“Das einzig Beständige ist der Wandel” – als Bonmot oft strapaziert und unterschiedlichsten historischen Größen zugeschrieben, gewinnt dieses alte Thema im Kontext von Business Intelligence jedoch berechtigterweise neue Bedeutung, denn die Fähigkeit, flexibel auf sich ändernde Prozesse, Organisationsstrukturen und Managementperspektiven reagieren zu können, ist für derartige Systeme unabdingbar. Wie ist nun aber in OLAP-Datenmodellen konkret mit veränderlichen Merkmalen und Strukturen umzugehen? Welche Sicht auf die Dinge ist die richtige? Dieser Blogbeitrag stellt grundsätzliche Ansätze zur Historisierung an überschaubaren Beispielen dar.
Ausgangssituation: Ein Beispielszenario
Das folgende kleine Beispiel soll die Grundsituation bilden:
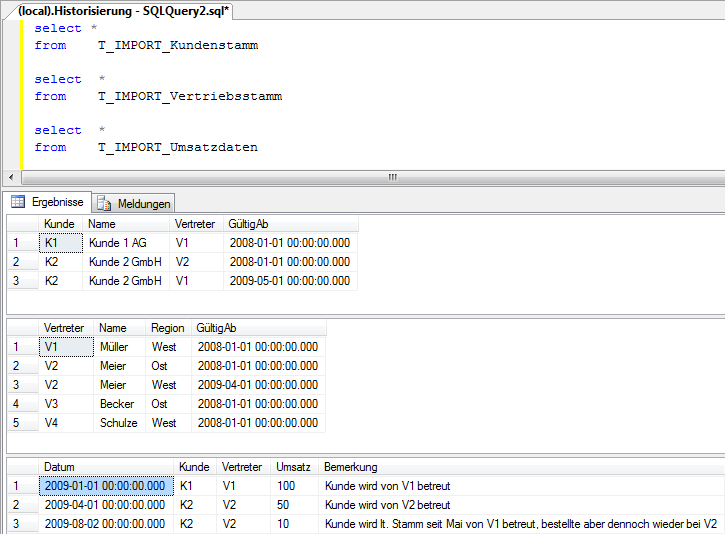
Aus den obigen Daten sind abhängig vom späteren Modellierungsansatz im Detail mehrere potentielle Problematiken zu erkennen:
- Kunde 2 GmbH (K2) wird seit Mai 2009 von einem anderen Vertreter betreut.
- Vertreter Meier (V2) wird im Zuge einer Organisationsänderung der Region West zugeordnet.
- Im Widerspruch zur organisatorischen Vorgabe laut Kundenstamm bestellt Kunde K2 am 02.08.2009 bei Vertreter V2.
Abstrahiert sind daraus unterschiedliche Gedanken und Entscheidungen abzuleiten. Handlungsbedarf entsteht grundsätzlich bei der Änderung von Organisationsstrukturen, z.B. im Vertrieb (Verantwortungsbereiche von Mitarbeitern im Außendienst für Kunden oder Zuordnung zu Regionen) oder auch im Produktportfolio (Artikel vs. Warengruppen), sofern die entsprechenden Merkmale in der OLAP-Datenbank als mehrstufige Hierarchien anstelle flacher, unabhängiger Listen abgebildet sind. Eine der goldenen Regeln der multidimensionalen Modellierung („abhängige Merkmale bilden Hierarchien, unabhängige Merkmale separate Dimensionen“) führt im Falle der Abhängigkeit nur für bestimmte Zeiträume zu einem Zielkonflikt in der Abbildung. Grundsätzlich wäre für die Abbildung von Kunden und Vertrieb die Modellierung einer einzigen Dimension mit den Hierarchiestufen „Region-Vertreter-Kunde“ nahe liegend. Doch die Zuordnungen innerhalb dieser Hierarchie sind veränderlich, und die Anforderungen hinsichtlich der Sichtweise auf diese Änderungen stellen einen Widerspruch dar:
Aktuelle Zuordnung
Der Wunsch nach Vergleichbarkeit von Organisationseinheiten erfordert die Abbildung des aktuellen Zustands.
