Die Verwendung der von DeltaMaster ETL unterstützten „Enterprise Architecture“ bietet einige Vorteile – Darunter eine übersichtlichere Struktur, gezielteres Backup bzw. Logging sowie ein präziseres relationales Berechtigungskonzept. Gerade in langjährigen, produktiven Umgebungen findet man jedoch häufig noch eine monolithische Architektur vor, d. h. das komplette relationale Data Warehouse besteht aus lediglich einer Datenbank. Dieser Blogbeitrag soll einerseits darlegen, wie die Enterprise Architecture grundsätzlich funktioniert und wie DeltaMaster ETL diese unterstützt. Andererseits soll ein Transformationspfad aufgezeigt werden, wie man eine bestehende monolithische Architektur Schritt für Schritt in eine Enterprise Architecture überführen kann. Zuletzt geht der Blogbeitrag noch auf einige Spezialfälle ein, die es beim Umbau zu berücksichtigen gilt. Der beschriebene Funktionsumfang bezieht sich auf die Version 6.3.2 von DeltaMaster ETL.
Nutzen und Struktur der Enterprise Architecture
In den meisten historisch gewachsenen Projektumgebungen findet man eine monolithische Architektur vor. Das bedeutet, dass das komplette relationale Data Warehouse lediglich aus einer Datenbank besteht. Während dies nach wie vor gut funktioniert, bietet ein aktueller architektonischer Ansatz – die Enterprise Architecture – einige Vorteile. Diese bestehen vor allem aus einer übersichtlicheren Struktur, gezielterem Backup bzw. Logging sowie einem präziseren relationalen Berechtigungskonzept. Grundsätzlicher Gedanke der Enterprise Architecture ist die Aufteilung des relationalen Data Warehouse in mehrere einzelne Datenbanken, die jeweils einem spezifischen Zweck dienen. Um dennoch übergreifende Funktionalität sicherzustellen, arbeiten die Datenbanken mit Synonymen, die jeweils auf notwendige Objekte aus anderen Datenbanken verweisen. Die Bestandteile der Enterprise Architecture werden im Folgenden kurz beschrieben, wobei die Bezeichnungen der Datenbanken lediglich Vorschlagscharakter haben und frei angepasst werden können.
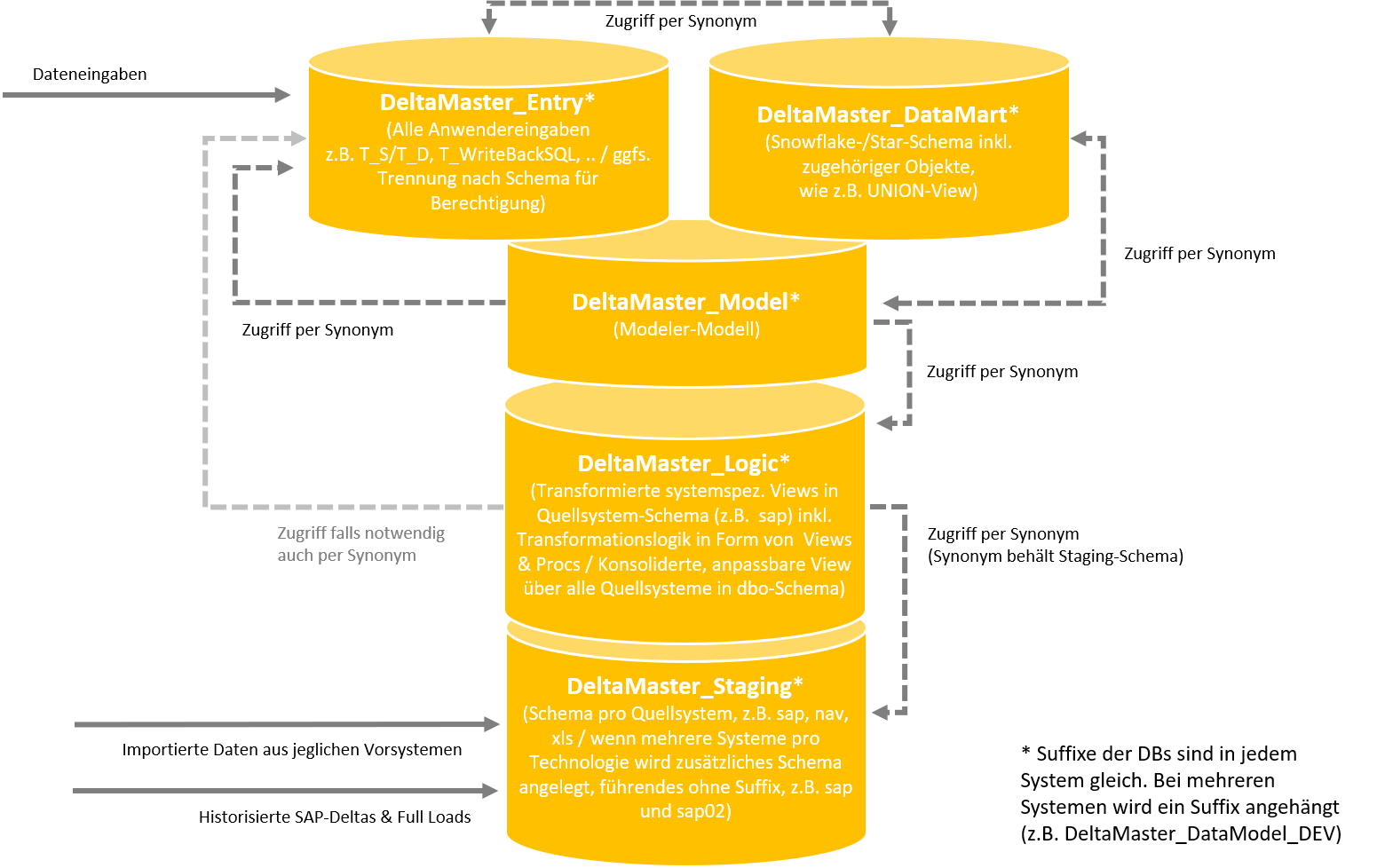
Abbildung 1: Aufbau der DeltaMaster Enterprise Architecture
DeltaMaster_Staging
In der Staging-Datenbank werden Importtabellen aus Vorsystemen (bspw. ERP-System oder *.csv-Dateien) vorgehalten, die i.d.R. nächtlich aktualisiert werden (Nomenklatur: „T_Import_%“). Um zwischen verschiedenen Quellsystemen zu trennen, kann mit abweichenden Datenbank-Schemata gearbeitet werden (bspw. „sap.T_Import_%“ vs. „csv.T_Import_%“). Die Staging-Datenbank verwendet Synonyme üblicherweise, um bspw. beim Import von *.csv-Dateien zu überprüfen, ob die importierten Werte auch wirklich in den Dimensionstabellen vorhanden sind (bspw. Perioden, Kunden oder Artikel). In diesem Fall werden Tabellen aus der DataMart-Datenbank in der Staging-Datenbank als Synonym hinterlegt. Darüber hinaus gibt es noch verschiedene von DeltaMaster ETL automatisch angelegte Synonyme.
DeltaMaster_Logic
