Performance-Tests sollten selbstverständlich Umgebungen nutzen, in der nur an sehr wenigen, möglichst nur einer Stellgröße ‚gedreht’ wird und alles andere gleich bleibt. Außerdem sollten die Tests nachvollziehbar sein.
In diesem Test wurde ein kleines Starschema aufgebaut, bestehend aus den Dimensionen Zeit, Kunden und Produkten. Ausgewertet werden Umsätze. Es wurden manuell 100 Kunden und 100 Produkte generiert und davon eine 2-stufige Hierarchie erstellt: Nachname, Kunde bzw. Marke, Produkt. 100 zweigliedrige Namen entstehen recht schnell durch einen Cross Join von z.B. 10 Vornamen und 10 Nachnamen. Die zweite Hierarchiestufe bekommt man dann auch gleich mit.
Außerdem wurde als Zeitraum jeder Tag des Jahres 2009 verwendet. Es wird angenommen, dass jeder Kunde jeden Tag jedes Produkt kauft und jedes Produkt immer 10 Euro kostet. Somit entstehen 100 x 100 x 365 = 3.650.000 Datensätze.
Tests auf der relationalen Datenbank
Es wurden zwei Fakten-Tabellen erstellt, wobei eine (T_FACT_INT) Integer-IDs als Schlüssel für Kunde und Produkt verwendet und die andere (T_FACT_VARCHAR) die Namen von Kunde und Produkt (als varchar(50)).
Nach dem Füllen, kann man mit Hilfe der Funktion sp_spaceused den Speicherplatz, den die beiden Tabellen benötigen, vergleichen:
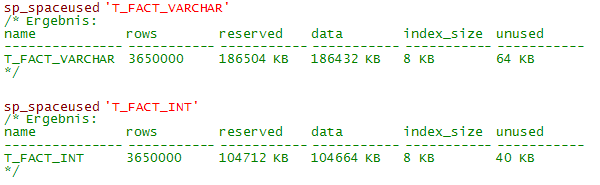
Die Tabelle mit den Zeichenketten-Schlüsseln nimmt wesentlich mehr Platz in Anspruch, als die Integer-Tabelle: 186 MB anstatt nur 105 MB. Die Frage bleibt dennoch offen, ob dieser Vorteil der geringeren Größe sich auf die Geschwindigkeit beim Verarbeiten der Tabelle auswirkt.
Getestet wurde die Dauer einer Insert-Into-Anweisung. Ich habe mich für eine Insert-Into-Anweisung entschieden, weil Insert-Anweisungen im Transform-Prozess eine wichtige Rolle spielen und entsprechend performant gestaltet werden sollten. Außerdem vermute ich genau dort einen hohen Nutzen der Tabellenverkleinerung, wo große Datenmengen bewegt werden. In Fällen, in denen viele Tabellen miteinander verknüpft werden oder komplexe Filter zum Einsatz kommen, spielen Indizes sicher eine größere Rolle.
Mit den folgenden einfachen SQL-Anweisungen wurde getestet:
![]()
Beim Vergleich der beiden Insert-Into-Statements muss darauf geachtet werden, ob die zu kopierende Tabelle bereits im Speicher zur Verfügung steht oder nicht. Natürlich ist eine Tabelle, welche bereits im Arbeitsspeicher ist, wesentlich schneller als eine, die erst noch geladen werden muss. Um die Vergleichbarkeit der Ergebnisse sicherzustellen, sollte vor jeder Ausführung der Daten- und der Proc-Speicher des SQL-Servers geleert werden. Bevor dies geschehen kann, müssen alle, im Transaktions-Protokoll befindlichen Objekte, rückgeschrieben werden. Das erledigt die Checkpoint-Anweisung:

An vielen Stellen ist es wichtig zu wissen, wie viel Arbeitsspeicher der SQL-Server belegt und davon auch nutzt. Der Task-Manager mit seinen Angaben für benutzten Speicher ist jedoch für den SQL-Server denkbar ungeeignet und sollte zu Messzwecken und Vergleichen nicht genutzt werden. Solche Werte lassen sich wesentlich genauer im ‚Systemmonitor’ analysieren. Dieser findet sich unter Systemsteuerung/Verwaltung/Leistung bzw. Zuverlässigkeits- und Leistungsüberwachung.
