DeltaMaster bietet mit dem neu gestalteten SQL-Durchgriff nahezu unbegrenzte Möglichkeiten, aus OLAP-Anwendungen heraus auf die zugrunde liegenden relationalen Daten in maßgeschneiderter Form zugreifen zu können. Wir demonstrieren anhand von Beispielen die prinzipielle Vorgehensweise.
Der SQL-Durchgriff dient in einer OLAP-Anwendung üblicherweise dazu, auf Details der relationalen Daten zugreifen zu können, die in der aggregierenden OLAP-Modellierung nicht berücksichtigt wurden.
Dieses bewusste Ausblenden von Informationen kann aus Performanz-, aber auch aus Relevanzgründen geschehen: Für die Beurteilung der monatlichen Gesamtumsatzentwicklung eines Kaufhauses ist es beispielsweise nicht nötig, die ausführlichen Bonpositionen eines einzelnen Einkaufs kennen zu müssen.
Nichtsdestotrotz soll es aber möglich sein, diese Details im Fall der Fälle in der aktuellen Sitzung in DeltaMaster sichtbar zu machen.
Eine Warnung vorweg: Hier wagen wir uns auf das Terrain der Datenbankmodellierung – es kann also heute etwas technischer werden. Aber keine Angst, der Berichtsempfänger braucht dieses Hintergrundwissen nicht, für den Berichtsredakteur kann es nützlich sein – und ansonsten wenden Sie sich bei Fragen bitte vertrauensvoll an die Consultants im Projekt!
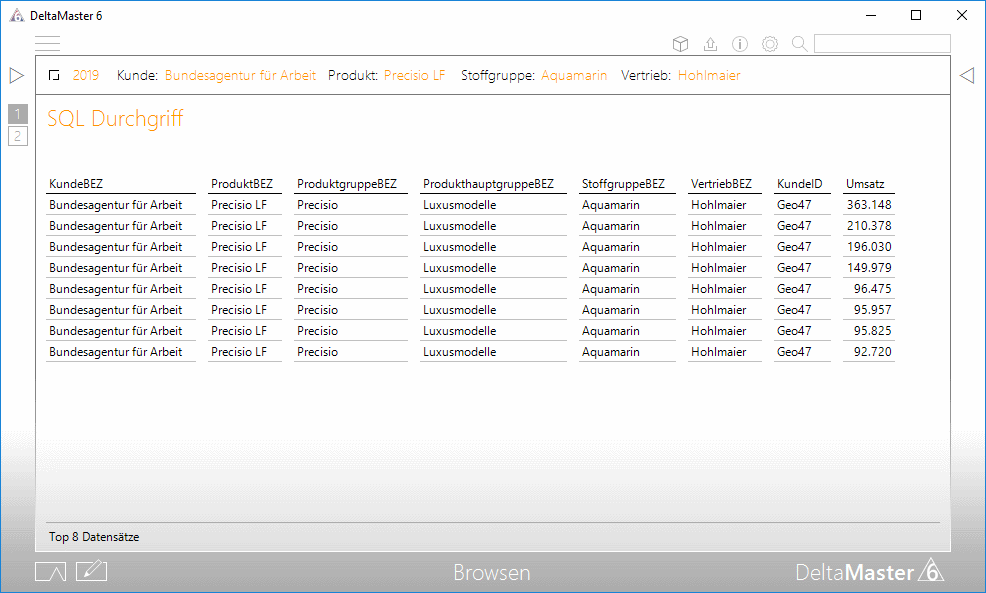
SQL-Durchgriff auf Basis einer Auswahl an Tabellenfeldern
So wie hier dargestellt könnte bei unserer Demoanwendung Chair der erzeugte Bericht des bewährten SQL-Durchgriffs auf Basis einer Auswahl an Tabellenfeldern aussehen.
