Datenerfassungssysteme für relationale Datenbanken gründen ihre Akzeptanz vor allem auf die Vereinfachung in der Darstellung und Handlingvorteilen gegenüber mehrdimensionalen Applikationen. So finden Sie insbesondere bei der Stammdatenpflege, Planung und manuellen Ist-Datenerfassung Anwendung. Vorteile hierbei bieten zum einen eine differenzierte Benutzerverwaltung und zum anderen die einfache Nutzung von Plausibilitätsprüfungen. Eine automatisierte Verteilung von Eingabewerten (Splashing) ist auf Basis relationaler Datenerfassungssysteme nur aufwendig umzusetzen. Analysen sind nur eingeschränkt möglich. Die erfassten Daten können jedoch zu Analysezwecken an eine OLAP-Datenbank übergeben werden.
Beispielanwendung
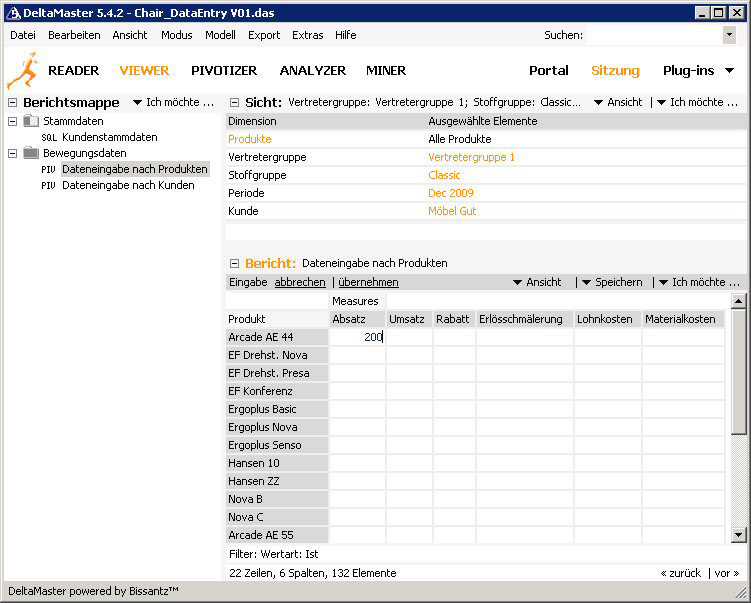
Mit der folgenden Beispielanwendung soll es möglich sein, über eine DeltaMaster-Analysesitzung sowohl Stamm- als auch Bewegungsdaten händisch erfassen zu können. Die Anwender haben die Möglichkeit neue Kunden zu anzulegen, zu pflegen oder zu löschen. Weitere Stammdaten werden vom System automatisch zur Verfügung gestellt. Darüber hinaus können Werte für folgende Kennzahlen erfasst werden.
- Absatz
- Umsatz
- Rabatt
- Erlösschmälerungen
- Lohnkosten
- Material
Der Zugriff auf die Daten wird über spezielle Benutzerrechte geregelt. Jeder Anwender kann nur die Daten lesen oder schreiben, für die er entweder Lese- und/oder Schreibrechte zugewiesen bekommen hat. In der aktuellen Beispielanwendung werden Benutzerrechte auf Basis der Dimensionsebene Regionen vergeben. Alle Elemente unterhalb dieser Ebene sind ebenfalls sichtbar.
Für die Zuweisung der Benutzerrechte ist der Administrator zuständig. Er hat die Möglichkeit diese Rechte in einer speziellen, für den „normalen“ Anwender nicht zugreifbaren, DeltaMaster-Analysesitzung zu pflegen. Außerdem können in dieser Analysesitzung weitere Stammdaten (Produkte, Regionen, Vertreter und Stoffgruppen) zentral geändert werden.
Dimensionalität des Datenbankmodells
Die verwendete Beispieldatenbank basiert auf der Chair-Demo. Das ER-Modell wurde als Schneeflockenschema abgebildet. Daten werden nur auf Basisebene erfasst.
