Das vorliegende Beispiel zeigt auf, wie die Migration von Daten mit Hilfe der Azure Cloud gelingen kann. Der Transfer der Daten in die Cloud und die Transformation in das gewünschte Format kann als Basis für Business-Intelligence-Anwendungen genutzt werden, die als Ganzes in der Cloud ausgeführt werden sollen. Die regelmäßige automatische Ausführung des Prozesses und das Error-Logging runden den Anwendungsfall ab.
Zielsetzung
Für den Daten-Transfer von Microsoft Business Central – Dynamics 365 auf einen SQL-Server, der in diesem Fall auf einer in Azure gehosteten virtuellen Maschine (VM) läuft, soll ein dynamischer Prozess aufgesetzt werden. Der Prozess ruft die Daten regelmäßig aus den Tabellen über eine REST-API ab und speichert diese auf dem SQL-Server. Als Zwischenschritt werden die Daten zusätzlich als Parquet-Datei im Storage von Azure gespeichert.
Die Daten werden für n Tabellen über eine mandantenspezifische API abgerufen. Für einige Tabellen werden die Daten vollständig und für andere Tabellen für einen zeitlich begrenzten Zeitraum angefragt, ein sogenanntes Delta-Load-Verfahren. Der Prozess wird per Trigger einmal am Tag ausgeführt. Sollten während der Migration Fehler auftreten, wird automatisch eine Benachrichtigung per E-Mail angestoßen.
Infrastruktur
Bevor der Migrationsprozess implementiert werden kann, müssen die technischen Voraussetzungen geschaffen werden. In Azure werden hierzu insbesondere ein Storage (Data Lake Gen2) und die Azure Data Factory (ADF) benötigt. Für die Funktionalitäten der ADF ist zusätzlich eine Integration Runtime (IR) erforderlich. In diesem Beispiel wird eine On-Premises-Variante auf einer in Azure gehosteten Virtual Machine (VM) verwendet (ähnlich wie im Beitrag „Datenimport von On-Premises-Datenquellen in die Azure-Cloud“).
Voraussetzungen im Storage-Account
Ein Storage-Account ist ein Speicher in der Cloud, der hierarchische Strukturen erlaubt, sodass Dateien verwaltet und in Ordnern strukturiert werden können. Für unseren Anwendungsfall sollten folgende Dateien und Ordner im Storage bereitstehen:
- Im Storage werden die zu verarbeitenden Mandanten in einer Excel-Datei (hier kann auch ein beliebiges anderes Format gewählt werden) mit dem entsprechenden Company-Code für die URL und dem Dateinamen für die Excel-Datei mit den zu importierenden Tabellen hinterlegt.
- Je Mandant wird eine Datei mit den Tabellennamen und dem zu betrachtenden rückwirkenden Zeitraum in Wochen bereitgestellt.
- In einem separaten Ordner sind die Zuordnungsschemata für die Felder einer jeden Tabelle im JSON-Format hinterlegt. Dieses wird benötigt, um die Felder der per API erhaltenen JSON-Datei auf die Spalten einer Parquet-Datei zu mappen.
- Abschließend befindet sich im Storage ein Ordner, in den die zu den Tabellen erstellten Parquet-Dateien gelegt werden.
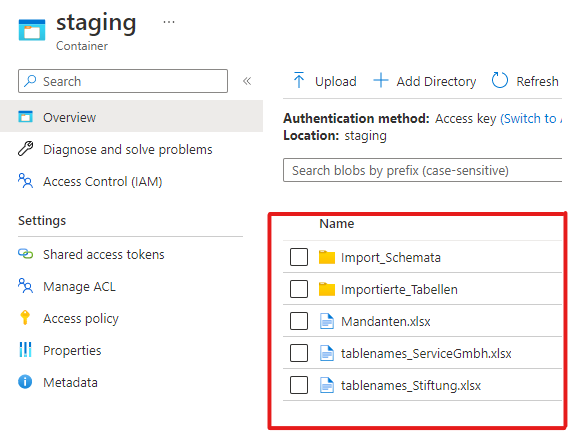
Abbildung 1: Schema im Azure Storage
Strukturen in der Azure Data Factory (ADF)
In der ADF selbst werden neben der Verbindung zu einer IR noch Linked Services benötigt, welche die Verbindungsdaten zum REST-Service, zum Storage-Account und zur SQL-Datenbank enthalten. Um Daten zu ermitteln und zu speichern, werden außerdem Datasets benötigt, welche für jedes entsprechende Dateiformat und für jeden Abhol- und Speicherort erstellt werden müssen.
