Unsere Beratungsmannschaft ist schnell – sehr schnell. In unseren 2-Tages-Workshops beweisen wir das regelmäßig und begeistern Interessenten und Kunden gleichermaßen. Mit unserer DeltaMaster Suite sind wir sowohl schnell beim Modellbau als auch beim späteren Berichtsbau.
Dennoch treibt mich schon seit langer Zeit die Frage um, wie wir hier noch besser und schneller werden können. Vor allem wie wir nerviges Try-and-Error auf fremden Datenbeständen loswerden. Intensive Diskussionen mit Dr. Nicolas Bissantz und diverse Webrecherchen haben mich schließlich auf die Idee des Data Profiling gebracht. Wie genial wäre es, wenn wir unsere DeltaMaster-Visualisierungstechnik bereits beim Beurteilen der Quelldaten nutzen könnten. Damit würden wir viele Schleifen beim Modellbau vermeiden und könnten bereits vorher Fehler identifizieren und Klippen umschiffen.
Ein paar Tage später war der Data Profiler geboren und die Ergebnisse begeistern mich noch immer. Da das Werkzeug aktuell erstmal als Stand-alone-Lösung existiert, sind ein paar manuelle Schritte für den Einsatz notwendig. Diese werden im vorliegenden Blogbeitrag erläutert und ein paar Beispiele für die Erkenntnisse aus den Daten geliefert. Lieutenant Caine – let’s go profiling…
Zusatzmaterial können Sie unter service@bissantz.de anfordern.
Vorbereitungen
Systemvoraussetzungen
Keine!
Die aktuelle Lösung besteht aus nicht mehr als einem SQL-Skript und einer DeltaMaster-Analysesitzung (siehe Zusatzmaterial). Beide arbeiten komplett ohne vorinstalliertem DeltaMaster ETL (vormals Modeler).
Bei Skriptausführung werden lediglich ein paar wenige SQL-Objekte angelegt. Aktuell sind dies:
- T_ModelInfo_TableProfile
- T_ModelInfo_TableColumnContent
- T_ModelInfo_TableColumnPattern
- V_ModelInfo_TableProfile
- V_ModelInfo_TableColumnContent
- V_ModelInfo_TableColumnPattern
- F_BC_TextPattern
- P_BC_Profile_Tables
Dass man zum Öffnen der Analysesitzung einen lauffähigen DeltaMaster benötigt, versteht sich von selbst. Getestet und entwickelt wurde die DAS mit der Version 6.1.5/5.6.5 MP6.
Installation
Zur Installation muss lediglich das Skript auf der zu analysierenden Zieldatenbank ausgeführt werden. Dass man dafür zunächst die Datenbank im Management-Studio korrekt einstellen muss, sollte auch vollkommen klar sein.
Abbildung 1: Installation
Damit sind die SQL-Objekte angelegt aber noch gänzlich leer.
Befüllung
Für die Befüllung muss lediglich die erzeugte Stored Procedure P_BC_Profile_Tables mit den entsprechenden Parametern ausgeführt werden.
Folgende Parameter sind dabei zu berücksichtigen:
- @TableNamePattern
Datentyp: varchar(250)
Default: ‚T_Import_%‘Hier kann der zu analysierende Tabellenname selbst oder das Namensmuster der zu analysierenden Tabellen übergeben werden. Also zum Beispiel alle die mit „T_Import_“ beginnen (was auch der Standardwert des Parameters ist). Dafür kann einfach auf die bekannte Syntax aus dem LIKE-Operator zurückgegriffen und die bekannten Wildcards verwendet werden. Also in dem Fall „T_Import_%“.
Wichtig ist noch, dass die Prozedur stets inkrementell arbeitet. Sprich, die Tabellen müssen nicht immer alle auf einmal analysiert werden. Die zugehörigen Logtabellen können also auch Schritt für Schritt mit einzelnen Tabellen gefüllt oder einzelne Tabelleninformationen aktualisiert werden.
In der aktuellen Version 11 des Skripts ist der Name des Parameters wörtlich zu nehmen, so dass wirklich nur Tabellen analysierbar sind. Für Views läuft das Skript zwar ohne Fehler durch, es können allerdings noch nicht alle Informationen korrekt ermittelt werden. Dies wird in einer späteren Version noch behoben, sollte aber auch einen Ausnahmefall darstellen. Das Profiling sollte üblicherweise auf den Rohdaten laufen als Grundlage für den Aufbau der nachfolgenden Views.
- @WorkOnDataExtract
Datentyp: bit
Default: 1
Mit diesem Parameter kann erstmal nur ein Extrakt von 10.000 Datensätzen analysiert werden. Das bietet sich für einen ersten Überblick über die vorliegenden Daten an, wenn die Tabellen sehr groß sind. Das Skript braucht schon etwas Zeit und kann bei der Analyse aller Daten durchaus mal mehrere Minuten laufen . Wenn nur der Extrakt analysiert wird, kann man die Laufzeit auf wenige Sekunden drücken. Die Standardwerte sind dabei so gewählt, dass die optimale Performance erzielt wird und nicht „versehentlich“ mal das Skript aufgerufen wird und ewig läuft.