Dimensionstabellen
| Dimension | Ebene | Erfassungsebene | Datenbank-Tabelle | Pflegbar durch |
| Periode | Jahr | T_S_Year | Administrator | |
| Quartal | T_S_Quarter | Administrator | ||
| Monat | X | T_S_Month | Administrator | |
| Wertart | Wertart | X | T_S_ValueType | Administrator |
| Kunde | Land | T_S_Country | Administrator | |
| Region | T_S_Region | Administrator | ||
| Gebiet | T_S_Region | Administrator | ||
| PLZ2 | T_S_District | Administrator | ||
| Kunde | X | T_S_Customer | Anwender | |
| Produkt | Produkthauptgruppe | T_S_Product_MainGroup | Administrator | |
| Produktgruppe | T_S_Product_Group | Administrator | ||
| Produkt | X | T_S_Product | Administrator | |
| Vertreter | Vertreter | X | T_S_Sales | Administrator |
| Stoffgruppe | Stoffgruppe | X | T_S_Color | Administrator |
Faktentabellen
Die Bewegungsdaten werden in der Tabelle T_D_Fact gespeichert. Diese Tabelle enthält Spalten für jede gebundene Dimensionsebene, für die Kennzahlen und für weitere Information zur Erfassung der Daten, wie zum Beispiel Benutzername des Erfassenden und das Erfassungsdatum.
| Spaltenname | Inhalt |
| Month_ID | ID des Monats |
| ValueType_ID | ID der Wertart |
| Customer_ID | ID des Kunden |
| Product_ID | ID des Produktes |
| Sales_ID | ID des Vertreters |
| Color_ID | ID der Stoffgruppe |
| Discount | Rabatt |
| Labour | Lohnkosten |
| Material | Materialkosten |
| Revenues | Umsatz |
| SD | Erlösschmälerung |
| Volume | Absatz |
| Transaction_ID | Transaktions-ID |
| TransactionState | 1 – Insert / 2 – Update |
| InputType | 0 – man. Erfassung / 1 – Import |
| UserID | Benutzername des Erfassenden |
| ChangeDate | Erfassung-/Änderungsdatum |
Zusätzlich zur Faktentabelle T_D_Fact existieren noch zwei weitere Tabellen, welche in direktem Zusammenhang mit der jeweiligen Faktentabelle stehen, die Tabellen T_D_Fact_Rollback und T_D_Fact_Log. In der Tabelle T_D_Fact_Rollback werden für die Dauer der Erfassung Rollbackinformationen auf Tabellenzeilenebene gespeichert, damit bei einer durch den Benutzer abgebrochenen Eingabe, die ursprünglichen Daten wieder hergestellt werden können. In der Tabelle T_D_Fact_Log werden alle gespeicherten Dateneingaben protokolliert.
Es ist empfehlenswert für alle genannten Tabellen ebenfalls Sichten bzw. Views in der Datenbank zu erstellen und über diese Sichten die Erfassung der Daten durchzuführen. Nur über Sichten kann die Zugriffsberechtigung sinnvoll gesteuert werden. Aus dem Name einer Sicht sollte hervorgehen, auf welche Tabelle sie sich bezieht. In diesem Zusammenhang hat sich die Verwendung von Präfixen bewährt, welche man den eigentlichen Objektnamen voranstellt.
| Präfix | Objekttyp | Beispiel |
| T | Tabelle | T_D_Fact |
| V | View/Sicht | V_D_Fact |
| P | Prozedur | P_Update_PIV_V_D_Fact |
| F | Funktion | F_BC_Concat |
Automatische Erzeugung der Eingabetabellen und Updatescripte
Die Faktentabellen inklusive der Rollback- und Logtabellen können über die Prozedur P_SYS_Generate_All automatisch erzeugt bzw. erweitert werden. Zu diesem Zweck wird bei der Ausführung dieser Prozedur die Tabelle T_SYS_Measure_Definition ausgelesen und abhängig von deren Einträgen die entsprechenden Objekte erstellt. Diese Tabelle enthält für jede zu erfassende Kennzahl einen Eintrag mit den entsprechend dazugehörigen Informationen.