Linked Services
Ein Linked Service enthält die Verbindungsdaten zu einer Quelle und/oder einem Ziel und die zugehörigen Zugangsdaten. Für jeden unterschiedlichen Quell-/Zieltypen wird somit ein separater Linked Service benötigt. In diesem Fall sind folgende drei Typen erforderlich:
- Azure Blob Storage (Ziel und Quelle): Beim Erstellen des Linked Services müssen nur der „Storage account name“ und die Zugangsdaten eines Accounts mit Zugangsberechtigung angegeben werden. Wenn zwischen lesendem und schreibendem Zugriff unterschieden werden soll, werden dementsprechend zwei Services mit unterschiedlichen Accounts benötigt.
- REST-Service (Quelle): Da die Daten über einen REST-Service abgerufen werden, muss der Service die URL der API enthalten. Zusätzlich besteht die Herausforderung, dass die Daten für zwei Mandanten abgerufen werden, bei denen sich die URL nur im Company-Code unterscheidet. Um nicht für jeden Abruf einen eigenen Service erstellen zu müssen, kann die URL mit Hilfe von Parametern dynamisiert werden. Indem für den Linked Service ein Parameter erstellt wird, kann beim späteren Aufruf der Company-Code übergeben und somit in die URL durch Konkatenation dynamisch eingebunden werden.
- SQL-Server (Ziel): Zum Speichern der Daten in der SQL-Datenbank werden im zugehörigen Linked Service der Server, die Datenbank und die Zugangsdaten für einen schreibberechtigten User angegeben.
Datasets
Datasets werden spezifisch für jeden Datentyp erstellt und enthalten eine Quelle oder ein Ziel. Für Dateien wie im Excel-Format, JSON, CSV etc. wird der Speicherort bis zum Dateinamen angegeben, für SQL-Server die zu verwendende Tabelle und für den REST-Service die URL aus dem Linked Service zuzüglich eventueller Erweiterungen. Ein Dataset baut immer auf einem Linked Service auf, dessen Verbindungsdaten für das Dataset verwendet und bei Bedarf erweitert werden. Analog zum Linked Service kann hier durch Zuweisung von Parametern eine Dynamisierung erreicht werden, sodass Datasets für verschiedene Teilprozesse wiederverwendet werden können.
1. Excel-Dataset: Da sowohl die zu importierenden Mandanten als auch die jeweils zu importierenden Tabellen in einer Excel-Datei gespeichert sind, wird hierfür ein Excel-Dataset verwendet, welches als Parameter den Dateinamen und den Namen des Tabellenblattes erhalten muss.
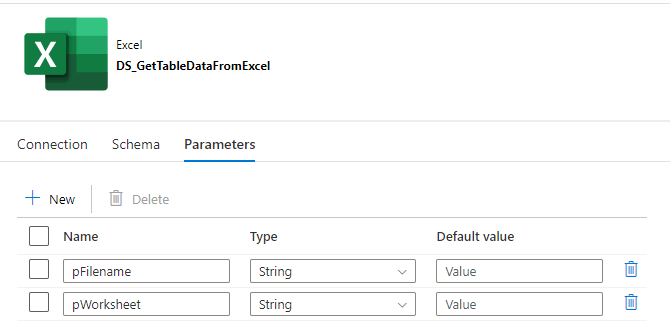
Abbildung 2: Parameteransicht des Excel-Datasets
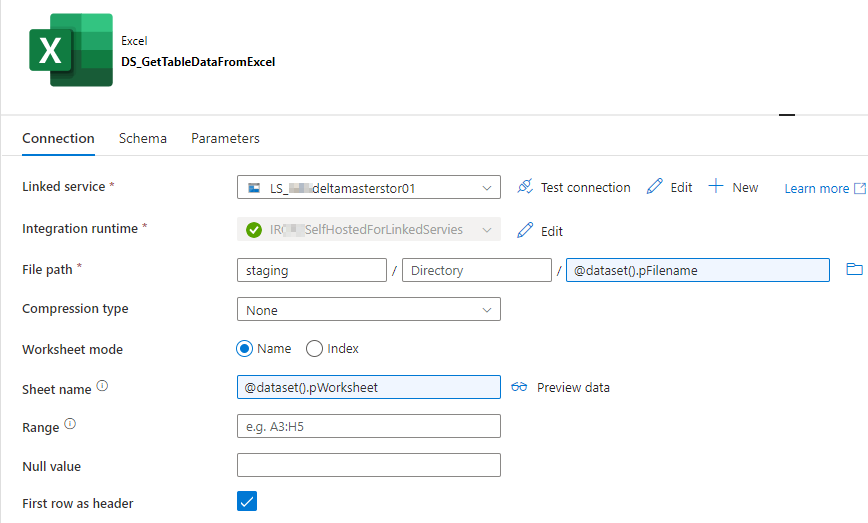
Abbildung 3: Verbindungsansicht des Excel-Datasets
2. REST-Service Dataset: Für das Abrufen der Tabellen wird ein REST-Service-Dataset benötigt, welches den Company-Code an den Linked Service übergibt und die URL um den Tabellennamen sowie ggf. einen Filter nach dem Zeitraum ergänzt, auf Basis des Ausführungszeitpunktes für die rückwirkende Betrachtung.
