Einer der Grundsätze der OLAP-Modellierung ist die Zusammenfassung von Informationen gleicher Merkmalstiefe in gemeinsamen Speicherobjekten. Diese werden getreu der Vorstellung der Multidimensionalität betriebswirtschaftlicher Daten als Würfel (Cubes) bezeichnet. In einschlägiger Literatur findet sich meist die Forderung, Measures gleicher Dimensionalität und Granularität innerhalb eines Cubes zu organisieren. In der Folge entstehen in BI-Systemen meist mehrere Cubes, welche später unter Umständen miteinander zu verknüpfen sind, wenn Informationen aus unterschiedlichen Cubes über gemeinsame Merkmale (Dimensionen) zueinander in Beziehung gesetzt werden sollen. Beispielsweise ist für eine Kennzahl “Umsatz pro Mitarbeiter” der Dividend aller Wahrscheinlichkeit nach mit mehr und/oder anderen Merkmalen behaftet als der Divisor. Für den korrekten Zusammenhang sorgt dabei üblicherweise das OLAP-Datenbanksystem eigenständig, indem die Berechnung nur über gemeinsame Achsen durchgeführt wird. Das Ergebnis, gleichsam die Ober-/Vereinigungsmenge der Basiswürfel, wird je nach Produkt als HyperCube, Supercube, virtueller Cube, Linked Cube, Derived Cube oder ähnlich bezeichnet.
Microsoft führte in diesem Kontext mit SQL Server Analysis Services 2005 einen neuen Begriff ein: die Measure Group. Handelt es sich dabei lediglich um eine Begriffsverschiebung, ist also Microsofts Measure Group schlichtweg der Cube der klassischen OLAP-Lehre, und ersetzt der Cube in Analysis Services 2005/2008, der alle Measure Groups in sich kapselt, den früheren virtuellen Cube? Gilt demnach die Regel, Analysewerte gleicher Dimensionalität/Granularität in Measure Groups zu organisieren, und alle Measure Groups zu einem einzigen Cube zusammenzufassen? In welchen Situationen ist es sinnvoll oder erforderlich, mehr als einen Cube zu modellieren?
Dieser Artikel untersucht Vor- und Nachteile beider Ansätze im aktuellen Paradigma.
Grundlegende Betrachtungen
Die Sinnhaftigkeit der separaten Speicherung strukturell unterschiedlicher Daten in OLAP-Modellen ist unstrittig. Auf der dem OLAP-System meist zugrundeliegenden relationalen Data Warehouse ist das sogenannte Eintabellenschema ein seltener Trivialfall; in produktiven Szenarien sind meist mehrere Star- oder Snowflake-Schemata vorzufinden, in denen Daten vor allem aus speichertechnischen Erwägungen, d.h. entsprechend ihrer Merkmalszahl und -tiefe, zusammengefasst werden. In Einzelfällen können logische Aspekte zu einer Trennung strukturell gleicher Daten (z.B. GuV und Bilanz) führen. Der umgekehrte Fall der Zusammenführung strukturungleicher Daten dagegen ist in der Regel ein Symptom suboptimaler Modellierung.
Auf dieser Basis ist zu beurteilen, welche der gegebenen Alternativen – die Speicherung von Measure Groups in einem gemeinsamen Cube oder in separaten Cubes – aus technischer wie pragmatischer und administrativer Sicht optimal ist. Hierzu müssen unterschiedliche Aspekte betrachtet werden:
Auf welche Objekte greift der Endanwender bzw. die Clientsoftware zu?
Grundsätzlich “sehen” Frontends wie DeltaMaster über die üblichen Schnittstellen (ODBO, ADOMD.NET) den Cube, nicht einzelne Measure Groups. Einen Sonderfall bilden die sogenannten Perspectives: Diese sind Untermengen von Cubes, die in den Microsoft-Modellierungswerkzeugen (Business Intelligence Development Studio) durch einfaches An-/Abwählen von Objekten innerhalb eines Cubes (Measures, Measure Groups, Dimensionen, Hierarchien, Ebenen, Attribute) erzeugt werden. In Analogie zu der Paarung “SQL-View versus physikalische Tabelle” sind Perspectives virtuelle Ausschnitte aus Cubes und werden BI-Clients ebenfalls wie Würfel präsentiert.