Für die Zusammenstellung des Extrakts von 10.000 Datensätzen wird nicht ein simples TOP 10.000 verwendet, sondern die von Jens Reumann beschriebene TABLESAMPLE-Funktion des SQL-Servers. Damit bekommt man einen deutlich repräsentativeren Ausschnitt der Daten und kann trotzdem die Laufzeitvorteile nutzen. Siehe dazu auch:
https://www.bissantz.de/know-how/crew/reprasentative-daten/
https://technet.microsoft.com/de-de/library/ms189108(v=sql.105).aspx - @IncludeColumnProfile
Datentyp: bit
Default: 0
Auch dieser Parameter dient lediglich der Laufzeitoptimierung und ist daher im Standard so gesetzt, dass das Skript schnell läuft. In dem Fall werden bei der Analyse die Spalteninformationen (Column content & Column pattern) ausgelassen. Möchte man die vollständigen Informationen erhalten, muss der Parameter auf 1 gesetzt werden.
Hintergrund: Insbesondere die Analyse der Spalteninhalte und der Wertmuster ist sehr aufwendig, gerade bei Spalten, die viele verschiedene Inhalte und Muster vorweisen. Daher kann man den Schritt gesondert abschalten.
Ein typischer Aufruf der Prozedur bei überschaubaren Datenmengen würde also so aussehen:
![]()
Da die Zeitersparnis durch die ermittelten Daten in aller Regel deutlich höher sein wird als die Laufzeit von ein paar Minuten, empfiehlt es sich meist die Analyse vollständig laufen zu lassen.
Die Oberfläche
Bericht „Table profile“
Die Analysesitzung ist recht schlank und besteht nur aus drei Berichten, wobei zwei der Berichte lediglich als Absprungziel dienen und über kurz oder lang wegfallen. Der wichtigste Bericht ist der Startbericht „Table profile“:
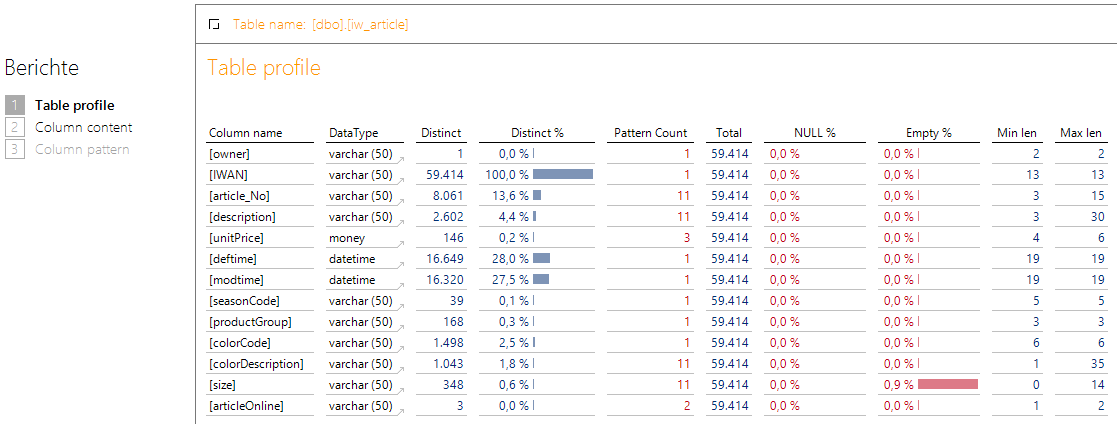
Abbildung 2: Bericht „Table profile“
Dort wird in der Sicht die gewünschte Tabelle ausgewählt. In den Zeilen werden anschließend die vorhanden Spalten in der technischen Reihenfolge samt Datentyp gezeigt. Interessant werden dann die dargestellten Kennzahlen.
Die Distinct-Spalten (Distinct/Distinct %) geben einen Hinweis darauf, wie unterschiedlich die Ausprägungen in einer Spalte sind. Wird ein Prozentsatz von 100 % erreicht, handelt es sich bei der Spalte mit hoher Wahrscheinlichkeit um einen Primärschlüssel, sofern es sich um eine Stammdatentabelle handelt. Ist hingegen nur ein kleiner Wert vorhanden, könnte es eine Gruppierungsinformation sein.
Der Pattern Count gibt Auskunft über die verschiedenen Formate in den Daten: Sehen Produktnummern, Datumsfelder oder Postleitzahlen immer gleich aus oder gibt es verschiedene Formate? Ideal ist natürlich für die folgende Verarbeitung immer der Wert 1. Existiert mehr als ein Format, kann das normal sein (z. B. bei Bezeichnungsspalten) oder es könnte ein Hinweis auf Datenfehler und/oder notwendige Konvertierungen sein. Von daher ist ein hoher Wert nicht zwingend schlecht.
Die Total-Spalte ist eine einfache Information über die Anzahl aller vorhandenen Datensätze und logischerweise in jeder Zeile identisch.