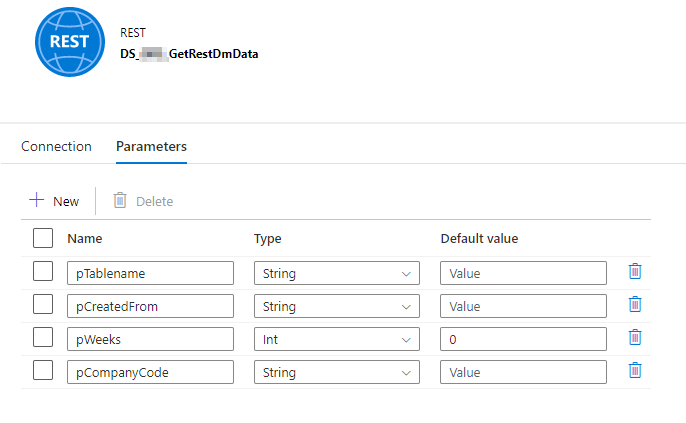
Abbildung 4: Parameteransicht des REST-Service Datasets
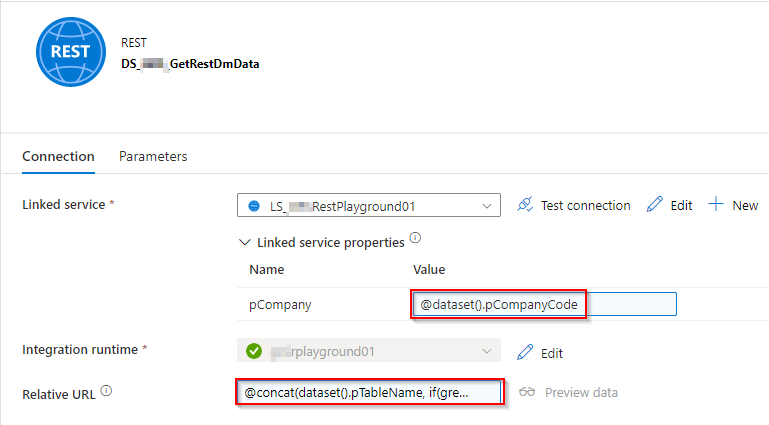
Abbildung 5: Verbindungsansicht des REST-Service Datasets
Relative URL:
@concat(
dataset().pTableName
,if(
greater(dataset().pWeeks, 0)
,concat(
'?$filter=systemModifiedAt gt '
,subtractFromTime(dataset().pCreatedFrom
,dataset().pWeeks, 'Week'
)
)
, ''
)
)3. Parquet-Dataset: Zum Speichern der abgerufenen Daten als Parquet-Datei im Storage wird ein entsprechendes Dataset herangezogen, welches den Speicherort enthält und als Parameter den Tabellennamen zugewiesen bekommt, der als Dateiname verwendet wird. Dasselbe Dataset wird dann wiederum verwendet, um die Daten abzurufen und in die SQL-Datenbank zu speichern.
