Nicht nur für Hobby-Meteorologen oder Klimaforscher können Wetterdaten spannende Einblicke gewähren und Trends bzw. Zusammenhänge aufzeigen. Auch im unternehmerischen Kontext haben Wetterdaten ihre Bewandtnis. Gerade bei Unternehmen aus dem Einzelhandel oder aus der Lebensmittelbranche ist der Einfluss des Wetters auf den Umsatz nicht so leicht von der Hand zu weisen. Auch wenn dies pauschal natürlich nicht für jeden Lebensmittelhersteller gilt, gibt es doch Paradebeispiele, wie den Eishersteller, dessen Umsatz stark von den Wettereinflüssen geprägt ist. Um nun selbst untersuchen zu können, ob es zwischen dem Wetter und einzelnen Kennzahlen im eigenen Unternehmen einen Zusammenhang gibt, muss erstmal die Datengrundlage geschaffen werden. Dieser Blogbeitrag befasst sich genau mit diesem Thema. Im ersten Teil dieser Beitragsreihe wird gezeigt, wie man überhaupt an freie Wetterdaten gelangt und wie diese angebunden werden können. Im zweiten Teil wird dann auf die Modellierung sowie die schlussendliche Analyse eingegangen.
Wetterdaten, nur woher?
Neben vielen privaten und kostenpflichtigen Wetterdiensten, die sich zum Teil auch auf Spezialanforderungen beispielsweise aus der Landwirtschaft spezialisiert haben, gibt es auch freie und kostenlose Wetterdaten, auf die zugegriffen werden kann. Wetter- bzw. Klimadaten können beispielweise vom Deutschen Wetterdienst bezogen werden. Dieser stellt im Rahmen seiner Grundversorgung umfangreiche Wetter- und Klimadaten bereit, die frei genutzt werden können. Im sogenannten Climate Data Center (CDC) kann auf eine Großzahl an meteorologischen Daten aus Deutschland aber auch Europa sowie dem Rest der Welt zugegriffen werden. Unter folgendem Link ist das Climate Data Center zu finden: http://www.dwd.de/DE/leistungen/cdcftp/cdcftp.html.
Die Daten werden mittels FTP-Server bereitgestellt und können darüber abgerufen werden. Auf der Startseite des Climate Data Centers ist der direkte Link auf den FTP-Server zu finden. Alternativ ist der FTP-Server direkt unter ftp://ftp-cdc.dwd.de/pub/CDC/ zu erreichen. Auf dem FTP-Server selbst gibt es unterschiedliche Wetterdaten, die in verschiedene Verzeichnisse aufgeteilt sind.
 Abbildung 1: FTP-Server des Climate Data Centers
Abbildung 1: FTP-Server des Climate Data Centers
Neben Rasterdaten von Deutschland und Europa werden zudem weltweite und deutschlandweite Wetterstationsdaten sowie Durchschnittswetterdaten der deutschen Bundesländer bereitgestellt. In den Unterverzeichnissen kann zudem noch unterschieden werden, auf welcher zeitlichen Basis man die Daten haben will. Hier gibt es teilweise Daten auf Stundenebene, aber auch auf Tages-, Monats- und Jahresbasis. Zudem wird meist zwischen historischen und aktuellen Wetterdaten unterschieden. Die histori-schen Wetterdaten beinhalten die Daten ab Beginn der Wetteraufzeichnungen bis hin zum Ende des letzten Jahres. Die aktuellen Wetterdaten beinhalten wiederum dynamisch die letzten eineinhalb Jahre.
Auswahl der Wetterdaten
Für dieses Beispiel sollen Wetterdaten von Deutschland herangezogen werden. Zudem soll möglichst weit in die Vergangenheit geschaut werden. Für die Vergleichbarkeit der Daten im Unternehmens-Kontext ist natürlich entscheidend, dass die Daten zeitlich wie geografisch gesehen auf einen Nenner gebracht werden können. Dahingehend wären die Durchschnittswerte auf Bundeslandebene zu grob (regional averages DE). Dementsprechend sind die Daten auf Wetterstationsbasis als Datengrundlage (observations_germany) hier die bessere Wahl. Genauer noch die Klimawerte (climate) auf Tagesbasis (daily), die alle Klima-Messwerte enthalten (kl) und die gesamte Historie (historical) abbilden.
