Das Konzept der m:n-Beziehungen in Microsoft Analysis Services (MSAS) ist mächtig und vielseitig. Es erleichtert die multidimensionale Modellierung von Fragestellungen, bei denen sowohl auf Summen- als auch auf Detailebene gezählt werden soll, auf aggregierter Ebene jedoch Mehrfachzählungen zu vermeiden sind. Erfahrene „relationale Datenbanker“ denken hier sofort an das verwandte SQL-Konzept Distinct Count. Wie m:n-Beziehungen in MSAS funktionieren, wurde bereits im Blogbeitrag „m:n-Dimensionsbeziehungen in Microsoft Analysis Services definieren“ beschrieben. Auch DeltaMaster Modeler unterstützt den Ansatz seit Release 211 vollautomatisch. In diesem Blogbeitrag möchte ich aus aktuellem Anlass eine Erweiterung vorstellen: Wie ermittelt man in diesem Kontext eigentlich korrekte Restmengen?
Zunächst einige typische Beispiele für Praxissituationen, die m:n-Beziehungen erfordern:
- Vertriebsdaten (Absatz/Umsatz) im Kontext beliebig vieler Kaufgründe
- Analyse von Supporttasks und Einzelschritten (Activities)
- Umfragedaten mit optionalen Mehrfachnennungen
- Kundennummern und mehrere Einzelverträge (z. B. bei Energieversorgern)
Für das heutige Thema werden wir uns in der Folge auf das erste Beispiel konzentrieren, zumal hierzu ein ideales Beispiel in Form der Microsoft-Demoanwendung „Adventure Works“ vorliegt. Das Szenario behandelt einen Sportartikelhändler, zu dessen tages-/kunden-/produktgenauen Rechnungsdaten in einer weiteren Tabelle optional beliebig viele Kaufgründe vorliegen. Kunde A hat sein Mountainbike also gewählt, weil es zum Sonderpreis verfügbar war, während Kundin B ihre beiden Tennisschläger sowohl wegen der überzeugenden Technik als auch aufgrund des ansprechenden Designs erstanden hat. Nun jedoch kauft Kunde C einen Fußball ohne Angabe irgendwelcher Gründe.
Die Marketingabteilung möchte erwartungsgemäß analysieren, wie oft welcher Kaufgrund genannt wurde und wie viele Gründe durchschnittlich angeführt wurden. Kein Problem bis hierhin, auch ohne m:n. Wieviel Absatz und Umsatz wurde pro Kaufgrund erwirtschaftet? Dank m:n lässt sich auch dies leicht lösen, ohne dass sich durch die beiden Angaben der Tenniskundin der Umsatz vervielfacht.
| Rechnung | Datum | Kunde | Produkt | Umsatz | Absatz |
|---|---|---|---|---|---|
| 1 | 01.01.2014 | A | Mountainbike | 1000 | 1 |
| 2 | 02.02.2014 | B | Tennisschläger | 400 | 2 |
| 3 | 03.03.2014 | C | Fußball | 50 | 1 |
Tab. 1: Vertriebsdaten
| Rechnung | Kaufgrund | ||||
|---|---|---|---|---|---|
| 1 | Preis | ||||
| 2 | Technik | ||||
| 3 | Design |
Tab. 2: Kaufgründe
| Kaufgrund | Absatz | Umsatz | |||
|---|---|---|---|---|---|
| Alle Kaufgründe | 4 | 1450 | |||
| Preis | 1 | 1000 | |||
| Technik | 2 | 400 | |||
| Design | 2 | 400 | |||
| keine Angabe | 1 | 50 |
Tab. 3: Ergebnistabelle
Wie aus den Beispieldaten ersichtlich ist, darf über die Dimension „Kaufgrund“ nicht wie sonst üblich summiert werden (oberste Zeile, kursiv dargestellt). Genau das ist das erwünschte Verhalten, das durch die Modellierung zweier separater MeasureGroups für Vertriebsdaten und Kaufgründe und den anschließenden Einsatz einer m:n-Beziehung erzielt wird. Wie jedoch lässt sich die nächste Frage der Kollegen aus dem Bereich Marketing beantworten: Wieviel Absatz und Umsatz entstand ohne jegliche Angabe von Gründen (unterste Zeile, ebenfalls kursiv dargestellt)? Hierzu liegen ja keinerlei Rohdaten vor!