Dass hier maximal 8 Zeilen zu sehen sind, liegt an der Wahl im Einstellungsdialog:
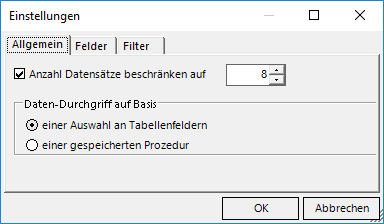
Allgemeine Einstellungen
Man beachte hier schon einmal die zweite mögliche Option „einer gespeicherten Prozedur“, aber bleiben wir erst einmal bei der Auswahl an Tabellenfeldern und schauen auf die definierten Felder:
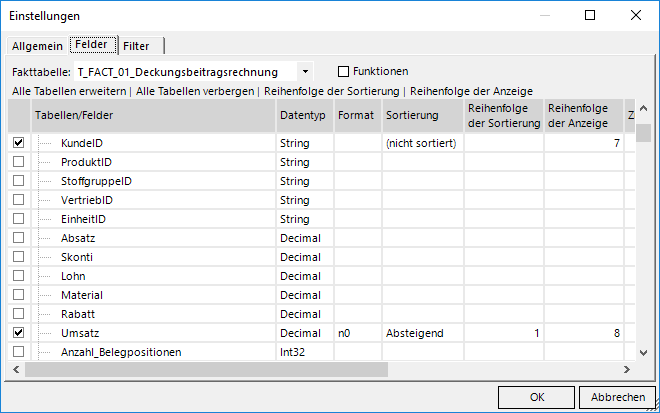
Einstellungen der Felder
DeltaMaster übernimmt dankenswerterweise für uns die Aufgabe, diese Einstellungen in die passende SQL-Abfrage mit einigen „INNER JOINS“ zu verwandeln, die an den SQL-Server geschickt wird. Im SQL-Log lässt sich der verwendete Befehl nachvollziehen:

Erzeugte SQL-Abfrage des SQL-Durchgriffs
Hier erkennen wir unsere Einstellungen in den hinterlegten Feldern wieder:
- die TOP 8, die aus der Datensatzbeschränkung stammen
- die eben ausgewählten Felder KundeID und Umsatz
- der „ORDER BY“-Befehl der letzten Zeile berücksichtigt die absteigende Sortierung nach Umsatz
- und vor allem der WHERE-Block überträgt die Filter der Sicht, die bei unserem Bericht eingestellt sind, wie etwa [KundeID]=’Geo47′ (Bundesagentur für Arbeit)
Der bisherige SQL-Durchgriff ist mächtig genug, um die meisten Abfragewünsche zu erfüllen. Es kann somit durchaus sein, dass Sie genau diese und darüber hinaus keine anderen Funktionalitäten benötigen und deshalb bisher auch nichts vermisst haben.
Es gibt aber Kunden, die spezielle Anforderungen an den SQL-Durchgriff haben und deshalb gerne auf die erzeugten Abfragen einwirken möchten.
Wir haben deshalb für Sie die Möglichkeit geschaffen, ihre Wunschabfrage in einer gespeicherten Prozedur (stored procedure) unterzubringen, die auf dem SQL-Server ausgeführt wird.
Der Vorteil liegt auf der Hand: Sie (oder besser gesagt die Datenbankadministration) können diese Abfrage vollkommen flexibel nach Ihren Wünschen gestalten.
Aber natürlich müssen Sie (oder besser gesagt die Datenbankadministration) die Programmierung der Abfrage aber auch selbst umsetzen.
Übrigens besitzen Kunden, die unser Modellierungs- und Projektautomatisierungstool „DeltaMaster ETL“ einsetzen, einen Vorsprung: Hier gibt es die Möglichkeit, automatisiert ein Template für eine gespeicherte Prozedur zu erzeugen, das bereits die „INNER JOIN“-Befehle, die Parameterübergabe und den WHERE-Block passend zum Modell anlegt.