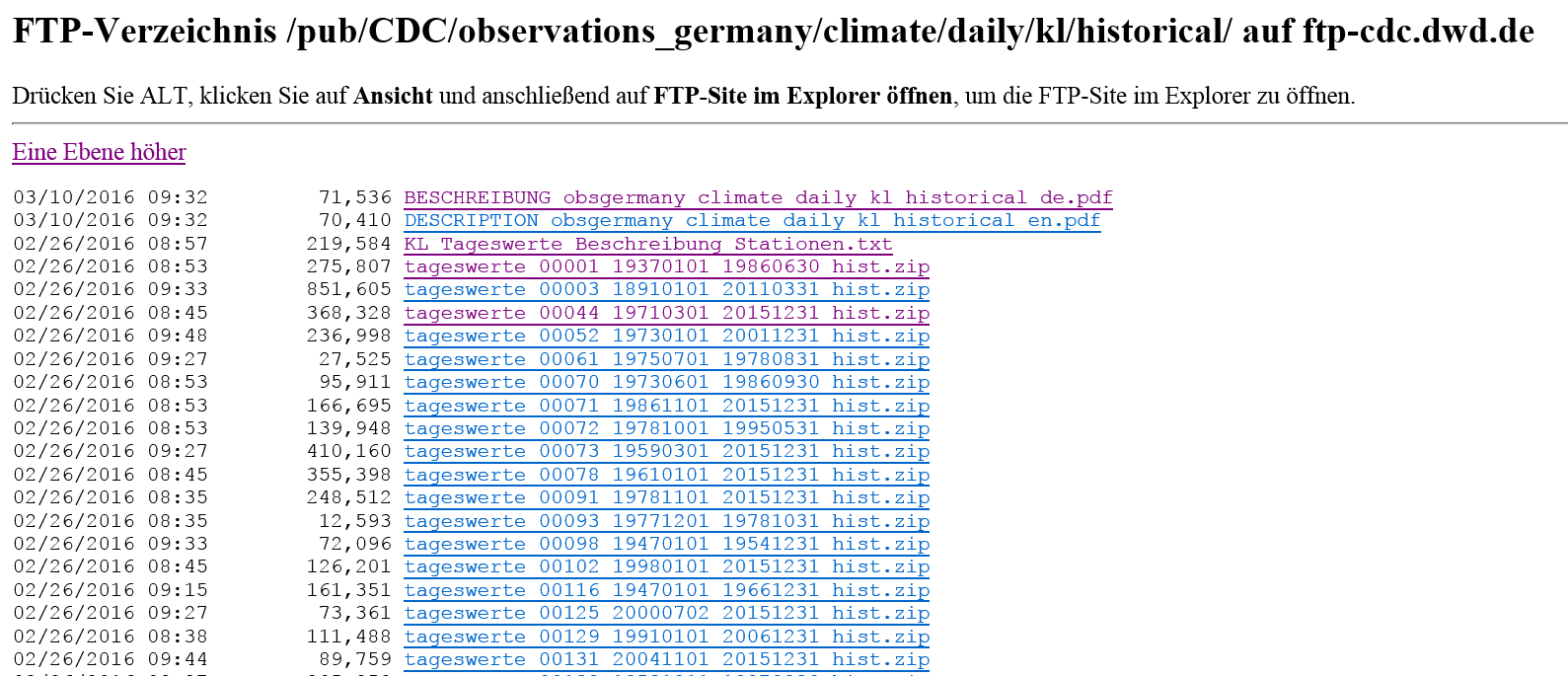
Abbildung 2: Klimawerte auf Tagesbasis
In dem spezifizierten Unterverzeichnis angekommen, wird pro Wetterstation eine ZIP-Datei zur Verfügung gestellt. Darin enthalten sind mehrere beschreibende Textdateien sowie die Daten-Textdatei (produkt_klima_Tageswerte_x_x_x) als solches. Neben den Datenpaketen in Form von ZIP-Dateien enthält das Unterverzeichnis auch eine Stammdaten-Datei zu den Wetterstationen, die unter „KL Tageswerte Beschreibung Stationen.txt“ zu finden ist. Darin enthalten ist die Stations-ID, die wiederum auch in den einzelnen Daten-Paketen vorhanden ist und Eigenschaften wie die Stationshöhe oder die Geokoordinaten beinhaltet.
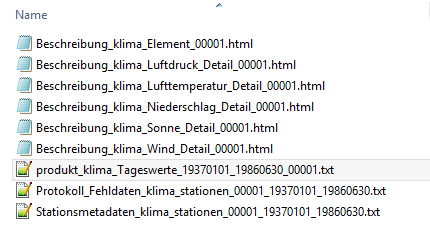
Abbildung 3: Unterverzeichnisse
Zu den mehr als 1000 Wetterstationen liegen wiederum verschiedene Messwerte zur Verfügung, unter anderem die folgenden:
- Lufttemperatur (Min/Max/Tagesmittel/Min am Erdboden)
- Dampfdruck
- Bedeckungsgrad
- Luftdruck
- Rel. Luftfeuchte
- Windgeschwindigkeit (Max/Tagesmittel)
- Niederschlagshöhe
- Sonnenscheindauer
- Schneehöhe
Mit dieser breiten Palette an Messwerten kann demnach das Wetter aus unterschiedlichen Gesichtspunkten betrachtet werden. Das bietet für die spätere Analyse der Daten eine gute Grundlage.
Anbindung der Daten
Für die Anbindung der Wetterdaten wird wie gewohnt das SQL-Server-eigene ETL-Werkzeug SSIS (SQL Server Integration Services) genutzt. Dabei bringt die Datenintegration in diesem Fall ein paar Besonderheiten mit sich. Normalerweise greifen wir in unseren Projekten auf Datenbankserver oder auf Daten aus Flatfiles oder Excel-Dateien zu. FTP-Server gehören hier definitiv zu den exotischeren Varianten. Hinzu kommt wie die Daten auf dem FTP-Server abgelegt sind. Durch die Komprimierung der Datenpakete in einem ZIP-File, müssen diese vor dem Ladeprozess in das Datawarehouse zuerst noch extrahiert werden. Da dies natürlich nicht händisch gemacht werden soll, muss das „Entpacken“ im automatischen Ladeprozess geschehen. Im Folgenden wird schrittweise beschrieben, wie das Vorgehen zur Anbindung der Wetterdaten ist.