| Spaltenname | Inhalt | Bemerkung |
| Facttable | Name der zu erstellenden Faktentabelle | |
| MeasureID | ID der Kennzahl | |
| MeasureCode | Kurzname der Kennzahl | |
| MeasureName | Name der Kennzahl | |
| MeasureDataTypeID | Datentyp der Kennzahl | Auflösung über Tabelle T_SYS_DataTypes |
| Month | Bindungsebene der Dimension Periode | NULL – nicht gebunden |
| ValueType | Bindungsebene der Dimension Wertart | NULL – nicht gebunden |
| Color | Bindungsebene der Dimension Stoffgruppe | NULL – nicht gebunden |
| Customer | Bindungsebene der Dimension Kunde | NULL – nicht gebunden |
| Sales | Bindungsebene der Dimension Vertreter | NULL – nicht gebunden |
| Product | Bindungsebene der Dimension Produkt | NULL – nicht gebunden |
In der Tabelle T_SYS_DataTypes wird definiert, bei welchen Spalten es sich um Dimensionsspalten handelt und welchen Datentyp diese erwarten. Die Bezeichnungen der Einträge der Spalte Dimension müssen mit den entsprechenden Spaltennamen der Tabelle T_SYS_Measure_Definition übereinstimmen. Bei der Generierung der Objekte werden im ersten Schritt die Fakten-, Rollback- und Logtabellen, danach die Sichten und anschließend die zur Befüllung der Faktentabellen notwendigen Prozeduren erzeugt. Die Benennung der Befüllungsprozeduren folgt ebenfalls einer Namenskonvention. Dem Namen der Faktentabelle wird ein Präfix, abhängig von der Art der Befüllungsprozedur, vorangestellt. Es wird jeweils eine Prozedur für das Einfügen, das Ändern und das Löschen von Daten erstellt.
| Ereignis | Faktentabelle | Prozedurname |
| Daten einfügen | V_D_Fact | P_Insert_V_D_Fact |
| Daten ändern | V_D_Fact | P_Update_V_D_Fact |
| Daten löschen | V_D_Fact | P_Delete_V_D_Fact |
Diese Prozeduren verwendet DeltaMaster bei schreibenden Zugriffen auf die Faktentabellen über einen SQL-Bericht.
Für schreibende Zugriffe auf die Faktentabellen über eine Pivottabelle ist nur jeweils eine Prozedur pro Faktentabelle notwendig, welche ebenfalls automatisch generiert wird.
| Ereignis | Faktentabelle | Prozedurname |
| Daten einfügen, ändern, löschen | V_D_Fact | P_Update_PIV_V_D_Fact |
Programmlogik von DeltaMaster bei aktivierter Modelltransaktion
Bei der Erfassung von Stamm- und/oder Bewegungsdaten über eine Pivottabelle oder einen SQL-Bericht über DeltaMaster sollte sich dieser prinzipiell im Viewermodus befinden. Dies kann über den Startmodus der Analysesitzung gesteuert werden.
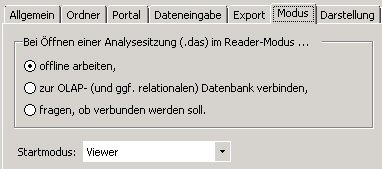
Befindet sich DeltaMaster nicht im Viewermodus, kann keine vollständige Transaktionssteuerung stattfinden.
Um eine Dateneingabe zu ermöglichen, müssen zusätzlich folgende Optionen aktiviert werden.
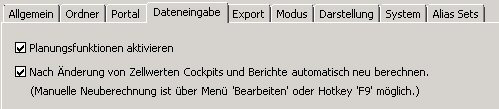
Im Dialog „Extras – Optionen“ muss das Häkchen „Planungsfunktion aktivieren“ gesetzt sein.
Im „Modell-Browser“ muss das Häkchen „Dateneingabeanwendung“ gesetzt sein.
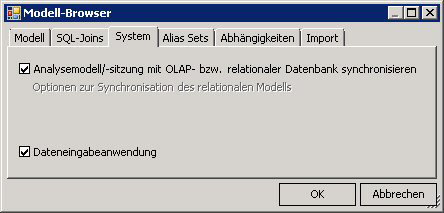
Eingabe über SQL-Berichte
Im Auswahlmenü Transaktionsteuerung muss für die Erfassung von Daten über einen SQL-Bericht der Eintrag „Datenbanktransaktion“ ausgewählt werden.
![]()
Mit diesen Einstellungen ist es möglich, eine Eingabe durch Betätigen des Knopfes „Eingabe starten“ einzuleiten.