Sollen also Daten aus mehreren Cubes miteinander verknüpft werden, muss diese Verknüpfung im Frontend stattfinden. Das verlagert einen Teil der Komplexität vom Server zum Client, erhöht den Netzwerktraffic und ist daher aus konzeptioneller Sicht wie auch aus Performancesicht suboptimal. DeltaMaster erlaubt darum zwar die Verwendung mehrerer Cubes innerhalb einer einzigen Analysesitzung, beschränkt jedoch ganz bewusst die Arbeit innerhalb eines Cockpits bzw. einer Analyse auf einen Quellcube, so dass die Zusammenführung von Daten aus unterschiedlichen Cubes lediglich in Form von Kombicockpits oder aber innerhalb eines Berichtsordners möglich ist. Diese Limitation wird von den meisten Anwendern negativ beurteilt werden. Aus dieser Hinsicht spricht also alles für die Verwendung eines einzigen Cubes, der dem Frontend als Gesamtsicht übertragen wird.
Was passiert bei der Verknüpfung von Daten unterschiedlicher Dimensionalität und/oder Granularität?
Grundsätzlich existieren hierzu zwei unterschiedliche Strategien: Der traditionelle Ansatz übernimmt Daten per Formel (Rule) aus Quellwürfeln in einen Zielwürfel. In einem derartigen System würden also so viele Basiswürfel modelliert, wie Kennzahlen unterschiedlicher Dimensionalität/Granularität existieren, und ein oder mehrere Analysewürfel nehmen Informationen via Rechenregeln aus den Basiswürfeln auf.
Microsofts Philosophie besteht seit Analysis Services 2000 darin, neben (Basis-)Cubes unter dem Namen “virtuelle Cubes” ein zweites Konstrukt anzubieten, das eine Obermenge über alle ausgewählten Quellobjekte (Cubes und deren Measures und Dimensionen) bildet, wobei serverseitig automatisch dafür gesorgt wird, dass ungültige Kombinationen (z. B. der Aufriss einer Measure aus Basiscube A nach einer Dimension, die nur in Basiscube B enthalten ist) keine Fehler oder falschen Ergebnisse verursachen, sondern wahlweise entweder die Gesamtsumme oder keine Werte angezeigt werden (“IgnoreUnrelatedDimensions”-Eigenschaft).
Dieses Konzept wurde in Analysis Services 2005 verworfen. Der frühere Cube, der Begriff für den primären OLAP-Datenspeicher für alle gleichartigen Objekte, heisst seitdem MeasureGroup, und ein Cube mit mindestens einer MeasureGroup entsteht im Modellierungsprozess automatisch. Die Notwendigkeit der nachträglichen manuellen Erstellung einer Gesamtsicht in Form eines virtuellen Cubes entfällt also. Es ist zu vermuten, dass diese Umkehrung der Denkweise aus der Einsicht resultiert, dass in der Mehrzahl der Fälle eine solche Gesamtbetrachtung wünschenswert ist. Auch im “neuen” (Gesamt-)Cube erfolgt die Verknüpfung aller in den beinhalteten Measure Groups enthaltenen Measures im Bedarfsfall automatisch entlang der gemeinsamen Achsen.
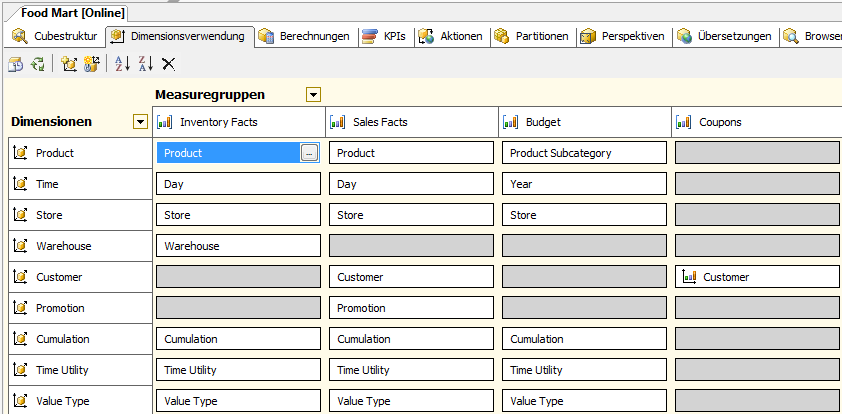
Die “Dimension-Measure-Matrix” zeigt die Verwendung der existierenden Dimensionen (Zeilen) in den einzelnen Measure Groups (Spalten) des Cubes. Die Granularität wird im Kreuzungspunkt durch den Namen des verwendeten Dimensionsattributs visualisiert (z. B. Product in Inventory Facts und Sales Facts, aber Product Subcategory im Budget).