In der Logic-Datenbank findet die Umformung und Harmonisierung der importierten Daten aus den Vorsystemen statt. Die Objekte in dieser Datenbank sind hauptsächlich Views, die der Nomenklatur „V_Import_%“ folgen. Auch materialisierte Views („TMV_Import_%“) werden hier angelegt. In der Logic-Datenbank werden Synonyme auf die Importtabellen aus der Staging-Datenbank benötigt. Auch Synonyme auf Strukturtabellen bzw. Views aus der Entry-Datenbank sind ggf. erforderlich. Um eine bessere Strukturierung der Synonyme vorzunehmen, erlaubt DeltaMaster ETL auch hier die Verwendung von verschiedenen Schemata. Dabei kann ein Quellschema bspw. in ein Zielschema überführt werden. Die sich daraus ergebenden Strukturierungsmöglichkeiten werden in den Bissantz ERP Solutions bereits automatisiert mitgeliefert. So wird bspw. im Fall von SAP die mitgelieferte View sap.V_Import_KNA1 in der Staging-Datenbank in die View sap.V_Import_DIM_Customer_Base auf der Logic-Datenbank überführt. Um mehrere Quellsysteme sowie weitere Individualisierungsmöglichkeiten zu erlauben, gibt es darüber hinaus die View dbo.V_Import_DIM_Customer auf der Logic-Datenbank, welche die verschiedenen Kunden-Dimensions-Views zusammenführt.
DeltaMaster_DataMart
Die DataMart-Datenbank beherbergt vornehmlich die Objekte, die im Rahmen des Create Relational Schema erzeugt werden, also Dimensions- und Faktentabellen („T_DIM_%“ und „T_FACT_%“) sowie Views auf diese. Darüber hinaus befinden sich dort im Falle der Verwendung eines relationalen Berechtigungskonzepts die Views zur Berechtigung für SQL-Durchgriffe, sie folgen der Nomenklatur „V_SEC_FACT_%“. In dieser Datenbank gilt es aufgrund der Möglichkeit von SQL-Durchgriffen auch, Endanwender relational zu berechtigen, eine Rechtevergabe auf anderen Datenbanken der Enterprise Architecture ist für Endanwender i.d.R. nicht erforderlich. Manuell angelegte Synonyme werden in dieser Datenbank in der Regel nicht benötigt, es gibt jedoch einige automatisiert angelegte Synonyme, die auf die Model-Datenbank verweisen.
DeltaMaster_Entry
Die Entry-Datenbank hat das Ziel, Planungseingaben sowie händische Ergänzungen zu den Quellsystemen bzgl. Stammdaten und Strukturinformationen zu verwalten. Dort befinden sich üblicherweise Strukturtabellen („T_S_%“) bzw. manuelle Datentabellen („T_D_%“) sowie Views auf diese. Auch sämtliche Objekte, die mit der Hybridplanung zusammenhängen („T_WriteBackSQL_%“, „P_WriteBackSQL_%“ etc.), sind hier zu finden. Im Fall von relationalen Pflegeanwendungen können auch Objekte für relationale Eingabeanwendungen („P_Insert_%“, „P_Update_%“, „P_Delete_%“) hier gefunden werden. Synonyme werden in dieser Datenbank bspw. benötigt, um Selektionsprozeduren auf Dimensionselemente zu realisieren, daher könnten die „T_Import_%“-Objekte als Synonyme hier angelegt werden. Auch die CustomApp wird in der Entry-Datenbank verwendet, da relationale Pflegeanwendungen i.d.R. hierauf zugreifen. Damit sind auch alle mit der CustomApp verbundenen Objekte (Tabellen, Views, Prozeduren) als Synonym zu hinterlegen. Wie in den anderen Datenbanken auch, werden zusätzlich automatisiert von DeltaMaster ETL benötigte Synonyme angelegt.
