Mit Hilfe von Satzarten können unterschiedliche Sichten auf Bewegungsdaten für Berichte und Analysen modelliert werden. Dabei werden Datensätze in zwei oder mehr Faktentabellen – je nach Anzahl der Sichten – vervielfacht. Gerade in größeren Faktentabellen, beispielsweise mit Rechnungsdaten, kann das zu langen Befüllungszeiten führen. Dieser Beitrag zeigt eine neue platzsparende Vorgehensweise mit fragmentierten Satzarten.
Bewegungsdaten wie Auftrags- oder Rechnungsdaten bilden im Business Intelligence normalerweise die Sicht des verwendeten Hauptquellsystems, in der Regel also von SAP- oder anderen ERP-Systemen. In dieser Sicht werden Kunden, Artikel und ähnliche zentrale Dimensionen gemäß der Geschäftsvorfälle erfasst. Abweichend zu dieser Erfassung der Bewegungsdaten kann es jedoch weitere Sichtweisen auf das Geschehen geben: So ist es zum Beispiel möglich, dass ein Kunde eine zentrale Bestellung für mehrere Filialen aufgibt. Hinter dieser Bestellung verbergen sich also eigentlich mehrere Kunden. Um die Anzahl der tatsächlich zu beliefernden Kunden auszuwerten, ist in diesem Fall also eine neue Sicht auf die Bewegungsdaten notwendig, die nicht der Standardsicht des Vorsystems entspricht.
Bisherige Implementierung und neuer Lösungsansatz
Um mehrere Sichten auf grundsätzlich identische Bewegungsdaten zu ermöglichen, werden in der multidimensionalen Modellierung üblicherweise sogenannte Satzarten verwendet. Mit diesen Satzarten werden Bewegungsdaten mehrfach in die Faktentabellen eingefügt und dabei jeweils einer unterschiedlichen Sichtweise zugeordnet. Bei Rechnungen kann das beispielsweise eine Zeitsicht sein (Bestelldatum vs. Lieferdatum), eine Währungssicht (Transaktionswährung vs. Konsolidierungswährung) oder verschiedene Kundensichten (Rechnungsempfänger vs. Lieferempfänger). Eine zusätzlich angebundene Schalterdimension dient dazu, zwischen den verschiedenen Sichten im Front-end unterscheiden zu können:
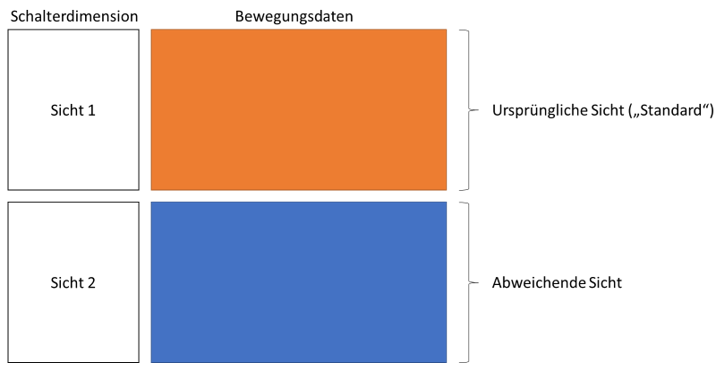
Abb. 1: Übliche Verwendung von Satzarten
Dieses Vorgehen kommt ohne größere Strukturanpassungen aus, abgesehen von der Anlage einer Schalterdimension. Außerdem ist die Verwendung von Satzarten in der Umsetzung und Bedienung denkbar einfach: Es bedarf keiner Anpassung im Cubeskript (vgl. LinkMember-Ansatz bei der Modellierung mehrerer Zeitdimensionen) und im Front-end ist die sprechende Auswahl zwischen den Sichten verständlich. Zusätzlich sind Durchgriffe auf relationale Daten leicht möglich, da es keine „unsichtbaren“ Anpassungen per MDX gibt, die beim SQL-Durchgriff relational übersetzt werden müssen.