Anschließend wird der Prozentsatz der NULL-Werte und der leeren Werte gezeigt (wobei Leerzeichen eliminiert werden). Beide Prozentsätze sollten möglichst niedrig sein. Andernfalls könnte die Datenqualität der Spalte sehr schlecht sein und evtl. nicht für eine Hierarchie verwendet werden. Sind Leer- und NULL-Werte vorhanden, muss dies in der folgenden Konvertierung berücksichtigt werden.
Die letzten beiden Spalten zeigen die minimale und maximale Länge über alle vorhandenen Werte in der Spalte an. Das liefert ähnlich dem Pattern Count auch ein Hinweis auf unsaubere Datenkonstellationen auf die evtl. reagiert werden muss. Zum Beispiel würden wir bei deutschen Postleitzahlen erwarten, dass sowohl Min als auch Max len den Wert 5 zeigen. Ist die Min len bei 4 legt das den Ver-dacht nahe, dass bei den 0er Postleitzahlen die führende 0 fehlt (ein ganz typischer Fehler).
Außerdem gibt es noch ein paar wertvolle, aber etwas versteckte Informationen in dem Bericht. Und zwar wird noch der Min- und Max-Wert der Spalte getrennt nach Datentyp ausgewertet. Diese Informationen sind im Tooltip der Zeilenachse versteckt:

Abbildung 3: Tooltip für Min/Max-Ausprägungen
Hier kann zum Beispiel die Auffälligkeit in der Min/Max len nochmal näher untersucht werden und man kann den kleinsten und größten Wert in Augenschein nehmen. Bei Texten wird dabei nicht der „normale“ Min-Wert ermittelt, sondern der kleinste Wert mit der Länge des Min-len-Werts. So wird sichergestellt, dass nicht einfach der alphabetisch erste Wert gezeigt wird, der aber dennoch die maximale Länge an Zeichen hat. Neben der Kontrolle der Min/Max-len-Information kann man die Information auch sehr gut bei Felder mit Datumsinformationen nutzen, um zu prüfen, ob Werte außerhalb des verwendeten Datentyps geliefert werden (wie z. B. 31.12.9999 oder 1789-01-01).
Abschließend existiert auf dem Bericht hinter der Spalte DataType eine Verknüpfung, die zu der jewei-ligen Spalte noch Details anbietet:
Abbildung 4: Verknüpfungen
In der aktuellen Version 11 ist dies nur der „Column content“. Später wird hier „Column content“ und „Column pattern“ wählbar sein.
Bericht „Column content“
Dieser Bericht ist sehr einfach aufgebaut und zeigt zu einer Spalte alle vorhandenen unterschiedlichen Werte an und zeigt die Anzahl des Vorkommens in der Tabelle an:
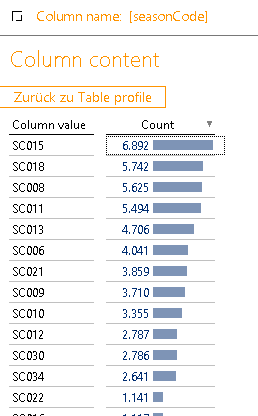
Abbildung 5: Bericht „Column content“
Damit kann man sehr schön Details und Wertverteilungen in den gelieferten Werten erkennen und ersten Anhaltspunkten weiter auf den Grund gehen. Sehr ungleiche Verteilungen an Werten können weitere Hinweise auf Auffälligkeiten in den Daten geben, die zumindest mal zu einer Rückfrage beim Datenlieferanten führen sollten. Später dazu mehr.
Hinweis: Da wirklich alle unterschiedlichen Ausprägungen gezeigt werden, kann es durchaus sein, dass der Bericht mal etwas länger rechnet (z. B. wenn alle Produktnummern einer Faktentabelle angezeigt werden sollen).
Bericht „Column pattern“
Dieser Bericht ist ebenfalls einfach aufgebaut und zeigt alle gefundenen Datenformate innerhalb einer Spalte an. Neben dem Format zeigt der Bericht noch einen Beispielwert an und liefert wie der vorherige Bericht die Anzahl an Datensätzen, welche jenes Format aufweisen:
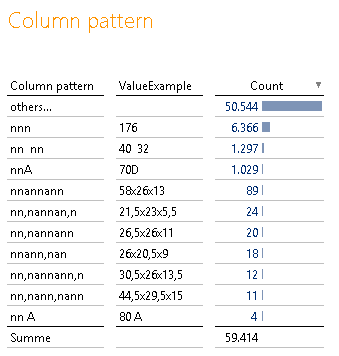
Abbildung 6: Bericht „Column pattern“
Hier kann man Auffälligkeiten im Pattern Count weiter untersuchen. Das Wertbeispiel liefert einen Hinweis auf die tatsächliche Ausprägung, welche das Muster erzeugt hat. Hier kann man schön die Tauglichkeit von Spalten für Hierarchien untersuchen.
Sind mehr als 10 verschiedene Muster in den Daten gefunden worden, bricht der Analyseprozess ab und fasst alle restlichen Formate unter der künstlichen elften Gruppe „others…“ zusammen. Dies geschieht ebenfalls aus Laufzeitgründen und unter der Annahme, dass es sich bei mehr als 10 verschiedenen Datenmustern ohnehin um eine Freitextspalte handelt, bei der das Muster zweitrangig ist.
