Dieser Blogbeitrag bietet einen Überblick über die Replikationskomponente des SQL Servers, ein Werkzeug zur Datenverteilung. In der Einführung wird auf das Konzept sowie die unterschiedlichen Formen der Replikation eingegangen. Im Anschluss wird die Konfiguration der Komponente erläutert. Zum Schluss wird die Replikation in der Praxis gezeigt und die Anwendungsgebiete sowie die Vorteile besprochen.
Einführung
Die Replikationsfunktionalität besteht schon seit Längerem in SQL Server. Genauer gesagt, seit der Version SQL Server 7.0, die 1998 erschienen ist. Sie dient der Datenverteilung und ist damit als Alternative zu den teilweise gängigeren Lösungen wie Backup & Restore, SSIS, oder LinkedServer zu sehen. Das Konzept der Replikation besteht aus mehreren Komponenten, die vom Sprachgebrauch her an das Verlagswesen angelehnt sind und folgendermaßen aussehen:
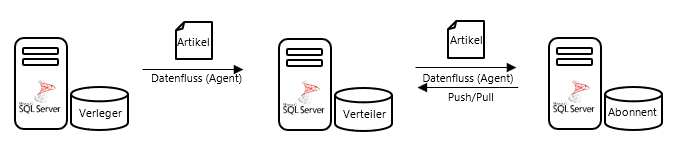 Abbildung 1: Schaubild zum Konzept der Replikation
Abbildung 1: Schaubild zum Konzept der Replikation
Artikel
Artikel sind das Äquivalent zu Datenbankobjekten. Dabei kann der Artikel nicht nur aus einer oder mehreren Tabellen bestehen, sondern auch andere Objekte, wie Sichten und Prozeduren, umfassen.
Verleger (Publisher)
Der Verleger definiert, welche Artikel dem Abonnenten zur Verfügung gestellt werden und legt damit fest, was veröffentlicht werden soll. Eine Veröffentlichung kann dann aus einem oder mehreren Artikeln bestehen.
Verteiler (Distributor)
Der Verteiler ist für den Datenverteilungsprozess zuständig. Hierzu wird extra eine Distributions-Datenbank (Systemdatenbank) auf der Instanz des Verteilers angelegt, die alle notwendigen Datenbankobjekte für die Verteilung der Daten beinhaltet. In der Praxis ist meist der Verleger und der Verteiler auf ein und derselben SQL Server Instanz angelegt. Im Schaubild wird dagegen die ausführliche Variante veranschaulicht, in der Verleger und Verteiler auf separaten Instanzen liegen.
Abonnent (Subscriber)
Der Abonnent kann über die Replikation von einem oder mehreren Verlegern eine oder mehrere Veröffentlichungen beziehen. Das Abonnement kann dabei im Push- oder Pull-Verfahren zur Verfügung gestellt werden. Somit kann der Abonnent entweder selbst beim Verteiler bzgl. aktualisierter Veröffentlichungen anfragen oder diese werden vom Verteiler dem Abonnenten automatisch in gewissen Abständen zur Verfügung gestellt.
Veröffentlichungstypen
Die Replikation der Daten kann auf unterschiedliche Weise konfiguriert werden. Zur Auswahl stehen dabei vier verschiedene Veröffentlichungstypen:
- Momentaufnahmeveröffentlichung: Bei dieser Variante wird von der gesamten Veröffentlichung ein Snapshot (Momentaufnahme) angefertigt und dieser an die Abonnenten verteilt. Da hier immer alle Daten verteilt werden, ist diese Art der Veröffentlichung nur zu empfehlen, wenn sich die Daten selten ändern. Sonst wäre es unter dem Aspekt des Datentraffic bzw. der Performance als suboptimal zu sehen.
- Transaktionsveröffentlichung: Bei dieser Variante wird initial ebenfalls ein Snapshot der Daten verteilt. Anschließend werden jedoch alle Änderungen in Transaktionen festgehalten, die dann an den Abonnenten verteilt werden und die Datenbankobjekte aktualisieren. Da diese Transaktionen einen deutlich geringeren Datentraffic verursachen (sie enthalten nur die jeweiligen Änderungen), bietet sich diese Variante in sehr vielen Szenarien an. Gerade auch dann, wenn die Verbindung zu den Abonnenten über eine geringe Bandbreite verfügt.
- Mergeveröffentlichung: Anders als bei den zuvor erläuterten Veröffentlichungstypen, können bei der Mergeveröffentlichung Änderungen auf beiden Seiten (Verleger und Abonnent) vorgenommen werden. Wenn beide Parteien die gleichen Daten ändern, wird der Konflikt entweder über vordefinierte SQL Serverlösungen oder über benutzerdefinierte Konfliktlösungen geheilt.
- Peer-to-Peer-Veröffentlichung: Diese Variante geht, wie die Transaktionsveröffentlichung, transaktional vor und repliziert nur die Änderungen. Hier jedoch an mehrere Knoten gleichzeitig. Dies erhöht die Verfügbarkeit der Daten, bei gleichzeitiger Redundanz in der Datenhaltung. Es gibt zudem spezielle Anforderungen an das Tabellendesign. Benötigt wird, im Gegensatz zu den anderen Varianten, eine Enterprise-Lizenz.
Einrichtung
Replikationsinstallation
Bevor mit der eigentlichen Einrichtung der Replikation begonnen wird, müssen noch ein paar Dinge beachtet werden. Denn obwohl die Replikation via SQL Server Management Studio im SQL Server bereits aufgeführt wird, kann es durchaus sein, dass man beim Starten der Konfiguration zunächst mit folgendem Hinweis konfrontiert wird:
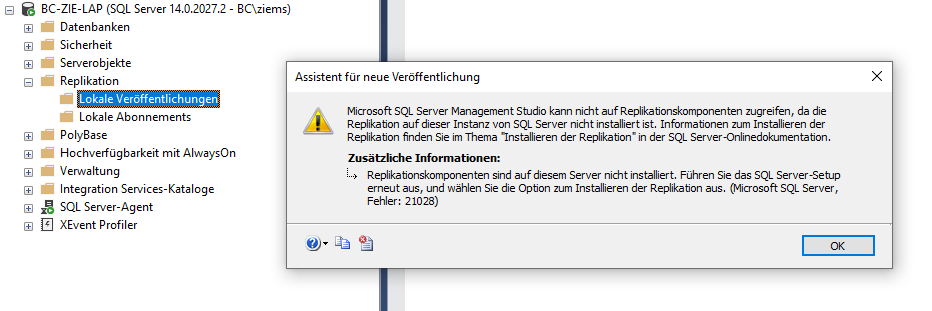
Abbildung 2: Hinweismeldung bei Starten der Replikationskonfiguration
Die Replikationskomponente kann nämlich trotz in Erscheinung treten im Replikationsordner noch nicht auf der SQL Server Instanz installiert sein. Um dies nachzuholen, muss im SQL Server Installationscenter die Replikationskomponente nachinstalliert werden. Hierbei kommt es meist zum nächsten Fallstrick. Denn beim Klicken auf „Neue eigenständige SQL Server-Installation oder Hinzufügen von Funktionen zu einer vorhandenen Installation“ muss der Pfad für das Installationsmedium angeben werden.
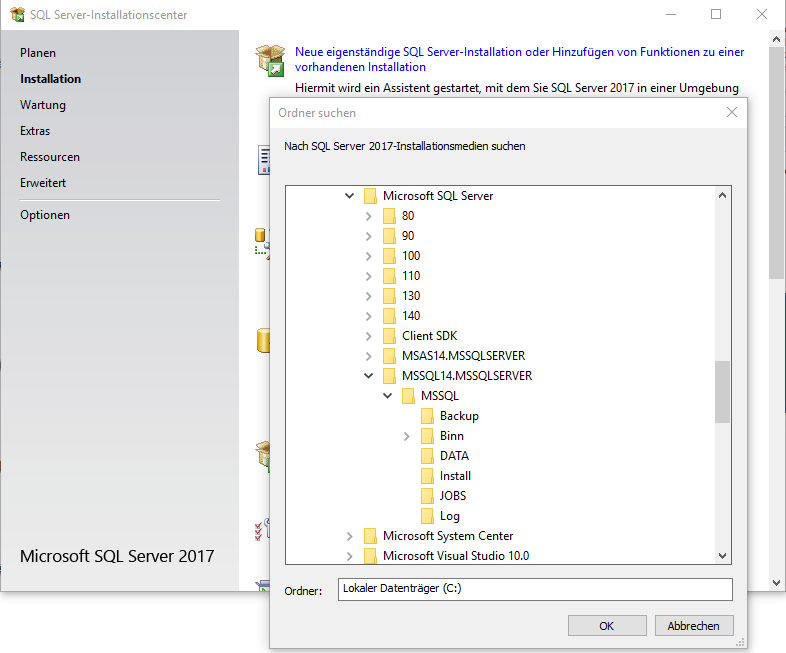
Abbildung 3: Angabe des SQL Server Installationsmediums im SQL Server Installationscenters
Sollte man hierbei den richtigen Pfad finden, in dem die Setup.exe liegt, wird höchstwahrscheinlich dennoch folgender Fehler ausgegeben, der die weitere Installation verhindert.