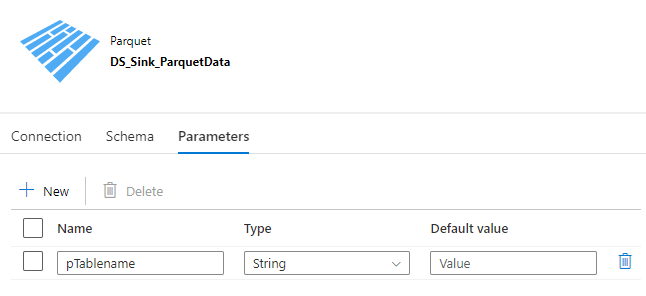
Abbildung 6: Parameteransicht des Parquet-Datasets
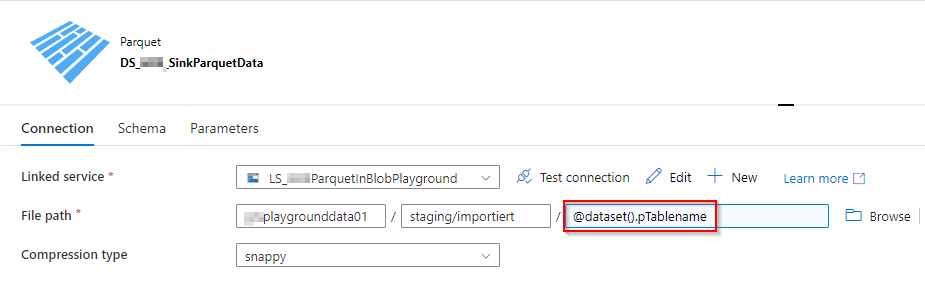
Abbildung 7: Verbindungsansicht des Parquet-Datasets
4. JSON-Dataset: Die Anfrage an den REST-Service und das anschließende Speichern in einer Parquet-Datei ist für Azure im JSON-Format definiert. Daher ist es erforderlich, jeweils das für die Tabelle erforderliche Mapping ebenfalls im JSON-Format bereitzustellen. Die Mapping-Datei zu jeder Tabelle liegt im Storage und kann hier mittels Tabellennamen abgerufen werden. Das Dataset benötigt als Parameter somit den Tabellennamen, der durch eine Konkatenation den abzurufenden Dateinamen ergibt (siehe Dateiname unten).
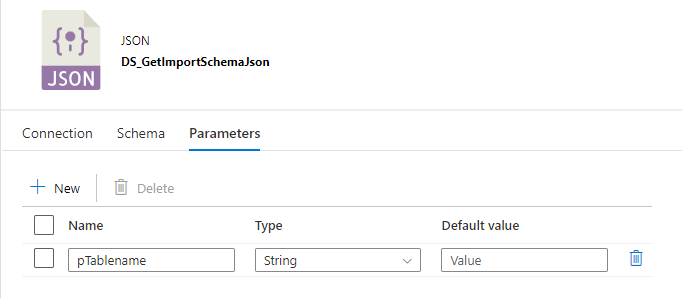
Abbildung 8: Parameteransicht des JSON-Datasets
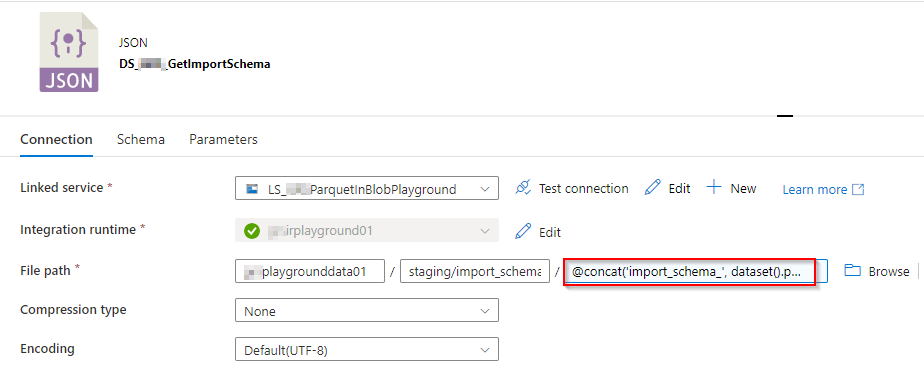
Abbildung 9: Verbindungsansicht des JSON-Datasets
Dateiname:
@concat(
'import_schema_'
, dataset().pTablename
, '.json'
)5. SQL-Server-Dataset: Um die Daten auf dem SQL-Server zu speichern, wird ein Dataset verwendet, in dem der zu verwendende Tabellenname angegeben ist, welcher wiederum parametrisiert ist.