Nachteil dieses Ansatzes ist jedoch, dass Bewegungsdaten, von denen es üblicherweise ohnehin schon viele gibt, noch je nach Anzahl der Sichten vervielfacht werden – im einfachsten Fall um den Faktor zwei. Das beansprucht nicht nur deutlich mehr Speicherplatz, es verlangsamt auch die Befüllung der Faktentabellen. Dabei ist eine Vervielfachung nicht für alle Daten notwendig: Im Fall von Währungssichten unterscheidet sich die Transaktionswährung nur selten von der Konsolidierungswährung. Im Fall von Kundensichten ist der bestellende Kunde häufig auch der Lieferempfänger. Es gibt also einige Datensätze, die keine Aufschlüsselung bzw. abweichende Sicht benötigen, aber standardmäßig bei der Verwendung von Satzarten ebenfalls vervielfacht werden:
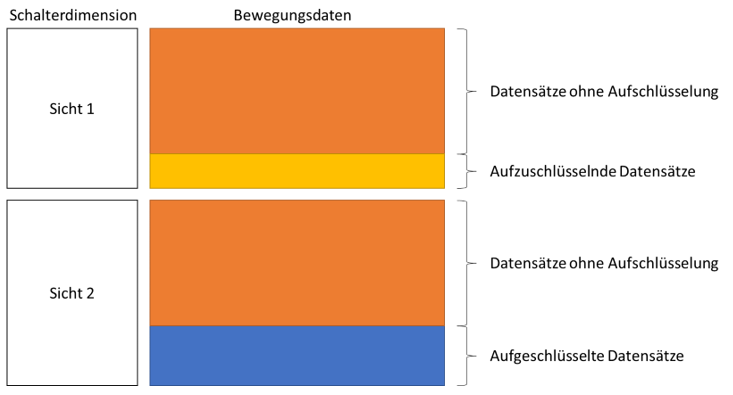
Abb. 2: Satzarten mit unnötiger Verdopplung nicht aufzuschlüsselnder Datensätze
Mit einem neuen Ansatz können wir diese unnötige Vervielfachung vermeiden und lediglich die aufzuschlüsselnden Datensätze in einen zweiten Satz übernehmen. Hierfür muss eine zweite Hilfsdimension zur Unterscheidung zwischen den beiden Sichten eingeführt werden – hauptsächlich, um die Standardsicht auszuwählen. Mit dieser Hilfsdimension werden satzübergreifend diejenigen Datensätze markiert, die in der entsprechenden Sicht angezeigt werden sollen:
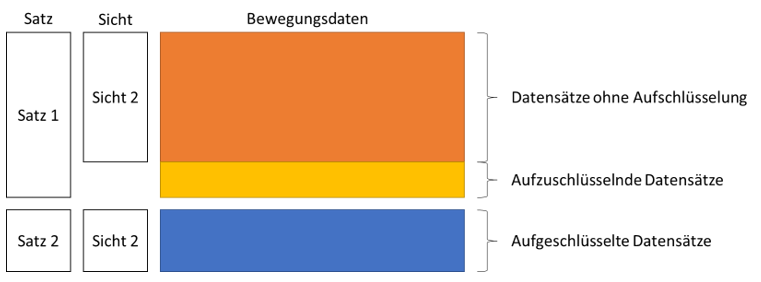
Abb. 3: Fragmentierte Satzarten ohne Redundanz der nicht aufzuschlüsselnden Datensätze
Mit dieser neu geschaffenen Struktur werden nur diejenigen Datensätze vervielfacht, die von einem Perspektivwechsel in der zweiten Sicht betroffen sind. Die Sichten werden über mehrere Sätze hinweg fragmentiert. Die Filterung, um die entsprechende Sicht zu erhalten, wird dadurch jedoch komplizierter: Für die Anzeige der Standardsicht gilt es, die Satzdimension auf Satz 1 zu filtern und keine Einschränkung in der Sicht-Dimension vorzunehmen. Für die alternative Sicht wiederum gilt es, die Sicht-Dimension auf Sicht 2 einzustellen und die Satz-Dimension nicht einzuschränken. So können beide gewünschten Sichtweisen eingestellt werden, ohne unnötig Datensätze zu vervielfachen. Um die Bedienung im Front-end mit DeltaMaster zu vereinfachen, sollte lediglich eine der beiden Hilfsdimensionen sichtbar sein und alle Sichtweisen anbieten. Dafür muss eine Ergänzung im Cubeskript vorgenommen werden, die im folgenden Abschnitt beschrieben wird im Rahmen einer Beispiel-Implementierung.