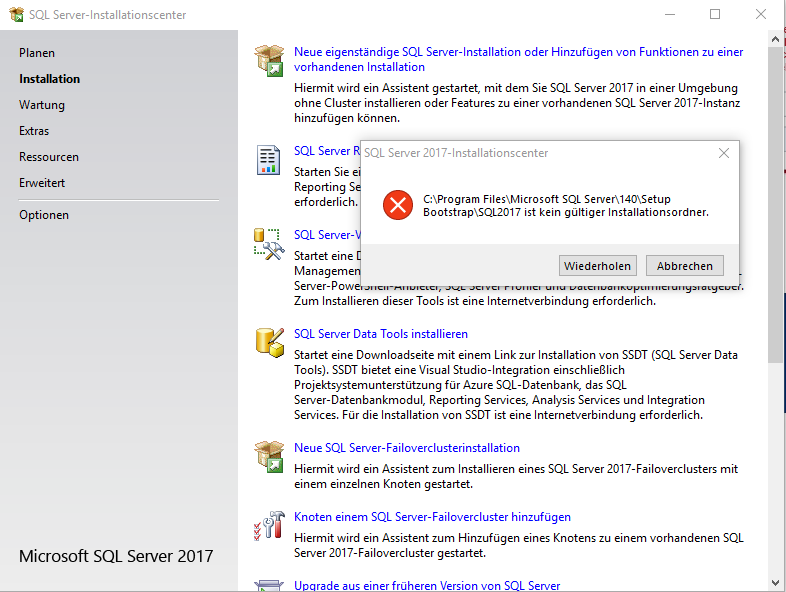
Abbildung 4: Fehlermeldung bei der Angabe des richtigen Installationsmedium-Pfads
Um diese Problematik zu umgehen empfiehlt es sich, die Nachinstallation über die ISO-Datei durch-zuführen oder sich aus der ISO-Datei die „MediaInfo.xml“ in den Setup.exe Ordner im Programmverzeichnis zu kopieren und die Installation über das SQL Sever Installationscenter nochmals zu starten.
Abbildung 5: Benötigte MediaInfo.xml-Datei für die Nachinstallation
Sollte der Pfad nach dem zuvor beschriebenen Vorgehen akzeptiert worden sein, kann nun die Nachinstallation der Replikationskomponente durchgeführt werden. Hierzu wählt man unter „Installationstyp“ die Instanz aus, auf der die Replikation installiert werden soll. Anschließend kann man dann die Komponente unter „Funktionsauswahl“ (Haken setzen bei „SQL Server-Replikation“) hinzufügen.
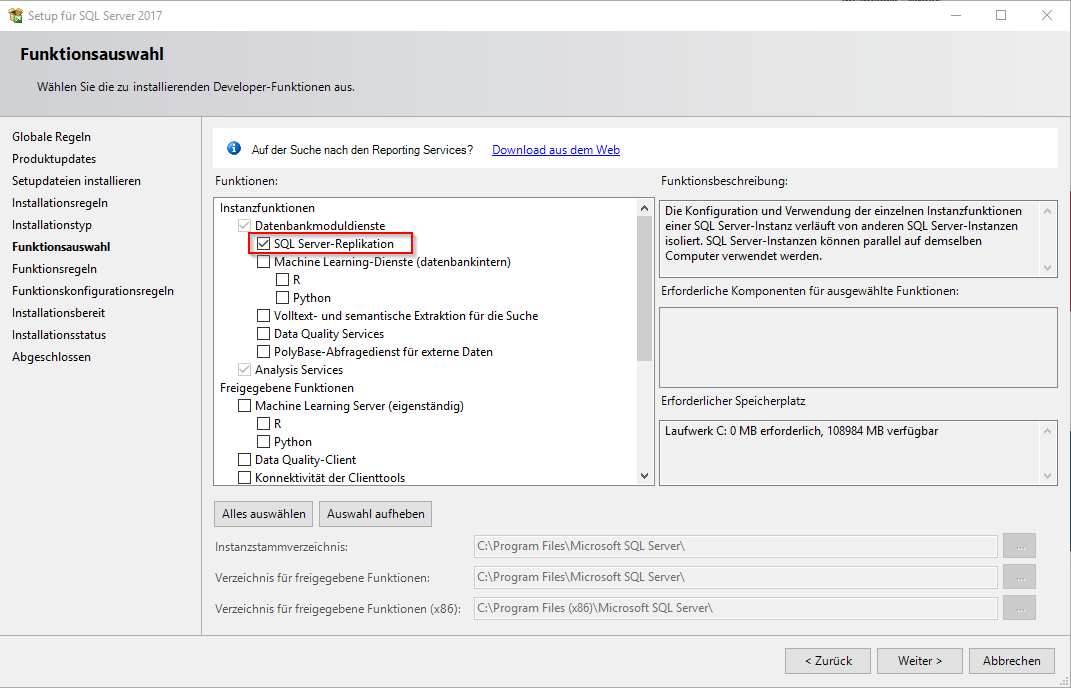
Abbildung 6: Nachinstallation der Replikationskomponente
Verteilungskonfiguration
Nachdem die Replikationskomponente erfolgreich installiert wurde, kann mit der Konfiguration der Replikation begonnen werden. Vorab empfiehlt es sich jedoch, noch mindestens zwei lokale Benutzer anzulegen, über die der Replikationsprozess schlussendlich ausgeführt wird. Diesen können dann die spezifischen Rechte zugeordnet werden, auf die im weiteren Verlauf näher eingegangen wird. Der eine Benutzer ist dabei für die Erstellung von Momentaufnahmen und Transaktionen zuständig, wohingegen der andere Benutzer für die Verteilung der Daten genutzt wird. In der nachfolgenden Abbildung sind die Benutzer mit entsprechendem Namen in der Computerverwaltung angelegt worden. Es ist darauf zu achten, dass bei der Erstellung der Konten der Haken bei „Kennwort läuft nie ab“ zu setzen ist.
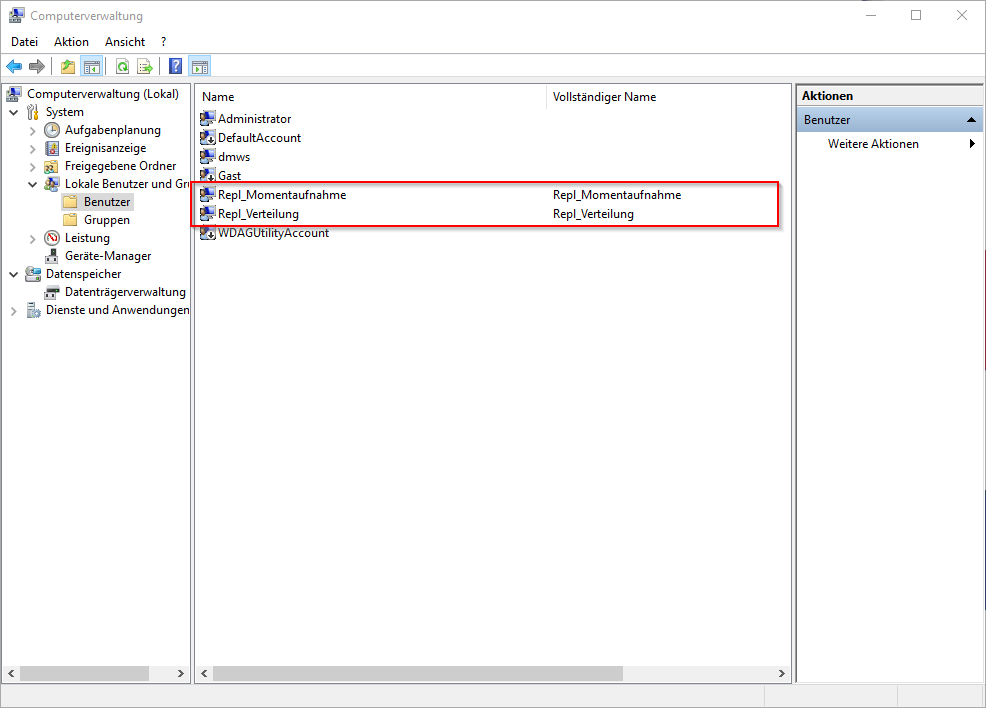
Abbildung 7: Anlage der benötigten lokalen Benutzer
Bei der Nachinstallation der Replikationskomponente wurde automatisch ein neuer Ordner im Programmverzeichnis der SQL Server Instanz angelegt. Dieser heißt „repldata“ und wird für die Speicherung von Snapshots verwendet. In den Eigenschaften dieses Ordners müssen folgende Einstellungen vorgenommen werden:
- Unter Freigabe -> Erweiterte Freigabe -> Haken bei „Diesen Ordner freigeben“ setzen
- Unter Freigabe -> Erweiterte Freigabe -> Berechtigungen -> Hinzufügen -> Angelegte User hinzufügen