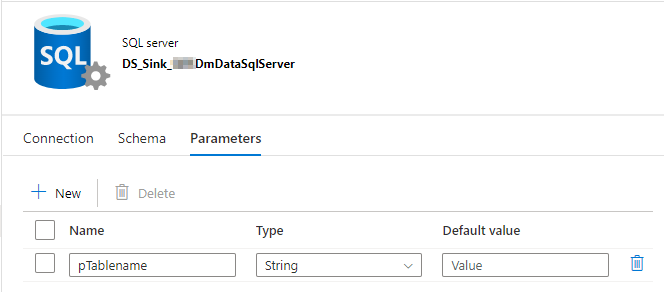
Abbildung 10: Parameteransicht des SQL-Server-Datasets
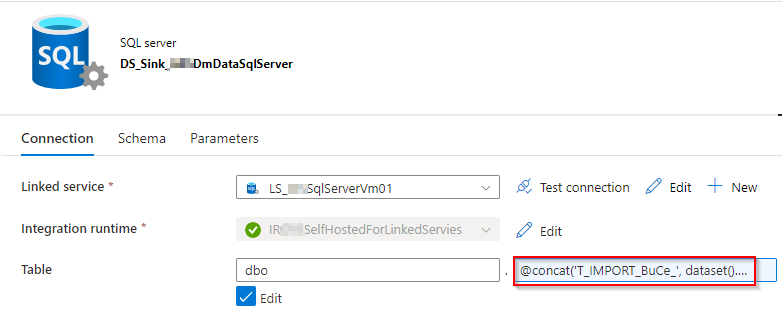
Abbildung 11: Verbindungsansicht des SQL-Server-Datasets
Tabellenname:
@concat(
'T_IMPORT_BuCe_'
, dataset().pTablename
)Import-Schema
Zu jeder Tabelle ist ein Import-Schema erforderlich. Prinzipiell gibt es in der ADF die Möglichkeit, entweder ein Mapping anhand der Quelle zu importieren oder sogar ohne Vorgabe eines Mappings ein automatisches Mapping durchführen zu lassen.
Einfache Transformationen können innerhalb der Kopierfunktionalität durchgeführt werden. Wenn allerdings, wie in diesem Fall, ein Verflachen der Hierarchie erfolgen soll, kann dies nicht automatisch aufgelöst werden, da die Daten in einem Array geliefert werden, das alle Werte aus der Tabelle enthält. Dann ist es notwendig, den Namen des Arrays anzugeben und dieses als Sammlung von Werten zu kennzeichnen, wodurch eine Überführung in eine flache Hierarchie möglich wird. Das Mapping ist dann aber statisch und für jede Tabelle müsste eine separate Kopierfunktion angelegt werden. Um das zu vermeiden, kann das Schema importiert, angepasst und anschließend als JSON-Datei gespeichert werden, um wie oben beschrieben für jede Tabelle das passende Schema dynamisch abzurufen.
Für komplexere Strukturen ist es nicht möglich, ein Mapping innerhalb der Kopierfunktion durchzuführen, da hier es hier lediglich möglich ist, ein einfaches Array aufzulösen. Für das Auflösen mehrerer oder gar verschachtelter Arrays müsste die Transformation in einem Data Flow durchgeführt werden.
Migrationsprozess
Nachdem die benötigte Infrastruktur für die Datenmigration steht, kann der eigentliche Prozess implementiert werden. Dieser besteht aus drei Pipelines, welche geschachtelt aufgerufen werden.
Zunächst wird in der ersten Pipeline (vgl. Abbildung 12) mittels einer Lookup-Aktivität die Datei „Mandanten.xlsx“ aus dem Storage abgerufen. Für jeden hier enthaltenen Mandaten wird eine ForEach-Schleife ausgeführt, in der zwei weitere Pipelines den folgenden Prozess steuern.