Auch hier deuten sehr ungleiche Verteilungen in den Formaten auf Auffälligkeiten und eventuelle Pflegefehler hin.
Hinweis: Aus technischen Gründen ist dieser Bericht bislang nicht als Verknüpfung in den Bericht „Table profile“ aufgenommen und muss aus dem Baum manuell aufgerufen und dann per Sichteinstellung konfiguriert werden.
Data Profiling live
Für die Entwicklung des Data Profilers habe ich Testdaten verwendet, die aus einem SQL-Lehrbuch stammen. Dabei handelt es sich um die Daten eines Online-Shops mit Stammdatentabellen (z. B. Kunde, Artikel) und mehreren Faktentabellen (Umsatz, Retoure, Offene Forderungen). Die Daten sind sehr realitätsnah und enthalten einige Überraschungen, die mir bei einem vorangegangen Modellaufbau auf die Füße gefallen sind. Diese sieht man nicht auf den ersten Blick und bemerkt sie erst bei den zahlreichen Aufbauversuchen oder der ersten Analyse der OLAP-Daten.
Begeben wir uns auf eine Reise durch unsere Daten und schauen uns ein paar Auffälligkeiten und Rückschlüsse an.
Tabelle „iw_article“
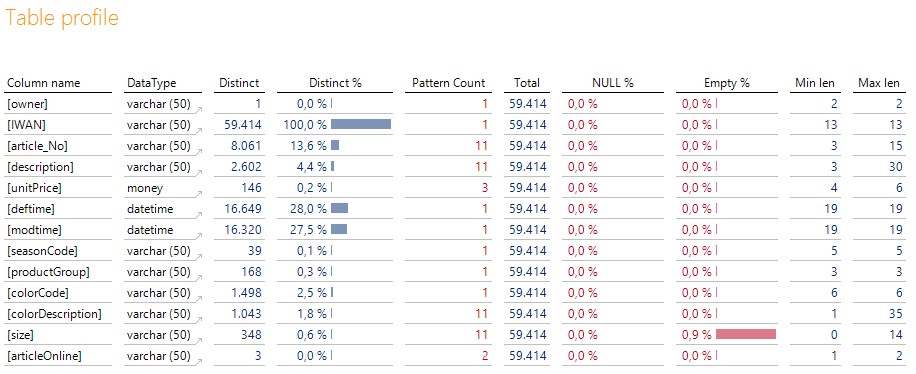
Abbildung 7: Tabelle „iw_article“
Der Name der Tabelle lässt darauf schließen, dass es sich hier um Stammdaten handeln muss, die den Artikelstamm enthalten. Bei einem Blick auf die Spaltennamen könnte man zunächst davon ausgehen, dass „article_No“ wohl die Artikelnummer und damit den Primärschlüssel enthalten wird. Einen Transformationsversuch bemerkt man allerdings, dass dem nicht so ist. Erst die Lektüre des Lehrbuchs zeigt, dass die Spalte „IWAN“ den eigentlichen Artikel enthält, der einen Artikeltyp an-scheinend noch einmal nach Größe oder Farbe unterscheidet. In dem oben gezeigten Profile erkennt man dies mit einem Blick auf die Spalte „Distinct %“. Vielleicht kann die Spalte „article_No“ für eine Verdichtungsebene verwendet werden? Auffällig ist hier aber weiterhin der Pattern count von 11. Das hätte ich bei einer Artikelnummer nicht erwartet. Der Blick in den Bericht „Column pattern“ verrät hier, dass es sehr viele verschiedene Formate gibt:

Abbildung 8: Column pattern „article_no“
Eine Rückfrage wäre hier angebracht. Ist das wirklich korrekt so?
Die Spalte „IWAN“ ist komplett eindeutig und hat auch einen Pattern count von 1. Also ganz klar unser Schlüsselfeld.
Was erkennen wir noch?
Die Spalte „owner“ scheint nicht sinnvoll befüllt zu sein, da anscheinend immer der gleiche Wert ent-halten ist (Wert „Distinct“ = 1).
Die Beschreibung der Artikel scheint sehr häufig gleich zu sein, weshalb man beispielsweise noch die IWAN-Nummer oder ein weiteres Kriterium im Alias verwenden sollte (Wert „Distinct“ der Spalte „description“ ist deutlich kleiner als der der Spalte „IWAN“).
unitPrice ist vom Format her eigentlich in Ordnung. Die Tatsache, dass hier 3 Patterns existieren, liegt lediglich an der unterschiedlichen Länge der Werte. Seltsam ist nur, dass es als kleinsten Wert einen unitPrice von 0 gibt?
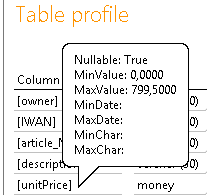
Abbildung 9: Tooltip „unitPrice“
Auch hier wäre eine Rückfrage angebracht.