DeltaMaster_Model
Hier ist das Modell zentral definiert. Die ETL-Analysesitzung greift auf diese Datenbank zu, da sich dort das Metamodell befindet. Auch die Prozeduren zur Befüllung der Dimensions- und Faktentabellen befinden sich hier („P_Transform_%“). Da einige Stränge hier zusammenlaufen, sind häufig auch mehrere Synonyme notwendig. Im einfachsten Fall benötigt die Model-Datenbank die Import-Views und TMVs der Logic-Datenbank, da diese zur Befüllung der DataMart-Datenbank verwendet werden.
Unterstützung bei der Anlage durch DeltaMaster ETL
Um zunächst zu verstehen, wie die Enterprise Architecture in DeltaMaster ETL parametrisiert wird, richten wir den Blick auf die relevanten Eingabeberichte in der Sitzung „DeltaMaster ETL.das“. In Version 6.3.2 befinden sich die relevanten Berichte im Ordner „Set Parameters“:

Abbildung 2: Relevante Berichte in der Analysesitzung DeltaMaster ETL
Im Bericht „Writeback Parameters“ kann die Entry-Datenbank angegeben werden. Auch Einstellungen bzgl. der Planung (bspw. Splash Limit) lassen sich hier vornehmen. Der Bericht „Application Parameters“ erlaubt die Spezifikation der Logic-Datenbank, im Bericht „Relational Object Parameters“ wird die DataMart-Datenbank hinterlegt und der Bericht „Import Parameters“ wird zum Festlegen der Staging-Datenbank verwendet. An dieser Stelle sei noch erwähnt, dass die Enterprise Architecture keinesfalls immer aus allen diesen Datenbanken bestehen muss – vielmehr kann projekt- und umgebungsspezifisch eine Auswahl getroffen werden, welche Datenbanken separat geführt werden sollen.
Verwaltung von Synonymen
Um die mögliche Vielzahl an Synonymen zu verwalten und um sicherzustellen, dass auch für neue Objekte entsprechende Synonyme angelegt werden, gibt es in der zentralen DeltaMaster-ETL-Analysesitzung den Bericht „Custom Synonyms“ (Define Model -> Advanced Modeling). Dort können der Namensraum für anzulegende Synonyme sowie Ziel- und Quelldatenbanken hinterlegt werden. Die Synonyme werden entsprechend der dort hinterlegten Regeln mit dem Ausführen der Prozedur „P_Model_CreateCustomSynonyms“ angelegt. Dies passiert automatisch im Rahmen des Create Relational Schema (auch inkrementell). Um die initiale Erzeugung von Synonymen zu vereinfachen, wird mit DeltaMaster ETL die Solution „DeltaMaster ETL Enterprise Architecture Synonyms“ ausgeliefert. Diese legt die üblicherweise erforderlichen Synonyme automatisch an, welche anschließend im Bericht „Custom Synonyms“ erweitert bzw. angepasst werden können.
Mit diesem Vorwissen wird im nächsten Abschnitt ein Vorgehen erläutert, mit dem eine monolithische Struktur Schritt für Schritt in eine Enterprise Architecture überführt werden kann.
Erforderliche Schritte beim Umbau einer monolithischen Struktur zur Enterprise Architecture
Im Folgenden wird von einem Szenario ausgegangen, in dem es eine einzige bestehende Datenbank für das relationale Data Warehouse gibt. Im Falle von mehreren Umgebungen (Entwicklungs-, Test- und Produktivumgebung) sind die Schritte entsprechend auf jeder Umgebung durchzuführen. Es empfiehlt sich dringend, vor einem entsprechenden Umbau eine Sicherung des relationalen Data Warehouse vorzunehmen. Bei den hier beschriebenen Schritten handelt es sich lediglich um einen Leitfaden, der von Bezeichnungen ausgeht, die dem ETL-Standard entsprechen und nicht sämtliche Spezialfälle in historisch gewachsenen Systemen abbilden kann. Ein Überblick über die grundsätzlichen Schritte wird in Abbildung 3 vermittelt.