Daten vom FTP-Server abfragen
Der erste Schritt auf dem Weg zu einer erfolgreichen Anbindung der Daten ist eine Verbindung zum FTP-Server aufzubauen. Hierfür wird eine neue Verbindung im SSIS über den Verbindungs-Manager erstellt. Über „Neue Verbindung“ gelangt man in eine Auswahl an unterschiedlichen Verbindungstypen. Darunter auch der gewünschte Verbindungstyp „FTP“.
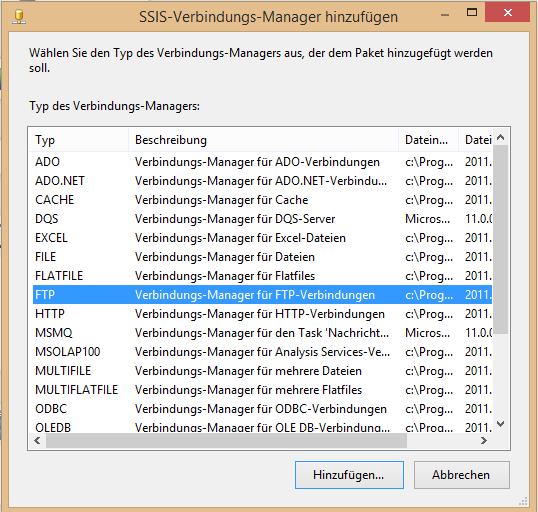
Abbildung 4: Verbindungs-Manager
Über den markierten Verbindungstyp „FTP“ und der Betätigung der „Hinzufügen“-Taste gelangt man in den FTP-Verbindungs-Manager-Editor. Hier sind einige Einstellungen notwendig, um sich mit dem FTP-Server verbinden zu können. Unter „Servername“ muss grundsätzlich die Serveradresse angegeben werden. Diese lautet in diesem Fall „ftp-cdc.dwd.de“. Mit der aus dem Browser kopierten Adresse gelingt es nicht. Es muss die reine Adresse ohne „ftp://“- Präfix und Verzeichnissen sein. Die Kommunikation mit dem FTP-Server läuft per Grundeinstellung über den Port 21. Dies sollte dementsprechend in den meisten Fällen auch nicht zu ändern sein. Da auf einen frei zugänglichen, ohne Anmeldeinformationen auskommenden, FTP-Server zugegriffen werden soll, sind im Bereich Anmeldeinformationen keine Eintragungen nötig. Der Eintrag „anonymus“ bei Benutzername kann stehen gelassen oder herausgelöscht werden. Dieser gibt nur an, dass man sich anonym mit dem Server verbindet. Eine wichtige Einstellungsmöglichkeit unter „Optionen“ ist, den Passivmodus zu verwenden. Wenn der Haken hier nicht gesetzt ist, wird dagegen der Aktivmodus genutzt. Beim aktiven Modus wird die Datenverbindung vom Server initiiert. Das heißt, der Server baut die Verbindung zum Client auf und nicht andersherum. Jedoch greift hier dann in vielen Fällen die Firewall und unterbindet diesen Verbindungsversuch. Beim Aktivieren des Passivmodus wird die Verbindungsanfrage vom Client aus initiiert. Damit entsteht keine eingehende Verbindung mehr auf dem Client und das Client-seitige Firewall-Problem wird damit umgangen. Dahingehend ist es sinnvoll hier den passiven Modus zu aktivieren.
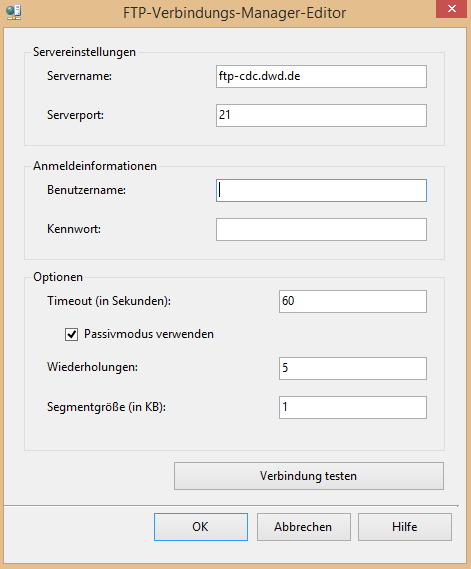
Abbildung 5: FTP-Verbindungs-Manager-Editor
Nun kann über die Taste „Verbindung testen“ überprüft werden, ob die Einstellungen richtig getätigt worden sind. Wichtig ist hierbei zu erwähnen, dass es für diesen Test nebensächlich ist, ob der Passivmodus aktiviert oder deaktiviert ist, da mit dem Test nur eine ausgehende Anfrage vom Client an den Server getätigt wird, ob der Server überhaupt erreichbar ist. Die Firewall-Problematik taucht erst auf, wenn wirklich Daten übertragen werden sollen. Nachdem nun die Verbindung erfolgreich getestet worden ist, kann nun mit der Datenübertragung der FTP-Server-Daten begonnen werden. Hierfür ist der FTP-Task aus der SSIS-Toolbox vorgesehen.