Dieses Template kann dann als Ausgangspunkt eigener Anpassungen verwendet werden.
Was muss die gespeicherte Prozedur verarbeiten können? Wie sieht die Eingabe aus?
Jedes Mal, wenn der auf einer Prozedur beruhende neue SQL-Durchgriff aufgerufen wird, werden zum einen die Filter der Sicht übertragen, also die Angaben, die normalerweise in den WHERE-Teil der SQL-Abfrage eingehen sollen, und zum anderen der Parameter @maxrows, der die Zahl enthält, die in „Anzahl Datensätze beschränken auf“ angegeben wird. Ist die zugehörige Checkbox nicht aktiv, wird hier „-1“ übertragen.
Es werden übrigens nur die Elemente übertragen, die vom all-Element abweichen. Die Namen der zu übergebenden Inputparameter lehnen sich an die Darstellung an, die auch im obigen SQL-Log zu sehen ist.
Soll eine anzulegende Prozedur also für alle Eventualitäten gewappnet sein, müssen alle möglichen Sichtelemente übergeben werden können.
Legen wir doch einfach einmal eine simple Prozedur „ChairProgSimple“ an:
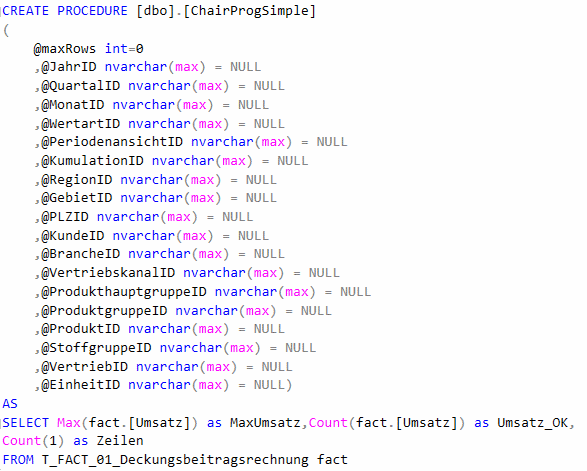
Gewappnet für die Übergabe der Sichtelemente
Wir sehen, dass zwar etliche Sichtparameter übergeben werden könnten, aber ob und wie diese Sichtelemente verwendet werden, ist dann eine andere Frage.
Unser simpler Programmcode berücksichtigt weder @maxrows, noch irgendein Sichtelement, sondern schaut in unserer Faktentabelle nach der größten Umsatzbuchung, zählt die Zeilen mit einem Umsatz und gibt die Gesamtanzahl der Zeilen aus. Wie man sieht, ist es also auch möglich, neue Spalten anzulegen.
Um diese Prozedur in DeltaMaster benutzen zu können, geben wir auf dem Reiter Prozedur den Namen unserer bereits komplett angelegten Prozedur ChairProgSimple an und klicken auf „Felder aktualisieren“. Hiermit wird der Parameter @maxRows=0 an unsere Prozedur übergeben und die Antwort ausgewertet (die in diesem konkreten Fall unabhängig von @maxRows ist!).
Die Felder werden erkannt und es ergibt sich das folgende Bild. Vergleichen Sie vor allem die vergebenen Namen, die Sie im obigen Prozedurcode auch entdecken können. DeltaMaster stellt die Datentypen passend ein.
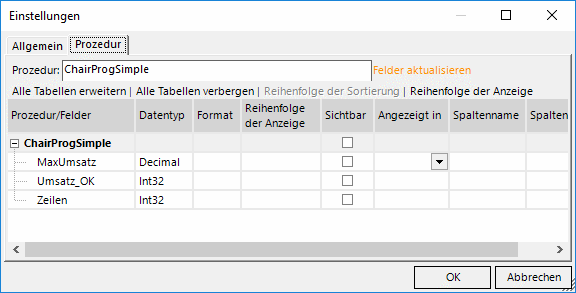
Wie programmiert, so geliefert!