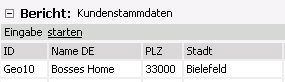
Alle nun folgenden Eingaben werden durch den Aufruf der Prozeduren P_Insert_*, P_Update_* oder P_Delete_* gefolgt von den Koordinaten der Zelle und vom eingegeben Wert an die Datenbank übergeben.
P_Insert_V_S_Customer_Input
@Customer_ID=Geo100
@Customer_Name_DE=Kunde1
@Customer_Name_EN=
@Customer_Name_FR=
@Customer_Name_ES=
@Customer_Name_IT=
@District_ID=17
@Zip=12345
@City=Lübeck
@Street=Straße
Nach erfolgter Eingabe kann diese durch Betätigen des Knopfes „Eingabe übernehmen“ gespeichert oder durch Betätigen des Knopfes „Eingabe abbrechen“ verworfen werden.
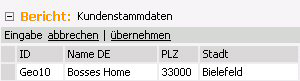
Eingabe über Pivottabellen
Für die Erfassung von Daten über eine Pivottabelle muss der Eintrag „Modellspezifische Transaktion“ ausgewählt werden.
![]()
Hier wird ebenfalls durch Betätigen des Knopfes „Eingabe starten“ eine Eingabe eingeleitet. Dabei wird die Prozedur P_DM_EditBegin aufgerufen, welche u. a. als Rückgabeparameter eine eindeutige Transaktionsnummer im Format UniqueID enthält.
P_DM_EditBegin
@TableName=V_D_Fact
@TransactionID=4cac9d44-83c0-4167-9df4-8b11a2d596b4
@ErrorDesc=
@ReturnValue=0
Diese Transaktionsnummer wird bei allen folgenden Dateneingaben innerhalb der aktuellen Transaktion durch Aufruf der Eingabeeprozedur P_Update_PIV_* an die Datenbank mit übergeben und in die Spalte Transaction_ID der aktuell bearbeiteten Datenzeile geschrieben. Sollte schon eine Transaktionsnummer in der aktuell bearbeiteten Datenzeile enthalten sein, welche nicht der übergebenen entspricht, wird dieser Datensatz im Moment von einem anderen Anwender bearbeitet und die Eingabe wird abgewiesen.
P_Update_PIV_V_D_Fact
@Product_ID=P1
@Sales_ID=V1
@Color_ID=C1
@Month_ID=200912
@Customer_ID=Geo35
@ValueType_ID=I
@TransactionID=4cac9d44-83c0-4167-9df4-8b11a2d596b4
@StepNumber=0
@MeasureName=Volume
@NewValue=20
@ErrorDesc=
@ReturnValue=0
Die Dateneingabe wird durch Betätigen des Knopfes „Eingabe übernehmen“ gespeichert. Dabei wird die Prozedur „P_DM_Edit_Commit“ aufgerufen.
P_DM_EditCommit
@TableName=V_D_Fact
@TransactionID=4cac9d44-83c0-4167-9df4-8b11a2d596b4
@ErrorDesc=
@ReturnValue=0
Das Ausführen dieser Prozedur sorgt dafür, dass die Transaktionsnummer aus allen bearbeiteten Datenzeilen gelöscht wird und somit eine Dateneingabe für andere Benutzer auf diesen Zellen wieder möglich wird. Außerdem werden der Benutzername und das Änderungsdatum in der Faktentabelle vermerkt und die Rollbackinformationen der aktuellen Transaktion gelöscht.
Beim Abbrechen einer Eingabe durch Betätigen des Knopfes „Eingabe abbrechen“ wird die Prozedur „P_DM_EditCancel“ aufgerufen. Beim Ausführen dieser Prozedur werden alle bearbeiteten Datenzeilen mit der aktuellen Transaktionsnummer aus der Faktentabelle gelöscht und aus der Rollback-Tabelle wieder hergestellt.