Die Integration von Informationen ist in der Variante der Kombination von MeasureGroups in einem gemeinsamen Cube also per se gegeben. Umgekehrt können Informationen, die in getrennten Cubes gespeichert sind, über das Konzept der Linked Measure Groups in andere Cubes übernommen werden. Eine weitere Alternative stellt der LookupCube-Befehl in MDX dar.
Administrative Aspekte
Die physikalische Speicherung der (Bewegungs-)Daten erfolgt pro Measure Group, genau gesagt pro Measure Group in einer oder mehrerer Partitionen. Jede Partition hat ihren eigenen Speicherentwurf (MOLAP, ROLAP oder diverse hybride Zwischenstufen), und für jede Partition können optional individuelle Aggregationsentwürfe erstellt werden, die aus den Basisdaten in frei definierbarem Umfang (Zwischen-)Summen entlang der existierenden Attributkombinationen vorberechnen. Dieses Prinzip gilt unabhängig von der Entscheidung über die Speicherung der Daten in einem gemeinsamen oder separaten Cube. Dennoch empfiehlt Microsoft im Analysis Services Performance Guide, die Anzahl der Measure Groups pro Cube zu beschränken, gibt dabei jedoch keine allgemeingültige Obergrenze an.
Performancemessungen zeigen klare Vorteile bei Einzelcubes. Dieser Effekt resultiert vornehmlich aus der dabei entstehenden Speicherplatzersparnis (die jeweiligen Kennzahlen müssen nur entlang ihrer eigenen Achsen gespeichert werden) und ist erwartungsgemäß besonders stark, wenn die betroffenen Measure Groups nur wenige gemeinsame und gleichzeitig viele zusätzliche individuelle Merkmale haben. Dieses Szenario ist nach unseren Erfahrungen in der Praxis eher selten anzutreffen: Realistisch ist ein hoher Merkmalsüberschneidungsgrad der einzelnen Measure Groups, denn typische Merkmale wie Zeit, Wertart, Mandant oder Artikel stehen meist in Verbindung zu nahezu jeder Kennzahl.
Hinsichtlich der Pflege von Benutzerberechtigungen in Rollen sind Measure Groups völlig transparent. Mit anderen Worten: Die Bündelung der Measures in ihre Gruppen ist in den Dialogen zur Rollendefinition nicht sichtbar, und jede Measure kann separat an- oder abgewählt werden. Umgekehrt kann auch die Berechtigungspflege für mehrere Cubes innerhalb einer Rolle erfolgen. Der Berechtigungsaspekt ist demnach in Bezug auf die Entscheidung für einen oder mehrere Cubes neutral.
Die Administration von (MDX-)Skripten/Formeln kann bei der Aufteilung auf mehrere Cubes zu Redundanz und Mehrfachpflegeaufwand führen. Dieser Nachteil ist nicht ausschließlich theoretischer Natur: Beispielsweise serverseitige Skripte für Zeitanalyseelemente (Kumulation etc.) sind pro Cube zu pflegen, und bei Änderungen ist eine manuelle Synchronisierung erforderlich.
Zusammenfassung und Empfehlung
Aus unserer Erfahrung sind die Vorteile eines Single Cubes meist gewichtiger als etwaige Nachteile hinsichtlich Performance und/oder Administration:
- Alle Inhalte der OLAP-Datenbank sind dem Anwender im Frontend ohne manuelle Nacharbeit und ohne funktionale Restriktionen aus einem Quellobjekt zugänglich.
- Der Server sorgt für korrekte Ergebnisse im Falle der Kombination von Measures und Dimensionen ohne gemeinsamen Kontext in Abfragen und Rechenformeln.
- Sämtliche erforderlichen Verknüpfungen finden im Backend statt.
- Berechnungen und Skripte sind nur einmalig zu pflegen.