Wir aktivieren die Sichtbarkeit und wählen die Anzeigeoption „Liste“; zur alternativen Formularansicht (Beta) und weiteren neuen Formatierungsmöglichkeiten kommen wir in einem späteren Blogbeitrag:
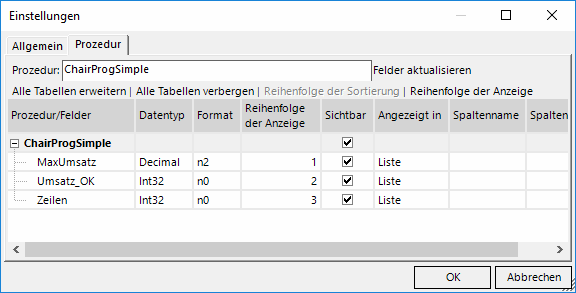
Alle Spalten sollen in Listenform angezeigt werden!
Alle Spalten sollen angezeigt werden. Unsere einfache Prozedur liefert nun immer das gleiche Ergebnis, egal, welche Elemente in der Sicht eingestellt werden:
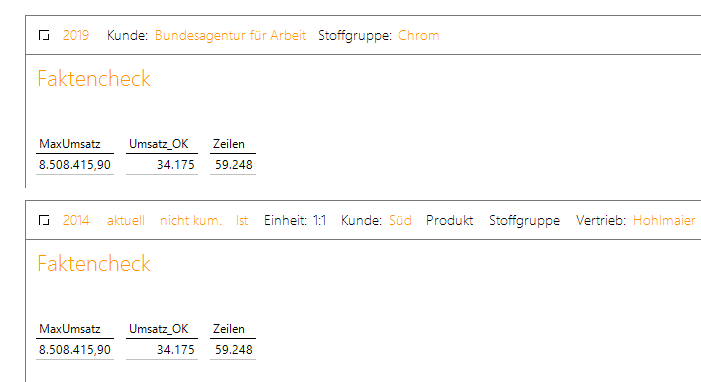
Diese Prozedur verarbeitet stur die gesamte Faktentabelle!
Etliche Zeilen enthalten im Umsatz den Wert NULL, da sie noch in der Zukunft liegen.
Schauen wir nun auf Anwendungen, die mit dem bisherigen SQL-Durchgriff nicht möglich waren, und bei denen auch die Filter der Sicht berücksichtigt werden.
Beispielsweise konnte man über den Menupunkt „Funktionen“ im bisherigen Modul über alle betroffenen Zeilen aggregierende Größen wie Maximum oder Minimum oder Anzahl ausgeben lassen – aber immer nur eine davon!
Mit einer gespeicherten Prozedur lassen sich diese Werte simultan ausgeben. Schauen wir einmal auf eine dynamisch zusammengesetzte SQL-Abfrage. Dabei wird erst ein großer String aufgebaut, der die Befehle enthält und zum Schluss wird der Inhalt des Strings als SQL-Abfrage interpretiert. Wir haben hier auf die Darstellung der gesamten Abfrage verzichtet und zeigen sie in Pseudocode:
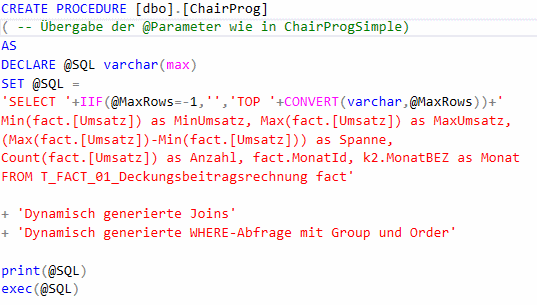
Zeige zusammenfassende Größen auf Monatsebene!