P_DM_EditCancel
@TableName=V_D_Fact
@TransactionID=4cac9d44-83c0-4167-9df4-8b11a2d596b4
@ErrorDesc=
@ReturnValue=0
Erstellung einer DeltaMaster-Analysesitzung für den Zugriff auf eine relationale Datenbank
Zur Erstellung einer DeltaMaster-Analysesitzung zur Eingabe von Daten in eine relationale Datenbank müssen folgende Schritte durchgeführt werden:
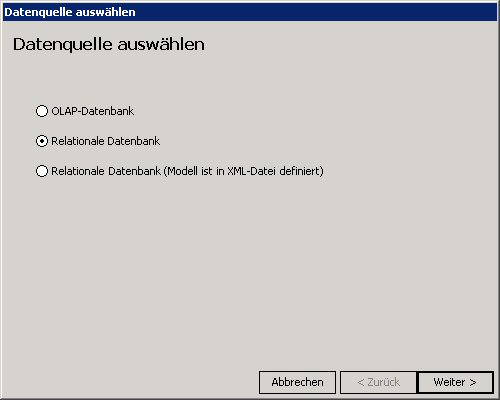
1. Über den Menüeintrag „Datei – Neues Analysemodell“ eine neue Analysesitzung erstellen. Im folgenden Dialog „Datenquelle auswählen“ muss die Option „Relationale Datenbank“ aktiviert sein. Über den Knopf „Weiter“ wird der nächste Dialog geöffnet
2. Im Dialog „Relationale Datenbank“ muss unter „OLE DB-Datenquelle“ der Datenbankserver und die entsprechenden Datenbank gewählt werden. Um zum nächsten Dialog zu gelangen muss der Knopf „Weiter“ angeklickt werden.
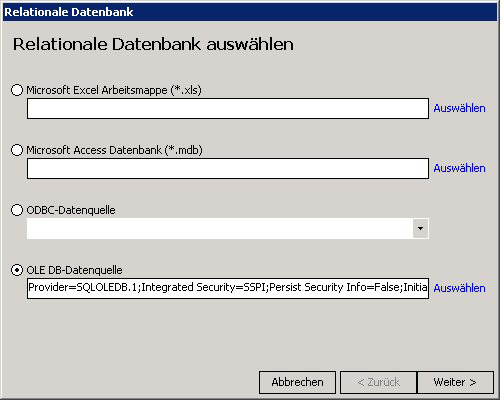
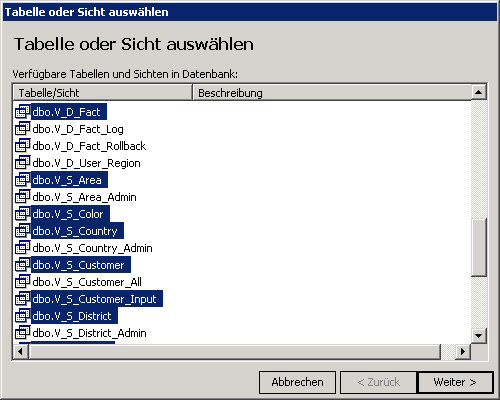
3. Im Dialog „Tabelle oder Sicht auswählen“ müssen die Tabellen oder Sichten ausgewählt werden, auf die mit DeltaMaster zugegriffen werden soll. Eine Mehrfachauswahl kann durch gleichzeitiges Drücken der Strg-Taste und der linken Maustaste bewerkstelligt werden. Durch Klicken auf den Knopf „Weiter“, werden die ausgewählten Objekte in DeltaMaster geöffnet.
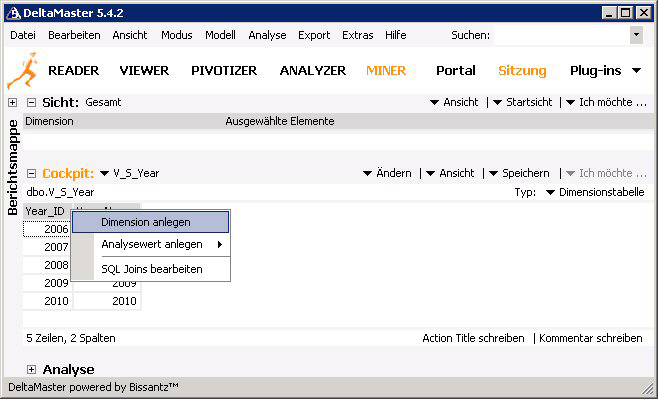
4. Zum Aufbau der Dimensionen muss die entsprechende Tabelle aus der Cockpitliste gewählt werden. Um eine neue Dimension zu erstellen, wird mit der rechten Maustaste auf den Spaltenkopf der Spalte geklickt, auf deren Basis eine neue Dimension erstellt werden soll und im danach erscheinenden Kontextmenü der Eintrag „Dimension anlegen“ gewählt. In einem Schneeflockenschema wird üblicherweise die Schlüsselspalte der Tabelle verwendet.