- Berechtigungen für Benutzer „Repl_Momentaufnahme“: Vollzugriff
- Berechtigungen für Benutzer „Repl_Verteilung“: Lesen
- Zudem muss man sich unter dem Reiter „Freigabe“ den UNC-Netwerkpfad für einen der nächsten Schritte notieren
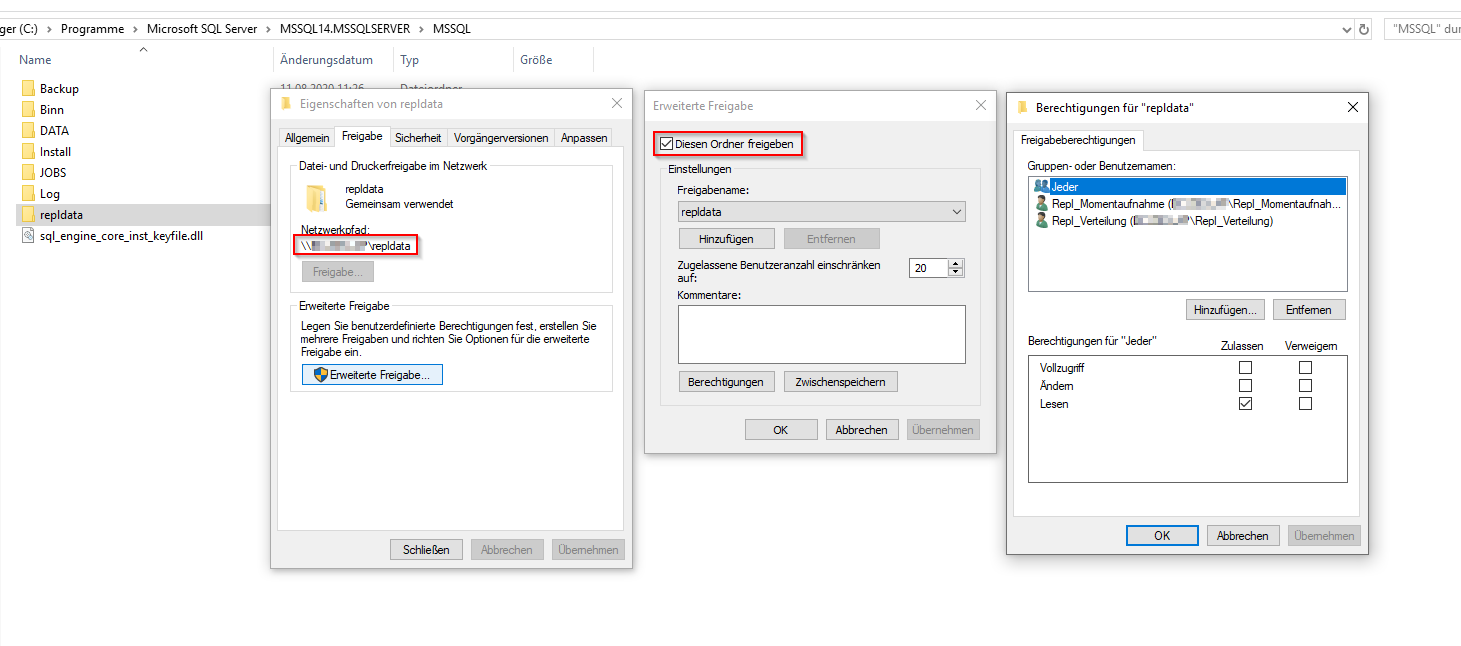
Abbildung 8: Setzen der Freigabe-Einstellungen auf dem repldata-Ordner
Neben der Freigabe müssen für die beiden Benutzer unter dem Reiter „Sicherheit“ noch folgende Berechtigungen gesetzt werden:
- Benutzer „Repl_Momentaufnahme“: Vollzugriff
- Benutzer „Repl_Verteilung“: Lesen
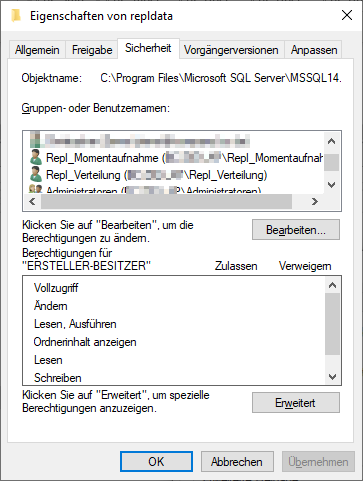
Abbildung 9: Setzen der Sicherheits-Einstellungen auf dem repldata-Ordner
Anschließend kann man nun mit der Konfiguration beginnen. Diese startet man per Rechtsklick auf den Ordner Replikationen -> Verteilung konfigurieren. Dadurch öffnet sich der Assistent, mit dessen Hilfe man Schritt-für-Schritt durch die Einstellungen durchgeführt wird.
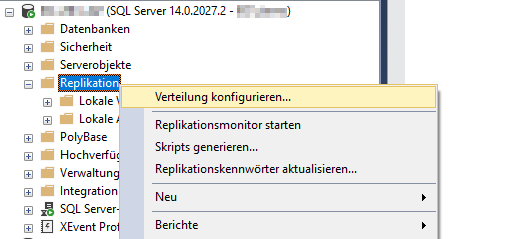
Abbildung 10: Start der Verteilungskonfiguration
Im ersten Schritt kann man zwischen den bereits oben beschriebenen Varianten wählen. In diesem Beispiel wird die praxisnahe Variante ausgewählt, bei der sowohl Herausgeber, als auch Verteiler auf der gleichen Instanz sind. Im nächsten Schritt muss man für den Momentaufnahmeordner den UNC-Pfad eintragen, welcher im Idealfall bereits bei der Ordnerberechtigung notiert wurde. Anschließend wird im nächsten Schritt für die Verteilung eine Systemdatenbank angelegt, welche auch gleich benannt werden kann. In diesem Fall wird sie „distribution“ genannt. Danach muss man dem Herausgeber noch die gerade angelegte Verteilungsdatenbank zuordnen und kann dann die Konfiguration über den Schalter „Fertig stellen“ abschließen.
(Um eine größere Ansicht zu erhalten, klicken Sie bitte auf die Abbildungen)
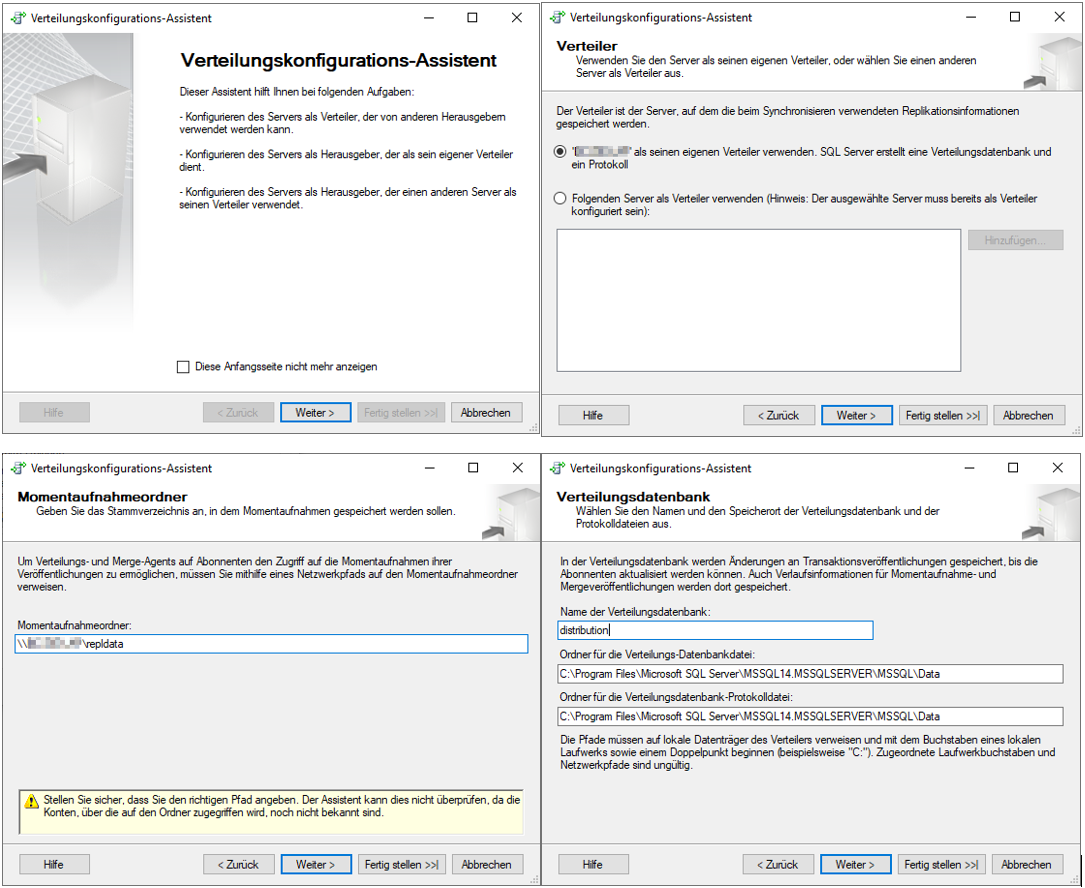
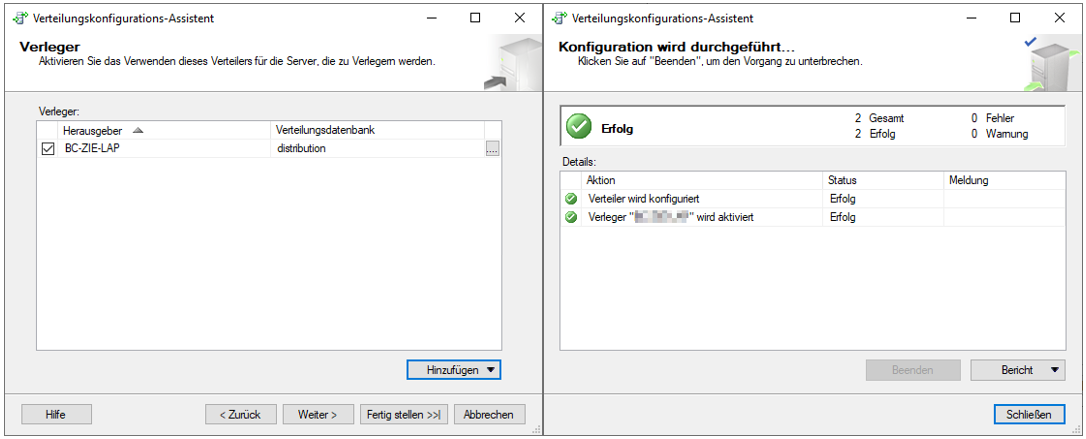 Abbildung 11: Schritte des Verteilungskonfigurations-Assistenten
Abbildung 11: Schritte des Verteilungskonfigurations-Assistenten
Nach der erfolgreichen Konfiguration kann man die erstellten Objekte betrachten. Zum einen wurde unter den Systemdatenbanken die Verteilerdatenbank mitsamt ihren relevanten Systemtabellen und Prozeduren angelegt (In diesem Fall namens „distribution“). Zum anderen wurden neue Jobs im SQL Server-Agent für den Replikationsprozess angelegt.