Implementierung am Beispiel-Szenario
In unserem Beispiel geht die fiktive Chair AG davon aus, dass der Kunde „Bundesagentur für Arbeit“ Bestellungen ausschließlich für die Verteilung an die Niederlassungen „Agentur für Arbeit Nürnberg“ und „Agentur für Arbeit Fürth“ vornimmt. Grundsätzlich kann man für eine solche Aufschlüsselung sehr präzise vorgehen und je nach vorhandenen Informationen sogar bis aus Belegebene aufschlüsseln. In diesem Beispiel nehmen wir zur Vereinfachung an, dass bei jeder vorgenommenen Bestellung 70 % auf die Agentur in Nürnberg entfallen und 30 % auf die in Fürth.
Um die Verteilungslogik abzubilden, ist eine Strukturtabelle notwendig, die im einfachsten Fall (wie in diesem Beispiel) ein konstantes Verhältnis angibt, in dem Bestellungen von einer Zentrale an Filialen verteilt werden. Diese Tabelle („T_S_Filialverteilung“) beinhaltet hier die bestellenden Kunden, die Zielkunden sowie den Aufteilungsschlüssel:

Abb. 4: Aufschlüsselungstabelle T_S_Filialverteilung
Bei genaueren Informationen könnten in der Aufschlüsselungstabelle neben dem ursprünglichen und dem Zielkunden z. B. auch Belegnummern oder genaue Stückzahlen pro Zielkunde aufgeführt werden.
Um die beiden Hilfsdimensionen anzulegen, wird jeweils eine weitere Strukturtabelle benötigt: Die Tabelle „T_S_Erweiterungssicht“ dient dazu, den Satz zu identifizieren, während „T_S_Filialverteilungssicht“ notwendig ist für die Identifikation der für die Sicht relevanten Datenätze.

Abb. 5: Quelltabellen für die Hilfsdimensionen T_S_Erweiterungssicht und T_S_Filialverteilungssicht
Mit diesen Tabellen können nun zunächst neue Dimensions-Views angelegt werden:
CREATE VIEW dbo.V_Import_Dim_Erweiterungssicht AS
SELECT
ErweiterungssichtID
,ErweiterungssichtBEZ
FROM dbo.T_S_Erweiterungssicht
GO
CREATE VIEW dbo.V_Import_Dim_Filialverteilungssicht AS
SELECT
FilialverteilungssichtID
,FilialverteilungssichtBEZ
FROM dbo.T_S_FilialverteilungssichtAnschließend wird die View für die Faktentabelle angepasst, sodass zwei Sätze entstehen: Ein ohnehin vorhandener Satz für die Standardsicht und ein neuer Satz, der lediglich aufgeschlüsselte Datensätze enthält. In der bisherigen Standardsicht (Satz 1) wird jeder Datensatz darauf überprüft, inwiefern er auch für die zweite Sicht relevant ist. Dies ist der Fall, wenn für diesen Datensatz keine Aufschlüsselung gewünscht ist und den sich demnach also beide Sichten teilen sollen. Die beiden neuen Sätze werden per „UNION ALL“-Operator miteinander verbunden:
CREATE VIEW dbo.V_Import_Fact_Deckungsbeitragsrechnung AS
WITH CTE_Kunden_Filailverteilung AS (
SELECT DISTINCT
OrderingCustomerID AS OrderingCustomerID
FROM T_S_Filialverteilung
)
--Satz 1: Standardsicht
SELECT db.MONTH AS Periode
,CONVERT(int,db.MONTH/100) AS Jahr
,db.Valuetype AS WertartID
,db.Product AS ProduktID
,db.Customer AS KundeID
