Sprichworte und Floskeln rund um das Thema Zeit existieren zuhauf: Zeit ist Geld. Zeit ist ein knappes Gut – das wissen nicht nur gestresste Manager. Zeit ist kostbar. Zeit soll man sich nehmen. Zeit vergeht…
Die Betrachtung der Dinge im Laufe der Zeit ist entscheidend. Vor allem in Ihrem BI-System. Und wenn, dann aber bitte richtig – erfahren Sie mit diesem Blogbeitrag wie.
Problem erkannt, Gefahr gebannt? Leider nein…
Die Relevanz des Merkmals Zeit für den BI-Anwender in Management und Controlling ist unbestritten: Zeitreihen, Trendberechnungen, Kumulation und Periodenabweichung sind essentielle Bestandteile von BI-Lösungen. Doch die Details und Untiefen in puncto Datenmodellierung werden allzu oft unterschätzt. Konzeptionelle Fehler fallen zu Anfang häufig gar nicht auf, stellen alle Beteiligten aus Anwendung und Technik jedoch mitunter später vor größte Schwierigkeiten.

Die Sichtung hunderter Implementierungen von Zeitberechnungen (z.B. Vorjahresabweichung oder Year-to-Date) auf unterschiedlichsten Technologieplattformen zeigt vor allem zwei Kardinalfehler:
- Die Implementierung innerhalb der Kennzahlendimension führt zu einer kreuzproduktartigen Multiplikation der eigentlichen Measures. Folge: Der Pflegeaufwand steigt, die Übersichtlichkeit geht verloren, die Akzeptanz leidet.
- Die Modellierung mehrerer paralleler Hierarchiebäume innerhalb der Zeitdimension unter Verwendung von Rules und/oder Links/Verweisen etc. führt die üblicherweise ebenenorientierte Logik der meisten Frontendfunktionen und MDX-Befehle ad absurdum, da nun die Elemente derselben Ebene keine echte Chronologie darstellen und die gemeinsame Semantik verloren geht: Monatsreihen vermischen dann beispielsweise die isolierten und kumulierten Periodenwerte oder gar zusätzlich absolute und/oder relative Abweichungen.
Der richtige Weg
Modellierung genau einer Zeitdimension
Eine bereits jahrelang beharrlich geführte Grundsatzdiskussion, geradezu einen Glaubenskrieg, innerhalb der OLAP-Gemeinde stellt die Entscheidung über die Anzahl der erforderlichen Zeitdimensionen dar. Wen diese Feststellung verwundert, der denke über folgende Argumentation nach: Die Struktur der Tage innerhalb der Monate sowie die Struktur der Wochen, Monate, Quartale, Tertiale und Halbjahre innerhalb der Jahre ist identisch und wiederholt sich somit innerhalb einer gemeinsamen Dimension permanent. Nach den Grundsätzen der dimensionalen Modellierung sind Verschachtelungen zu vermeiden, so dass eine Trennung z.B. der Jahre von der unterjährigen Struktur oder eine weitere Separierung angezeigt ist. Wenn diese Begründung auch nicht völlig von der Hand zu weisen ist, führt der Entschluss für getrennte Zeitdimensionen zu Folgeproblemen, denn aus technischen wie logischen Gründen erlauben die meisten Systeme nur eine logische Zeitdimension pro Cube, und jahresübergreifende Berechnungen mit Hilfe der dafür vorgesehenen MDX-Funktionen (rollierende Durchschnitte etc.) und Visualisierungen (z.B. Sparklines, Trends) sind nur innerhalb einer kontinuierlichen Achse sinnvoll möglich.
Wichtig: Die technische Entscheidung für eine einzige Dimension bedeutet nicht zwingend die Darstellung nur eines Merkmals im Frontend.
Hierarchisierung
Um einerseits die Aggregation atomarer (Tages-)Werte auf Zeiträume sowie andere Top-down-Analysen zu ermöglichen, sollte die Zeitdimension anstelle flacher Attributlisten mindestens eine Hierarchie aufweisen. Typische Strukturen sind “Jahr-Quartal-Monat-Tag” und “Jahr-Kalenderwoche-Tag”. Zusatzinformationen wie z.B. Wochentage können in modernen OLAP-Technologien wie z.B. Microsoft SQL Analysis Services 2005/2008 als zusätzliche einstufige Attributhierarchie abgebildet werden, die dann im Anwenderfrontend als separate Dimension angezeigt wird und damit kreuztabellierbar ist.