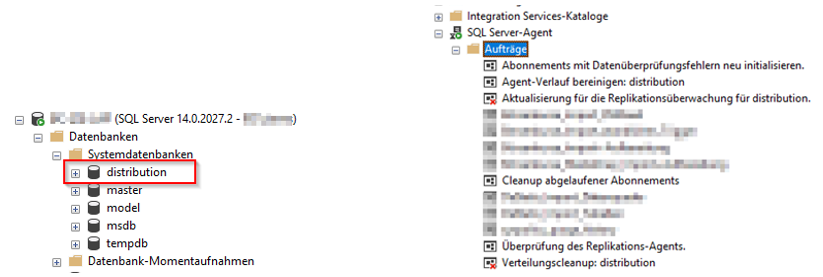
Abbildung 12: Angelegte Datenbankobjekte durch den Verteilungskonfigurations-Assistenten
Veröffentlichungskonfiguration
Nachdem der Verteiler korrekt konfiguriert wurde, kann nun mit der Konfiguration der ersten Veröffentlichung begonnen werden. Vorab wurde hierfür eine neue Datenbank namens „Replikation“ angelegt, auf die sich im Folgenden bezogen wird. Die Erstellung einer neuen Datenbank ist nicht notwendig, da man sich auf jede vorhandene Datenbank ebenfalls beziehen hätte können. Bevor mit der Konfiguration gestartet wird, müssen noch datenbankseitig Berechtigungen für die neu angelegten lokalen Benutzer gesetzt werden. Hierfür legt man für die beiden Benutzer neue Anmeldungen unter „Sicherheit“ an und erteilt beiden „db_owner“-Rechte auf der Verteilerdatenbank (in diesem Fall „distribution“) und der Datenbank (es können auch mehrere sein), von der aus Daten veröffentlicht werden sollen (in diesem Fall „Replikation“).
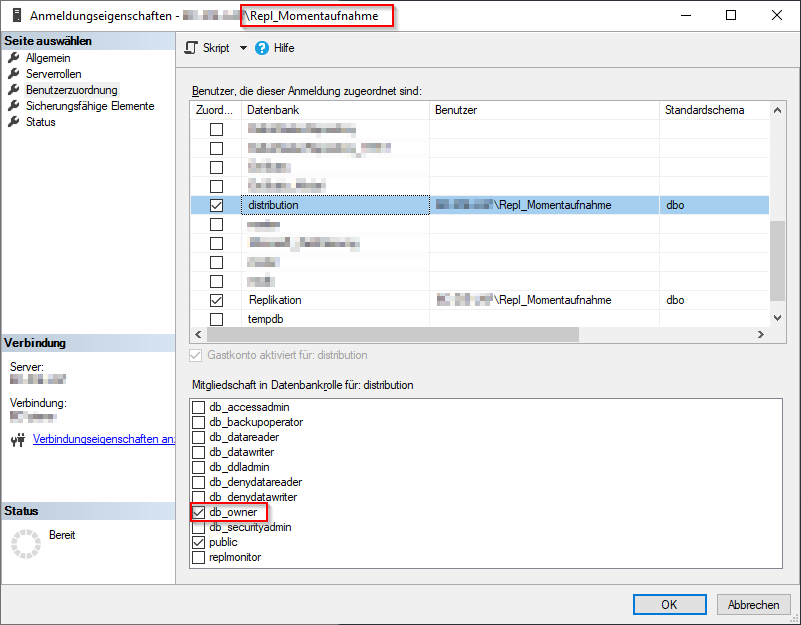
Abbildung 13: Datenbankberechtigungen für die angelegten Benutzer
Anschließend kann mit der Veröffentlichungskonfiguration begonnen werden. Dies geschieht per Rechtsklick auf den Unterordner „Lokale Veröffentlichungen“, anschließend wählt man„Neue Veröffentlichung…“.
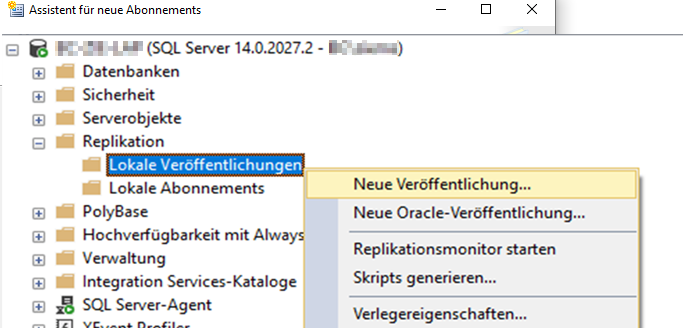 Abbildung 14: Start der Veröffentlichungskonfiguration
Abbildung 14: Start der Veröffentlichungskonfiguration
Im ersten Schritt des Assistenten wählt man die Datenbank, aus der Daten veröffentlicht werden sollen. Anschließend kann man zwischen den unterschiedlichen Veröffentlichungstypen wählen, die bereits in der Einführung vorgestellt wurden. In diesem Fall wurde sich für den in der Praxis sehr häufig genutzten Typen der „Transaktionsveröffentlichung“ entschieden. Im Anschluss können die Artikel (Datenobjekte) ausgewählt werden, die veröffentlicht werden sollen. Hierbei ist zu beachten, dass bei der Transaktionsveröffentlichung bei den Tabellenobjekten zwingend ein Primärschlüssel vorhanden sein muss. Das hat den Hintergrund, dass bei diesem Veröffentlichungstypen nur die sich geänderten Daten aktualisieren und damit über den Schlüssel fest gekennzeichnet werden können. Zur Auswahl stehen neben den Tabellen zusätzlich auch Sichten und Prozeduren.
Im nächsten Schritt können die zu veröffentlichenden Tabellen individuell gefiltert werden. Dies macht beispielsweise bei einer Replikation an verschiedene dezentrale Stellen Sinn, um diesen nur Ihren jeweiligen Datenausschnitt zur Verfügung stellen zu können. Anschließend kann entschieden werden, wann die initiale Momentaufnahme der zu veröffentlichenden Daten erstellt werden soll. Hier bietet sich die sofortige Erstellung an. Diese ist jedoch nicht zwingend notwendig. Danach müssen die Benutzer ausgewählt werden, unter denen der Agent laufen soll. Hierfür wurden im Vorfeld die lokalen Benutzer erstellt und bereits mit den benötigten Berechtigungen auf Ordner- und Datenbankebene ausgestattet. In diesem Fall kann man den beiden Agents den „Repl_Momentaufnahme“-Benutzer zuweisen. In den letzten beiden Schritten hat man noch die Möglichkeit, zwischen dem direkten Erstellen der Veröffentlichung und der Erstellung eines Skripts zu wählen und der Veröffentlichung einen Namen zu geben. Danach wird über „Fertig stellen“ die Veröffentlichung bereitgestellt.