Abbildung 6: FTP-Task
Nachdem der Task in die Ablaufsteuerung gezogen wurde, öffnet man per Doppelklick den Editor. Auf dem Reiter „Allgemein“ ist zwingend nur die gerade angelegte Verbindung unter „FtpConnection“ auszuwählen. Unter dem Reiter „Dateiübertragung“ muss bei Lokale Parameter -> LocalPath der Pfad angeben werden, an dem die Dateien vom FTP-Server abgelegt werden sollen. Hier kann einfach über das Auswahlfeld eine neue Verbindung anlegt werden. Die Einstellung „OverwirteFileAtDest“ sollte auf „True“ stehen, um ein Ersetzen der Altdaten durch neue zu ermöglichen. Bei „RemotePath“ kommt nun der Verzeichnispfad ins Spiel. Hier muss der Verzeichnispfad eingetragen werden, der hinter dem Servernamen im Web-Browser steht und auf den gewünschten Ordner zeigt. In diesem Fall ist es der folgende Pfad „/pub/CDC/observations_germany/climate/daily/kl/historical/“. Um aus diesem Ordner jedoch nur die Wetterdaten enthaltenden ZIP-Dateien zu laden, muss beim Pfad mit Wildcards gearbeitet werden. Damit sieht der RemotePath schlussendlich folgendermaßen aus: „/pub/CDC/observations_germany/climate/daily/kl/historical/*.zip“.
Unter Vorgang -> Operationen muss nun noch bestimmt werden, was mit den Dateien geschehen soll, die über den RemotePath definiert wurden. In diesem Fall sollen die Dateien empfangen werden. Die Option „IsTransferAscii“ ist hier noch ein wichtiges Stellrad. Sollten Text-Dateien übertragen werden, ist die Einstellung auf „True“ in diesem Fall richtig, da diese meist ASCII-Textkodiert sind. Da die Textdatei-en komprimiert in einer ZIP-Datei abgerufen werden, ist die ZIP-Datei selber nicht mehr ASCII-Textkodiert und muss dementsprechend im binary-Modus übertragen werden. Deshalb muss die Option auf „False“ gestellt werden. Schlussendlich sehen die Einstellungen wie folgt aus:
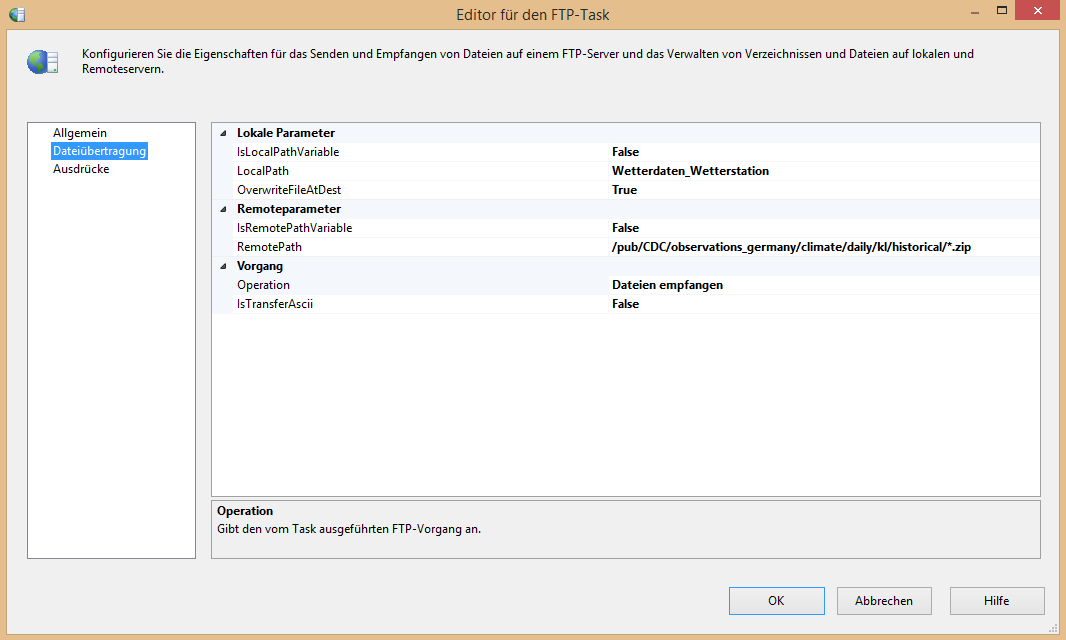
Abbildung 7: FTP-Task Editor
Wird der FTP-Task nun ausgeführt, überträgt er sämtliche ZIP-Dateien von dem angegebenen FTP-Serverpfad auf den Zielpfad (LocalPath). Damit wurde der FTP-Server erfolgreich angebunden und die Daten geladen.