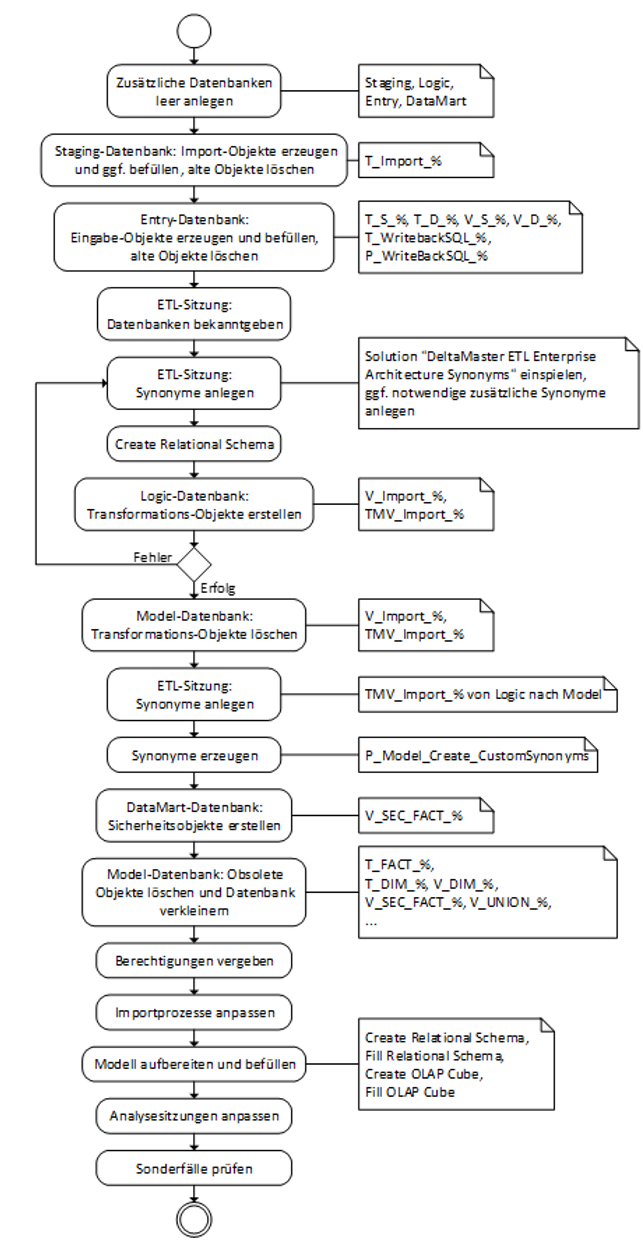
Abbildung 3: Ablauf bei der Umstellung
Zusätzliche Datenbanken leer anlegen
Ausgangspunkt für die Model-Datenbank bleibt die bisher verwendete zentrale Datenbank. Alle zusätzlich notwendigen Datenbanken (Staging, Logic, Entry, DataMart) werden in einem ersten Schritt leer angelegt. Als Wiederherstellungsmodell empfiehlt sich „Einfach“, in der Entry-Datenbank ggf. „Vollständig“, um Nutzereingaben gesondert abzusichern.
Import-Objekte per Skript in Staging-Datenbank erzeugen
Per Rechtsklick auf die bisherige Datenbank kann über „Tasks -> Skripts generieren…“ eine Auswahl an Objekten getroffen werden, die für die Staging-Datenbank relevant sind (typischerweise „T_Import_%“). Wahlweise können diese auch mitsamt Daten exportiert werden (Dialog „Erweitert“, Option „Schema und Daten“):
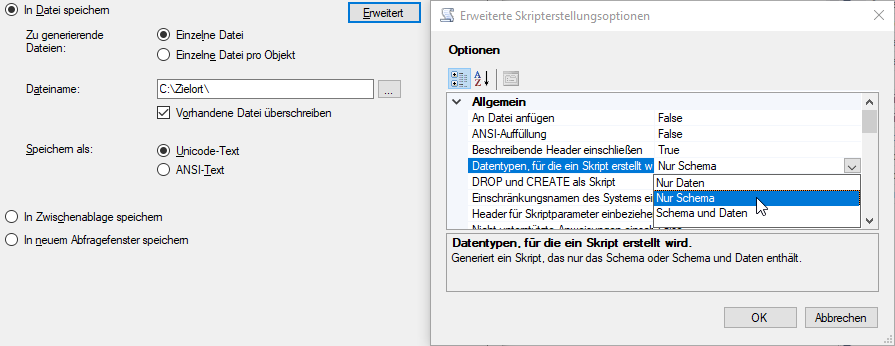
Abbildung 4: Skripts für relevante Objekte erstellen
Da die Befüllung durch ein in der Regel bereits vorhandenes SSIS-Paket später ohnehin noch zu testen ist, empfiehlt es sich jedoch, nur das Schema zu exportieren. Das erzeugte Skript wird dann auf der Staging-Datenbank ausgeführt, um die Objekte dort zu erstellen. Hier gilt es zu beachten, dass bei der Skripterstellung der Datenbankname mit exportiert wird, dieser muss vor dem Ausführen auf der Zieldatenbank angepasst werden. Soll die Struktur mitsamt Daten auf der Staging-Datenbank erstellt werden, ist eine weitere Möglichkeit, einen Datenfluss über die Funktion „Daten importieren…“ anzulegen. Hierzu kann per Rechtsklick auf die Staging-Datenbank im Bereich „Tasks -> Daten importieren…“ als Quelle die bisherige Datenbank und als Ziel die Staging-Datenbank ausgewählt werden. Wurden die Importtabellen erfolgreich angelegt und befüllt, sollten diese aus der bisherigen Datenbank gelöscht werden.
Struktur- und Planungsobjekte in Entry-Datenbank erzeugen
Analog zu Schritt 4.2 gilt es, Struktur- bzw. Datentabellen („T_S_%“, „T_D_%“) und deren Views sowie Planungsobjekte („T_WriteBackSQL_%“,“P_WriteBackSQL_%“) in der Entry-Datenbank zu erzeugen und zu befüllen. Da insbesondere Strukturtabellen i.d.R. weniger umfangreich sind, kann hier die Option „Schema und Daten“ bei der Skripterstellung verwendet oder erneut auf den Task „Daten importieren…“ zurückgegriffen werden. Planungsobjekte können alternativ nach Bekanntgabe der Entry-Datenbank in der Analysesitzung DeltaMaster ETL mit einem Create Relational Schema erzeugt werden. Anschließend gilt es, diese mit den bestehenden Daten zu befüllen und ggf. angepasste Objekte (bspw. Pre- oder PostProcess-Prozeduren) zu ersetzen. Eine Besonderheit gibt es bei Strukturtabellen zu berücksichtigen: Die Standard-Tabellen T_S_Periode, T_S_Wertart, T_S_Kumulation sowie sämtliche ausschließlich von DeltaMaster ETL verwendete Strukturtabellen (bspw. T_S_Dummy_Content, T_S_TRL_StandardContent usw.) werden von DeltaMaster ETL auf der Model-Datenbank angelegt und auch dort ggf. neu erzeugt/befüllt. Daher sollten diese nicht in die Entry-Datenbank verschoben werden, auch wenn es sich um Strukturtabellen handelt. Wurden die Planungsobjekte und Strukturtabellen erfolgreich angelegt und befüllt, sollten diese aus der bisherigen Datenbank gelöscht werden.