(Um eine größere Ansicht zu erhalten, klicken Sie bitte auf die Abbildungen)
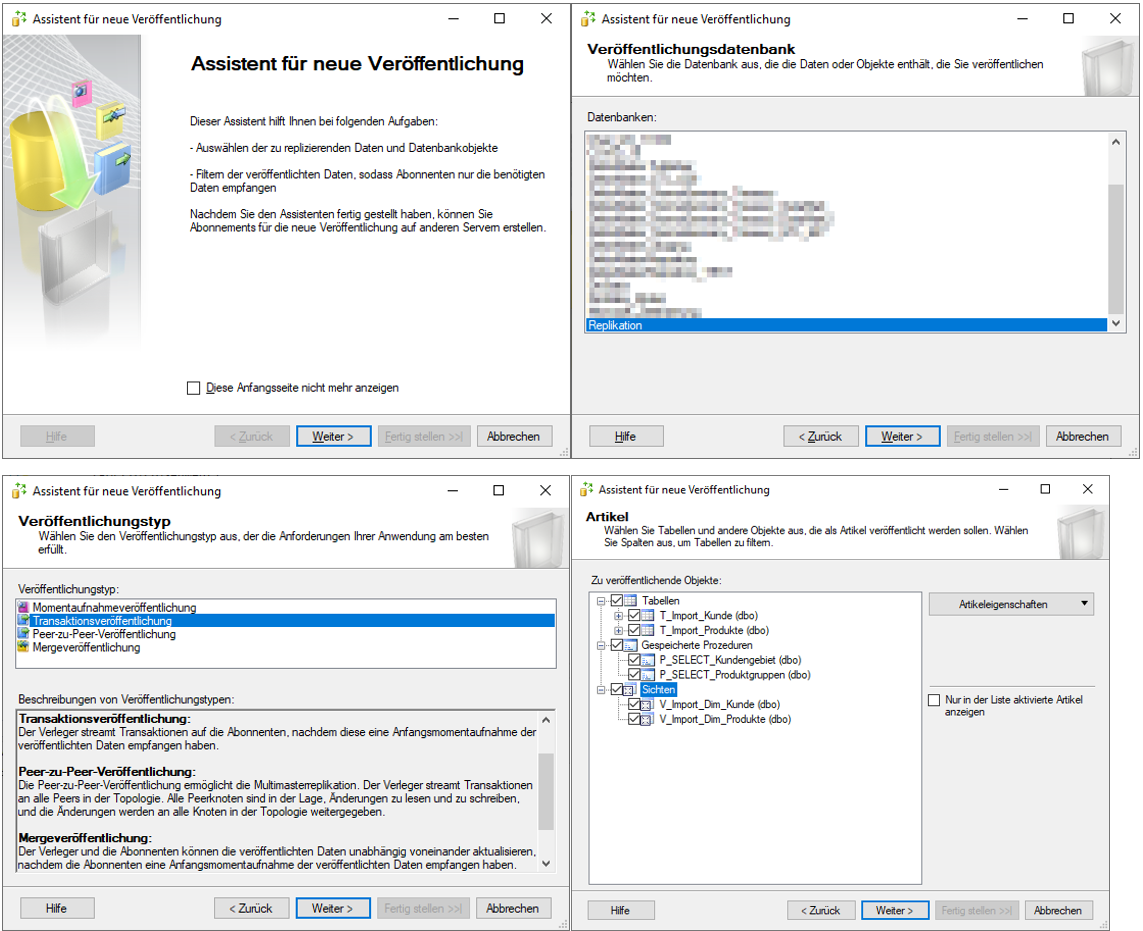
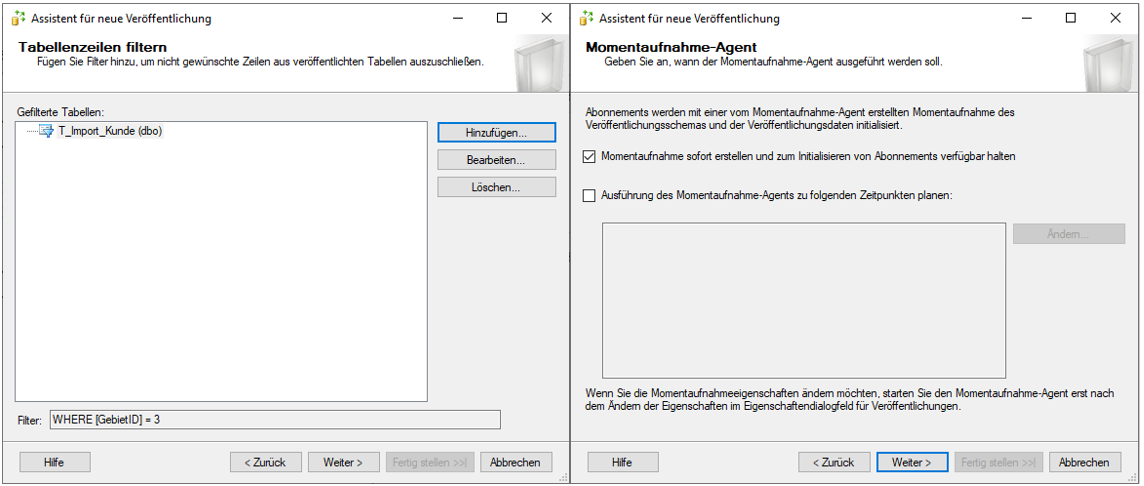
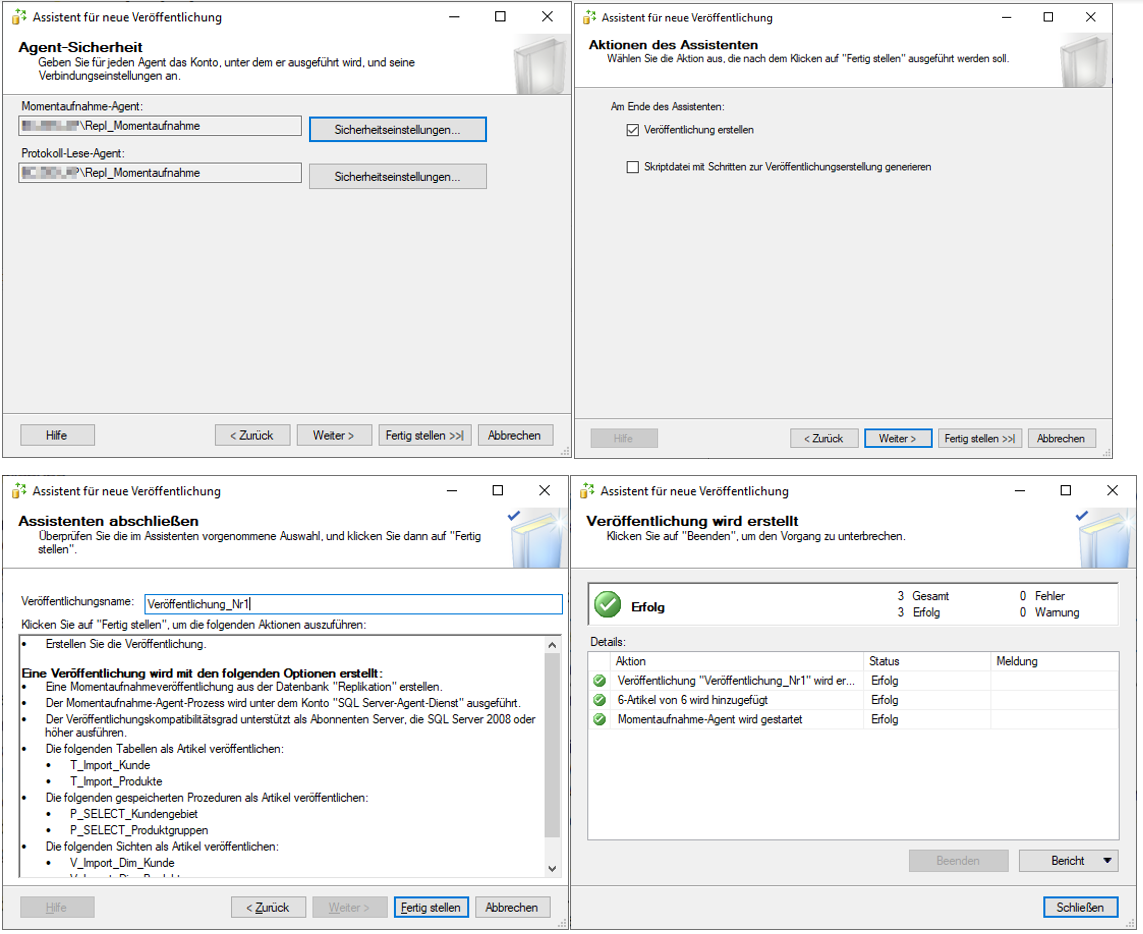
Abbildung 15: Schritte des Assistenten für neue Veröffentlichungen
Abonnements
Nachdem man nun erfolgreich eine Veröffentlichung konfiguriert hat, benötigt man noch den Gegenspieler, das Abonnement. Hierfür wurde eine separate SQL-Server Instanz mit dem Namen Abonnent eingerichtet, die als Abonnent fungieren soll. Bei der Installation der neuen Instanz muss man zwingend auch die Replikationskomponente installieren, sonst kann die neue Instanz keine Abonnements beziehen. Die Konfiguration des Abonnements wird erneut begonnen, indem per Rechtsklick auf den Unterordner „Lokale Abonnements“ geklickt und dann „Neue Abonnements…“ ausgewählt wird. Man kann die Konfiguration dabei von der Verlegerseite und von der Abonnentenseite aus starten. In vorliegendem Beispiel wurde sich für die Abonnentenseite entschieden.
