Immer häufiger hören wir das Thema Cloud Computing in Gesprächen mit Kunden. Trotz der Tatsache, dass unsere Kunden im europäischen Raum diesbezüglich deutlich zurückhaltender sind als Kunden auf dem amerikanischen Kontinent, gilt es für uns sich diesem zukunftsträchtigen Thema zu nähern. Dies ist der daher der erste Blogbeitrag, der die Terminologie der relevantesten Cloud-Begriffe klären soll und zudem auf Spezifika des Cloudanbieters Microsoft Azure eingeht.
Generelle Definitionen
Cloud Computing
Cloud Computing ist die Bereitstellung von Computing-Ressourcen (d. h. Server, Speicher, Datenbanken, Netzwerkkomponenten, Software, Analyse- und intelligente Funktionen, KI, Machine Learning etc.) über das Internet, um schnellere Innovationen, flexible Ressourcen und Skaleneffekte zu bieten. In der Regel bezahlt der Kunde nur für die Clouddienste, die er tatsächlich nutzt. Dadurch werden die Betriebskosten gesenkt, die Infrastruktur effizienter ausgeführt und bedarfsorientiert skaliert. Darin liegen die großen Vorteile von Cloud Computing.
Architektur von Cloud Computing
Es gibt mehrere Arten von Cloud Computing, um Kunden die ideale Lösung anzubieten, die Ihren Anforderungen entspricht. Für die Bereitstellung von Clouddiensten gibt es drei Möglichkeiten: öffentliche Cloud (Public Cloud), private Cloud (Private Cloud) und hybride Cloud (Hybrid Cloud).
Public Cloud
Die Public Cloud befindet sich im Besitz externer Cloudanbieter und wird von diesen verwaltet und ausgeführt. Dabei werden die Computing-Ressourcen, wie Server und Speicher, über das Internet zur Verfügung gestellt. Microsoft Azure ist ein Beispiel für eine öffentliche Cloud. Bei öffentlichen Clouds sind sämtliche Hardware-, Software- und andere unterstützende Infrastrukturkomponenten Eigentum des Cloudanbieters und werden von diesem verwaltet. In der Regel greift man per Webbrowser auf die Plattform zu, um Dienste zu nutzen und sein Konto zu verwalten.
Private Cloud
Bei einer Private Cloud werden die Computing-Ressourcen exklusiv von einem einzigen Unternehmen genutzt. Die private Cloud kann sich physisch im Datencenter des Unternehmens befinden. Einige Unternehmen nutzen auch die Leistungen externer Dienstanbieter, um ihre private Cloud zu hosten. Bei privaten Clouds werden die Dienste und Infrastrukturkomponenten in einem privaten Netzwerk verwaltet.
Hybrid Cloud
Die Hybrid Cloud ist eine Kombination aus öffentlichen und privaten Clouds, die über Technologien für eine gemeinsame Nutzung von Daten und Anwendungen verbunden sind. Die Hybrid Cloud erlaubt es Daten und Anwendungen, sich zwischen privaten und öffentlichen Clouds zu bewegen.
Arten von Cloud-Diensten
In der Regel lassen sich Cloud-Computing-Dienste in vier Kategorien unterteilen: IaaS (Infrastructure-as-a-Service), PaaS (Platform as a Service), SaaS (Software-as-a-Service) und serverloses Computing. Die folgende Übersicht zeigt, wie sich diese Dienste unterscheiden; wichtig ist dabei der Unterschied in der vom Kunden bzw. vom Cloudanbieter verwalteten Bestandteile.