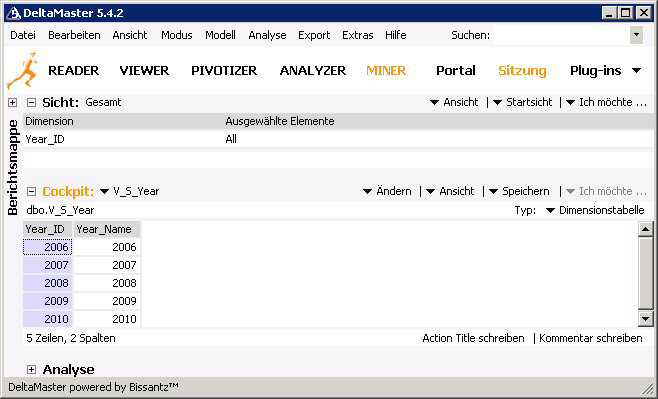
5. Wurde die Dimension erfolgreich erstellt, wird die verwendete Schlüsselspalte in der Tabelle Blau eingefärbt.
6. Zum Anlegen alternativer Bezeichnungen können den Dimensionselementen der jeweiligen Ebene zusätzliche Elementeigenschaften zugewiesen werden. Hierzu muss mit der rechten Maus auf den Spaltenkopf der Spalte geklickt und im dann erscheinenden Kontextmenü der Eintrag „Elementeigenschaften anlegen“ gewählt werden.
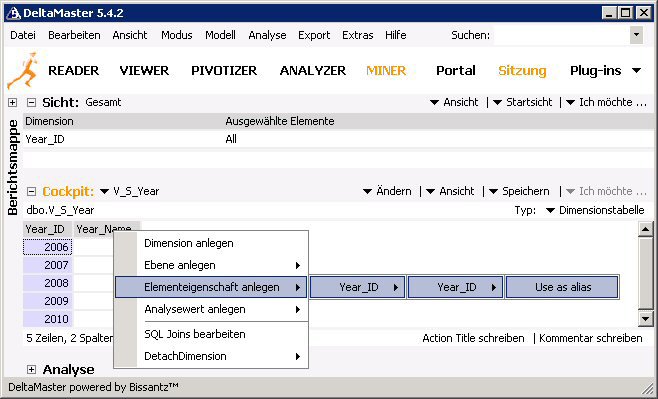
7. Spalten, deren Inhalte als Elementeigenschaften genutzt werden, sind an der gelben Einfärbung erkennbar.
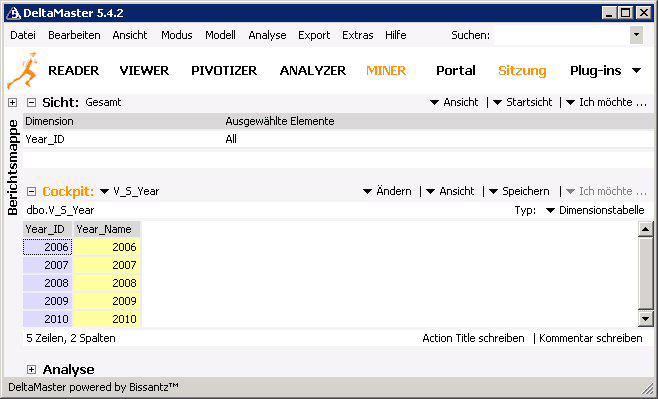
8. Zum Einfügen weiterer Dimensionsebenen, muss aus der Cockpitliste die entsprechende Tabelle gewählt und mit der rechten Maustaste auf den Spaltenkopf der Schlüsselspalte geklickt werden. Im danach erscheinenden Kontextmenü wird der Eintrag „Ebene anlegen“ gewählt. Die Reihenfolge der Ebenen kann nachträglich jederzeit per Drag-and-drop geändert werden.