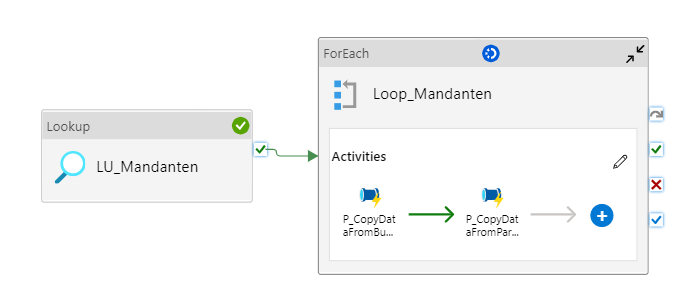
Abbildung 12: Gesamtprozess Datenmigration (Pipeline 1)
Beim Aufruf der zweiten Pipeline (Abbildung 13) wird per Lookup die Excel-Datei mit den abzurufenden Tabellen abgefragt. In einer weiteren ForEach-Schleife wird für jede Tabelle zunächst das zugehörige Import-Schema aus oben genanntem Ordner im Storage geholt und beim Kopieren der Daten vom REST-Service in eine Parquet-Datei verwendet. Die Kopieraktivität ruft die zu importierenden Daten per REST-API ab unter Verwendung des Company-Codes, der aktuellen Zeit und der rückwirkenden Betrachtung. Die gelieferten Daten kommen im JSON-Format. Um die Daten in eine Parquet-Datei speichern zu können, muss die Aktivität wissen, dass im JSON ein Array vorhanden ist, das aufgelöst werden muss, und welcher Wert auf welche Spalte mit welchem Datentyp kopiert werden soll. Diese Informationen stehen im Import-Schema, welches zuvor zu der jeweiligen Tabelle abgerufen wurde. Die Daten werden um eine Spalte für die Identifizierung des Mandanten ergänzt, da später Daten von unterschiedlichen Mandanten in derselben Tabelle landen sollen. Die Parquet-Dateien werden nach erfolgreichem Kopieren im Storage gespeichert.
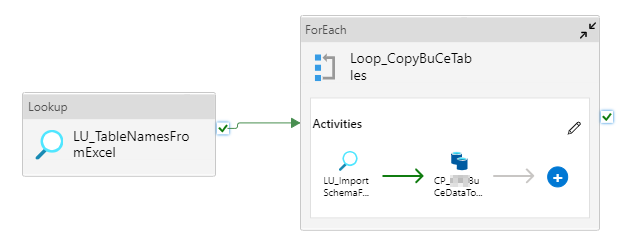
Abbildung 13: Abrufen der Daten per REST-API und Kopieren in Parquet-Dateien (Pipeline 2)
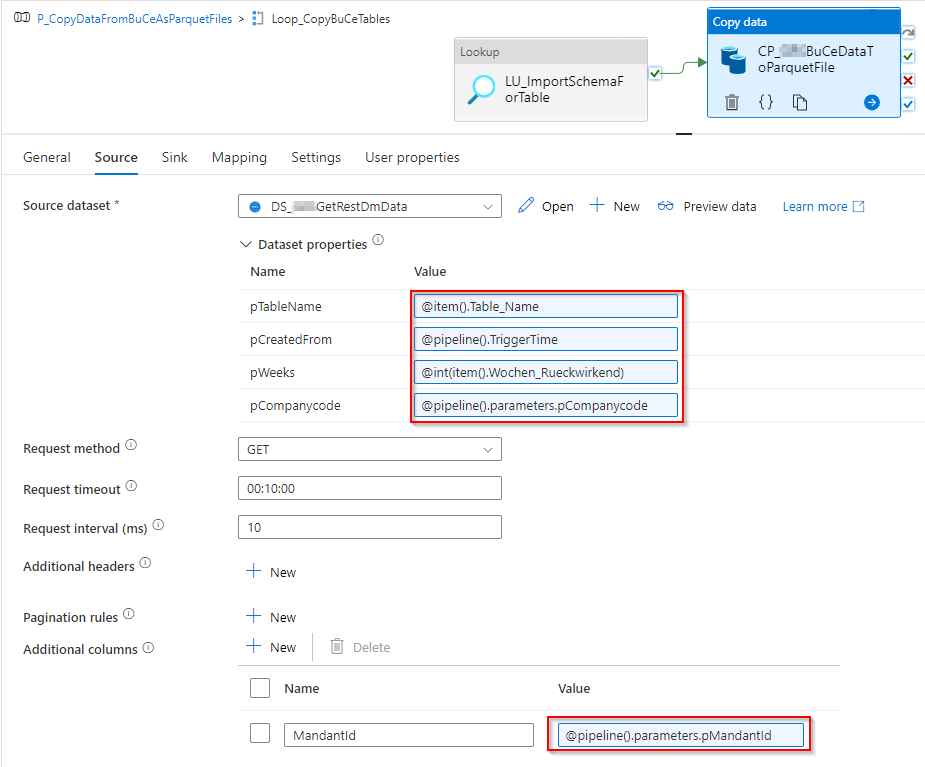
Abbildung 14: Quelleinstellungen der Kopieraktivität REST-API zu Parquet-Datei
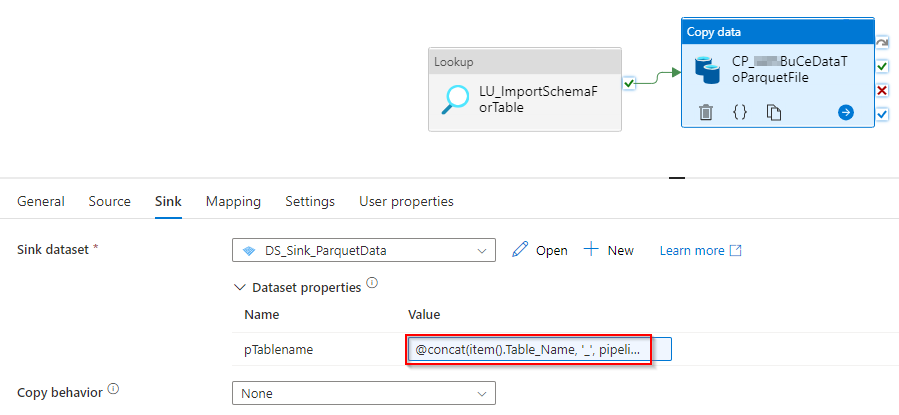
Abbildung 15: Zieleinstellungen der Kopieraktivität REST-API zu Parquet-Datei