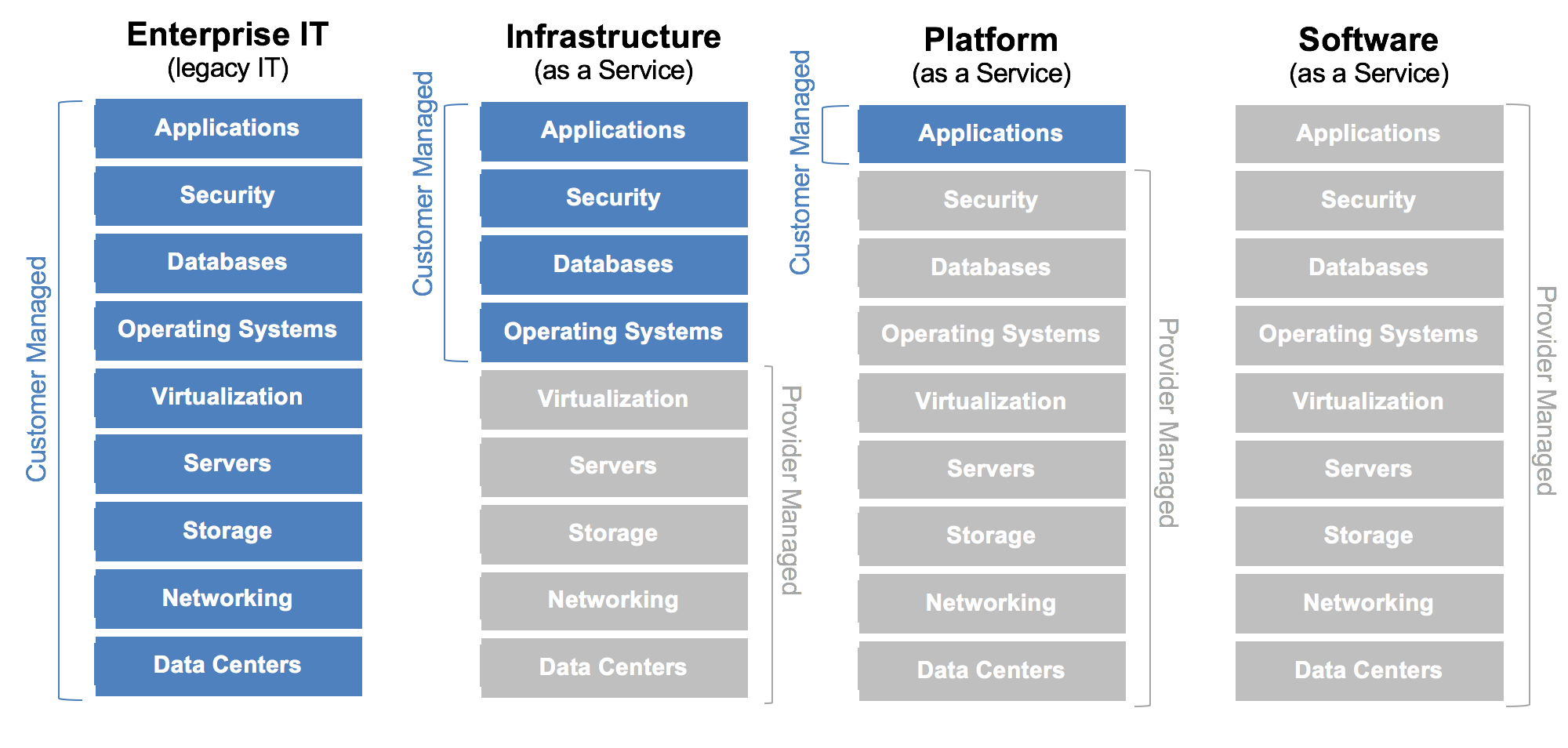
IaaS (Infrastructure-as-a-Service)
IaaS ist die einfachste Kategorie von Cloud-Computing-Diensten. Bei dieser nimmt man IT-Infrastruktur wie Server, virtuelle Computer, Speicher, Netzwerke und Betriebssysteme eines Cloudanbieters in Anspruch und entrichtet nutzungsbasierte Gebühren für diese Dienste.
Aufgrund der Tatsache, dass es derzeit wie in absehbarer Zukunft keine multidimensionale OLAP-Unterstützung sondern ausschließlich tabluarbasierte OLAP-Unterstützung in Microsoft Azure gibt und geben wird, nutzen wir IaaS für PoCs, da wir auf den damit bereitgestellten Virtual Machines die Freiheiten haben, welche die uns bekannte Technologie bietet. Auf diesen Virtual Machines stellen wir in den Workshops für die multidimensionale OLAP-Modelle unsere gewohnte Umgebung bereit – inklusive SQL Server.