Die Spalten von „deftime“ bis „colorCode“ sind alle sehr gut befüllt. Der Pattern Count von 1 gibt Gewissheit, dass das gelieferte Format sauber ist. Aufgrund der kleinen Anzahl von unterschiedlichen Werten bei „seasonCode“ und „productGroup“ eignen diese sich sicherlich für eine Hierarchie. Ein Blick auf die „Column contents“ schafft nochmal Gewissheit (siehe auch Abbildung 5).
„colorDescription“ darf wieder viele Muster haben, da es sich dem Namen nach um eine Beschreibung handelt. Allerdings scheint es wieder eine ganze Menge Beschreibungen zu geben, die bei verschiedenen colorCodes doppelt existieren (Distinct „colorCode“ > Distinct „colorDescription“). Wären die Namen eindeutig, hätten beide den gleichen Distinct-Wert. Auch hier empfiehlt sich die Verwendung eines Langnamens mit Code als Alias.
Die Spalte „size“ ist wieder auffällig. Der Name ließe auch auf die Verwendung als Hierarchie schließen (S, M, L). Da wir allerdings 11 verschiedene Patterns und ganze 348 unterschiedliche Werte haben, kann hier etwas nicht stimmen. Schaut man sich die Ausprägungen an (siehe Abbildung 6), erkennt man, dass es sich hier anscheinend um eine Art Freitextfeld handelt, in welchem jede beliebige Größenangabe hinterlegt werden kann. Dies vermutlich auch, weil es sich um verschiedene Größenkategorien handelt (Männer, Frauen, Kinder, Europäisch, Amerikanisch, Zwischengrößen, …):
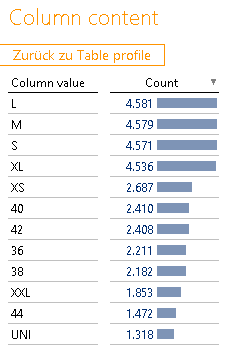
Abbildung 10: Column content „size“
Dass außerdem 0,9 % der „size“-Werte Leerstrings enthalten, verschlimmert die Datenqualität noch weiter. Eine Hierarchie ist hier vermutlich wenig sinnvoll.
Schließlich noch die Spalte „articleOnline“. Drei unterschiedliche Ausprägungen und der Name der Spalte deuten wieder auf die Nutzbarkeit als Hierarchie hin. Vom Namen her müsste es aber nur ein Ja-Nein-Feld (True/False) sein – warum also drei Ausprägungen? Auch hier hilft wieder die Verknüpfung auf den „Column content“ weiter:

Abbildung 11: Column content „articleOnline“
Der Verdacht mit dem Ja-Nein-Feld war schon ziemlich richtig. Allerdings haben sich ganz offensichtlich 70 Falscheingaben in Form von 0“ eingeschlichen. Ganz offensichtlich ein Fall für das ERP-Team des Kunden.
Tabelle „iw_codeReason“
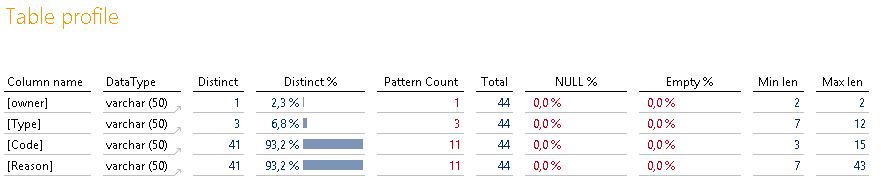
Abbildung 12: Tabelle „iw_codeReason“
Die Größe der Tabelle von 44 Datensätzen und der Name der Tabelle lassen den Schluss zu, dass es sich hier offensichtlich um Stammdaten handelt. Allerdings ist es seltsam, dass es keine eindeutige Spalte gibt?
„Code“ und „Reason“ scheinen beide Kandidaten zu sein, aber hier existieren jeweils nur 41 unterschiedliche Ausprägungen. Schauen wir uns zunächst die Inhalte von „Code“ an:
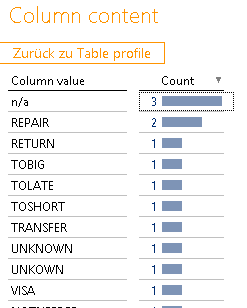
Abbildung 13: Column content „Code“
Hier erkennen wir, dass sowohl das Kriterium „n/a“ als auch „REPAIR“ ganz offensichtlich doppelt vorkommen. Ein klarer Hinweis darauf, dass wir die Werte „künstlich eindeutig“ machen müssen. Da das einzige Gruppierungskriterium die Spalte „Type“ zu sein scheint, wäre vermutlich eine Verknüpfung von „Type“ und „Code“ sinnvoll, um eine Eindeutigkeit zu erzielen. Ohne die Information habe ich natürlich mein Modell erstmal nur auf dem „Code“ aufgebaut und habe eine Primärschlüsselverletzung produziert.
Ein Blick auf die Inhalte der Spalte „Reason“ verrät, dass es sich ganz offensichtlich um die zugehörigen Bezeichnungsfelder handelt. Die Wertverteilung ist gleich und die Texte sehen deutlich lesbarer aus:

Abbildung 14: Column content „Reason“
Tabelle „iw_customer“
Die nächste Stammdatentabelle mit Kundendaten. Auch hier haben wir bestimmte Erwartungen an die Inhalte. Vermutlich werden Namen enthalten sein, Adressdaten evtl. E-Mail-Adressen. Alle sollten bestimmte Bedingungen erfüllen, damit sie gut nutzbar sind.