ZIP-Dateien automatisiert entpacken
Nachdem die ZIP-Dateien an dem gewünschten Pfad per FTP-Routine abgelegt wurden, müssen die Dateien noch entpackt werden, um an die Textdatei zu gelangen, die unsere Bewegungsdaten beinhaltet. Hierfür wird zuerst einmal ein Datenkompressionsprogramm auf dem Rechner benötigt, welches im SSIS-Paket ausgeführt werden soll. In diesem Beispiel wird hierfür „7-Zip“ genutzt. Wenn die Voraussetzungen geschaffen sind, kann der automatisierte Entpackungsprozess aufgebaut werden. Hierfür ist der Task „Prozess ausführen“ zu nutzen.
Abbildung 8: Task „Prozess ausführen“
Nachdem der Task per Drag-and-drop in die Ablaufsteuerung gezogen wurde, gelangt man wieder per Doppelklick in den Editor. Im Reiter „Verarbeiten“ müssen nun ein paar Einstellungen vorgenommen werden. Bei „Executable“ muss die exe-Datei hinterlegt werden, mit der der Prozess ausgeführt werden soll. Hier muss dementsprechend der Pfad des Datenkompressionsprogramms gewählt werden. In diesem Fall ist der Pfad zur 7-Zip.exe folgender: „C:\Program Files\7-Zip\7z.exe“. Mit dem Task können nicht nur verschiedene Prozesse ausgeführt, sondern den Prozessen können gleichzeitig auch gewisse Parameter/Argumente mitgegeben werden, die bei der Ausführung berücksichtigt werden sollen. In diesem Fall soll aus den ZIP-Dateien, die in einem vorgegebenen Ordner liegen, bestimmte Dateien extrahiert und diese in einem definierten Ordner ablegt werden. Der Extract-Befehl wird über ein „x“ angezeigt. Darauf folgt der Pfad der zu extrahierenden ZIP-Datei. Mit dem Befehl „-o“ und einem darauffolgenden Pfad legt man den Zielpfad fest. Der Befehl „-o“ kann noch weiter spezifiziert werden. Mit einem vorangesetzten a („-ao“) kann man beispielsweise den „Overwrite Mode“ aktivieren und spezifisch mit einer Auswahl an weiteren Buchstaben angeben, wie die Daten, die erneut in den Zielpfad extrahiert werden, behandelt werden sollen. In diesem Fall wäre ein Überschreiben der Alt-Dateien sinnvoll, jedoch hatte der „Overwrite Mode“ im Test keine Wirkung gezeigt. Das Argument sieht zusammengefasst dann folgendermaßen aus: x „Quellpfad“ -o„Zielpfad“. Mit diesem Argument können die ZIP-Dateien schon erfolgreich extrahiert werden. Jedoch sollen nur bestimmte Dateien aus dem ZIP-Ordner genutzt werden, denn wie bereits veranschaulicht, enthält nur eine der neun Dateien im Ordner die Bewegungsdaten. Deshalb muss ein weiterer Parameter genutzt werden, der mit einem Leerzeichen separiert direkt hinter den Zielpfad geschrieben wird. Mit diesem wird der Dateiname angegeben. Dabei kann mit Wildcards gearbeitet werden, um später genau die gewünschte Datei zu erhalten. In diesem Fall beginnt die Datei immer mit „produkt“ und ist zudem eine txt-Datei. Dementsprechend sieht der letzter Parameter mit Wildcard dann wie folgt aus: „produkt*.txt“. Damit funktioniert die Extraktion einer Zip-Datei schon ohne weitere Anpassung.
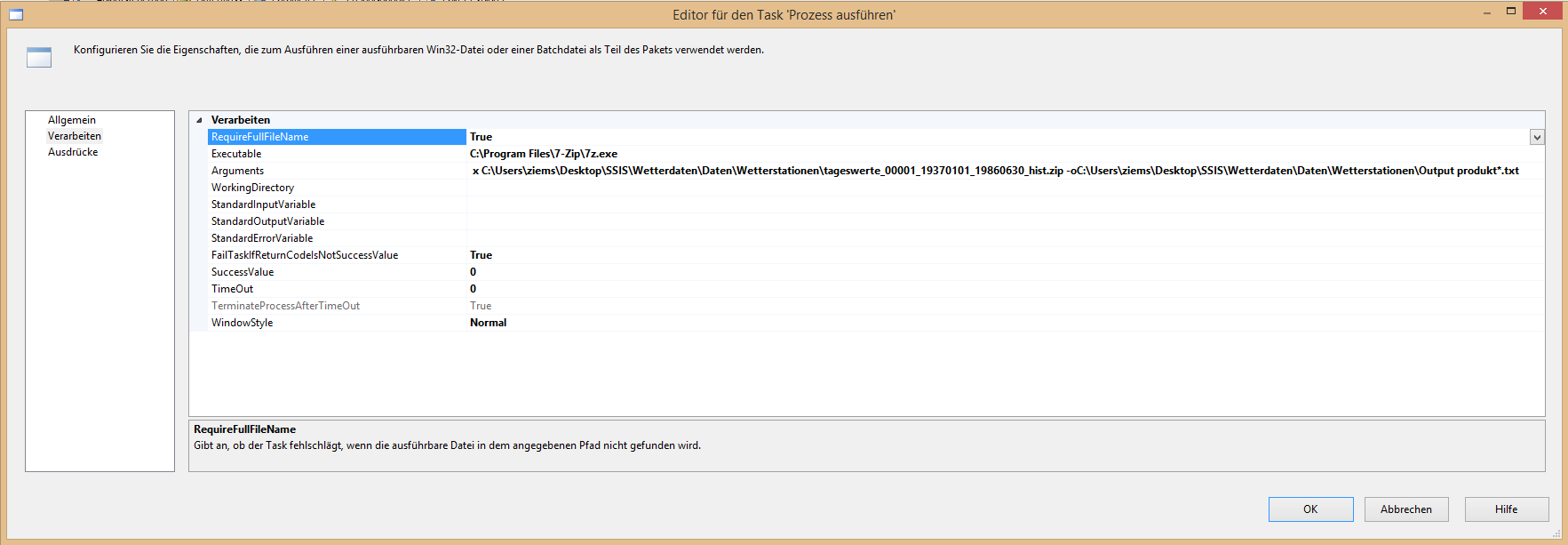
Abbildung 9: Editor für den Task „Prozess ausführen“
Jedoch muss dieser Prozess für jede ZIP-Datei durchführt werden, die vom FTP-Server geladen wurde. Daher muss der Prozess über einen Foreach-Schleifencontainer dynamisch gestaltet werden. Hierfür muss eine Variable für den Quellpfad einer ZIP-Datei und der Zielpfad des Zielordners angelegt werden. (Der Zielpfad müsste jedoch nicht zwingend als Variable angegeben werden, da er statisch bleibt).

