Die Archivierung und das Abbilden historischer Bestandsdaten ist in vielen Projekten eine Notwendigkeit, um Veränderungen der Bestände im zeitlichen Verlauf betrachten zu können. Vor allem dann, wenn im Vorsystem nur die aktuellen Bestände abgebildet werden und keine historischen Daten vorliegen. Bestandsdaten über Differenzen der aktuellen Daten zu den vorhergehenden Daten zu ermitteln ist eine bekannte und effektive Methode. Wie Differenzen mit den Windows-Functions in SQL-Server auf einfache Art umgesetzt und über Kumulation im Cube-Skript die Bestandsdaten berechnet werden, zeigt dieser Blogbeitrag.
Zum Thema Bestand und wie man damit relational und in OLAP-Modellen umgeht, gibt es bereits einige Blogbeiträge:
- Februar 2010 „Bestandsbetrachtungen“
- April 2010 „Historische Betrachtung von Bestandswerten“
- Mai 2016 „Aufbau einer Bestandslogik“
Die seit 2012 in Microsoft SQL-Server eingeführten Windows-Functions ermöglichen hier neue Lösungsansätze, die die Abbildung eines historischen Bestands deutlich vereinfachen. Diese Lösung funktioniert auch mit einer SQL-Standardedition, da in MDX kein „LastNonEmpty“ benötigt wird.
Dies soll in diesem Blogbeitrag anhand eines einfachen Beispiels in unserer bekannten Demo-Datenbank Chair veranschaulicht werden.
Lagerbestand archivieren
Als Beispiel für eine Bestandsrechnung wurde ein Lagerbestand gewählt. Dieser Lagerbestand wird täglich aktuell geliefert, historische Daten zu den Lagerbeständen liegen im Vorsystem nicht vor, da der aktuelle Bestand täglich neu ermittelt und die vorhergehenden Bestandswerte überschrieben werden. Dieses Beispiel entspricht einer konkreten Situation bei einem Kunden. Der Einfachheit halber wird als Bestandswert nur die Lagermenge betrachtet, um das generelle Vorgehen anhand dieser Kennzahl zu demonstrieren.
Damit ergibt sich als erstes, dass die täglich gelieferten aktuellen Bestandswerte in eine Archivtabelle geschrieben werden müssen, damit ein zeitlicher Verlauf überhaupt abgebildet werden kann. Zusätzlich wird auch der aktuelle Lagerbestand in unser Modell aufgenommen.
In diesem Beispiel wurde davon ausgegangen, dass die Lagerbestandsmengen täglich geliefert werden, aber nur monatlich von Interesse sind. Ob die Bestandsänderungen tatsächlich täglich von Interesse sind, wie beispielsweise im Einzelhandel oder monatliche historische Werte ausreichen, ist jeweils zu hinterfragen – das monatliche Speichern von Bestandsdaten kann das Datenvolumen in der Archivtabelle erheblich verringern.
Es wurde eine Prozedur entwickelt, die die Daten jeweils am Monatsletzten in die Archivtabelle schreibt, unter Berücksichtigung, dass Datenimporte jeweils montags bis freitags stattfinden und damit der Monatsletzte auf einem Wochenende liegen kann. Für die verwendete Datenbank ist als Standardsprache Deutsch eingestellt. Andere Sprachen erfordern eine Anpassung im nachstehend abgebildeten Skript, da die Funktion DATEPART() hier andere Werte für Wochentage und Wochenende zurückliefern würde.
Da die Lagerbestandsmengen nächtlich importiert werden, bilden sie den Bestand des Vortages ab und werden mit dem Stichtag heute -1 abgebildet.