,1 AS ErweiterungssichtID --Angabe des Satzes in diesem Fall Satz 1
,CASE
WHEN fv.OrderingCustomerID IS NOT NULL THEN 0
ELSE 1
END AS FilialverteilungssichtID --Anzeige nur, falls keine Aufschlüsselung gewünscht
,db.Discount AS Rabatt
,db.Labour AS Lohnkosten
,db.Material AS Materialkosten
,db.Revenues AS Umsatz
,db.SD AS Erlösschmälerungen
,db.Volume AS Absatz
,1 AS AnzahlBelegpositionen
FROM dbo.T_IMPORT_Deckungsbeitragsrechnung db
LEFT JOIN CTE_Kunden_Filailverteilung fv
ON db.Customer = fv.OrderingCustomerID
UNION ALL
--Satz 2: Lediglich aufgeschlüsselte Datensätze
SELECT db.MONTH AS Periode
,CONVERT(int,db.MONTH/100) AS Jahr
,db.Valuetype AS WertartID
,db.Product AS ProduktID
,fv.TargetCustomerID AS KundeID
,2 AS ErweiterungssichtID --Angabe des Satzes in diesem Fall Satz 2
,1 AS FilialverteilungssichtID --Wird in aufgeschlüsselter Sicht stets an-gezeigt
,db.Discount * fv.DistributionPercentage AS Rabatt
,db.Labour * fv.DistributionPercentage AS Lohnkosten
,db.Material * fv.DistributionPercentage AS Materialkosten
,db.Revenues * fv.DistributionPercentage AS Umsatz
,db.SD * fv.DistributionPercentage AS Erlösschmälerungen
,db.Volume * fv.DistributionPercentage AS Absatz
,1 AS AnzahlBelegpositionen
FROM dbo.T_IMPORT_Deckungsbeitragsrechnung db
LEFT JOIN T_S_Filialverteilung fv
ON db.Customer = fv.OrderingCustomerID
WHERE fv.OrderingCustomerID IS NOT NULLSind die relationalen Vorbereitungen getroffen, können die Sichten in DeltaMaster ETL modelliert werden. Dafür werden die beiden Hilfsdimensionen mit unterschiedlichen Eigenschaften für das All-Element angelegt:

Abb. 6: Anlage der Hilfsdimensionen in DeltaMaster ETL
Hintergrund dieser unterschiedlichen Eigenschaften ist, dass die Filialverteilungssicht in Front-end von DeltaMaster verborgen werden soll. Deshalb wird ein All-Element vergeben, um die Filterung auf diese Dimension später leichter aufheben zu können. In der Dimension Erweiterungssicht darf wiederum kein All-Element vorliegen, damit unterschiedliche Sichten nicht vermischt werden können. Da für beide Hilfsdimensionen stets eine Ausprägung in der Faktentabelle vorhanden ist, sollten keine Default-Werte eingefügt werden. Anschließend werden die Dimensionen an die entsprechende Measure Group angebunden.

Abb. 7: Anbindung der Hilfsdimensionen an die Measure Group
Nach dem Aufbau des Modells in DeltaMaster können zunächst beide Hilfsdimensionen in Kombination verwendet werden, um die entsprechende Darstellungsform zu erzielen:
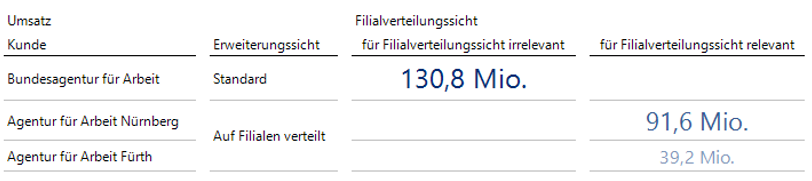
Abb. 8: Ansicht der beiden Hilfsdimensionen in DeltaMaster
Für ausschließlich von der Aufschlüsselung betroffene Kunden ist diese Darstellung bereits korrekt. Kommen jedoch weitere Kunden hinzu, die von der Aufschlüsselung nicht betroffen sind, kann die Darstellung etwas verwirrend sein (vgl. Abbildung 9).