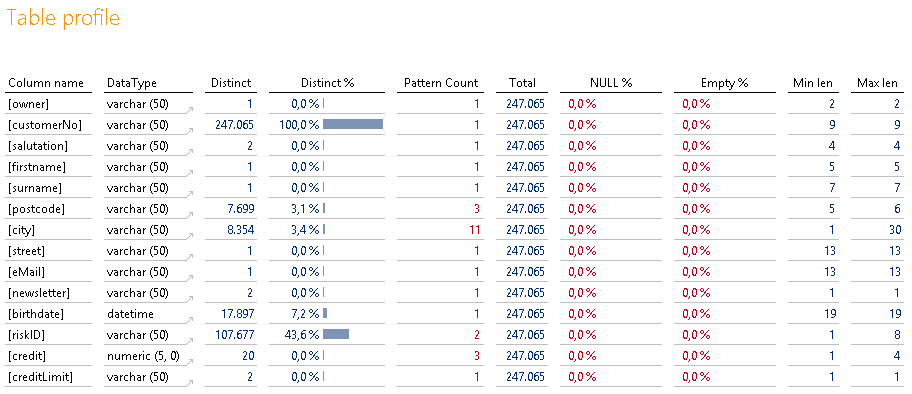
Abbildung 15: Tabelle „iw_customer“
Die Spalte „owner“ kann auch hier wieder ignoriert werden.
„customerNo“ ist (entgegen der Artikel) der Primärschlüssel und der Pattern count von 1 lässt uns bezüglich der Formate ruhig schlafen. Ebenso die „salutation“.
Sind die ganzen Spalten mit dem Distinct Count von 1. „Firstname“, „surname“, „street“, „eMail“ – alle gleich? Auch hier hilft der Verknüpfungssprung, um die Inhalte zu prüfen:
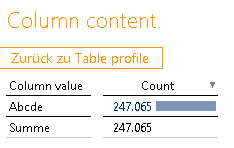
Abbildung 16: Column content „firstname“
Ganz offensichtlich handelt es sich hier um anonymisierte Daten und die Verwendung der Spalten in einem Modell lohnt sich nicht. Soweit so gut.
Wie sieht es mit „postcode“ und „city“ aus? Auffällig ist wieder der Pattern count von 3 bei der Postleitzahl. Sollte das Format hier nicht eindeutig sein? Auch eine Min len von 5 und eine Max len von 6 sind auffällig. Diesmal sollte man den Bericht „Column pattern“ vorziehen und die unterschiedlichen Wertmuster ansehen:

Abbildung 17: Column pattern „postcode“
Die Erkenntnis: Zwei Datensätze sind fehlerhaft gepflegt oder zumindest auffällig. Einer enthält eine 6-stellige Postleitzahl und einer eine österreichische Postleitzahl. Letzteres könnte durchaus gewollt und korrekt sein.
Bei der „city“ ist es in Ordnung, dass mehr als 10 verschieden Formate existieren. Schließlich gibt es unterschiedliche Längen und Formate bei Städtenamen. Misstrauisch macht allerdings die Min len von 1. Das wäre schon eine sehr kurze Bezeichnung? Hier reicht ein Blick auf den Tooltip, um den Indikator zu identifizieren:
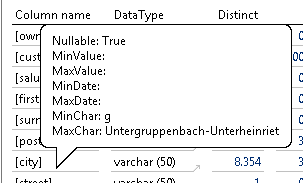
Abbildung 18: Tooltip „city“
Eine Stadt namens „g“ – spannend. Hier zeigt sich die Stärke des gewählten MinChar-Algorithmus. Würde einfach der Min-Wert gezeigt, wäre vermutlich Aachen oder ähnliches gezeigt worden.
„newsletter“ als typisches Ja-Nein-Feld sieht in Ordnung aus. „birthdate“ auf den ersten Blick auch. Da es sich hierbei allerdings um ein Datumsfeld handelt und wir wissen wie speziell ERP-Systeme teilweise mit Datumsfeldern umgehen, lohnt bei diesen immer ein Blick auf den Tooltip, um die Min-Max-Werte zu prüfen:
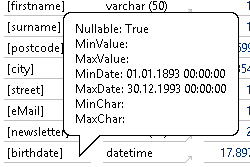
Abbildung 19: Tooltip „birthdate“
Und gleich noch ein Treffer. Die Kombination aus übersichtlicher Darstellung und ein bisschen Modellierungserfahrung ist unschlagbar. Hier sollten wir das Datumsfeld entweder groß genug dimensionieren oder diese Dummywerte in der weiteren Verarbeitung ausschließen. Obendrein würde ich für das Geburtsdatum den Zeitstempel abschneiden.
Die restlichen Spalten sind unauffällig und werden an dieser Stelle nicht weiter behandelt.