Abbildung 10: Variablen
Nun müssen diese Variablen in den „Prozess ausführen“-Task als Argument-Befehlskette aufgenommen werden, um diese dann durch die Schleife iterieren lassen zu können. Dafür wird auf dem Reiter Aus-drücke unter „Expressions“ für die Einstellung „Arguments“ die zusammengesetzte Befehlskette angegeben. Dies sollte dann folgendermaßen aussehen:

Abbildung 11: Expressions
Anschließend müssen die Einstellungen des ForEach-Schleifencontainers noch vorgenommen werden. Als erstes wird die Enumeratorkonfiguration auf dem Reiter „Sammlung“ eingestellt. Damit wird angegeben, durch welche Dateien welchen Ordners die Schleife iterieren soll. Als Ordner wird der Quellpfadordner und als Dateien, per Wildcard, alle ZIP-Dateien („*.zip“) angegeben. Da der gesamte Pfad der ZIP-Dateien in der Variable „VarZipFilePath“ verwendet wird, muss bei „Dateinamen abrufen“ auf Vollqualifiziert gestellt werden.
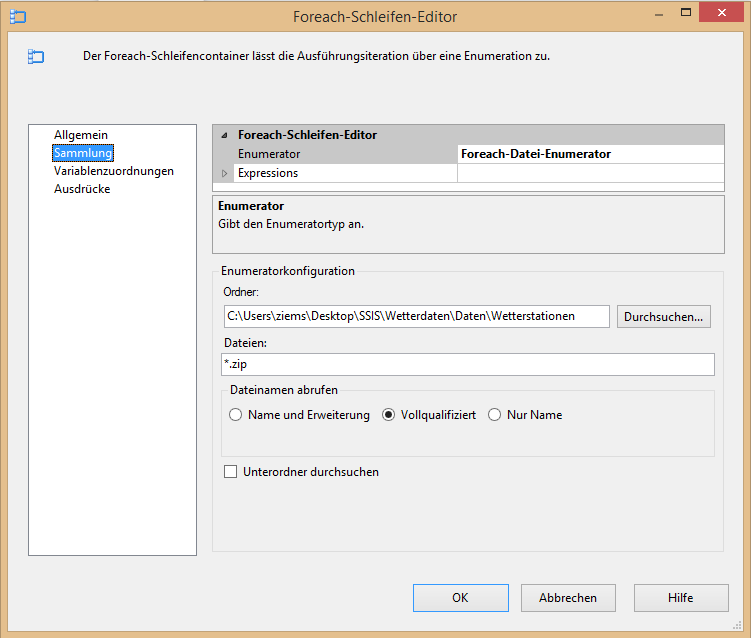
Abbildung 12: Foreach-Schleifen-Editor
Mit dieser Einstellung iteriert der Prozess nun durch alle ZIP-Dateien und übergibt den Vollqualifizierten-Pfad des Iterationsobjektes. Diesen Wert soll er an die Variable „VarZipFilePath“ übergeben. Das wird erreicht, indem im Reiter „Variablenzuordnungen“ diese Variable einfach aus dem Drop-Down-Menü auswählt wird. Damit ist auch der Schleifen-Container erfolgreich konfiguriert und die gewünschte Datei aus den ZIP-Ordnern wird erwartungsgemäß in den Zielpfad extrahiert.