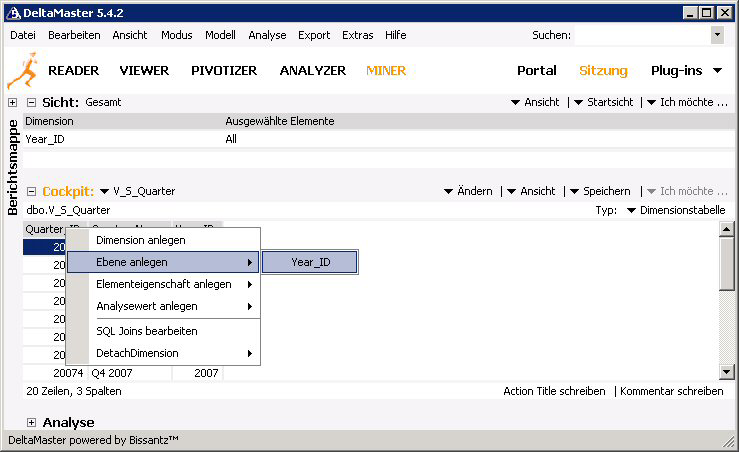
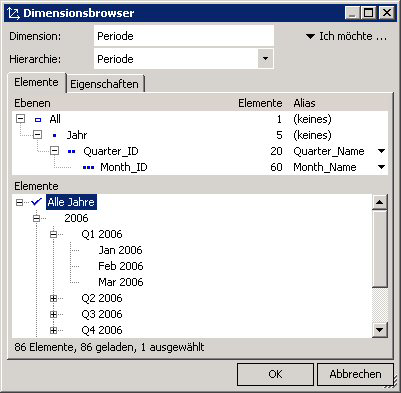
9. Die aufgeführten Schritte werden für alle zu erstellenden Dimensionen und Dimensionsebenen wiederholt. In der folgenden Abbildung ist die Dimension Periode zu sehen, welche aus den Ebenen Jahr, Quartal und Monat besteht.
10. Nach erfolgter Erstellung aller Dimensionen werden die Analysewerte angelegt. Dazu wird im Cockpitfenster die Faktentabelle ausgewählt und mit der rechten Maustaste auf den Spaltenkopf der zur erstellenden Analysewerte geklickt. Im darauffolgenden Kontextmenü wird der Eintrag „Analysewert anlegen“ gewählt und sich für eine Aggregatfunktion entschieden. Spalten, aus denen Analysewerte erstellt wurden, sind an der grünen Einfärbung erkennbar.
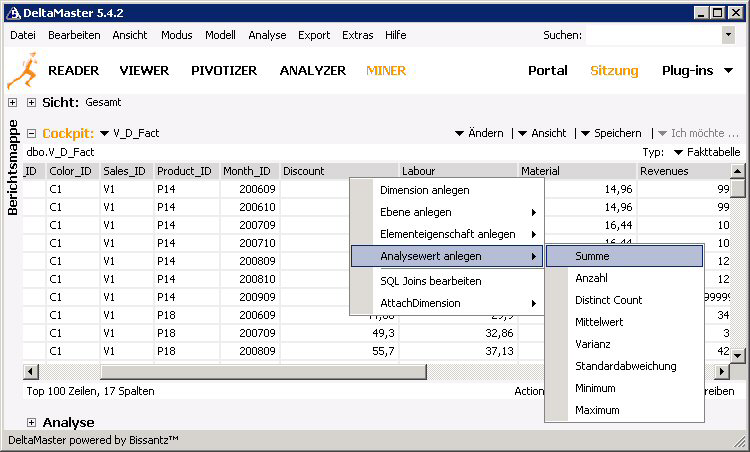
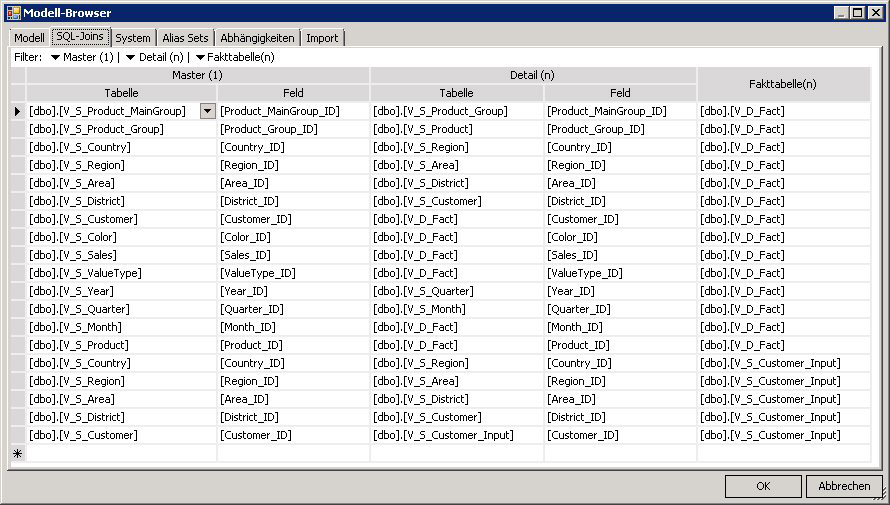
11. Um die Daten bei der Eingabe oder der Analyse auf Basis der ausgewählten Elemente der Dimensionen im Fenster „Sicht“ filtern zu können, müssen die Beziehungen zwischen den Tabellen der verschiedenen Dimensionsebenen und der Faktentabellen definiert werden. Die Definition wird im „Modell-Browser“ auf der Registerkarte „SQL-Joins“ vorgenommen.