Tabelle „iw_sales“
Hierbei haben wir die erste Faktentabelle vor der Brust. Auch hier haben wir bestimmte Erwartungen an Schlüssel-, Kennzahlen- und Datumsfelder. Schauen wir, ob diese erfüllt werden und was hier auffällig ist.
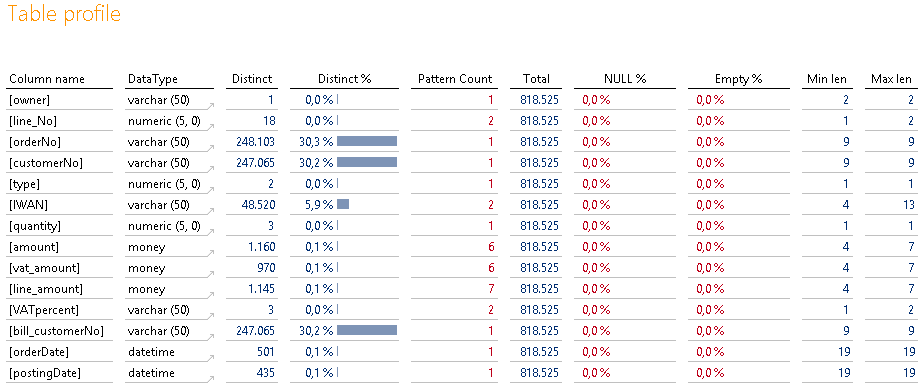
Abbildung 20: Tabelle „iw_sales“
Der Spaltenname „orderNo“ lässt darauf schließen, dass es sich um eine Bestellnummer handelt. Da diese nicht eindeutig ist, handelt es sich ganz offensichtlich um eine Tabelle mit einzelnen Bestellpositionen (also keine Kopftabelle). Vermutlich die Spalte „line_No“.
Auffällig ist die Tatsache, dass fast jede Bestellung durch einen anderen Kunden ausgeführt wird. Er-warten könnte man, dass Kunden mehrfach bestellen, sprich der Distinct-Wert der Spalte „customerNo“ deutlich geringer ist als der Distinct-Wert der Spalte „orderNo“. Ist der Shop so schlecht? Tatsächlich offenbart das Lehrbuch aus dem die Daten kommen irgendwann, dass es sich hierbei um viele Gastzugänge handelt, die bei jeder Bestellung neu angelegt werden. Will man den tatsächlichen Kunden haben, muss man auf die Spalte „riskID“ aus den Kundenstammdaten zurückgreifen. Diese werden über die Schufa ermittelt und identifizieren die natürliche Person eindeutig. Durch die hervor-ragende DeltaMaster-Visualisierung hätte man selbst darauf kommen und nachfragen können. Mir blieb es beim ersten Versuch ohne den Profiler verborgen.
Die nächste Überraschung wartet in der Spalte „IWAN“ auf uns. Wir erinnern uns, dass wir diese vor-hin eindeutig als Schlüsselkandidaten identifiziert haben und einen Pattern count von 1 haben. Nicht so in den Faktendaten. Hier haben wir einen Pattern count von 2 und eine Min len von 4 – was ist da denn los? Sowohl Tooltip als auch „Column content“ geben hier Aufschluss:
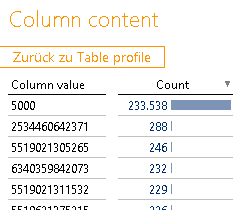
Abbildung 21: Column content „IWAN“
Ein gehöriger Anteil der Daten steht auf einer einzelnen 4-stelligen IWAN-Nummer? Und diese gibt es noch nicht mal in unseren Stammdaten? Auch hier hätte eine Nachfrage frühzeitig zur Lösung des Problems beigetragen. Im Lehrbuch kommt später heraus, dass es sich dabei um die Versandkosten handelt, die auch alle über die Umsatztabelle laufen aber eben keinem Artikel zugeordnet werden. Daher werden diese auf dem Dummy-Artikel 5000 verbucht. Eine adäquate Reaktion darauf wäre entweder das Anreichern der Stammdaten aus den Fakten oder noch besser das Ausgliedern der Ver-sandkosten in eine eigene MeasureGroup.
Die Wertspalten in der Tabelle sind alle in Ordnung und weisen keine seltsamen Formate auf.
Seltsam mutet dann wieder die Spalte „bill_customerNo“ an. Inhaltlich scheint das (typisch Online-Shop) eine abweichende Rechnungsadresse zum Kunden zu sein. Dass hier allerdings exakt so viele Einträge wie Kundennummern vorhanden sind, ist komisch.
Abschließend offenbart auch hier wieder die obligatorische Tooltip-Prüfung auf Datumsfeldern, dass das „orderDate“ wieder ein „Monddatum“ enthält – spannend wie früh der Online-Shop schon aktiv war:
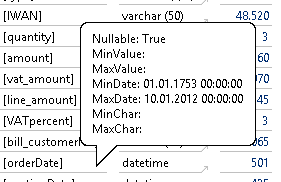
Abbildung 22: Tooltip „orderDate“
Tabelle „iw_return_header“
Die nächsten Faktendaten sind aufgeteilt in Kopf- und Satzdaten. Auch das nicht unüblich. Starten wir mit den Kopfdaten, diesmal geht es um die Rücksendungen.