Der Teil IIF(@MaxRows=-1,“,’TOP ‚+CONVERT(varchar,@MaxRows)) sorgt dafür, dass die eingestellte Zeilenanzahl X als TOP X berücksichtigt wird. Ist die Checkbox nicht aktiv, wird maxRows = -1 gesetzt und in diesem Teilbefehl ein leerer String erzeugt.
print(@SQL) zeigt den erzeugten SQL-Befehl beispielsweise im SQL Management Studio an und ganz zum Schluss wird mit dem exec-Befehl der String als ausführbarer Code interpretiert.
Diese Prozedur ist dafür gedacht, einen einzelnen Kunden in der Sicht auszuwählen, unter Berücksichtigung der anderen Elemente. Als Ergebnis sieht man etwa die folgende Darstellung:
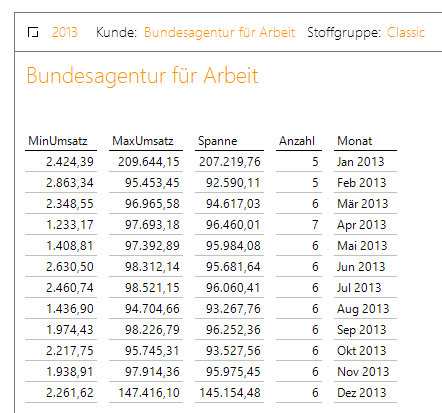
Sowohl Minimum, Maximum und Anzahl, als auch Spanne sind gleichzeitig zu sehen!
Hier sind für einen ausgewählten Kunden Minimum, Maximum, als auch Spanne (diese Größe gibt es im bisherigen SQL-Durchgriff nicht!) des Umsatzes und Anzahl der Bestellpositionen für die Monate eines ausgewählten Zeitraums gleichzeitig zu sehen! Nur Bestellpositionen von Produkten der Stoffgruppe „Classic“ werden hier berücksichtigt.
Übrigens lässt sich im SQL-Log der Diagnose in DeltaMaster der Aufruf der Prozedur erkennen. Wird der Reiter Abfrage angeklickt und der Code aus dem SQL-Log kopiert, kann er auch hier ausgeführt und das Ergebnis angeschaut werden:
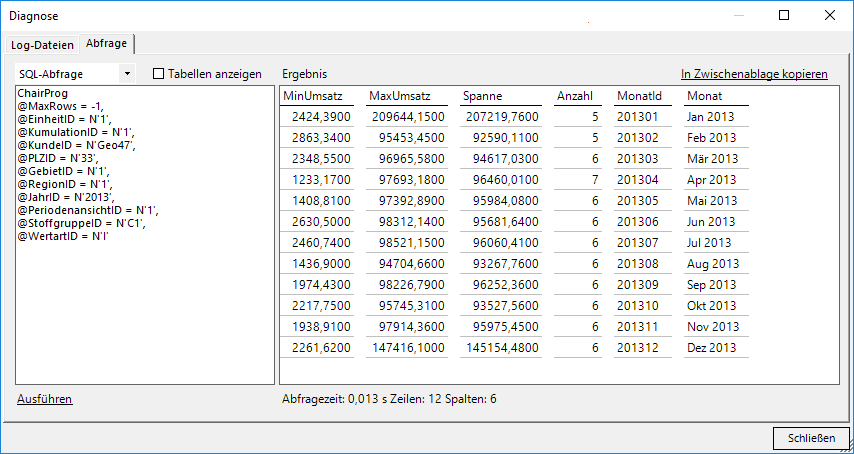
Übergebene Parameter und was die Prozedur daraus macht!
Es lässt sich hier erkennen, dass nicht nur die KundenId, sondern auch die übergeordneten Elemente der zugehörigen Hierarchie – also PLZID, GebietID und RegionID – übertragen werden und von der Prozedur direkt verwendet werden könnten.
Die Anwendungsmöglichkeiten des neuen SQL-Durchgriffs sind so mächtig und zahlreich, wie es die gespeicherten Prozeduren selbst sind – vor allem in der Hand von Experten! Das betrifft etwa Planungsanwendungen oder die Abbildung spezieller Geschäftslogiken.