Anpassen der Parameter in der Analysesitzung DeltaMaster ETL
Da für die weiteren Schritte bereits Synonyme notwendig sind, gilt es, in der DeltaMaster-ETL-Analysesitzung die anderen Datenbanken bekanntzugeben (siehe Abschnitt 2). Außerdem müssen einige Synonyme angelegt werden (siehe Abschnitt 3), um weitere Arbeiten durchführen zu können. Hierbei kann die bereits erwähnte Solution „DeltaMaster ETL Enterprise Architecture Synonyms“ zum Einsatz kommen. Nach der Installation der Solution gibt es folgende Synonyme im Bericht „Custom Synonyms“:
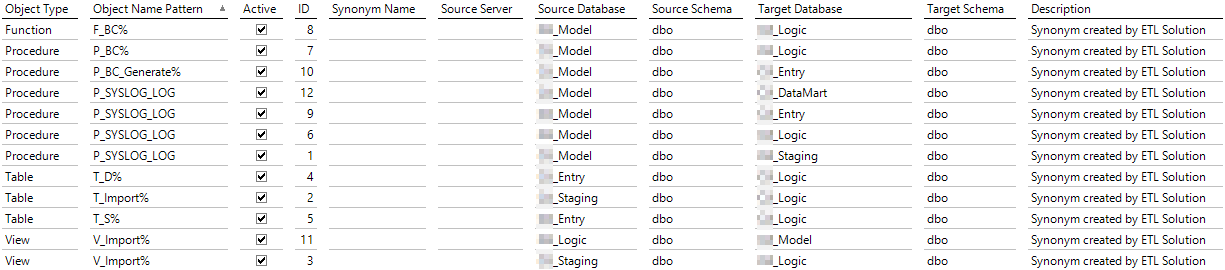
Abbildung 5: Synonyme nach Installation von „DeltaMaster ETL Enterprise Architecture Synonyms“
Um die Logic-Datenbank befüllen zu können, benötigen wir dort Synonyme auf die „T_Import_%“-Tabellen der Staging-Datenbank. Je nach Modell kann es außerdem sein, dass Strukturtabellen aus der Entry-Datenbank in der Logic-Datenbank benötigt werden. Beides wurde bereits durch die Solution berücksichtigt. Anschließend gilt es, mithilfe von DeltaMaster ETL.exe das relationale Schema neu aufzubereiten (Create Relational Schema). Es gibt nun ausreichend Synonyme, um die Logic-Datenbank mit ihren Views zu befüllen.
Logic-Datenbank mit (materialisierten) Views befüllen
Analog zu Schritt 4.2 kann nun ein Skript für die Logic-Objekte („V_Import_Dim_%“, „V_Import_Fact_%“, „TMV_Import_Fact_%“) erstellt werden. Diese Objekte gilt es auf der Logic-Datenbank wiederherzustellen. Sollte es in diesem Schritt zu Fehlermeldungen kommen, müssen in aller Regel Synonyme hinzugefügt werden (vgl. Schritt 4.4). Um lediglich Synonyme neu zu erzeugen, kann die Prozedur „P_Model_Create_CustomSynonyms“ auch einzeln ausgeführt werden.
Quell-Views in Model-Datenbank austauschen
In diesem Schritt werden nun die eigentlich in der Model-Datenbank (das ist die bisherige zentrale Datenbank) vorhandenen Import-Views und materialisierte Import-Views durch Synonyme auf die Logic-Datenbank ersetzt. Hierfür gilt es, die Import-Views („V_Import_%“) und die materialisierten Import-Views („TMV_Import_%“) aus der Model-Datenbank zu löschen. Anschließend müssen die Synonyme für die „V_Import_%“- bzw. „TMV_Import_%“-Objekte angelegt werden. Die „V_Import_%“-Objekte wurden bereits durch die Solution „DeltaMaster ETL Enterprise Architecture Synonyms“ angelegt. Falls auch „TMV_Import_%“-Objekte vorhanden sind, gilt es, diese im Bericht Custom Synonyms zu ergänzen. In jedem Fall müssen die Synonyme nun erzeugt werden, bspw. per Prozeduraufruf von „P_Model_Create_CustomSynonyms“. Zur Kontrolle kann in ETL-Berichten mit Quellspalten (bspw. Level Source Columns) nachgesehen werden, ob dort angezeigt wird, dass es sich um Synonyme handelt (Zusatzangabe „Synonym to: <Logic-Datenbank>“):

Abbildung 6: Verweise auf Synonyme in den Quelltabellen
Je nach Modellgröße kann an dieser Stelle ausprobiert werden, ob die üblichen ETL-Schritte bereits funktionieren (Create Relational Schema, Fill Relational Schema, Create OLAP Database, Fill OLAP Database).