CREATE PROC [dbo].[P_APP_Lagerbestand_Archiv]
AS
BEGIN
-- ab 01.01.2020 Archivierung am Folgetag 6Uhr
-- daher getdate() - 1Tag für Stichtag, da der Bestand des Vortages geliefert wird
DECLARE @Stichtag date
DECLARE @Monatsende date
-- Datenaufbereitung montags - freitags (Datepart 1-5)
-- Ermitteln Stichtag unter Berücksichtigung von Wochenenden und Jahreswechsel
IF (DATEPART(dw,DATEADD(dd,-1,getdate()))) = 7
SET @Stichtag =
CASE WHEN YEAR(getdate()) > YEAR(EOMONTH(getdate(),-1))
THEN DATEADD(dd,CAST(DAY(getdate()) * -1 AS smallint),getdate())
ELSE DATEADD(dd,-3,getdate())
END
ELSE
SET @Stichtag = DATEADD(dd,-1,getdate())
-- Ermitteln Monatsende ohne Wochenende
SET @Monatsende =
CASE DATEPART(dw,EOMONTH(getdate(),-1))
WHEN 6
THEN DATEADD(dd,-1,EOMONTH(getdate(),-1))
WHEN 7
THEN DATEADD(dd,-2,EOMONTH(getdate(),-1))
ELSE EOMONTH(getdate(),-1)
END
-- Archivierung erfolgt nur am Monatsletzten
IF @Stichtag = @Monatsende
BEGIN
-- wurde heute bereits archiviert? Dann Daten mit diesem Stichtag erst löschen.
DELETE FROM T_Import_FACT_Lagerbestand_Archiv
WHERE Stichtag = @Stichtag
-- Einfügen neue Datensätze in das Archiv
INSERT INTO T_Import_FACT_Lagerbestand_Archiv (Stichtag, Lager_ID, ProductID, Lagermenge, Nettogewicht)
SELECT
@Stichtag AS Stichtag
, Lager_ID
, ProductID
, Lagermenge
, Nettogewicht
FROM dbo.T_Import_FACT_Lagerbestand_aktuell
END
END
Historische Lagerbestandswerte ermitteln
Mit der Archivtabelle und ihrer regelmäßigen Befüllung wurde die Grundlage für die Abbildung der historischen Lagerbestandswerte gelegt. Für das Abbilden des zeitlichen Verlaufs wird der Stichtag, an welchem die Daten archiviert werden, jeweils an die Datensätze angehängt.
Beim Stühlehersteller in diesem Beispiel kann davon ausgegangen werden, dass nicht jedes Stuhlmodell in jedem Monat aus jedem Lager geliefert oder neu eingelagert wird. Im vorliegenden Beispiel ist dies zwar tatsächlich der Fall, aber in der Realität wäre das sicher nicht so. Daher ist die bereits beschriebene Differenzenmethode (siehe: Bestandsbetrachtungen) sehr gut geeignet. Mit dieser Methode werden die Differenzen aus dem aktuellen Bestand und dem vorhergehenden Bestand gebildet.
Vorhergehender Bestand klingt nach Vorgänger und genau hier können wir die Windows-Function Lag() ins Spiel bringen. Lag() ermittelt den Vorgänger eines Elements in einer Datentabelle. Die Funktion an sich wird in diesem Beitrag als bekannt vorausgesetzt, kann aber auch unter https://docs.microsoft.com/de-de/sql/t-sql/functions/lag-transact-sql?view=sql-server-ver15 nachgelesen werden.