Um also die oft zitierte „Apfel-mit-Birnen“-Betrachtung von beispielsweise Umsatzzeitreihen über mehrere Jahre zu vermeiden, wird davon ausgegangen, dass Kunde K2 schon immer von Vertreter V1 betreut wird und Vertreter V2 schon immer der Region West zugeordnet ist. Das bedeutet, auch der Umsatz von Kunde K2 aus dem April 2009 wird Vertreter V1 zugerechnet, obwohl zu diesem Zeitpunkt konsistent sowohl laut Stammdaten als auch laut Bewegungsdaten Vertreter V2 verantwortlich ist. Gleiches gilt für Region West, der die Umsätze der Kunden von Vertreter Meier rückwirkend zugeschlagen werden.
Historische Zuordnung
Die Forderung nach buchhalterisch korrekter (verursachungsgerechter) Zuordnung z.B. im Sinne der Nachvollziehbarkeit und Provisionierung verlangt die Darstellung des historisch jeweiligen tatsächlichen Zustands.
Die obige Darstellung erzeugt also (Zwischen-)Summen, die im Widerspruch zu den Tatsachen stehen, die z.B. aus den Buchungen des ERP-Systems ablesbar sind.
Lösungsansätze
Die Fälle 1 (Zuordnung Kunde zu Vertreter) und 2 (Zuordnung Vertreter zu Region) können mit Hilfe paralleler Hierarchien abgebildet werden. Eine Hierarchie stellt den jeweils aktuellen Zustand dar, eine weitere den jeweils zum entsprechenden Zeitpunkt tatsächlichen („historischen“).
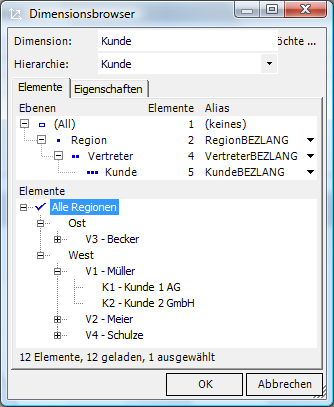
Beide Hierarchien haben Nachteile, d.h. abhängig von der Fragestellung des Betrachters muss die jeweils andere Hierarchie herangezogen werden: Die aktuelle Darstellung ermöglicht Vergleiche, entspricht jedoch nicht den historischen Tatsachen; die historische Darstellung ist buchhalterisch korrekt, stellt jedoch alle Elemente, die Veränderungen erfahren haben, entsprechend oft dar, sodass in unserem Fall z.B. keine eindeutige Summe über Kunde K2 ablesbar wäre, da dieser sowohl unter Vertreter V1 als auch unter Vertreter V2 (der wiederum in zwei Regionen auftaucht) mit den jeweiligen Umsätzen erscheint. Hintergrund: Alle Elemente erhalten kombinierte Schlüssel aus den betroffenen Ebenen (hier: Kunde-Vertreter-Region).
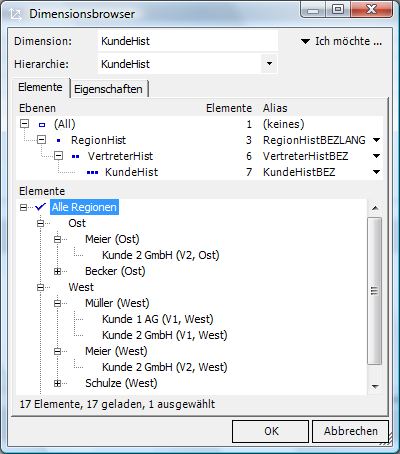
Fall 3 (Inkonsistenz zwischen Stamm- und Bewegungsdaten) kann letztlich nur durch eine Trennung der Merkmale in zwei Dimensionen „Kunden“ und „Vertrieb“ gelöst werden. Mit anderen Worten: Die Faktentabelle, in der als eindeutiger Identifikator eigentlich der Kunde vorliegt, wird um die zusätzliche Spalte Vertreter angereichert. Dieser bei „unsauberen“ ERP-Daten einzig sinnvolle Modellierungsansatz (laut Vorgabe im Kundenstamm besteht eine zumindest zeitpunktweise Abhängigkeit zwischen Kunde und Vertreter, die Bewegungsdaten erlauben jedoch Abweichungen, folglich herrscht faktisch Unabhängigkeit zwischen beiden Merkmalen) sorgt also für eine Verbreiterung der Faktendaten mit eigentlich redundanten Informationen (transitive Abhängigkeiten, die nach den Regeln relationaler Modellierung zu normalisieren wären).