V_SEC-Views auf DataMart-Datenbank wiederherstellen
Im Fall eines relationalen Berechtigungskonzepts müssen noch die „V_SEC_%“-Views der vorherigen zentralen Datenbank in der DataMart-Datenbank wiederhergestellt werden (analog zu Schritt 4.2). Da diese sich i.d.R. auf Berechtigungstabellen in der Entry-Datenbank beziehen, gilt es ggf., Custom Synonyms für diese Tabellen von der Entry-Datenbank in die DataMart-Datenbank zu erstellen (Anlage im Bericht „Custom Synonyms“ und Ausführen der Prozedur „P_Model_Create_CustomSynonyms“).
Nicht mehr benötigte Objekte aus Model-Datenbank löschen
Um die Model-Datenbank auf die minimal notwendige Größe zu verkleinern, müssen nun die restlichen nicht mehr benötigten Objekte aus dieser gelöscht werden. Dies sind insbesondere relational aufbereitete Dimensions- und Faktentabellen sowie deren Views („T_DIM_%“, „T_FACT_%“, “V_DIM_%“, “V_FACT_%“, “V_UNION_%“, “V_SEC_%“). Nachdem die Objekte gelöscht wurden, sollte die Datenbank entsprechend verkleinert werden (Tasks -> Verkleinern -> Datenbank). Damit wird auch physisch der nicht mehr verwendete Speicherplatz freigegeben.
Benutzer hinzufügen und Berechtigungen anpassen
Auf den neu erstellten Datenbanken (sowie auch auf der Model-Datenbank) gilt es, die Berechtigungen entsprechend anzupassen. Endanwender, die per SQL-Durchgriff auf die relationale Datenbank zugreifen sowie der Service-User für den Webclient sollten entsprechend auf die DataMart-Datenbank berechtigt werden. Dafür gilt es, diese zunächst als Benutzer hinzuzufügen und anschließend einer passenden Rolle zuzuweisen. Für Nutzer, die außerdem Stammdaten pflegen bzw. planen können sollen, sind entsprechende Berechtigungen auf der Entry-Datenbank zu vergeben. Bislang vergebene Berechtigungen für diese Nutzergruppen auf der Model-Datenbank können grundsätzlich entfernt werden. In der Logic- und Staging-Datenbank müssen keine zusätzlichen Berechtigungen für Endanwender vergeben werden.
Importprozesse anpassen (bspw. SSIS-Pakete)
Bestehende Importprozesse müssen an die neuen Datenbanken angepasst werden. Konkret gilt es, die Zieldatenbank für sämtliche Importprozesse auf die Staging-Datenbank umzustellen. Langfristig kann es sich lohnen, diese im SSIS-Paket dynamisch aus den ETL-Parametern auszulesen, sodass diese Umstellung bei künftigen Anpassungen der Staging-Datenbank nicht mehr erforderlich ist. Hierfür gilt es, folgenden Parameter auszulesen:
SELECT dbo.F_MODELSYS_GetParameter(610)
Analysesitzungen anpassen
Wenn Analysesitzungen das relationale Modell angebunden haben, müssen diese im Wartungsdialog geöffnet werden und die Verbindungszeichenfolge auf die DataMart-Datenbank (im Fall von In-Memory-Hybridplanung: Entry-Datenbank) umgestellt werden. Wird die Hybridplanung verwendet, gilt es, in den Optionen im Bereich Dateneingabe die Verbindungszeichenfolge für das Rückschreibeverfahren auf die Entry-Datenbank umzustellen.
Sonderfälle
Auch wenn DeltaMaster ETL Anwender bei vielen bestehenden Anwendungen bereits tatkräftig unterstützt, gibt es noch einige Sonderfälle, die es bei der Einrichtung der Enterprise Architecture zu berücksichtigen gilt. Diese sind im Folgenden aufgeführt.
Materialisierung von Views (P_BC_Generate_TMV)
Wird die Prozedur „P_BC_Generate_TMV“ bspw. im Rahmen der Transformation verwendet, muss in der Enterprise Architecture die Logic-Datenbank als Zieldatenbank für das Ergebnis mit angegeben werden. Hintergrund ist, dass die Materialisierungen sonst auf der Model-Datenbank erstellt würden, da sich die Prozedur dort befindet. Der Name der Logic-Datenbank lässt sich hierfür dynamisch aus den Parametern von DeltaMaster ETL auslesen:
DECLARE @DBName varchar(50) = (SELECT dbo.F_MODELSYS_GetParameter(431));
EXEC P_BC_Generate_TMV 'V_Import_Fact_Sales', @DBNameTgt = @DBName;
EXEC P_BC_Generate_TMV 'V_Import_Fact_Production', @DBNameTgt = @DBName;
...CustomApp
Die CustomApp wird nach wie vor in der zentralen Model-Datenbank mithilfe der Analysesitzung DeltaMaster ETL gepflegt. Um diese jedoch auch in Anwendungen auf anderen Datenbanken (üblicherweise der Entry-Datenbank) verwenden zu können, müssen Synonyme auf die CustomApp-Objekte angelegt werden. Die notwendigen Object Name Patterns für die Custom Synonyms lauten:
P_SYS_CustomApp%
T_SYS_CustomApp%
V_SYS_CustomApp%
Als Quelldatenbank ist die Model-Datenbank, als Zieldatenbank die Datenbank anzugeben, auf der die CustomApp zur Verfügung gestellt werden soll (bspw. Entry-Datenbank).