12. Im Anschluss können Eingabeberichte zur Pflege von Stammdaten auf Basis eines SQL-Berichtes erstellt werden.
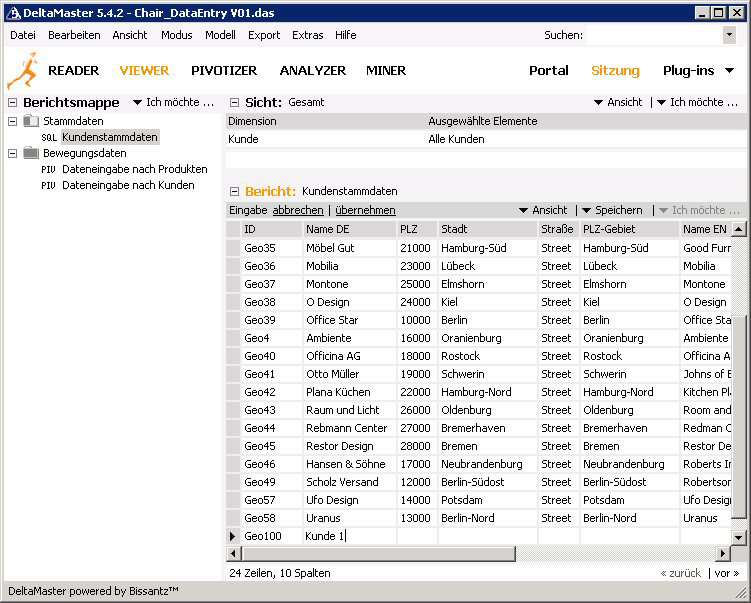
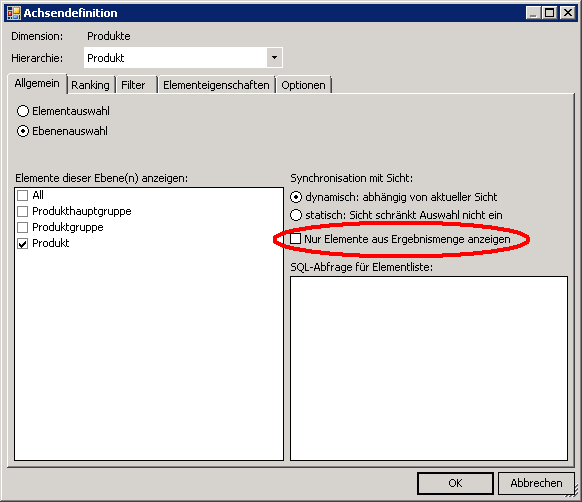
13. Zur Erfassung von Bewegungsdaten erstellt man eine Pivotabelle mit entsprechenden Spalten- und Zeilenaufrissen. In der Achsendefinition muss der Punkt „Nur Elemente aus Ergebnismenge anzeigen“ deaktiviert sein, ansonsten werden im Cockpit nur Zeilen für Elemente mit bereits erfassten Daten angezeigt.