Tabellenname:
@concat(
item().Table_Name
,'_',pipeline().parameters.pMandantId
)In der dritten Pipeline werden die Daten aus den Parquet-Dateien wiederum kopiert und in eine SQL-Datenbank geschrieben (vgl. Abbildung 16). Die Vorgabe eines Schemas ist hier nicht notwendig, da die Meta-Daten mit Spaltennamen und Typ bereits in der Parquet-Datei enthalten sind und eins zu eins für die SQL-Datenbank übernommen werden können. Die Basis für die zu kopierenden Dateien bildet wiederum die Excel-Datei mit den Tabellennamen. Nach Abschluss dieses Kopiervorgangs werden die Pipelines 2 und 3 für den nächsten Mandanten erneut durchlaufen.
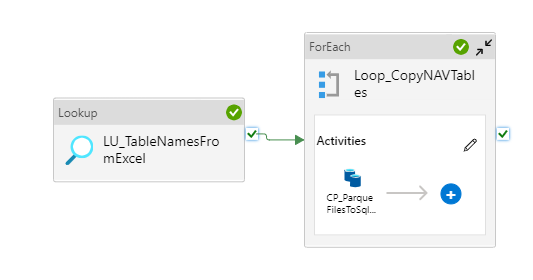
Abbildung 16: Kopieren der Daten aus den Parquet-Dateien in die SQL-Datenbank (Pipeline 3)
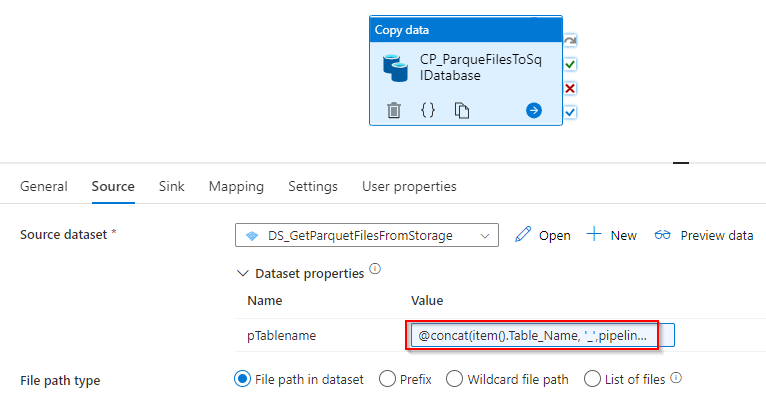
Abbildung 17: Quelleinstellungen der Kopieraktivität Parquet-Datei zu SQL-Datenbank
Tabellenname:
@concat(
item().Table_Name
,'_',pipeline().parameters.pMandantId
)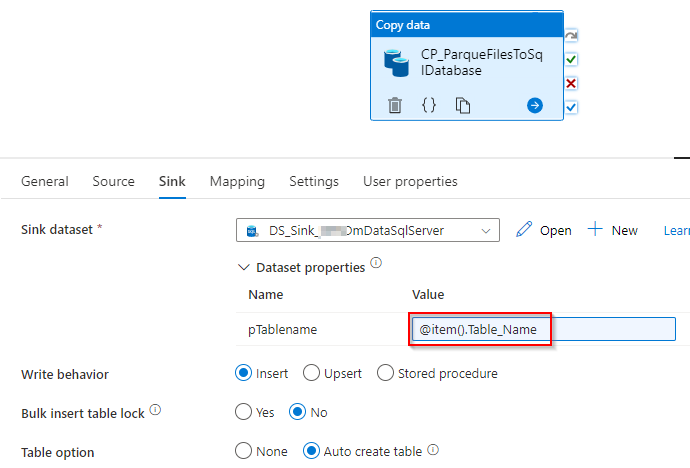
Abbildung 18: Zieleinstellungen der Kopieraktivität REST-API zu Parquet-Datei
Error-Logging
Um die regelmäßige automatische Datenmigration zu überwachen, wird ein Alert eingestellt, der bei Fehler oder Abbruch der Pipeline eine Nachricht in Form von E-Mail, SMS und/oder Push-Benachrichtigung in der Azure-App an eine oder mehrere zuständige Personen sendet. Eine manuelle Überwachung ist somit nicht nötig. Bei Fehlermeldungen kann umgehend in den Prozess eingegriffen werden. Bei Bedarf sind die Prozessdurchläufe immer in der ADF einsehbar.