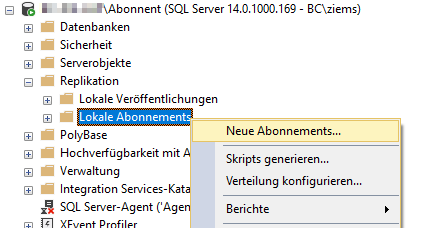
Abbildung 16: Start der Abonnentenkonfiguration
Im ersten Schritt des Assistenten kann über das Auswahlmenü der Verleger bestimmt werden, von dem man eine Veröffentlichung abonnieren möchte. Die Veröffentlichungen selbst sind nach den Datenbanken gegliedert, aus denen sie stammen. Im zweiten Schritt kann dann das gewünschte Verteilungsverfahren ausgewählt werden. Dies bestimmt, ob die Daten von der Verteiler-Instanz „gepusht“ oder die Daten von der Abonnenten-Instanz „gepullt“ werden. Im vorliegenden Falle wurde die zentrale Verwaltungsvariante ausgewählt, bei der im Push-Prinzip die Daten vom Verleger an den Abonnenten repliziert werden.
Anschließend können die Abonnenten hinzugefügt werden, die die ausgewählte Veröffentlichung erhalten sollen. Neben dem Abonnenten selbst muss auch die Abonnentendatenbank definiert werden, in die die Daten repliziert werden sollen. Hier gibt es ebenfalls die Option, sich eine neue Datenbank erstellen zu lassen. Diese Option wurde hier ausgewählt und eine Datenbank namens „Replikation“ wurde erstellt.
Wie bei der Veröffentlichung, gibt es beim Abonnement ebenfalls einen zu definierenden Agenten, über den die Abonnements durchgeführt werden. Dieser wird im nächsten Schritt abgefragt. Hierzu wurde im Vorfeld ebenfalls ein lokaler Benutzer namens „Repl_Verteilung“ angelegt, der nun genutzt und hinterlegt wird.
Anschließend kann man die Art der Synchronisation wählen, mit der die Daten abgeglichen und repliziert werden. Mit „Fortlaufend ausführen“ gleicht der Agent-Job permanent ab, ob sich Daten geändert haben und pusht diese anschließend an die Abonnenten. Beim bedarfsgesteuerten Ausführen wird kein Zeitplan hinterlegt und der Anwender muss den Job selbst manuell starten. Ansonsten besteht natürlich die Möglichkeit, einen Zeitplan zu hinterlegen und den Job in einem gewissen Turnus ablaufen zu lassen, wie man es auch von anderen Agent-Jobs gewohnt ist.
Im Anschluss kann das Abonnement direkt oder über ein Skript erstellt werden. Zudem kann im nächsten Schritt gewählt werden, ob die Abonnenten-Datenbank initial mit der aktuellen Momentaufnahme des Verlegers befüllt werden soll. Nachdem man alle Einstellungen vorgenommen hat, kann über „Fertig stellen“ das Abonnement erstellt werden.
(Um eine größere Ansicht zu erhalten, klicken Sie bitte auf die Abbildungen)
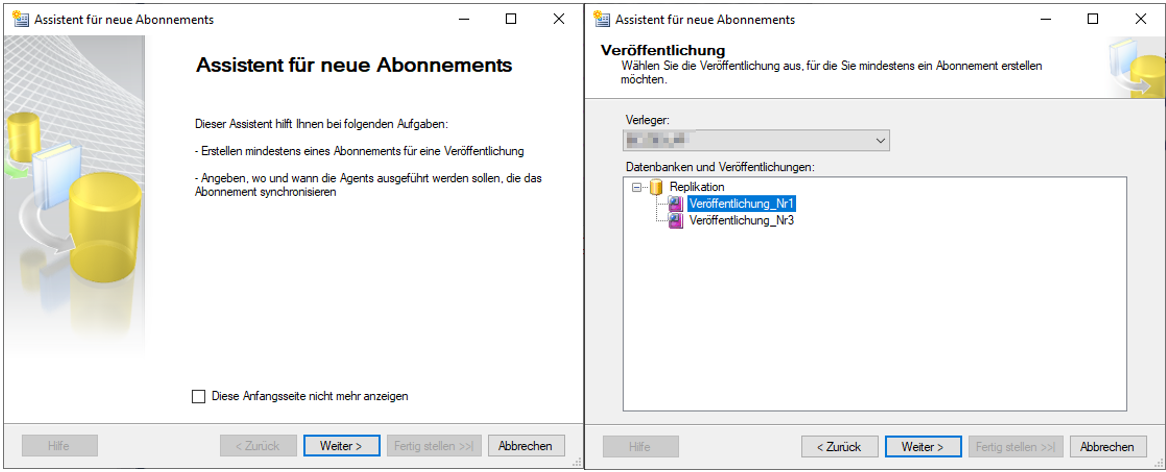
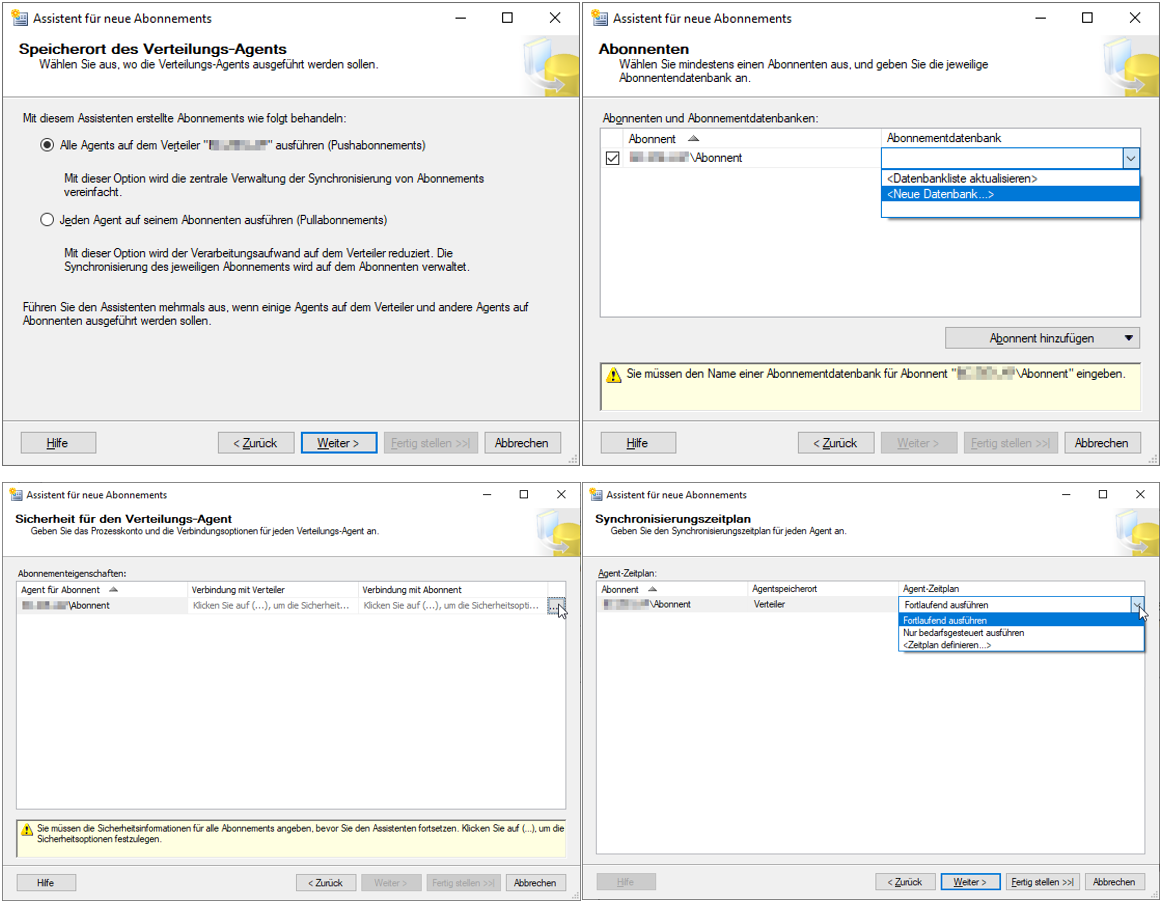
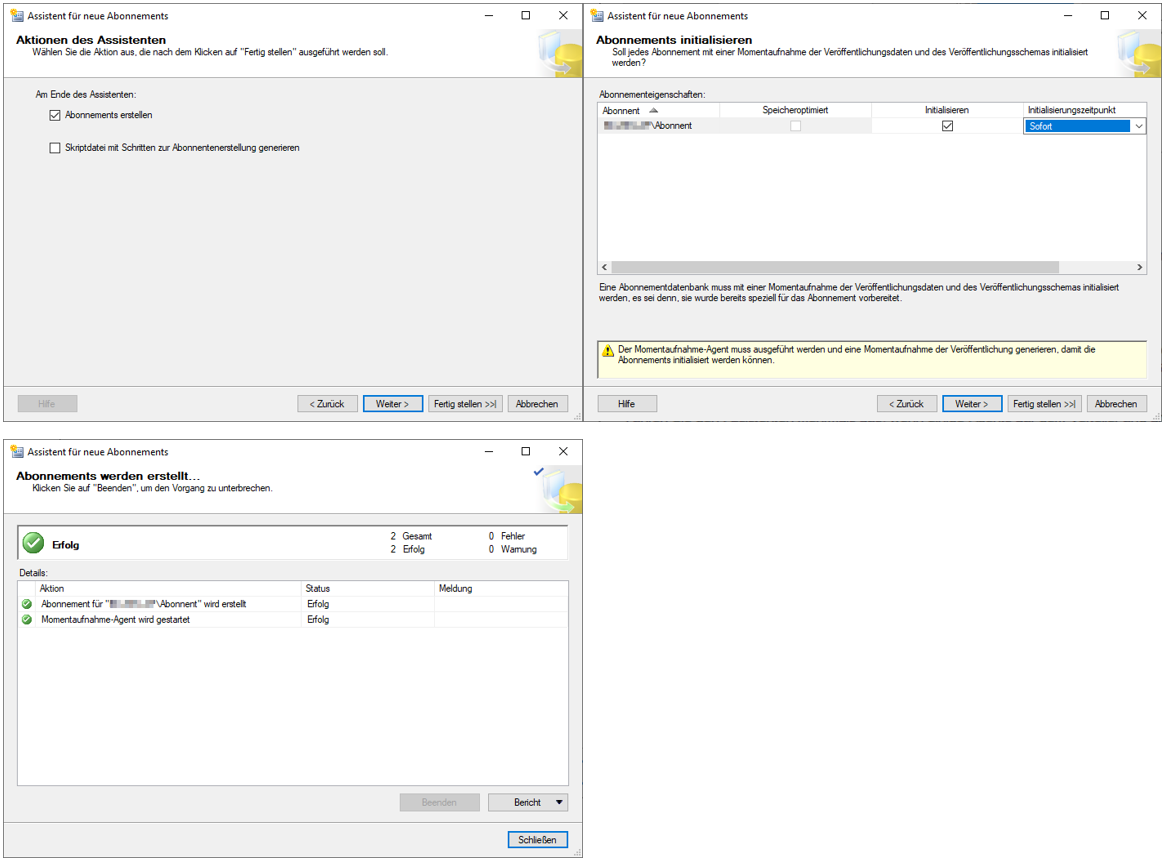
Abbildung 17: Schritte des Assistenten für neue Abonnements
Replikation im Einsatz
Nach der erfolgreichen Konfiguration der gesamten Replikation kann man sich zu guter Letzt das Endergebnis und die wichtigsten Werkzeuge zur Überwachung anschauen.