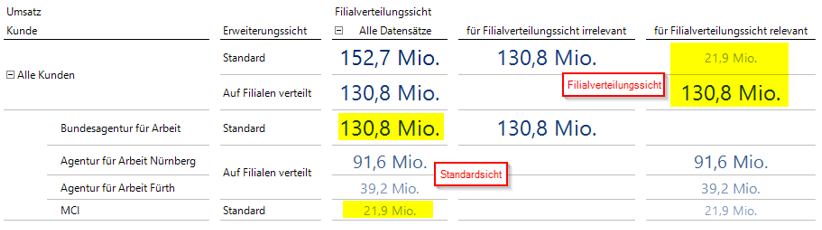
Abb. 9: Kombinationen der Hilfsdimensionen bei nicht betroffenen Elementen
Markiert sind hier jeweils die sinnvollen Kombinationen der Hilfsdimensionen: Die in Abbildung 9 rot bezeichnete „Standardsicht“ stellt die Erweiterungssicht Standard ohne Einschränkung der Filialverteilungssicht dar. Die rot bezeichnete „Filialverteilungssicht“ stellt die Filialverteilungssicht in der Spalte „für Filialverteilungssicht relevant“ ohne Einschränkung der Erweiterungssicht dar. Um diese beiden Kombinationen komfortabel zugänglich zu machen und Doppelungen der Werte vorzubeugen, empfiehlt es sich, die Dimension „Filialverteilungssicht“ zu verbergen. Das funktioniert via Cube-Anpassung oder mit der Perspektive in DeltaMaster. Im Cubeskript ist folgende Ergänzung vorzunehmen:
CREATE MEMBER CURRENTCUBE.[Erweiterungssicht].[Erweiterungssicht].[All] AS
AGGREGATE(
{[Erweiterungssicht].[Erweiterungssicht].[Erweiterungssicht].&[1],
[Erweiterungssicht].[Erweiterungssicht].[Erweiterungssicht].&[2]}
)
,VISIBLE=0;
CREATE MEMBER CURRENTCU-BE.[Erweiterungssicht].[Erweiterungssicht].[Filialverteilungssicht] AS
NULL
,VISIBLE=1;
SCOPE (
[Erweiterungssicht].[Erweiterungssicht].[Filialverteilungssicht]
,Measuregroupmeasures('Deckungsbeitragsrechnung')
);
THIS = ([Erweiterungs-sicht].[Erweiterungssicht].[All],[Filialverteilungssicht].[Filialverteilungssicht].[Filailverteilungssicht].&[1]);
END SCOPE;Damit wird zunächst ein künstliches All-Element für die Erweiterungssicht angelegt, welches jedoch in DeltaMaster nicht sichtbar ist. Anschließend wird ein neues Mitglied in der Erweiterungssicht hinzugefügt, das per SCOPE-Anweisung dazu verwendet wird, die korrekte Filialverteilungssicht sowie das künstliche All-Element der Erweiterungssicht zu kombinieren. In DeltaMaster werden in der Erweiterungssicht nun drei Elemente angeboten:
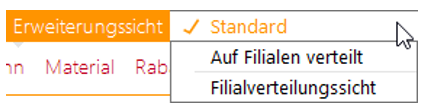
Abb. 10: Angebotene Erweiterungssichten in DeltaMaster
Je nach analytischer Fragestellung kann nun zwischen der Standardsicht (entspricht dem Vorsystem), einer reinen Sicht auf verteilte Elemente und einer Filialverteilungssicht unterschieden werden. Letztere beinhaltet sowohl nicht zu verteilende Elemente der Standardsicht als auch verteilte Elemente der Filialverteilung.

Abb. 11: Finale Ansicht der fragmentierten Satzarten in DeltaMaster
Sollte die mittlere Sicht nicht gewünscht sein, in der lediglich die verteilte Datenätze dargestellt werden, so kann in Berichten, in denen zwischen den Sichten gewechselt werden darf, der Filterkontext für den Betrachter entsprechend eingeschränkt werden.
Diskussion und Limitationen
Die Idee zu den fragmentierten Satzarten stammt aus einem Kundenprojekt, in dem diese Art der Aufschlüsselung seit mehreren Jahren erfolgreich eingesetzt wird. Sie kann zu einer Reduktion der Datenmenge in Faktentabellen führen, wenn bereits Satzarten für verschiedene Perspektiven auf Bewegungsdaten verwendet werden. Im konkreten Anwendungsfall bei unserem Kunden wurde die Menge an Bewegungsdaten bei gleichem Informationsgehalt von 77.116 Zeilen bei klassischer Verwendung von Satzarten auf 42.236 verringert (- 45 %). Dies liegt jedoch auch daran, dass relativ wenige Transaktionen aufzuschlüsseln waren (rund 5 %). Je mehr Transaktionen aufzuschlüsseln sind, desto geringer fällt die Datenersparnis aus. Muss jede einzelne Transaktion aufgeschlüsselt werden, können ohnehin reguläre Satzarten verwendet werden. Wie effektiv der neue Ansatz ist, hängt also maßgeblich von der Anzahl der Datensätze ab, die aufzuschlüsseln sind: Je weniger Daten mit unterschiedlichen Sichten betrachtet werden können, desto sinnvoller ist es, fragmentierte Satzarten zu nutzen.