Laden der extrahierten Daten in das Datawarehouse
Nachdem nun die ZIP-Dateien vom FTP-Server geladen werden und die gewünschten Dateien aus diesen extrahiert wurden, müssen diese noch in das Datawarehouse geladen werden. Für diesen Prozess ist ebenso ein Foreach-Schleifencontainer nötig, der die extrahierten Dateien nacheinander in die Datenbank lädt. Auch hier werden wieder Variablen erstellt, um den Schleifen-Prozess abzubilden. Die Variable „BasePath“ soll dabei den Pfad des Ordners mit den extrahierten Dateien enthalten und die Variable „Datei“ den Dateinamen einer beliebigen, aber vorhandenen extrahierten Datei.

Abbildung 13: Variablen
Nun kann wieder der Schleifencontainer konfiguriert werden, indem unter „Sammlung“ die Enumeratorkonfiguration vorgenommen wird. Bei „Ordner“ wird der gleiche Pfad angeben, wie der, der bereits angelegten „BasePath“-Variable. Bei Dateien muss der Ausdruck „*.txt“ angegeben werden. Diesmal muss bei „Dateinamen abrufen“ jedoch die Eigenschaft „Name und Erweiterung“ ausgewählt werden, da lediglich die Variable „Datei“ durchiteriert werden soll.
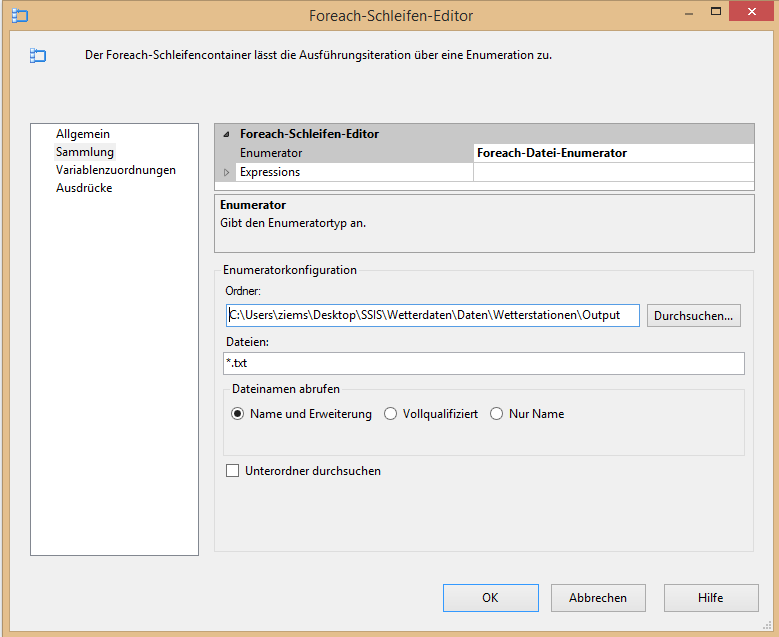
Abbildung 14: Foreach-Schleifen-Editor
Deswegen wird nun bei „Variablenzuordnungen“ auch nur die Variable „Datei“ eingetragen. Damit sind die Einstellungen des Schleifen-Containers abgeschlossen. Der zu iterierende Task ist diesmal der Datenflusstask. In diesem wird der Datenfluss von den Textdateien hin zur Bewegungstabelle in der Datenbank abgebildet. Hierzu muss im Verbindungsmanager die Verbindung zur Datenbank sowie zur Text-Datei ergänzt werden. Für die Verbindung zur Datenbank wird die OLE-DB Verbindung genutzt. Hier werden der Servername sowie die gewünschte Datenbank eingetragen. Die Verbindung zur Textdatei wird mit einer FlatFile-Verbindung erstellt, bei der eine beliebige Textdatei aus dem Ordner mit den extrahierten Dateien auswählt wird, um die Verbindung zu konfigurieren. Da jedoch alle txt-Dateien aus dem Ordner geladen werden sollen, muss die Flatfile-Verbindung für die Iteration dynamisch gestaltet werden. Daher muss in den Eigenschaften der Verbindung (Rechtsklick auf die Verbindung -> Eigenschaften) unter „Expressions“ der Verbindungspfad dynamisiert werden. Hierzu muss aus dem Drop-Down-Menü bei Eigenschaften „ConnectionsString“ ausgewählt und als Ausdruck der Pfad über die vorher angelegten Variablen angegeben werden.
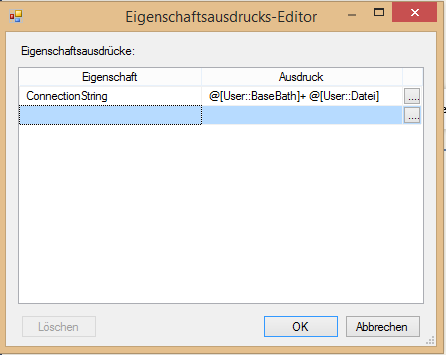
Abbildung 15: Eigenschaftsausdrucks-Editor
Durch die Iteration im Schleifen-Container über die Variable „Datei“ wird die Verbindung zu jeder txt-Datei im Ordner hergestellt. Im Datenflusstask selber muss nun noch der Datenfluss von der Quelle ins Ziel angeben werden. Hierzu wird als Quelle die „Flatfilequelle“ und als Ziel das „OLE DB-Ziel“ benötigt. In der Quelle wird als Verbindung die zuvor dynamisierte Flat-File-Verbindung ausgewählt. Anschließend wird die Quelle mit dem Ziel verbunden. Im Ziel wird ebenfalls die zuvor angelegte OLE-DB Verbindung ausgewählt. Unter „Name der Tabelle oder Sicht“ über den „Neu“-Schalter wird eine neue Tabelle in der Datenbank generiert. Über den Reiter „Zuordnungen“ wird überprüft, ob die Zuordnung der Eingabe-spalten zu den Zielspalten korrekt ist. Damit ist der grundsätzliche ETL-Prozess abgeschlossen und die Daten können in das Datawarehouse geladen werden.