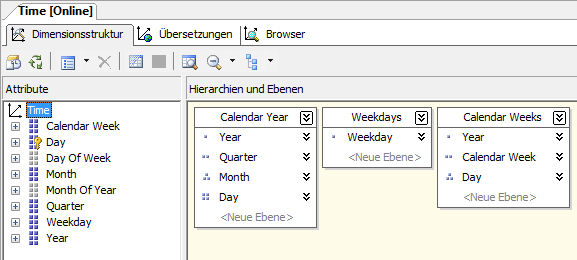
So können beispielsweise Wochentagsspitzen im Monatsverlauf betrachtet werden:
Die Verwendung von Hierarchien im Frontend als alternative Hierarchien oder separate Dimensionen wird innerhalb der ADOMD.NET-Schnittstelle gesteuert. Um komplexere Zusammenhänge wie die Vorgabe, die Monats- oder Wochenhierarchie oder Kalender- und Geschäftsjahressicht nur alternativ anzubieten, alle vorgenannten jedoch z.B. mit der Wochentagshierarchie kombinierbar zu machen, ist eine Feinsteuerung erforderlich. Bissantz & Company verwendet daher eine von DeltaMaster nicht genutzte Hierarchieeigenschaft zur Definition: den DisplayFolder. Mit der einfachen Regel “Hierarchien mit identischem DisplayFolder werden als Hierarchie dargestellt, pro DisplayFolder entsteht eine eigene Dimension” sind alle Konstellationen abbildbar.
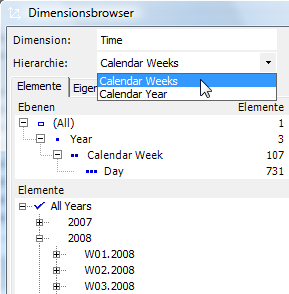
Chronologie durch Zeittabelle
Die Zeitdimension sollte eine lückenlose Chronologie darstellen und deshalb aus einer eigenen Stammdatentabelle befüllt werden. Würden Datumswerte aus Bewegungs-/Faktendaten abgeleitet, entstehen zum einen Lücken z.B. bei Feiertagen oder Betriebsferien, und zum anderen ist die Zeitachse nicht für die Eingabe von (Zukunfts-)Planwerten vorbereitet. Betrachtungsstart und -ende des Systems können so frei definiert werden. Von der Verwendung virtueller Konstrukte wie der Analysis-Services-Serverzeitdimension in Kombination mit DeltaMaster ist abzuraten, da beim SQL-Belegdurchgriff basierend auf der OLAP-DataSource automatisch ein Mapping mit den tatsächlichen SQL-Tabellen generiert wird, das andernfalls ins Leere greift.
Umgang mit Uhrzeiten
Sollte das Anwendungsszenario die Integration Tages- oder gar Uhrzeiten erfordern, gilt das Prinzip analog: Die kleinste Einheit der (gemeinsamen!) Zeitreihe bilden anstelle eines Datums nun beispielsweise Stunden oder Minuten, wodurch die Zeittabelle um den Faktor 24 bzw. 24*60=1.440 wächst. So können weiterhin korrekte Zeitreihen gebildet, Kumulationen und Bestände ermittelt und Abweichungen berechnet werden. Im Frontend wird die Uhrzeithierarchie idealerweise separat dargestellt und zeigt eine Struktur wie z.B. Tageszeit-Stunde-Viertelstunde-Minute. Auf diese Weise können Zeit und Uhrzeit kreuztabelliert werden, und z.B. im Handels- und Dienstleistungssektor (Call Center etc.) werden übliche Analysen von Belastungsspitzen möglich.
Zeitberechnungen
Microsoft propagiert den Einsatz einer Hilfsdimension (“TimeUtility”), innerhalb derer sämtliche zeitbezogenen Berechnungen abgebildet werden. Entscheidender Vorteil dieses auf den ersten Blick kompliziert erscheinenden Ansatzes: Die Formeldefinition erfolgt an einer einzigen Stelle und wird unterstützt von fest integrierten MDX-Funktionen wie ParallelPeriod und PeriodsToDate. Erweitert man diesen Gedanken konsequent, drängt sich die Forderung nach der Trennung der Operationen in Zeitaggregationen (Kumulation, rollierende Durchschnitte, Moving Annual Total etc.) und Zeitsprünge (Vorjahr/Vorperiode und absolute/relative Abweichung) auf. Die Begründung ist einfach: Ein Bericht, der in den Spalten die Hilfsdimension verwendet, um ausgehend vom aktuellen Element in der Zeitdimension die aktuelle Periode, die Vorperiode und die absolute und relative Abweichung zeigt, soll mit einem Klick zwischen (perioden-)isolierter und kumulierter Betrachtung umschaltbar sein. Modelliert man beides innerhalb einer einzigen Hilfsdimension, müssen alle drei Berechnungen (Vorperiode, absolute Abweichung, relative Abweichung) sowohl periodenweise als auch kumuliert berechnet werden – im Ergebnis sind 3*2=6 Formeln nötig, und wiederum entsteht ein Kreuzprodukt.