Darüber hinaus ist sind die fragmentierten Satzarten hauptsächlich für Dimensionen abseits der Zeitdimension geeignet. Bei der Verwendung von Satzarten für unterschiedliche Datumssichten (bspw. Bestelldatum vs. Lieferdatum) gilt in der Regel, dass diejenigen Einträge, für die es noch keine Entsprechung gibt, nicht in den zweiten Satz aufgenommen werden (wenn also ein Artikel zwar bestellt, aber noch nicht geliefert wurde). Durch die fehlende Redundanz der Einträge aus dem ersten Satz können mit der Verwendung von fragmentierten Satzarten keine Daten gespart werden. Fragmentierte Satzarten ergeben also nur dann Sinn, wenn jeder zusätzliche Satz ursprünglich sowohl nicht aufzuschlüsselnde als auch aufgeschlüsselte Transaktionen enthält und es damit redundante Transaktionen in beiden Sätzen gibt.
Eine Stärke der fragmentierten Satzarten ist es, mit mehreren Aufschlüsselungen pro Datensatz umgehen zu können – beim LinkMember-Ansatz ist das nicht möglich. Im hier beschriebenen Beispiel wurden zwei tatsächliche Warenempfänger übernommen anstelle eines einzelnen Kunden als Warenempfänger. Dies ist lediglich mit einer zusätzlichen Spalte in der Faktentabelle, die den tatsächlichen Warenempfänger angibt, nicht möglich. Daraus folgt, dass fragmentierte Satzarten insbesondere für Fälle geeignet sind, in denen eine Transaktion auf mehrere Transaktionen aufgeteilt werden soll.
Da in der vorgestellten Variante der fragmentierten Satzarten auch Anpassungen im Cubeskript vorgenommen wurden inkl. der Erstellung eines künstlichen Elements in der Erweiterungssicht, gibt es Einschränkungen bei der Verwendung des SQL-Durchgriffs. Die Verwendung der Sicht „Standard“ ist ohne Einschränkungen möglich. Auch die aufgeschlüsselten Werte lassen sich mit dem SQL-Durchgriff problemlos durch die Verwendung der Erweiterungssicht anzeigen. Für die Anzeige der aufgeschlüsselten Transaktionen in Verbindung mit den nicht aufzuschlüsselnden Transaktionen müssen allerdings beide Dimensionen verwendet werden:
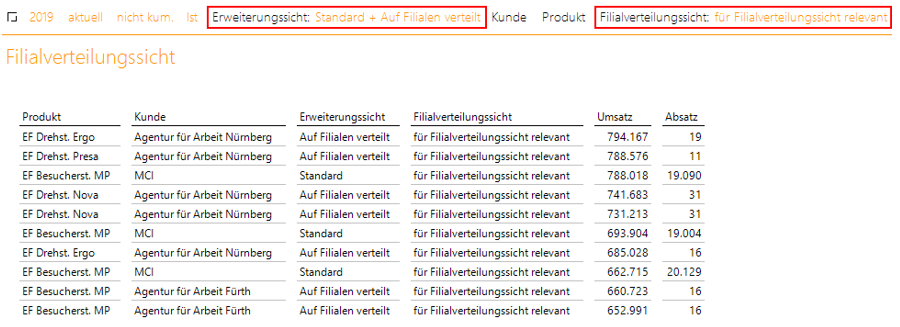
Abb. 12: SQL-Durchgriff mit fragmentierten Satzarten
Für Verknüpfungen in einem solchen SQL-Durchgriff sollte also darauf geachtet werden, dass für das künstliche Element keine Filterung übergeben wird und der Zielbericht entsprechend vorgefiltert ist.
Fazit
Mit der Verwendung von fragmentierten Satzarten lassen sich Speicherplatz und Verarbeitungszeit einsparen. Voraussetzung für eine solche Ersparnis ist, dass nur ein Teil der Bewegungsdaten für verschiedene Sichten aufzuschlüsseln ist und dass jeder zusätzliche Satz ursprünglich sowohl nicht aufzuschlüsselnde als auch aufgeschlüsselte Transaktionen enthält. Der Ansatz ist für Anwender leicht zu bedienen und kann mit Mehrfachaufschlüsselungen (mehrere Aufschlüsselungsziele pro Transaktion) umgehen.
