Stellvertretende Schlüssel sind besser als Textschlüssel. Wie mit Hilfe von SQL-Server eine lückenlose Nummerierung entwickelt werden kann, zeigt dieser Blogbeitrag. Details zum Thema Identitätsspalten und -funktionen werden ebenso betrachtet wie auch die Entstehung von Lücken in vergebenen Identitätswerten und deren Ursachen. Abschließend werden die Ergebnisse in einem kurzen Praxisbeispiel dargestellt.
Wer kennt nicht die Notwendigkeit von einer fortlaufenden Nummerierung in Planungsanwendungen? Häufig werden in Planungssystemen zusätzliche Informationen in der relationalen SQL-Datenbank in Tabellen gespeichert. Die Aktualisierung dieser Tabellen erfolgt meistens über einen separaten Pflegebericht in DeltaMaster, sodass die Fachabteilung die Daten ohne Hilfe aus der IT selbst aktualisieren kann. Beispiele dafür sind z. B. die Pflege von Fremdwährungen, Anlage neuer Planversionen oder die Pflege von benutzerdefinierten Hierarchien.
Unpraktischerweise bedeutet dieser Prozess aber auch, dass derartige Merkmale aus der Kombination von Spalteninhalten bestehen können, welche oft nur als Textspalten vorliegen. Diese Textschlüssel könnte man natürlich verwenden, aber dieser Blogbeitrag zum Thema Datentypen zeigt sehr schön, warum wir dies besser nicht praktizieren sollten.
Abhilfe schafft hier die Verwendung eines eigenen numerischen Schlüssels für die Datensätze. In Datenbankumgebungen wird hier von stellvertretenden Schlüsseln (engl.: surrogate keys) gesprochen.
Es gibt verschiedene Methoden, einen eindeutigen nummerischen Schlüssel zu generieren (z.B. die Funktion Binary_Checksum()), welche aber relativ „teuer“ (bezogen auf die Ausführungszeit) sind und sehr lange Schlüssel im Ergebnis liefern. Und fortlaufend ist der Schlüssel schon gar nicht.
SQL-Server bietet für diesen Zweck eine separate Spalteneigenschaft, die sogenannte Identitätsspalte. Soweit nichts Neues. Worauf zu achten ist, wenn eine automatische, lückenlose und fortlaufende Nummerierung zu erfolgen hat, zeigen wir im Folgenden.
Identity-Eigenschaft vs. -Funktion
Tabellen in SQL-Server bieten die Möglichkeit, eine beliebige Spalte für das Datenbankmodul als Identitätsspalte zu definieren. Dabei gibt es zwei Varianten: Die Identity-Eigenschaft für CREATE-TABLE-Ausdrücke und die Identity-Funktion, welche bei SELECT-INTO-Anweisungen verwendet werden kann.
Pro Tabelle kann es genau eine Spalte mit dieser Eigenschaft geben. Die Syntax sieht wie folgt aus:
CREATE TABLE dbo.T_S_Mitarbeiter ( ID INT IDENTITY(1,1) ,Vorname VARCHAR(20) NULL ,Nachname VARCHAR(20) NULL ,Geschäftsbereich INT NULL )
Hier muss für IDENTITY-Eigenschaft zusätzlich noch ein sog. SEED und INKREMENT angegeben werden.
SEED = Startwert
INKREMENT = Wert, der auf den letzten bekannten Identitätswert aufaddiert wird
Weitere Hinweise wie Standardwert, mögliche Datentypen und Rückgabetypen können hier oder unter den weiterführenden Links nachgelesen werden.
Soweit alles bekannt und nicht wirklich spannend.
Einschränkungen
Über die Microsoft Dokumentation sind wir auf einen kleinen Nebensatz aufmerksam geworden, der sich als Ursache eines „unglücklichen“ Verhaltens herausstellt. Denn die von der Identitätseigenschaft erstellten Schlüssel können Lücken aufweisen, angeblich laut Microsoft zwecks Leistungsverbesserung. Wie denn das, wenn ich eine Identitätsspalte verwende, um Schlüssel zu generieren? Wäre da nicht eine durchgehend fortlaufende Nummerierung das erwartete Ergebnis?
Eine weitere Einschränkung besteht darin, dass die Identitätseigenschaft einer SQL-Tabelle sich nicht ohne weiteres wieder entfernen lässt, wenn die Tabelle bereits Daten enthält und diese nicht verloren gehen dürfen. DeltaMaster ETL ist für diesen Fall eine große Hilfe, denn unsere Toolbox liefert dazu eine sehr nützliche Hilfsfunktion im Standard bereits mit aus: P_BC_Remove_IdentityFromColumn
Für die technisch Interessierten Leser: Die Prozedur erstellt eine temporäre Tabelle, ermittelt die Spalte mit der Identitätseigenschaft und sichert die Daten aus der entsprechenden Spalte. Anschließend wird die Ursprungsspalte gelöscht und aus der temporären Tabelle unter dem ursprünglichen Namen und dessen Datentypen wiederhergestellt.
Lücken, warum?