Nach unserer Erfahrung sind mit zwei Hilfsdimensionen alle Konstellationen abbildbar, denn alle uns bekannten Berechnungen lassen sich entweder der Gattung “Zeitaggregation” oder “Zeitsprung” zuordnen und müssen nicht innerhalb der eigenen Gattung kombiniert werden. Die Fleißarbeit übernimmt in Bissantz-Modellen übrigens automatisch der Standardcontent des DeltaMaster Modeler.
Ob die Definition der Formeln optimalerweise client- oder serverbasiert erfolgt, ist im Einzelfall zu beurteilen. Es gilt der allgemeine Grundsatz “Flexibilität versus Einheitlichkeit und Performance”. Im Sinne der Ressourcenbelastung ist einzig die Aggregation (vor allem bei der Kumulation von Werten auf Tagesebene oder noch feinerer Granularität) “teuer”, so dass die Auslagerung auf den Server zu spürbarer Beschleunigung führt.
Hinweis am Rande: Besondere Vorsicht ist bei Zeitberechnungen im Kontext paralleler Zeithierarchien (siehe oben: Monat vs. Kalenderwoche, Kalender- vs. Geschäftsjahr etc.) angeraten, denn hier bietet die Formelgenerierung innerhalb DeltaMaster den Vorteil der dynamischen MDX-Codegenerierung auf der Basis der aktuellen Hierarchie. MDX-Formeln im Backend dagegen müssen hier mit Hilfe eines “Iif”-Konstrukts die aktuelle Hierarchie ermitteln, was wiederum aufgrund mangels Verfügbarkeit einer Eigenschaft “CurrentHierarchy” nur per Workaround über die Prüfung der CurrentMember sämtlicher Hierarchien möglich ist.
Multiple Verwendung: Zeitrollen
Oft enthalten Bewegungsdaten gleich mehrere Zeitinformationen. Um sich nicht aufgrund der obigen Definitionen z.B. zwischen Bestell-, Liefer-, Rechnungs- und Zahlungsdatum für nur eine der vorliegenden Informationen entscheiden zu müssen, existieren wiederum mehrere Konzepte. Die schnellste und einfachste Alternative stellt Microsofts Ansatz der Role Playing Dimensions dar, wobei die Dimensionstabelle schlichtweg mehrfach mit den jeweiligen Spalten der Faktentabelle verknüpft und die Zeitdimension im Cube einfach mehrfach verwendet wird – übrigens automatisch inklusive all ihrer etwaigen Hierarchien. Hier liegt jedoch wiederum ein Denkfehler vor, denn weiterhin gilt: Nur eine logische Dimension hat die Eigenschaft Zeit und kann damit die Basis für die oben beschriebenen erforderlichen Berechnungen bilden. Das Konzept der Role Playing Dimensions eignet sich also nur bedingt für Zeitmerkmale.
Nach unserer Erfahrung ist die “Best Practice” stattdessen die Transformation der Bewegungsdaten mit Hilfe eines Satzart-Kennzeichens, in dem die jeweilige Bedeutung der Information abgebildet wird (z.B. Bestellung, Lieferung, Rechnung, Zahlung). Im obigen Beispiel entstehen aus einem Rohdatensatz also vier Sätze. Der Vorteil der uneingeschränkten Nutzbarkeit der bisher beschriebenen Konzepte wird demnach diese Multiplikation der Rohdaten in Kauf genommen.
![]()
Fazit
Mit Hilfe der beschriebenen Modellierungsansätze entstehen flexible, robuste, performante und skalierbare Systeme. Der eventuelle Zusatzaufwand einer generischen Konzeption und Implementierung spart auf lange Sicht viel Ärger, Zeit und Geld. Damit schließt sich der Kreis. Viel Erfolg bei der Umsetzung!