PaaS (Platform-as-a-Service)
Bei PaaS handelt es sich um Cloud-Computing-Dienste, die eine bedarfsgesteuerte Umgebung für Entwicklung, Tests, Bereitstellung und Verwaltung von Softwareanwendungen anbieten. Mit einer solchen Lösung wird die schnelle Entwicklung von Web-Apps oder mobilen Apps vereinfacht, ohne dass man sich Gedanken um die Einrichtung oder Verwaltung der zugrunde liegenden Infrastruktur aus Servern, Speichern, Netzwerkkomponenten und Datenbanken machen muss, die für die Entwicklung benötigt werden.
SaaS (Software-as-a-Service)
SaaS ist eine Methode zur Bereitstellung von Softwareanwendungen über das Internet. Die Bereitstellung erfolgt nach Bedarf und in der Regel im Rahmen eines Abonnements. Bei SaaS werden Softwareanwendungen und zugrunde liegende Infrastrukturen von Cloudanbietern gehostet und verwaltet. Auch alle Wartungsaufgaben (z. B. Upgrades und Sicherheitspatches) werden vom Cloudanbieter übernommen. Benutzer verbinden sich über das Internet mit der Anwendung und verwenden dazu üblicherweise einen Webbrowser auf ihrem Mobiltelefon, Tablet oder PC. Die Entwicklung unseres Service für das Bissantz DashBoard unterliegt dieser Zielsetzung.
Microsoft Azure-spezifische Begriffe
Wir nutzen derzeit vor allem den Clouddienst Azure von Microsoft. Daher bezieht sich der folgende Abschnitt auf Azure-spezifische Begriffe, die sich in unserem Umfeld von BI befinden. Obwohl sich die Welt rund um Cloud Computing vor allem auch um nicht-relationale Datenbanken („NoSQL-Datenbanken“) dreht, gibt es selbstredend weiterhin die uns geläufigen SQL-Datenbanken; diese al-lerdings in verschiedenen Formen für verschiedene Spielarten.
Azure SQL-Datenbank: Einzeldatenbank
Azure SQL-Datenbank ist eine relationale DBaaS-Lösung (Database-as-a-Service) und basiert auf der neuesten stabilen Version der Microsoft SQL Server-Datenbank-Engine. SQL-Datenbank ist eine zuverlässige, sichere Hochleistungsdatenbank, mit der man neue Anwendungen, Websites und Microservices in der Programmiersprache seiner Wahl erstellen kann, ohne dabei eine Infrastruktur verwalten zu müssen. Die Datenbank lässt sich jedoch konfigurieren – entweder anhand eines DTU-basierten (d. h. „Data Throughput Units, die eine vorgefertigte Bündelung an Compute- und Speicherpaketen widerspiegeln) oder eines vCore-basierten (d. h. virtuelle Kerne, die individueller konfigurierbar sind und flexibler eingesetzt werden können) Kaufmodells. Letztgenanntes wird dabei von Microsoft Azure empfohlen.
Pool für elastische SQL-Datenbanken
Pools für elastische SQL-Datenbank-Instanzen sind eine kostengünstige Lösung zum Verwalten und Skalieren mehrerer Datenbanken mit variierenden und unvorhersehbaren Anforderungen, wie es bei Kunden in bestimmten Zeiträumen der Fall ist. Die Datenbanken in einem Pool für elastische Datenbanken befinden sich auf einem einzelnen Azure SQL-Datenbank-Server und nutzen gemeinsam eine festgelegte Anzahl von Ressourcen zu einem festen Preis. Mit Pools für elastische Datenbanken in Azure SQL-Datenbank sind SaaS-Entwickler in der Lage, das Preis-Leistungs-Verhältnis einer Gruppe von Datenbanken im Rahmen eines vorgegebenen Budgets zu optimieren und gleichzeitig eine flexible Leistung für jede Datenbank sicherzustellen. Für Pools für elastische Datenbanken erfolgt die Abrechnung auf Stundenbasis, in der ein Pool auf der höchsten Ebene existiert.