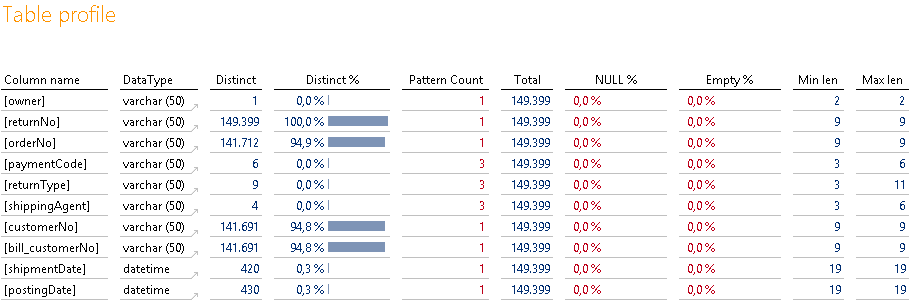
Abbildung 23: Tabelle „iw_return_header“
Diese Tabelle ist im Vergleich zu den anderen nicht ganz so auffällig. Dennoch gibt es ein paar erwähnenswerte Punkte.
Ausgehend vom Tabellenamen wissen wir, dass es sich um eine Faktentabelle handelt. Dennoch existiert ein Distinct-%-Wert von 100 %? Ganz offensichtlich ist das eine Identifikation des Buchungssatzes und nicht weiter ungewöhnlich. Hätten wir eine Umsatzkopftabelle gehabt, wäre dies dort genauso gewesen. Dieses Feld bietet sich also Infofeld an. Sprich, mit einem Distinct-%-Wert von 100 % verfahren wir im Falle einer Faktentabelle anders als bei einer Stammtabelle.
Interessant ist weiterhin, dass es zu einer „orderNo“ anscheinend mehr als eine „returnNo“ gibt. Auch das wieder mit einem Blick auf den Distinct-Wert erkennbar und auch logisch. Eine Bestellung kann zum einen mehr als einen Artikel enthalten, die durchaus auch getrennt zurückgeschickt werden können. Weiterhin kann ein Artikel (z. B. bei Reparatur) auch mehrfach eingeschickt werden, wenn dieser wiederholt kaputtgeht. Auch diese Tatsache ist mir erst nach einer ursprünglich falschen Modellierung aufgefallen. Mit CSI-Profiler-Technik wäre das nicht passiert.
Tabelle „iw_return_line“
Der Vollständigkeit halber schauen wir uns nun noch die Satztabelle zu den Rücksendungen an.
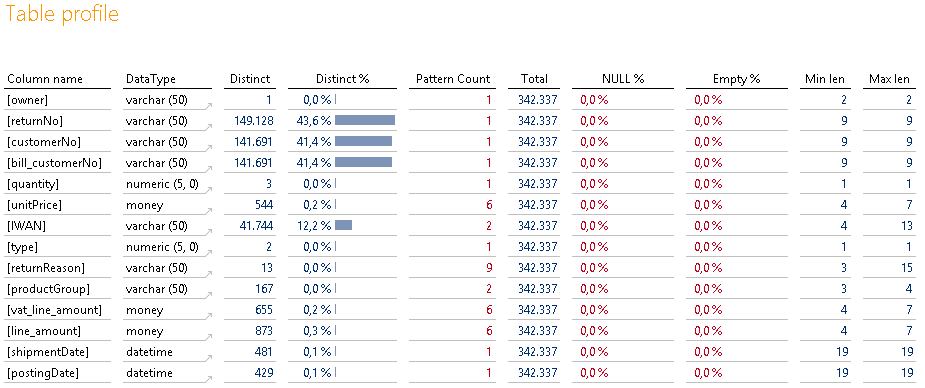
Abbildung 24: Tabelle „iw_return_line“
Hier warten allerdings kaum neue Erkenntnisse auf uns.
Lediglich die Besonderheit der IWAN-Nummer 5000 fällt hier wieder auf. Auch bei den Retouren scheint diese enthalten zu sein.
Außerdem auffällig ist die Spalte „productGroup“. Neben der Tatsache, dass diese meiner Meinung nach eigentlich nichts in den Faktendaten zu suchen hat, werden hier auch noch zwei verschiedene Formate geliefert – eines davon enthält den Text „NULL“. Ein deutlicher Hinweis darauf, die Spalte links liegen zu lassen und lieber die Spalte aus dem Artikelstamm zu verwenden. Dort hat nur ein Pattern existiert.
Fazit & Ausblick
Es ist nach wie vor phantastisch, was man alles durch das Profiling auf den Daten herausfinden kann. Insbesondere durch das Zusammenspiel des Data Profilers mit Modellierungserfahrung können in Windeseile Schlüsse gezogen werden, die vorher nur durch mühsames Try-and-Error möglich waren.
Im nächsten Schritt werden wir die Komponente nahtlos in DeltaMaster ETL integrieren, so dass das Werkzeug in jedem Projekt mit an Bord ist.