Eine einfache Restwertberechnung (Summe minus Einzelelemente) führt bei Distinct Count/m:n ja definitionsgemäß zum falschem Resultat. Die Lösung ist wie nach kurzem Nachdenken so oft ernüchternd simpel: Es wird eine zusätzliche Ausprägung namens „ohne Ausprägung“ (hier: „keine Angabe“) benötigt. Leicht gesagt, doch wie ist dies technisch zu bewerkstelligen? Ganz einfach mit den folgenden beiden Schritten:
- In der betroffenen Dimension (hier: Kaufgrund) wird ein Dummy-Element hinzufügt.
- In der Bridge-MeasureGroup (hier: Kaufgründe) werden zusätzlich die Elementkombinationen ohne Nennung gezählt.
Abschließend die entsprechenden SQL-Views aus der AdventureWorks2012-Demo:

ALTER VIEW [dbo].[V_IMPORT_DIM_SalesReason] AS
SELECT SalesReasonID,
[name] SalesReasonTEXT
FROM sales.SalesReason
UNION ALL
SELECT 999,
'No sales reason'
GO
ALTER VIEW [dbo].[V_IMPORT_FACT_Bridge_Sales_SalesReason] AS
SELECT -- Dims
soh.OrderDate,
soh.CustomerID,
sod.ProductID,
sosr.SalesReasonID,
-- Msrs
CONVERT(float, 1) SalesReasonCounter
FROM sales.SalesOrderHeader soh#
INNER JOIN sales.SalesOrderDetail sod
ON soh.SalesOrderID = sod.SalesOrderID
INNER JOIN sales.SalesOrderHeaderSalesReason sosr
ON soh.SalesOrderID = sosr.SalesOrderID
UNION ALL
SELECT -- Dims
soh.OrderDate,
soh.CustomerID,
sod.ProductID,
999 SalesReasonID,
-- Msrs
CONVERT(float, 1) SalesReasonCounter
FROM sales.SalesOrderHeader soh
INNER JOIN sales.SalesOrderDetail sod
ON soh.SalesOrderID = sod.SalesOrderID
LEFT JOIN sales.SalesOrderHeaderSalesReason sosr
ON soh.SalesOrderID = sosr.SalesOrderID
WHERE sosr.SalesReasonID IS NULLDer entscheidende Trick ist der zweite Teil der FactView unterhalb des UNION ALL: Es müssen alle Bewegungsdaten, die keine Entsprechung in der Kaufgrundtabelle haben, ermittelt und mit der Dummy-Ausprägung versehen werden. Da im oberen SELECT-Statement alle Tabellen mit INNER JOIN verknüpft werden, enthält das Resultat nur Käufe mit Kaufgründen; im unteren SELECT-Statement wird die Kaufgrundtabelle per LEFT JOIN verknüpft, und durch eine WHERE-Klausel werden ausschließlich Käufe ohne Kaufgrund zurückgegeben. Mit anderen Worten: Beide Mengen müssen disjunkt sein.
Abschließend das Ergebnis mit den AdventureWorks-Originaldaten in DeltaMaster:
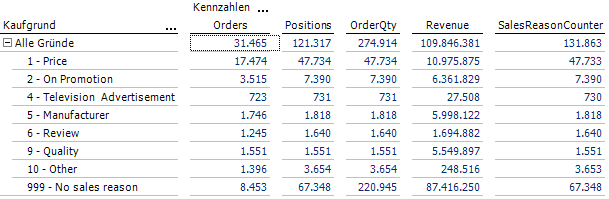
Abb. 1: Ergebnis in DeltaMaster