Zum Anzeigen der Auswirkungen der beiden dbcc-Funktionen (und auch der Auswirkungen der beiden Insert-Into-Anweisungen) empfehle ich die Überwachung folgender Leistungsindikatoren:
- SQLServer:Speicher-Manager\Serverspeicher gesamt (KB)
- SQLServer:PufferManager\Seiten gesamt
- SQLServer:PufferManager\Freie Seiten
- SQLServer:PufferManager\Datenbankseiten
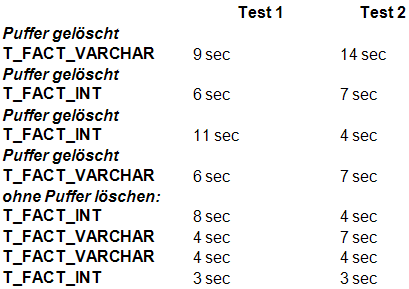
Nach jedem Ausführen eines der beiden SQL-Statements wurde die entsprechende %_BAK-Tabelle wieder gelöscht. Um auch die Unterschiede zu dokumentieren, zwischen der Situation, dass eine Tabelle bereits im Speicher vorhanden ist und der Situation, dass die Tabelle erst geladen werden muss, sind einige Messungen ohne vorheriges Löschen der Puffer. Die Pufferlöschvorgänge sind auch dokumentiert. Um mögliche Messfehler durch die Reihenfolge der Messungen zu vermeiden, wurde die Reihenfolge immer wieder geändert (erst die %_VARCHAR-Tabelle, dann die %_INT-Tabelle und danach in anderer Reihenfolge). Folgendes sind die Ergebnisse:
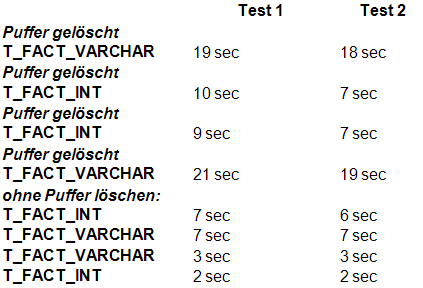
Der Test zeigt, dass die Tabellen sich ungefähr entsprechend ihrer Größe (NICHT Zeilenanzahl sondern absolute Größe) verhalten, wenn sie nicht bereits im Arbeitsspeicher vorhanden sind. Sind die Tabellen bereits geladen, ist kein Unterschied zwischen den beiden Insert-Into-Anweisungen in diesem Test ersichtlich.
Nun gibt es seit der Version 2008 in den höherstufigen Varianten des SQL-Servers eine Optimierungsmöglichkeit, die genau an der Stelle ansetzt. Es ist seit SQL-Server 2008 möglich, die Tabellen in komprimierter Form zu speichern. Dabei werden natürlich Zeichenketten wesentlich stärker gepackt als Zahlen. Ein Vergleich komprimierter Tabellen ist also durchaus interessant. Folgendermaßen wird die Komprimierung eingeschaltet:
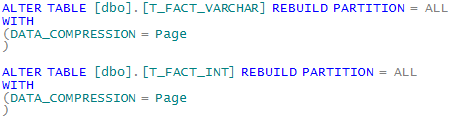
Ein Blick auf den belegten Speicherplatz der beiden Tabellen zeigt deutlich die Komprimierung:
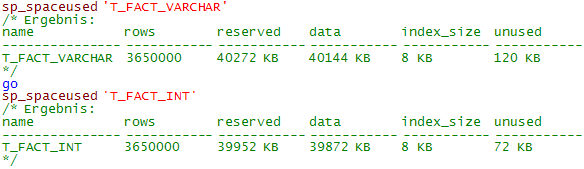
Nach der Page-Komprimierung sind beide Tabellen wesentlich kleiner als vorher und beide ungefähr gleich groß. Mit Komprimierung sah das Ergebnis wie folgt aus:
Es zeigt sich, dass die Ergebnisse stärkeren Schwankungen unterliegen. Möglicherweise wird die Dekomprimierung nicht immer auf die gleiche Art und Weise vollzogen. Fakt ist aber auch, dass alle Ergebnisse schneller sind als bei der unkomprimierten Variante und dass sich die Werte für die %_VARCHAR-Tabelle denen der %_INT-Tabelle nähern. Trotzdem ist die Tabelle mit den Integer-Schlüsseln immer noch etwas schneller, als die Tabelle mit den Varchar-Schlüsseln.