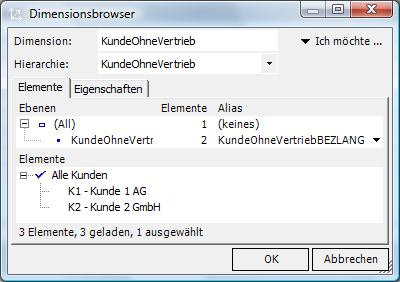
Um den gedanklichen Kreis zu schließen: Diese Überlegungen sollten jedoch keinesfalls dazu führen, alle in Frage kommenden Merkmale einfach unabhängig voneinander, also als separate Dimensionen, abzubilden, denn dadurch wird dem Anwender weitgehend die Möglichkeit genommen, komfortable „Drill-downs“ entlang der Unternehmenshierarchien durchzuführen. Auch Planungsanwendungen gestalten sich ohne hierarchische Strukturen äußerst schwierig, denn die Verteilungslogik bei Werteingaben auf verdichteter Ebene wäre dann nicht vom System automatisch aus den Dimensionsstrukturen ablesbar, sondern müsste manuell als Regelwerk implementiert werden. Die goldene Modellierungsregel mit der Gretchenfrage „Abhängigkeit“ gilt also weiterhin, lediglich eingeschränkt um die oben beschriebenen Aspekte.
Weiter gehende Betrachtungen
Die im selben Kontext gelegentlich geforderte Stichtagsbetrachtung, also die Abbildung von Zuordnungen, die zu einem gegebenen Zeitpunkt in der Vergangenheit aktuell waren, stellt nichts anderes als einen Sonderfall der aktuellen Betrachtung dar, auch wenn diese Feststellung auf den ersten Blick überraschen mag. Eine flexible Lösung, diese Anforderung im Bedarfsfalle abzubilden, ist die Speicherung des gewünschten Stichtags (Betrachtungsdatum) als Systemparameter, wobei dieser mit dem jeweils aktuellen Datum (Getdate()) vorbelegt wird. Wenn dieser Parameter bei der Aufbereitung der Dimensionsstrukturen berücksichtigt wird (im obigen Beispiel durch Vergleich mit der Spalte „gültig ab“, kann das System bei Bedarf automatisch für jeden beliebigen Stichtag aufbereitet werden.
Wenige Technologieanbieter ermöglichen die Modellierung “echter” Zeitabhängigkeit, wobei sich der Inhalt einer Dimension durch eine Auswahl in einer anderen Dimension ändert. Nach unseren Erfahrungen erweisen sich derartige Ansätze bei nichttrivialen Datenmengen als sichere Performancekiller.
Die von Microsoft seit Analysis Services 2005 propagierten Ansätze SCD (Slowly Changing Dimensions) und RCD (Rapidly Changing Dimensions) klingen vielversprechend, entpuppen sich jedoch bei genauer Betrachtung als Variationen des obigen Themas:
- SCD Typ 1 entspricht regulären Dimensionen ohne Historisierung.
- SCD Typ 2 verwendet eine interne Element-ID, um die Historie des Elements zu erhalten; dies entspricht dem oben beschriebenen Ansatz „historisch“.
- SCD Typ 3 hält keine Historie; Original- und aktueller Status sind abrufbar.
- RCD speichert in einer zusätzlichen Dimensionstabelle alle relevanten Attributkombinationen; die Fakten sind sowohl über die Original-ID mit der Dimensionstabelle als auch über einen Surrogatschlüssel mit der Zusatztabelle verbunden.