Logging per DDLEvent
Eine sehr praktische Funktion gerade in größeren Umgebungen ist das standardmäßig aktivierte Logging von DDL Events. Dieses läuft auch nach dem Umbau auf die Enterprise Architecture weiter – allerdings auf der Model-Datenbank, wo inhaltlich nicht die wichtigsten DDL-Anpassungen passieren. Stattdessen würde man sich dies bspw. auf der Logic-Datenbank wünschen. Um das sicherzustellen, gilt es, die Tabelle T_SYSLOG_DDLEvent aus der Model-Datenbank in die Logic-Datenbank zu übertragen (Analog zu vielen anderen bereits skizzierten Fällen). Anschließend muss noch ein Datenbank-Trigger erstellt werden, den man sich ebenfalls per Skript von der Model-Datenbank erzeugen lassen kann:
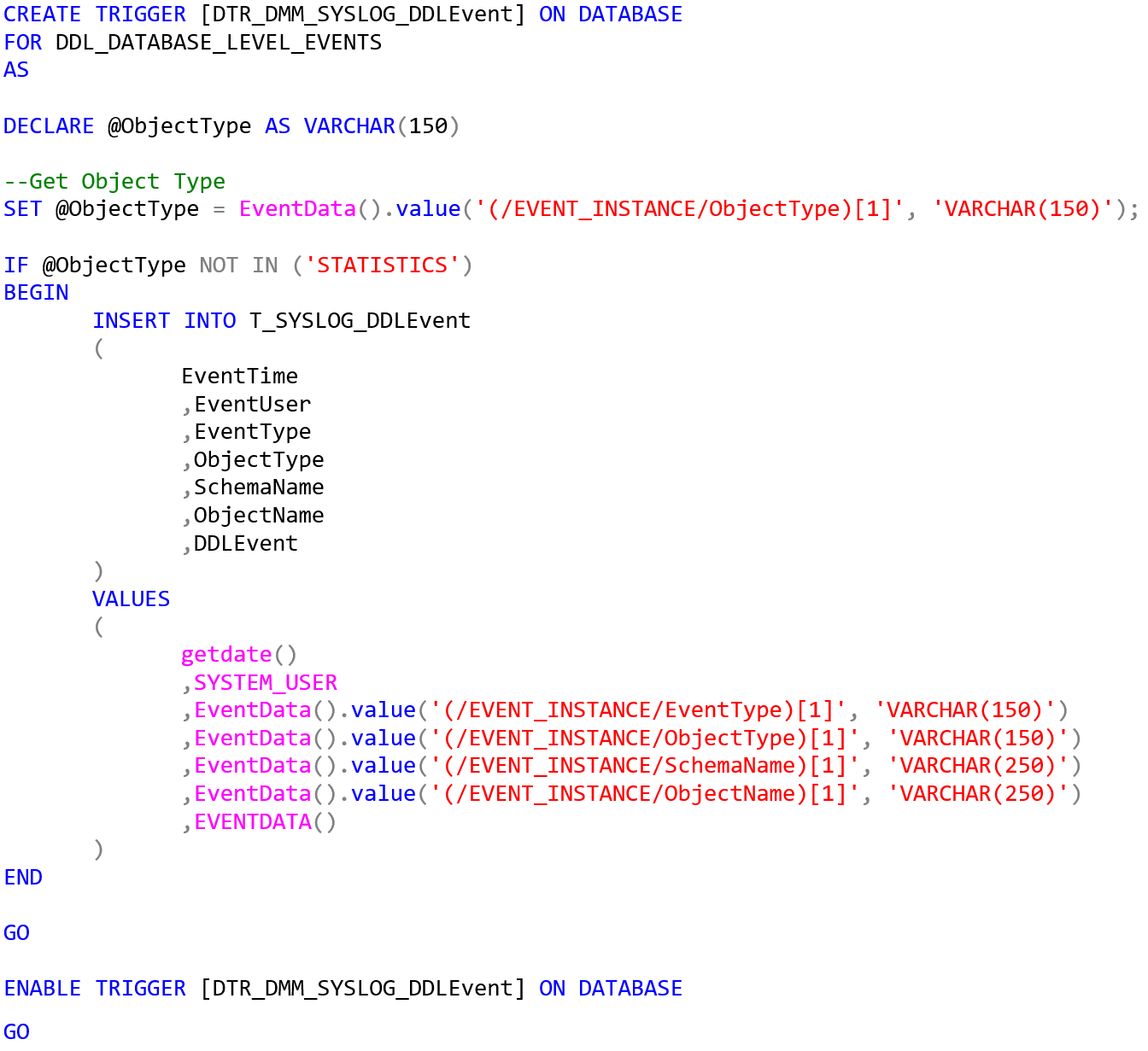
CREATE TRIGGER [DTR_DMM_SYSLOG_DDLEvent] ON DATABASE
FOR DDL_DATABASE_LEVEL_EVENTS
AS
DECLARE @ObjectType AS VARCHAR(150)
--Get Object Type
SET @ObjectType = EventData().value('(/EVENT_INSTANCE/ObjectType)[1]', 'VARCHAR(150)');
IF @ObjectType NOT IN ('STATISTICS')
BEGIN
INSERT INTO T_SYSLOG_DDLEvent
(
EventTime
,EventUser
,EventType
,ObjectType
,SchemaName
,ObjectName
,DDLEvent
)
VALUES
(
getdate()
,SYSTEM_USER
,EventData().value('(/EVENT_INSTANCE/EventType)[1]', 'VARCHAR(150)')
,EventData().value('(/EVENT_INSTANCE/ObjectType)[1]', 'VARCHAR(150)')
,EventData().value('(/EVENT_INSTANCE/SchemaName)[1]', 'VARCHAR(250)')
,EventData().value('(/EVENT_INSTANCE/ObjectName)[1]', 'VARCHAR(250)')
,EVENTDATA()
)
END
GO
ENABLE TRIGGER [DTR_DMM_SYSLOG_DDLEvent] ON DATABASE
GO Wird dieser Trigger auf der Logic-Datenbank erstellt, erfolgt das Logging nun auch dort. Grundsätzlich kann man dieses Vorgehen für jede Datenbank wiederholen, auf der ein DDL Event Logging gewünscht ist.