Verwaltete Instanz („managed instance“)
Eine verwaltete Instanz ist eine Bereitstellungsoption von Azure SQL-Datenbank, die für die Kompatibilität mit der aktuellen lokalen SQL Server-Datenbank-Engine (Enterprise Edition) sorgt. Mit diesem Bereitstellungsmodell können bestehende SQL-Server-Kunden ihre lokalen Anwendungen mit minimalen Änderungen an den Anwendungen und Datenbanken per „Lift & Shift“ zur Cloud migrieren. Gleichzeitig wird die Bereitstellungsoption für die verwaltete Instanz beibehalten (automatisches Patchen und automatische Versionsupdates, automatische Sicherungen, Hochverfügbarkeit), was den Verwaltungsaufwand und die Gesamtkosten reduziert.
Azure Synapse (ehemals Azure SQL Data Warehouse)
Vielleicht etwas irreführend ist die Bezeichnung „Azure Synapse“. Seit Anfang November lautet nämlich das ehemals bezeichnete Azure SQL Data Warehouse nun so. Darunter versteht Microsoft die Kombination aus Data Warehoussing mit Big-Data-Analysen. Im Fokus steht hier die Verarbeitungsgeschwindigkeit, die für Big-Data-Analysen vonnöten ist – mittels MPP („massive parallel processing“, d. h. Verteilung der Verarbeitungskapazität auf beliebigen Compute-Einheiten mit integrierter Logik und konzertierter Ausgabe). Durch die dahinter existierende Entkopplung von Speicher- und Computeressourcen kann man bei der Verwendung von SQL-Analyse folgende Aktionen ausführen:
- Anpassen der Größe der Compute-Leistung unabhängig von den Speicheranforderungen
- Vergrößern oder Verkleinern der Compute-Leistung innerhalb eines SQL-Pools (Data Warehouse), ohne Daten verschieben zu müssen
- Anhalten der Compute-Kapazität ohne Beeinträchtigung der Daten (und nur Bezahlung für den Speicher)
- Fortsetzen der Compute-Kapazität während der Betriebszeiten
Azure Data Factory
Ein sehr mächtiger, serverloser und bedarfsgesteuert skalierbarer Datenintegrationsdienst ist die Azure Data Factory, die eine noch umfangreichere Form von SSIS darstellt. Damit erstellt man ETL- und ELT-Vorgänge entweder ohne Code über eine visuelle Umgebung oder über eigens verfassten Code zur Automation. Für die Integration von Datenquellen stehen derzeit 85 nativ erstellte Connectors zur Verfügung, die nicht gewartet werden müssen – ohne dass zusätzliche Kosten anfallen. Dabei lassen sich einfache Datenkopierprozesse genauso durchführen wie komplexere Datenintegrationsworkflows, egal ob von OnPremise-Systemen in die Cloud oder zurück, genauso wie innerhalb der Cloud. Die vordefinierten Connectors übernehmen dabei die Hauptaufgabe zügig und fehlerfrei und werden per Trigger oder Zeitplan gesteuert. Die Einrichtung der Azure Data Factory gelingt binnen Minuten.
Azure Cosmos DB
Die Azure Cosmos DB ist ein vollständig verwalteter Datenbankdienst, der den Fokus auf die globale, sofort einsatzbereite Verteilung und Multimasterreplikation legt. Er bietet Latenzen für Lese- und Schreibvorgänge im Millisekundenbereich im 99. Perzentil, automatische und elastische Skalierung von Durchsatz und Speicher weltweit, 99,999 Prozent Hochverfügbarkeit sowie fünf genau definierte Konsistenzoptionen, die berücksichtigen, ob entweder das Lesen von korrekten Datensätzen oder die Abfrageleistung im Vordergrund steht. Der große Vorteil an Cosmos DB besteht darin, dass die Datenbank global repliziert wird und so die Kunden, die über Anwendungen Abfragen auf die Datenbanken vornehmen (z. B. beim Online-Shopping), immer die Datenbank nutzen, die in ihrer Nähe ist. Die genannten, geringen Latenzzeiten sind bei weltweit eingesetzten Lösungen eine gute Alternative. Cosmos DB bietet verschiedene APIs zum Arbeiten mit den in der Cosmos-Datenbank gespeicherten Daten. Standardmäßig kann man zum Abfragen der Cosmos-Datenbank SQL verwenden; Cosmos DB implementiert auch APIs für andere Datenbanken wie Cassandra, MongoDB, Gremlin und Azure Table Storage.