Einer unserer Consultants hat mir begeistert vom implementierten Blättern durch Tabellen über die Verwendung einer Hilfsdimension erzählt; im Gegensatz zum Scrollen lassen sich hier beispielsweise zuerst die Zeilen 1 bis 50, dann 51 – 100 usw. anzeigen.
Sollten Sie also eine Anforderung haben, von der Sie glauben, dass sie nicht mit dem bisherigen Tabellenfelder-Durchgriff zu erfüllen ist, zögern Sie nicht, die Bissantz-Projektleitung anzusprechen!
Da ich in der Forschung oft mit statistischen Analysen zu tun habe, habe ich untersucht, ob sich auch hier mit dem neuen SQL-Durchgriff eine Anwendungsmöglichkeit auftut.
Dazu muss man wissen, dass ab der Version SQL Server 2016 die Ausführung von R-Skripten auf dem SQL-Server unterstützt wird. Seit SQL Server 2017 gilt dies zusätzlich für Python-Skripte und seit SQL Server 2019 wird auch noch Java bedient.
Im folgenden Beispiel seien Bankkunden gegeben, denen in einer persönlichen Beratung die Vorteile der neuen Geldanlage nahegebracht werden sollen. Da die Ressourcen begrenzt sind, sollen am besten nur diejenigen angesprochen werden, die die vermeintlich größte Affinität zum Produkt aufweisen, hier wird also der „Best Next Client“ für das gegebene Produkt gesucht.
Die Kunden haben verschiedene Eigenschaften, aber nur Geschlecht und Einkommen sollen bei unserem Beispiel im OLAP-Cube ansteuerbar sein. Zusätzlich gibt es in der relationalen Datenbank die Variablen Bildung, Kreditkarte, Beschäftigung und Altersklasse.
Bisher wurden Kunden nicht systematisch angesprochen, und es wurde festgehalten, ob jemand Interesse am Anlageprodukt gezeigt hat. In der Rückbetrachtung soll nun geschaut werden, ob ein statistisches Klassifikationsmodell besser abgeschnitten hätte.
Die Idee ist nun, Geschlecht und Einkommen auszuwählen und aus den restlichen vier Variablen mit einem Teil der Fälle in einem R-Skript, das in einer gespeicherten Prozedur eingebettet ist, ein Klassifikationsmodell zu erstellen und dann anschließend auf die restlichen Fälle anzuwenden. Die 12 Personen mit der höchsten Wahrscheinlichkeit, auf die Anfrage anzusprechen, sollen ausgegeben werden.