Backup/Restore Snowflake Schema
Die Funktionalität, den Inhalt der relationalen Tabellen im Data Warehouse abzuspeichern und wiederherzustellen ist mit den Prozeduren „P_BC_Backup_SnowflakeSchema“ und „P_BC_Restore_SnowflakeSchema“ grundsätzlich gegeben. In der Enterprise Architecture funktionieren diese jedoch zurzeit nicht, da sie keine Angabe einer Zieldatenbank (DataMart-Datenbank) zulassen. Es ist geplant, diese Funktionalität in DeltaMaster ETL 6.3.4 zu ergänzen.
Zellkommentare und datenbankgestützte Berichtskommentare
Bei vorhandenen datenbankgestützten Berichtskommentaren sollte die Tabelle für die Berichtskommentare samt Inhalt in die Entry-Datenbank verschoben werden, da es sich hier grundsätzlich um Nutzereingaben handelt. Dabei ist zu berücksichtigen, dass die Nutzer entsprechend auf diese Tabelle berechtigt werden. In den Analysesitzungen muss dann auch die Datenquelle für Berichtskommentare in den Optionen angepasst werden:
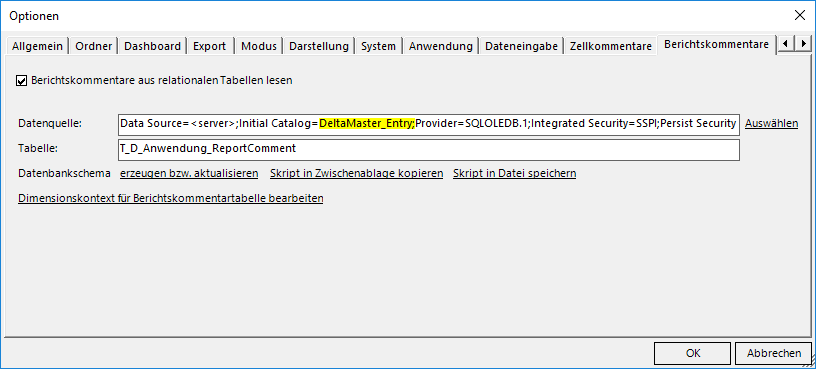
Abbildung 7: Datenquelle für Berichtskommentare anpassen
Bei der Verwendung von Zellkommentaren gilt es ebenfalls, bereits vorhandene Objekte (i.d.R. „T_FACT_%_TEXT“) in die Entry-Datenbank zu verschieben und in Analysesitzungen die Datenbank für Zellkommentare anzupassen:
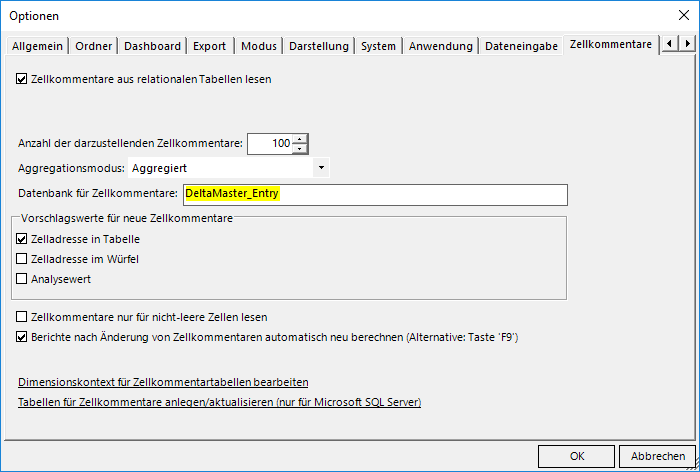
Abbildung 8: Datenquelle für Zellkommentare anpassen
Fazit
Obwohl es sich bei der Umstellung der relationalen Architektur grundsätzlich um eine größere Anpassung der Projektumgebung handelt, zeigt der vorliegende Beitrag, dass dafür nicht zwangsläufig auch großer Aufwand erforderlich ist. Mit dem zur Verfügung gestellten Leitfaden ist sichergestellt, dass man bei einer Umstellung keine grundlegenden Schritte übersieht. Die beschriebenen Sonderfälle ergänzen den Leitfaden, sodass auch speziellere Situationen abgedeckt sind. Es bleibt allerdings anzumerken, dass ein solcher Leitfaden nicht sämtliche möglichen Konstellationen abdecken kann. Das beschriebene Vorgehen wurde bereits in einem Projekt bei einem mittelständischen Unternehmen erfolgreich erprobt. Der Aufwand für die Umstellung belief sich auf weniger als einen Tag, dies hängt jedoch immer von der konkreten Projektumgebung ab. Seit der Umstellung profitiert das Unternehmen von einer übersichtlicheren Struktur, gezielteren Backups sowie einem präziseren relationalen Berechtigungskonzept.
