. Ein Log, das sich automatisch um kleine Einheiten vergrößert, wird irgendwann sehr viele, kleine VLFs enthalten. Man spricht dann von einem fragmentierten Log.
Informationen über Struktur und Beschaffenheit des Logfiles liefert DBCC LogInfo. Die Anfrage gegen die Datenbank liefert pro VLF einen Datensatz und informiert über den Status eines VLF. Status 0 zeigt dabei an, dass das VLF zur Verwendung bereitsteht, Status 2 zeigt, dass es nicht wiederverwendet werden kann (sich also im vorher beschriebenen Status Active oder Recoverable befindet).
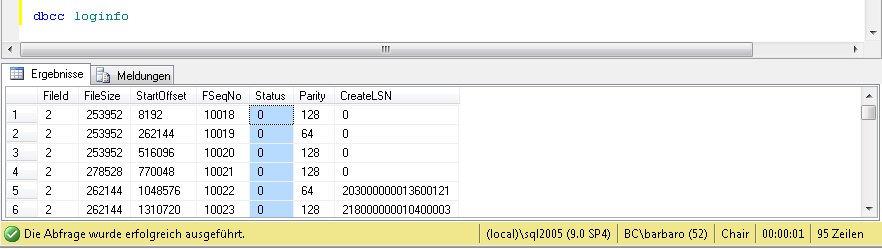
Das Logfile unserer Standardanwendung Chair besetzt auf meinem Server 95 Zeilen. Es werden also 95 VLFs verwendet! Setzt man die Loginfo während des laufenden Prozesses ab, erkennt man, wie immer mehr VLFs vom Status 0 (inaktiv) in den Status 2 (aktiv) wechseln. Am Ende des Transform-Prozesses sind nahezu alle VLFs in Benutzung. Setzt man jetzt einen checkpoint auf die Chair-DB ab, werden die veränderten Seiten vom Cache in die Datenbank geschrieben und die VLFs freigegeben. Nach dem checkpoint haben die VLFs also wieder den Status 0 (inaktiv). Die Größe des Logfiles beträgt allerdings immer noch 95 VLFs, es wird also deshalb nicht weniger Speicherplatz verwendet.
Lösungswege
Welche Möglichkeiten habe ich also nun, wenn mein Transform_All-Prozess fehlschlägt und der Server ein volles Log meldet?
- Logfile verkleinern:
Mit dem Datenbankkommando DBCC Shrinkfile wird das Logfile physisch verkleinert, inaktive VLFs werden also freigegeben. Bei einem Neustart des Transform_All-Prozesses werden dann aber wieder genau so viele VLFs wie vorher benötigt. Findet der SQL-Server dann im Logfile keine inaktiven VLFs mehr, wird er das File vergrößern und wahrscheinlich wieder an seine Grenzen stoßen und mit Meldung 9002 abbrechen. Wenn sich noch weitere Datenbanken auf dem Server befinden, kann es ratsam sein, das Kommando auf diesen abzusetzen. Dadurch werden auch deren Logfiles physisch verkleinert und vielleicht ist dann genügend freier Speicherplatz für den fehlgeschlagenen Transform_All-Prozess verfügbar. Das Problem wäre für heute vom Tisch.
2. Inserts splitten:
Wenn der Prozess, bei dessen Ausführung das Log voll läuft, einen langen Teilprozess beinhaltet, der das Active Log besonders vergrößert, kann es hilfreich sein, diesen Teilprozess in mehrere kleinere Prozesse aufzusplitten. Wird bspw. während des Transform_All-Prozesses ein einziges insert-Statement aufgerufen, das jeweils 10000 Datensätze aus den Jahren 2007 bis 2012 in eine Tabelle schreibt, müssen alle diese Daten, wie anfangs erklärt, zunächst ins Log geschrieben werden. Erst bei einem checkpoint wandern diese Daten vom Log- ins Datenbankfile und der Logspeicher kann durch ein dbcc shrinkfile freigegeben werden.
Unterteilt man nun das insert-Statement in einzelnen Jahre mit den Prozeduren Proc_2007, Proc_2008, usw., die jeweils ein Insert-Statement pro Jahr absetzen, ist der benötigte Speicherplatz bedeutend kleiner, und dem Transform_All-Prozess reicht ggf. insgesamt der verfügbare Speicherplatz aus. Das Problem wäre auch morgen noch vom Tisch.
3. Speicher erweitern:
-
- Wir spielen den Ball an den/die Datenbankadmin des Kunden und bestellen dort mehr Speicherplatz für den Server oder bitten darum, die Festplatte aufzuräumen und nicht mehr notwendige Dateien zu entfernen. Mit ein bisschen Glück reicht der neu verfügbare Platz aus, um das Problem ad hoc zu lösen.
- Das Logfile kann aus mehreren Dateien bestehen, die auch an unterschiedlichen physischen Orten liegen können. Wenn möglich, kann also das bestehende File einfach erweitert werden, das auf einer anderen Festplatte liegt.
Das Logfile kann auch auf einer anderen Festplatte liegen als die Datenbank und somit einfach verschoben werden. - Backup des Logs erstellen (nicht für Wiederherstellungsmodell einfach): Das Backup des Logs beim vollständigen oder massenprotokollierten Wiederherstellungsmodell entspricht dem database checkpointdes einfachen Wiederherstellungsmodells. Die Daten im Log werden in das Datenbankfile geschrieben und der Speicherplatz des Logfiles verkleinert.
So, das sollte erstmal ausreichen.