Aber kurz zurück, woher können Lücken in den Identitätswerten entstehen? Zur Veranschaulichung fügen wir ein paar Datensätze in unsere Tabelle ein.
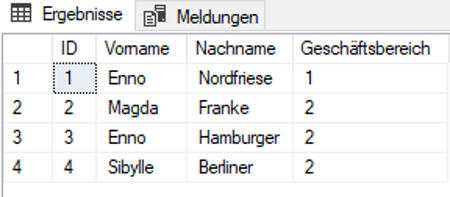 Abbildung 1: Eingefügte Testdaten
Abbildung 1: Eingefügte Testdaten
Soweit alles normal. Beim Einfügen der Datensätze mussten wir die Spalte ID nicht angeben, SQL-Server hat dankenswerterweise die Nummerierung selbständig übernommen. Fügen wir nun einen weiteren Datensatz ein:
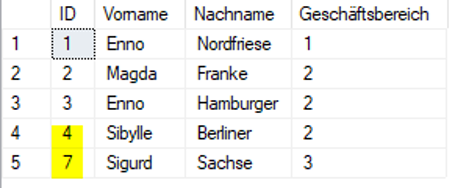 Abbildung 2: Identity nach Datenbankfehler, Serverneustart
Abbildung 2: Identity nach Datenbankfehler, Serverneustart
Ups, da fehlen doch IDs. Ursache war hier ein absichtlich provozierter Datenbankfehler bei noch geöffneten Transaktionen. Das gleiche Verhalten würde aber auch dann auftreten, wenn ein Benutzer einen Datensatz in der Tabelle gelöscht und einen neuen angelegt hätte. Typisch sind auch IDs, die um 1000 erhöht sind. Hier ist die Ursache ein abrupter Serverneustart, aus Sicherheitsgründen erhöht SQL-Server dann das SEED um 1000.
Prüfen lässt sich der aktuelle Wert mit Hilfe der Systemfunktionen IDENT_CURRENT(<Tabellenname>), @@Identity oder DBCC Checkident(<Tabellenname>). Letztere liefert zusätzlich zum aktuellen Spaltenwert der Tabelle noch den aktuellen Identitätswert, @@Identity den letzten vergebenen Wert in der aktuellen Sitzung.
Lücken umgehen, Eindeutigkeit gewährleisten
Mindestens seit der SQL-Server Version 2012 ist es möglich, den Identitätswert einer Tabelle automatisch „lückenlos“ zu halten. Der Befehl hierfür lautet wie folgt:
DBCC CHECKIDENT(<Tabellenname>, RESEED, optional new_reseed_value)
Das Argument RESEED gibt an, dass der aktuelle Identitätswert der angegebenen Tabelle zurückgesetzt werden soll, optional kann auch der Wert manuell angegeben werden, wobei davon dringend abzuraten ist.
Stellen wir uns eine beliebige, mit Hilfe von DeltaMaster ETL erstellte, Eingabeprozedur für eine Tabelle vor. Um eine fortlaufende, eindeutige Nummerierung der Datensätze zu gewährleisten reicht es aus, den DBCC-CHECKIDENT-Befehl innerhalb der Prozedur zu verwenden.
In der Praxis sind uns jedoch Fälle bekannt, in denen ein einfacher RESEED nicht ausreichend gewesen ist. Insbesondere macht es für das Datenbankmodul einen Unterschied, ob in einer Tabelle gelöscht oder der gesamte Inhalt mit TRUNCATE TABLE entfernt wurde. Wenn dann auch ein Serverabsturz dazwischenkommt, reicht es eben nicht, nur den Identitätswert zurückzusetzen. Was ist dann die Lösung? Siehe da:
--für fortlaufende Nummerierung nach Neustarts sorgen
DBCC CHECKIDENT ('T_S_Mitarbeiter', RESEED, 1)
DBCC CHECKIDENT ('T_S_Mitarbeiter', RESEED)
Die erste Ausführung des Befehls sorgt dafür, dass im Falle eines Serverneustarts, wenn durch SQL-Server die Identität um 1000 erhöht wurde, dies zurückgesetzt wird. Der zweite Befehl sorgt anschließend dafür, dass die Nummerierung bei dem nächsten freien Wert fortgesetzt wird.
Verwendet man die beiden Befehle in den P_Insert und P_Update Prozeduren, lässt sich damit eine eindeutige und permanent fortlaufende Nummerierung erstellen. Ohne separate Nummernkreistabellen, die wiederum einer eigenen Pflege bedürfen. Pragmatisch eben!
Fazit
Zugegeben, im Allgemeinen ist es für uns Business-Intelligence-Entwickler nicht notwendig, dass die Nummerierung von Datensätzen lückenlos erfolgt, da normalerweise die Namen und Bezeichner in den Berichten gewünscht werden.
Aber sollte jemand in einem Projekt z. B. eine eindeutige Belegnummer erstellen müssen, kann das beschriebene Vorgehen der kleine, pragmatische Weg sein.
Microsoft selbst hat diese Problematik ebenfalls erkannt und seit SQL Server 2012 das Konzept der SEQUENZEN eingeführt. Doch das wird in einem weiteren Blogbeitrag noch genauer betrachtet werden.