Laden der Daten in ein OLAP-Modell
Als nächstes wurden entsprechend dem Starschema eine OLAP-Datenbank mit Integer-Schlüsseln, die andere mit Varchar-Schlüsseln in der Faktentabelle erstellt. Das ‚Verarbeiten’ der OLAP-Datenbanken ist im Grunde auch ein Vorgang, in dem große Datenmengen bewegt werden, nur nicht in eine andere Tabelle, sondern in das OLAP-Modell. Das OLAP-Modell wurde einmal ohne und einmal mit eingeschalteter Tabellen-Komprimierung geladen:

Dabei zeigt sich, dass die Komprimierung an dieser Stelle kaum Vorteile bringt. Das Verarbeiten des Int-Cube ist zwar schneller, aber nicht wesentlich und nicht mehr im Verhältnis der Tabellengrößen zueinander.
MDX-Abfrage im OLAP-Modell
Letztendlich soll auch noch der Performance-Unterschied im OLAP-Modell geprüft werden. Dazu wird eine MDX-Abfrage mit einem aufwändigen Ergebnis (hohe Anzahl zurückgegebener Werte) auf beide Datenbanken ausgeführt.

Folgendes Ergebnis war dabei zu beobachten:

Erstaunlicherweise sind die Ergebnisse in beiden Datenbanken nahezu identisch. Die Wahl der Schlüssel scheint keine Bedeutung zu haben. Das kann damit zusammenhängen, dass die Daten eines OLAP-Cubes bereits im Speicher geladen sind und somit die Vorteile beim schnelleren Laden in den Speicher wegfallen.
Fazit des Tests: Auf der relationalen Seite ergaben sich im besten Falle die vermuteten Verhältnisse zwischen absoluter Tabellengröße und Geschwindigkeit. Sind die Daten bereits in Speicher geladen, verliert sich der Vorteil der Integer-Schlüssel. Es lohnt sich relational also durchaus, über das künstliche Generieren von Integer-Schlüssel nachzudenken, wenn eine große Tabelle häufig im Gesamten kopiert wird. Im multidimensionalen Umfeld waren keine Unterschiede spürbar, obwohl von Seiten Microsofts eindeutig Integer-Schlüssel empfohlen werden. Möglicherweise war die geladene Menge der Daten zu gering und es ergeben sich andere Verhältnisse, wenn die Menge der Daten den Arbeitsspeicher weit übersteigt. Dies konnte mit diesem Test noch nicht herausgefunden werden. Der Gesamtspeicher der beiden OLAP-Datenbank liegt laut SSMS (SQL-Server Management Studio) bei 11,5 MB für die VARCHAR-Datenbank und bei 10,5 MB für die INT-Datenbank. Hier wäre auch interessant, herauszufinden, warum die VARCHAR-Datenbank sogar kleiner ist, als die INT-Datenbank. Dies ist aber nicht mehr Gegenstand dieses Tests. Da würde sicher auch eine Ermittlung des Speicherbedarfs der einzelnen Datenbanke-Bestandteile mit Hilfe einer XMLA-Abfrage hilfreich sein: