Im vorherigen Blogbeitrag zum Thema “Volltextsuche” (vgl. Blogbeitrag Volltextsuche Teil I) haben wir bereits alle notwendigen Komponenten zur Einrichtung der Datenbank kennengelernt. Außerdem konnten wir erste Erfahrungen mit einfachen Suchvorgängen sammeln.
In dieser Ausgabe lernen wir weitere Volltextprädikate und Funktionen kennen.
Volltextprädikate
CONTAINS
Das Prädikat CONTAINS haben wir schon behandelt. Es wird für genaue oder ungenaue Übereinstimmungen eingesetzt. Dabei können auch boolesche Operatoren benutzt werden:
SELECT d.* FROM dbo.T_Documents d WHERE Contains(d.Document, 'spannweiten OR dimensionsgruppen')
Mögliche Erweiterungen des obigen Statements sind:
- Präfix-Angabe: Suche nach Wörtern oder Ausdrücken, die mit dem angegebenen Text beginnen. Es ist darauf zu achten, dass der Text samt Sternchen in doppelten Anführungszeichen steht. Sonst wird das Sternchen bei der Suche als Zeichen behandelt.
SELECT d.* FROM dbo.T_Documents d WHERE Contains(d.Document, '"dimensions*"')
Wenn es aber um einen Ausdruck geht, wird jedes im Ausdruck vorhandene Wort als separates Präfix behandelt:
SELECT d.* FROM dbo.T_Documents d WHERE Contains(d.Document, '"gleiten aggregat*"')
Das obige SQL-Skript findet also unter anderem den Ausdruck “gleitende Aggregation”.
- Sprachabhängige Wortstammerkennung (FORMSOF): Es wird in Verbindung mit dem Parameter INFLECTIONAL benutzt. Dabei wird der übergebene Suchbegriff auf die Grundform zurückgeführt, da intern nur die Grundformen von Wörtern gespeichert werden (also z. B. “lesen” für “Leser” oder “gelesen”)
SELECT d.* FROM dbo.T_Documents d WHERE Contains(d.Document, 'FORMSOF(INFLECTIONAL, lesen)')
- NEAR-Term: Wie der AND-Operator müssen beide Suchbegriffe gefunden werden.
SELECT d.* FROM dbo.T_Documents d WHERE CONTAINS(d.document, 'skala NEAR grafik')
- WEIGHT: Dieser Parameter hat zwar keine Auswirkung auf die Ergebnisse mit CONTAINS, verändert aber den Rang in CONTAINSTABLE-Abfragen. Deshalb zeigen wir den Einsatz weiter unten auf.
FREETEXT
Wie das Prädikat CONTAINS liefert FREETEXT den Wert TRUE oder FALSE zurück. Es wird in der WHERE-Klausel oder der HAVING-Klausel einer SELECT-Anweisung angegeben und kann mit Transact-SQL-Prädikaten wie z. B. LIKE kombiniert werden. Es ist aber nicht so genau wie CONTAINS, denn es weist jedem Suchbegriff eine Gewichtung zu, ohne nach dem genauen Wortlaut zu suchen. Eingegeben werden kann ein beliebiger Text aus Wörtern, Ausdrücken und Sätzen.
Im Gegensatz zu CONTAINS, in der AND oder OR Schlüsselwörter sind, werden sie bei FREETEXT als Stoppwörter interpretiert und verworfen. Dieses Verhalten wird von SQL-Server automatisch eingesetzt damit der Volltextindex nicht unnötig aufgebläht wird.
Das testen wir doch gleich:
SELECT d.* FROM dbo.T_Documents d WHERE FREETEXT(d.Document, 'and or to the und oder zu in der die das')
Und tatsächlich, es werden keine Datensätze zurückgegeben.
Obwohl Stoppwörter vom Volltextindex ignoriert werden, wird ihre Position bei der Suche berücksichtigt, sodass die Positionen der anderen Wörter unverändert bleiben.
Im folgenden Beispiel werden die Stoppwörter ignoriert und der Rest des Ausdrucks führt zu einem Ergebnis. Bei dem Suchbegriff oder Ausdruck werden die Wörtertrennung und die Wortstammerkennung ausgeführt sowie der Thesaurus angewendet.
SELECT d.* FROM dbo.T_Documents d WHERE FREETEXT(d.Document, 'Die Tabelle lässt sich anhand der Skala sortieren')
Volltextfunktionen
Auf die Funktionen wird in der FROM-Klausel einer SELECT-Anweisung verwiesen. Sie liefern eine Tabelle mit null oder mehreren Datensätzen zurück, die die Volltextabfrage erfüllen. Verwendet man diese Funktionen in einer Abfrage, liefern sie einen Relevanzrangfolgenwert (RANK) und einen Volltextschlüssel für jede Zeile zurück. Je höher der Rangwert in einer Zeile ist, desto relevanter ist die Zeile für die betreffende Volltextabfrage. Die Rank-Spalte liefert also für jede Zeile einen Wert, der angibt, wie gut eine Zeile mit den Suchkriterien übereinstimmt.
CONTAINSTABLE
Im folgenden SQL-Skript werden unsere PDF-Dokumente nach genauer oder ungenauer Übereinstimmung untersucht und nach der Rank-Spalte absteigend sortiert:
SELECT d.Document_Name, KEY_TBL.RANK FROM dbo.T_Documents AS d INNER JOIN CONTAINSTABLE ( dbo.T_Documents, DOCUMENT, 'skala or grafik or sparklines' ) AS KEY_TBL ON d.Document_No = KEY_TBL.[KEY] ORDER BY KEY_TBL.RANK DESC
Das Suchergebnis liefert folgende Zeilen:
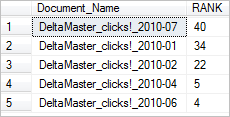 Abb. 1: CONTAINSTABLE
Abb. 1: CONTAINSTABLE
Wenn wir die PDF-Dokumente genau untersuchen, finden wir in den DeltaMaster_clicks!_2010_07 15 Treffer bei dem Wort “Skala”, 3 Treffer bei “Grafik” und 4 Treffer bei “Sparklines”, in den DeltaMaster_clicks!_2010-01 lediglich 1 Treffer bei “Skala”, 9 Treffer bei “Grafik” und 2 Treffer bei “Sparklines”. Alle Suchwörter wurden in den beiden Dateien gefunden, aber die Datei mit höherer Trefferzahl hat den höchsten Rang.
Wie oben schon erwähnt, kann das Argument WEIGHT Einfluss auf die Rangfolge der Suchergebnisse nehmen. Dabei werden die Wörter oder Ausdrücke für die Suche mit einem Gewichtungswert von 0,0 bis 1,0 versehen.
Für die nächste Suche bewerten wir das Wort “Sparklines” höher ein:
SELECT d.Document_Name, KEY_TBL.RANK FROM dbo.T_Documents AS d INNER JOIN CONTAINSTABLE ( dbo.T_Documents, DOCUMENT, 'ISABOUT (skala weight (.2), grafik weight (.3), sparklines weight (.8) )' ) AS KEY_TBL ON d.Document_No = KEY_TBL.[KEY] ORDER BY KEY_TBL.RANK DESC
Und prompt ändert sich auch das Ergebnis:
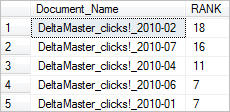
Abb. 2: CONSTAINABLE mit ‚WEIGHT‘
In dem erstpositionierten PDF-Dokument gibt es mehr Treffer bei “Sparklines” als bei unserer Parade-Datei “…_2010_07″, die sich nun mit dem zweithöchsten Rang zufriedengeben muss.
FREETEXTTABLE
Das folgende Beispiel veranschaulicht den Umgang mit dieser Funktion:
SELECT d.Document_Name, KEY_TBL.RANK FROM dbo.T_Documents AS d INNER JOIN FREETEXTTABLE ( dbo.T_Documents, DOCUMENT, 'skala grafik sparklines' ) AS KEY_TBL ON d.Document_No = KEY_TBL.[KEY] ORDER BY KEY_TBL.RANK DESC
Das Ergebnis dieser Abfrage lautet:
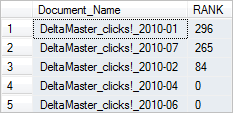 Abb. 3: FREETEXTTABLE
Abb. 3: FREETEXTTABLE
Die PDF-Dateien wurden nach Ihrem Rangwert absteigend sortiert. Dieser wird für jede Zeile berechnet und kann als Ordnungskriterium verwendet werden. Die Dokumente mit höchster Relevanz werden nach oben “gespült”. In unserem Beispiel finden wir tatsächlich alle unserer Suchbegriffe in den beiden ersten Dokumenten. Während die restlichen PDF-Dateien nur einige der drei Suchbegriffe beinhalten.
Die Rangwerte geben lediglich eine relative Relevanzreihenfolge der Zeilen an. Die tatsächlichen Werte sind nicht von Bedeutung und unterscheiden sich meist bei jeder Ausführung der Abfrage.
Bei beiden Funktionen kann das Argument “top_n_by_rank” eingesetzt werden. Es steigert die Abfrageleistung, indem nur die relevantesten Treffer abgerufen werden.
Es gibt die “Top-Höchsten” Treffer in absteigender Reihenfolge zurück.
In dem obigen Beispiel erweitern wir das Statement um ein weiteres Argument nach dem Suchbegriff (die Zahl 3 steht für Top 3):
SELECT d.Document_Name, KEY_TBL.RANK FROM dbo.T_Documents AS d INNER JOIN FREETEXTTABLE ( dbo.T_Documents, DOCUMENT, 'skala grafik sparklines', 3 ) AS KEY_TBL ON d.Document_No = KEY_TBL.[KEY] ORDER BY KEY_TBL.RANK DESC
Das Ergebnis:
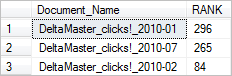
Abb. 4: FREETEXTTABLE mit Top-3 Treffern
Grundlegendes zu Stoppwörtern und –listen sowie zur Thesaurus-Konfiguration werden wir in einem nächsten Blogbeitrag erläutern.