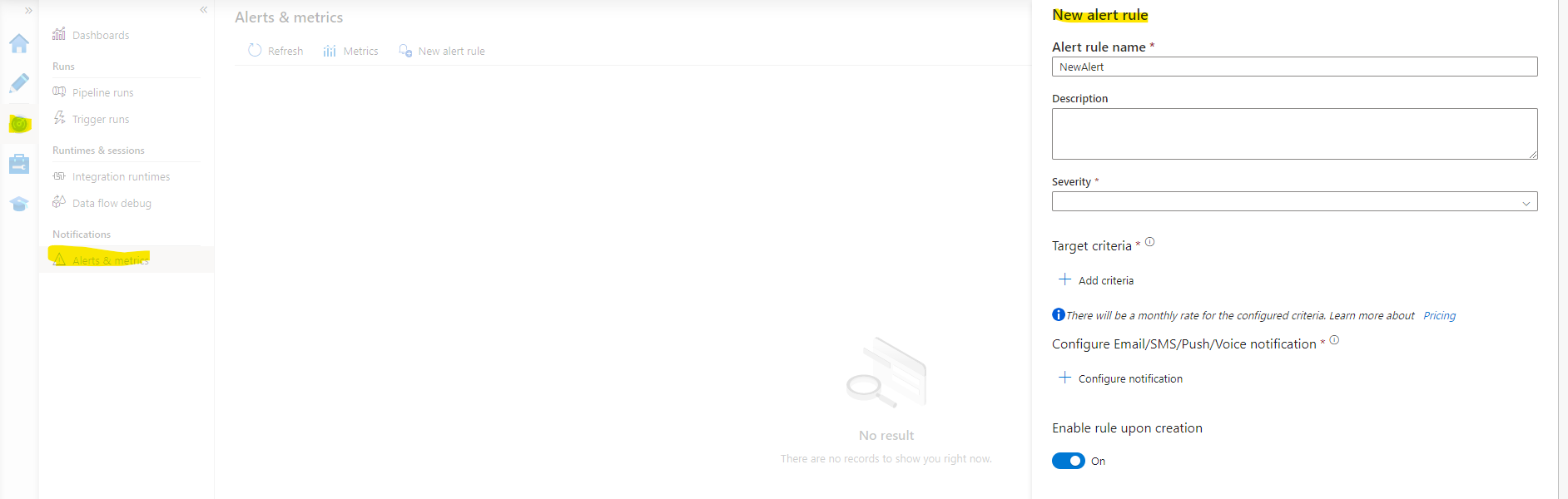
Abbildung 19: Einstellen eines Alerts in der ADF
Fazit
Wie das vorliegende Beispiel zeigt, bietet die Azure Data Factory eine sehr gute Möglichkeit zur Migration von Daten über verschiedenste Systeme und Formate hinweg. Eine Dynamisierung und somit eine kompakte Datenflussstruktur wird durch die Parametrisierung der unterschiedlichen Komponenten erreicht. Das Beispiel bildet einen relativ einfachen Anwendungsfall ab, bei dem insbesondere die Transformation der Daten in ein anderes Format unkompliziert möglich ist. Aber auch für komplexere Anwendungsfälle bietet die ADF die nötigen Werkzeuge für eine reibungslose Migration und Transformation von Daten.