Zusammenfassung und Ausblick
Damit der ETL-Prozess auch als Routine genutzt werden kann, sind ergänzend noch zwei Tasks in den schlussendlich folgendermaßen aussehenden Prozess einzubauen.
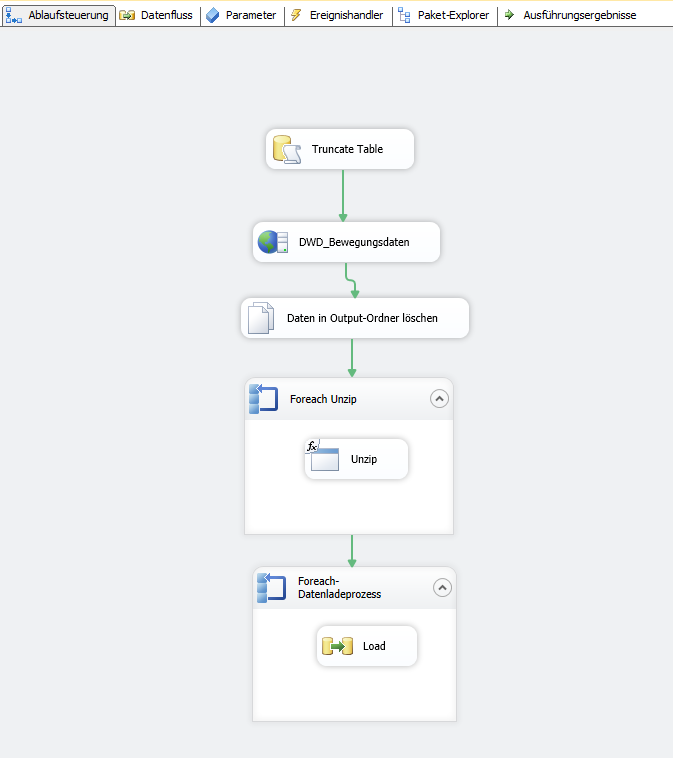
Abbildung 16: Ablaufsteuerung
Durch den oberen „SQL ausführen“-Task kann in der Routine die Importtabelle der Wetterdaten vor dem nochmaligen Laden zuvor geleert werden. Dies gehört auch zur gängigen Praxis in Projekten. Der dritte Task „Daten in Output-Ordner löschen“ vom Typ „Dateisystem“ ist nur deswegen nötig, da die „Overwrite-Funktion“ im „Prozess ausführen“-Task im Test nicht funktionierte. Daher wird die „Overwrite-Funktion“ mit Hilfe des „Daten in Output-Ordner löschen“–Task nachgestellt, indem der Output-Ordner vor der nächsten Befüllung geleert wird.
Hierzu muss zuerst noch eine neue Verbindung des Typen „Dateiverbindung“ mit dem Pfad zum „Output“-Ordner angelegt werden. Im Task „Dateisystem“ muss im Reiter Allgemein unter SourceConnection die gerade angelegte Verbindung ausgewählt werden. Unter „Vorgang“ kann dann eingestellt werden, was mit diesem Ordner oder dessen Inhalt passieren soll. In diesem Fall wäre die Option „Verzeichnisinhalt löschen“ die richtige. Damit ist der ETL-Prozess für den täglichen Routinelauf gewappnet ohne dass die gleichen Daten mehrfach geladen werden. Die bereits angesprochene Stammtabelle „KL Tageswerte Beschreibung Stationen.txt“, die sich ebenfalls auf dem FTP-Server im gleichen Verzeichnis verbirgt, kann ebenfalls mit dem beschriebenen Verfahren geladen werden. Jedoch ist dies hier deutlich einfacher zu handhaben, da die Datei nicht aus einer ZIP-Datei extrahiert werden muss und es keiner Schleifenlogik bedarf, wodurch der Ladeprozess folgendermaßen aussieht:
Abbildung 17: Ladeprozess
Das Anlegen der FlatFile-Verbindung über das Format „feste Breite“ hat sich bei der Txt-Datei als etwas schwierig herausgestellt. Deshalb ist es zu empfehlen die Txt-Datei erst in Excel zu importieren, da sich hier der Vorgang als deutlich leichter herausgestellt hat. Anschließend kann wie gewohnt die Excel-Datei über das SSIS-Paket angebunden werden.
Nachdem nun im ersten Teil auf den reinen Importprozess eingegangen wurde und die Daten erfolg-reich in die Datenbank geladen wurden, wird im zweiten Teil das Augenmerk auf die Modellierung und die Analyse gelegt. Hier werden noch einige Kniffe zu sehen sein, um aus den Daten möglichst viel Informationsgehalt herausholen zu können.