Durch die Abonnementkonfiguration sind weitere Jobs hinzugekommen, die für die Replikation zu-ständig sind. Es gibt dabei drei Gruppierungsebenen an Jobs. Ein Job ist für sämtliche Veröffentli-chungen einer Datenbank zuständig (Aufbau: <Server>-<Datenbank>-<Integer>). Der zweite Job umfasst alle Abonnements einer Veröffentlichung (Aufbau: <Server>-<Datenbank>-<Veröffentlichung>-<Integer>) und der letzte Job beinhaltet ein spezifisches Abonnement einer Veröf-fentlichung (Aufbau: <Server>-<Datenbank>-<Veröffentlichung>-<Abonnement>-<Integer>).
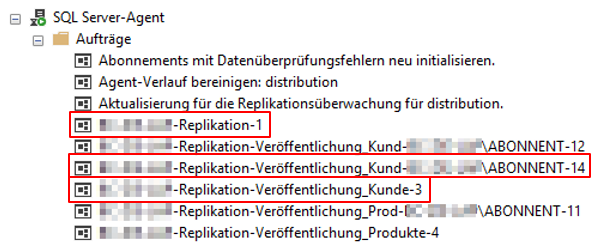
Abbildung 18: SQL Agents Jobs der Replikation
Ein wichtiger Hinweis zu den Jobs: Sollte man in der Abonnementkonfiguration vergessen haben, ein Abonnement vom Agent-Zeitplan auf „Fortlaufend ausführen“ zu stellen und will man dies nachholen, kann dies nicht, wie angenommen, über die Zeitpläne des SQL Agent Jobs gesteuert werden. Für die Funktion muss nämlich im 2. Schritt des Abonnentenjobs an das Ende des Befehls der Parameter „-Continious“ gesetzt werden. Nach einem Neustart des SQL Agent Dienstes sollte dieser dann fortlaufend ausgeführt werden. Sichtbar ist das auch im Auftragsaktivitätsmonitor.
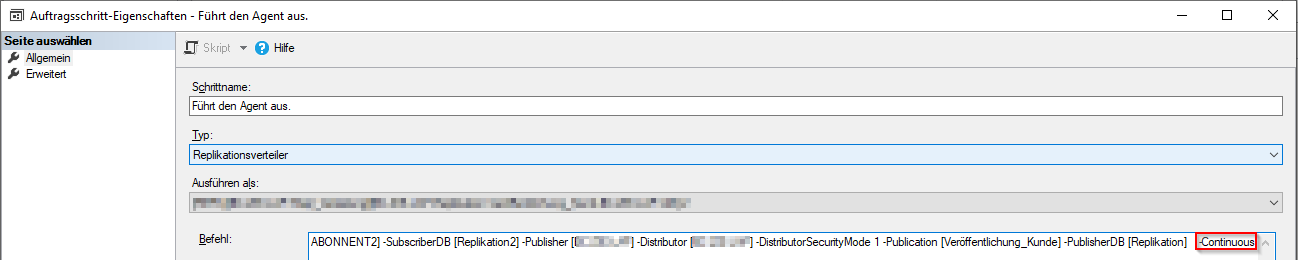
Abbildung 19: Parameter zur fortlaufenden Ausführung der Replikation
Für die Überwachung der Replikationen gibt es ebenfalls ein Monitoring. Dies ist per Rechtsklick auf den Ordner „Replikation“ unter „Replikationsmonitor“ zu finden. Aufgeführt sind hier alle Verleger und deren Veröffentlichungen. Die Icons an den Veröffentlichungen signalisieren, wie gewohnt von den SQL Server Agent Jobs, ob eine Replikation fehlerhaft oder erfolgreich läuft. Über einen Rechtsklick auf die Veröffentlichung und anschließend auf „Eigenschaften“ hat man die Möglichkeit, sämtliche Konfigurationen zu ändern und beispielsweise einen neuen Filter zu setzen oder neue Objekte in die Replikation mit aufzunehmen.
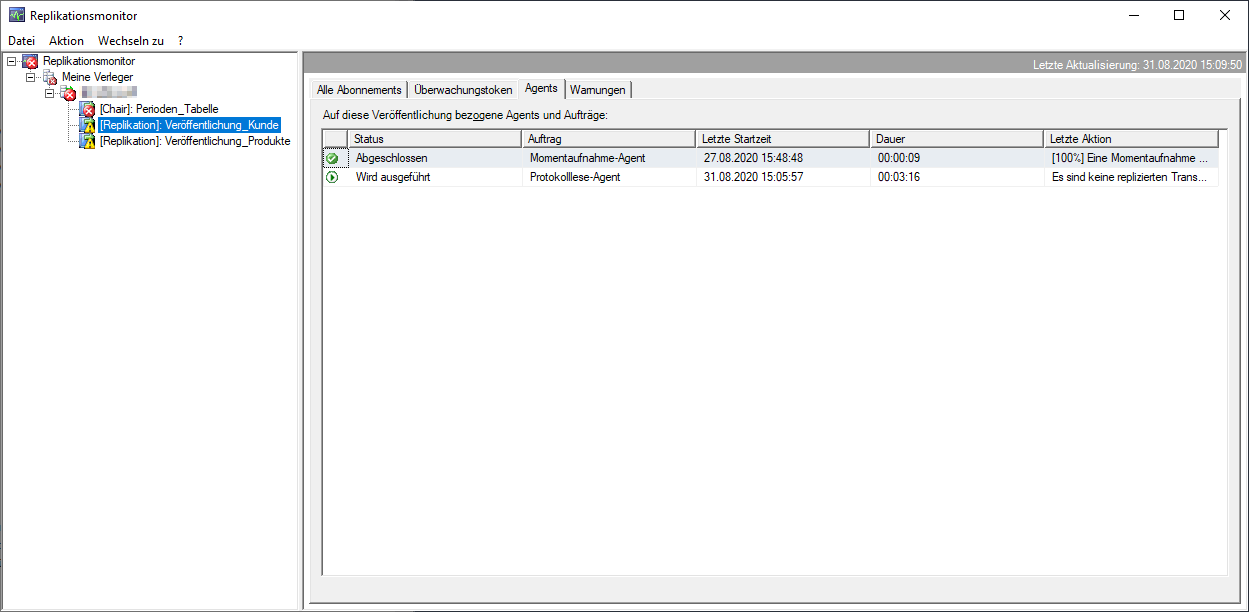
Abbildung 20: Replikationsmonitor
Nachdem nun ein Überblick über die administrativen Werkzeuge der Replikation dargelegt wurde, wird nun anhand eines Beispiels die Replikation in Aktion gezeigt.