Wir nutzen eine Grafische Tabelle als Absprunghilfe, die auf einen Multiples-Bericht verweist und die ausgewählten Elemente von Geschlecht und Einkommen an die Multiples übergibt:
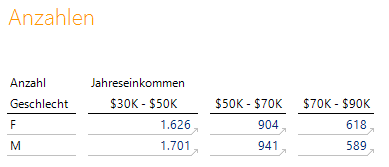
Auswahl der Teilmenge für die Analyse
Klickt man zum Beispiel auf die 1.626, die zu F wie Female und der Gehaltsklasse „$30K – $50K“ gehört, landet man bei der folgenden Auswertung (klicken Sie bitte auf die Grafik für eine vergrößerte Darstellung!):
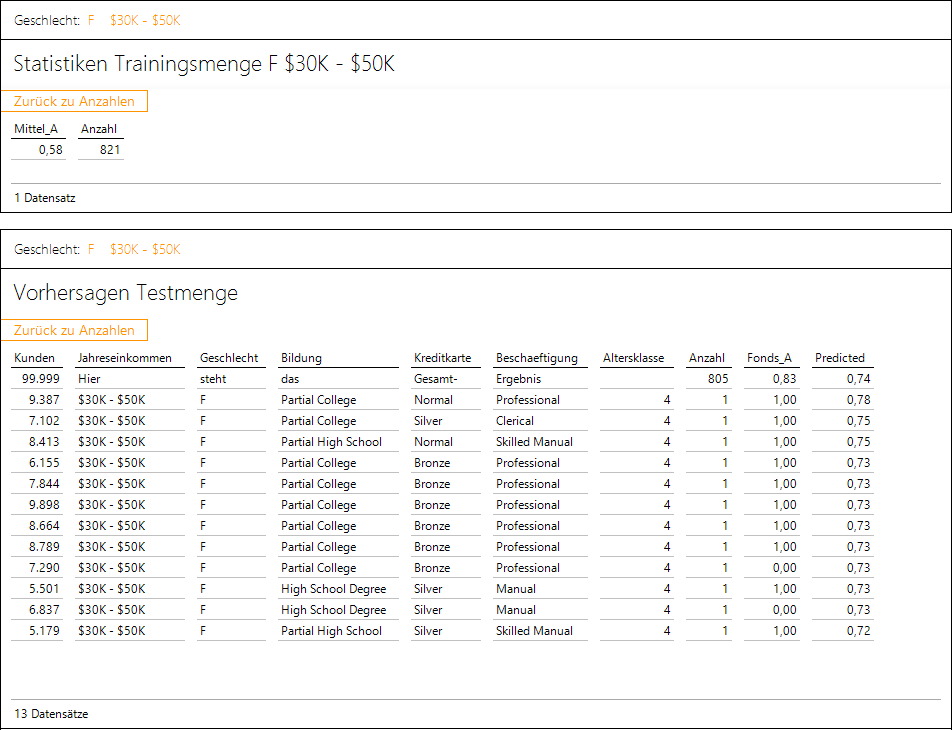
Ergebnis der Analyse
Im oberen Bericht ist eine gespeicherte Prozedur hinterlegt, die in Abhängigkeit von den Filtern die betroffenen Fälle der Trainingsmenge auswertet. Es gab 821 Frauen mit dem genannten Einkommen, von denen 58 % positiv auf die Anfrage reagiert haben.
Die zum unteren Bericht gehörige Prozedur ermittelt die Liste der betroffenen Personen und übergibt diese an das eingebettete R-Skript. Dieses wiederum trainiert mit den Daten der Personen aus der Trainingsmenge ein Klassifikationsverfahren und lernt den Zusammenhang zwischen Interesse und den Variablen Bildung, Kreditkarte, Beschäftigung und Altersklasse.
Für die Personen der Testmenge (deren Ergebnisse hier schon bekannt sind, aber für die Anpassung des Modells nicht verwendet werden) werden die Wahrscheinlichkeiten, die das angepasste Modell vorhersagt, berechnet und in der letzten Spalte Predicted ausgegeben. Die 12 Personen mit den höchsten Werten (hier zwischen 0,72 und 0,78, also deutlich höher als der allgemeine Anteil 0,58 auf der Trainingsmenge) werden kontaktiert.
Die erste Zeile, die noch im R-Skript hinzugefügt wird, fasst das Ergebnis zusammen: Es gab 805 Testfälle, von denen die besten 12 ausgesucht wurden. Vorhergesagt wurde eine Akzeptanz von ungefähr 74 %, tatsächlich haben sogar 83 % der 12 kontaktierten Personen positiv reagiert. Bei diesen kleineren Mengen können die Ergebnisse natürlich noch schwanken.
Diese Tabelle der Ergebnisse wird wieder an die umgebende gespeicherte Prozedur übergeben und dann von DeltaMaster angezeigt. D. h., mit dieser Vorgehensweise können Analysen durch externe Systeme wie R Services und Python Services in DeltaMaster integriert werden.
Das ist ein interessantes Thema, dem ich mich noch intensiver widmen werde.