In diesem Beispiel wurde die Tabelle „T_Import_Kunde“ von der Verlegerdatenbank (in Abbildung 21, links) veröffentlicht und von der Abonnentendatenbank (in Abbildung 21, rechts) abonniert. Auf beiden ist vor der Datenmanipulation der Datensatz der CustomerID „Geo61“ vorhanden. Das zeigt, dass die initiale Momentaufnahme erfolgreich an den Abonnenten repliziert wurde.
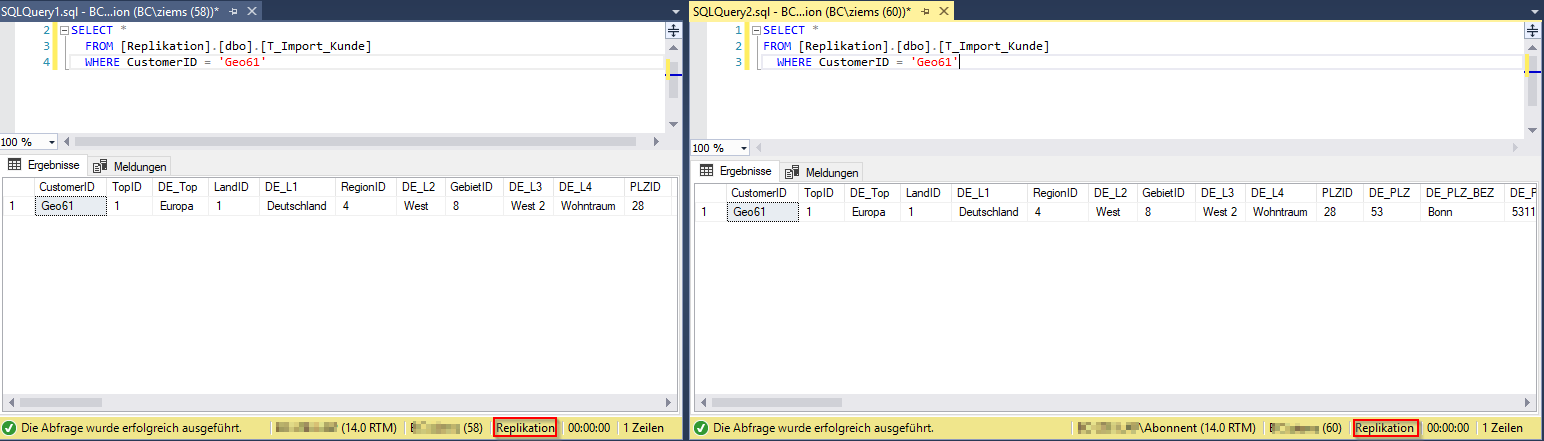
Abbildung 21: Abfrage der Verleger-DB (links) und der Abonnenten-DB (rechts) vor der Datenmanipulation
Im nächsten Schritt soll eine Datenmanipulation vorgenommen werden, um zu prüfen, ob diese auch auf der Abonnentendatenbank ankommt. Hierzu wird auf der Verlegerdatenbank der Datensatz für die CustomerID „Geo61“ gelöscht (siehe Abbildung 22).
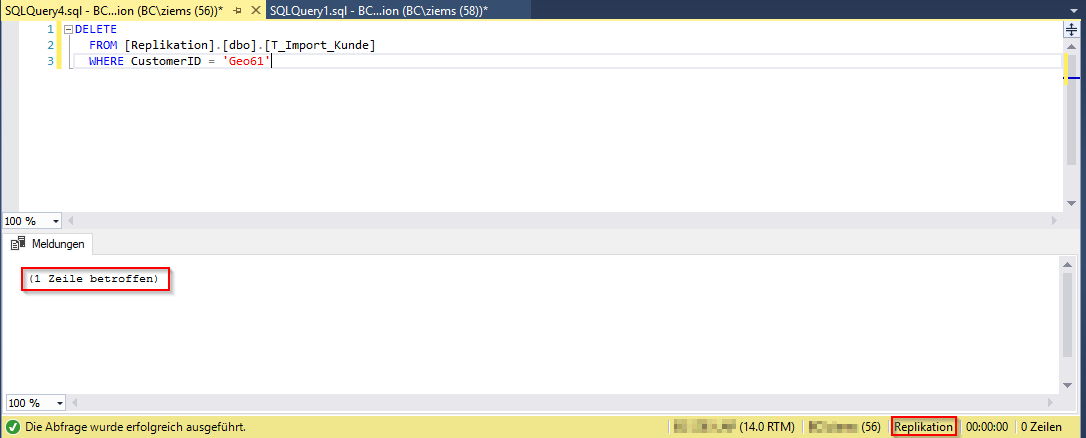
Abbildung 22: Ausführung der Datenmanipulation auf der Verleger-DB
Nach der erneuten Abfrage des Datensatzes für die CustomerID „Geo61“ auf der Verlegerdatenbank ist dieser nicht mehr zu finden. Wird nun auf der Abonnentendatenbank das gleiche Statement abgefragt, so wird kein Datensatz mehr angezeigt. Die Replikation hat dementsprechend korrekt funktioniert und auch auf der Abonnentendatenbank den Datensatz gelöscht.
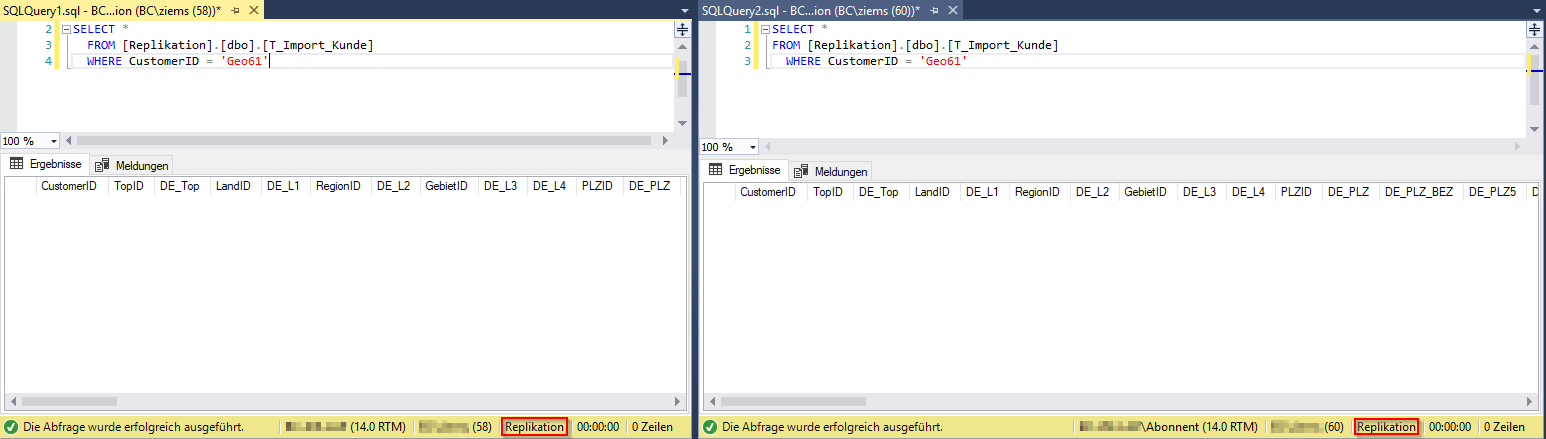
Abbildung 23: Abfrage der Verleger-DB (links) und der Abonnenten-DB (rechts) nach der Datenmanipulation
In diesem Beispiel wurde die Datenmanipulation direkt auf die Abonnentendatenbank repliziert, da die fortlaufende Ausführung in der Konfiguration auswählt wurde. Je nachdem, welchen Agent-Zeitplan man gewählt hat, muss man für die erfolgreiche Replikation entweder den eingestellten Turnus abwarten oder den Agentjob von Hand starten, um das Ergebnis zu sehen.
Neben der exemplarisch gezeigten Änderung von Daten in einer Tabelle funktioniert die Replikation ebenso bei Änderungen von Sichten und Prozeduren analog nach demselben Prinzip.
Schlussgedanke
Dieser Blogbeitrag hat mit der Replikation auf der einen Seite eine Form der Datenverteilung aufgezeigt, die zwar von der Konfiguration her deutlich aufwendiger ist als klassische Formen, wie Backup & Restore oder LinkedServer. Auf der anderen Seite bietet sie jedoch viele Vorteile in der Automatisierung der Daten, die bei den anderen Formen so nicht gegeben sind.
Neben den klassischen Anwendungsgebieten, der Verteilung von Daten von einer zentralen Stelle aus an dezentrale Stellen, macht diese Datenverteilung durchaus auch in einer Test/(Dev)/Prod-Architektur Sinn. Hier könnte nämlich der Austausch von neuen Sichten oder Prozeduren zu benutzerdefinierten Zeitpunkten über die Replikation gesteuert werden, ohne dass Skripte von den geänderten Objekten manuell angefertigt werden müssen.
Man sieht also, dass die Anwendungsgebiete und die Vorteile der Replikation als Form der Datenverteilung durchaus gegeben sind. Am Ende ist individuell zu prüfen, welche Datenverteilungsstrategie am besten in ein bestimmtes Szenario passt. Die Replikation kann hier eine attraktive Alternative darstellen.