So könnte eine Sicht aussehen, die die Differenzen der Lagerbestandsmengen aus der Archivtabelle ermittelt:



ALTER VIEW [dbo].[V_Import_Fact_hist_Lagerbestand]
AS
WITH cte_Summe_Bestand
AS
-- Summierung ist dann notwendig, wenn es innerhalb eines Lagers Lagerbereiche oder -plätze gibt und diese auch in der monatlichen Datenlieferung enthalten sind, aber für die Berechnung des historischen Lagerbestandes keine Rolle spielen
(
SELECT
arc.Stichtag
, arc.Lager_ID AS LagerID
, arc.ProductID AS ProduktID
, arc.Nettogewicht
, SUM(arc.Lagermenge) AS Lagerbestandsmenge
FROM dbo.T_Import_FACT_Lagerbestand_Archiv arc
GROUP BY arc.Stichtag, arc.Lager_ID, arc.ProductID, arc.Nettogewicht
),
cte_Bestandsdifferenz
AS
(
SELECT
arc.Stichtag AS PeriodeID
, arc.LagerID
, arc.ProduktID
, arc.Nettogewicht
, arc.Lagerbestandsmenge - LAG(arc.Lagerbestandsmenge, 1, 0) OVER (PARTITION BY arc.LagerID, arc.ProduktID ORDER BY arc.Stichtag) AS Lagerbestandsmenge_Diff
, ROW_NUMBER() OVER (PARTITION BY arc.LagerID, arc.ProduktID ORDER BY arc.Stichtag) AS RowNum
FROM cte_Summe_Bestand arc
)
-- Startperiode Januar 2020
-- Startperiode enthält die Anfangswerte, zu denen die jeweiligen Differenzen später addiert werden können
SELECT
YEAR(PeriodeID) * 100 + MONTH(PeriodeID) AS MonatID,
'I' AS WertartID,
1 AS PeriodenansichtID,
1 AS KumulationID,
LagerID,
ProduktID,
-- Kennzahlen
Lagerbestandsmenge_Diff,
-- Info
Nettogewicht
FROM cte_Bestandsdifferenz
WHERE RowNum = 1
UNION ALL
-- Folgeperioden mit Mengendifferenzen
-- Ist die Mengendifferenz = 0, d.h. es hat in einem Monat keine Lagerbewegung zu diesem Artikel gegeben, so kann dieser Datensatz ausgeklammert werden
SELECT
YEAR(PeriodeID) * 100 + MONTH(PeriodeID),
'I' AS WertartID,
1 AS PeriodenansichtID,
1 AS KumulationID,
LagerID,
ProduktID,
-- Kennzahlen
Lagerbestandsmenge_Diff,
-- Info
Nettogewicht
FROM cte_Bestandsdifferenz
WHERE RowNum > 1
AND Lagerbestandsmenge_Diff <> 0.0
In der Sicht werden zunächst die Bestandssummen pro Lager und Produkt gebildet. Das wäre in diesem Beispiel nicht notwendig, ist aber in allen Fällen, in denen es Lagerbereiche und/oder – plätze gibt, die in den Datensätzen vorhanden sind, die für die Bestandbetrachtung selbst aber keine Rolle spielen, unverzichtbar. Daher ist diese Summenbildung zur Vollständigkeit mit aufgenommen worden.
Im folgenden Bereich (cte_Bestandsdifferenz) wird mittels der Lag()-Funktion der jeweilige Vorgänger-Datensatz ermittelt und von der aktuellen Lagermenge abgezogen:
![]()
Lagerbestandsmenge - LAG(Lagerbestandsmenge, 1, 0) OVER (PARTITION BY LagerID, ProduktID ORDER BY Stichtag)
Der Bereich, der bei der Vorgängersuche betrachtet werden soll, wird durch die LagerID und die ProductID bestimmt – daher stehen diese Elemente im PARTITION BY. Die Sortierung erfolgt nach dem Stichtag – also steht Stichtag im ORDER BY.
Im nun folgenden SELECT-Statement wird zunächst der erste verfügbare Datensatz ermittelt (Startperiode). In diesen Datensätzen stehen die Werte, die pro Lager und Produkt zu Beginn der Archivierung als Bestand vorlagen. Dafür wurde im Bereich cte_Bestandsdifferenz zusätzlich eine Zeilennummer (rownum()) ermittelt. Für die ersten Datensätze in der Archivtabelle ist diese Zeilennummer = 1. Bei allen Datensätzen mit einer Zeilennummer > 1 handelt es sich um Differenzbeträge.
Ausgeschlossen werden die Datensätze, bei denen die Differenz der Lagerbestandsmenge = 0 ist, da es in diesem Fall keine Änderung der Menge gegeben hat und man sich diesen Datensatz daher sparen kann.
Modellierung und MDX
Modelliert werden die historischen Lagerbestandswerte wie alle anderen Werte in unserem Modell auch, daher soll darauf nicht näher eingegangen werden. Nur eine Besonderheit sei erwähnt: Da die Lagerbestandsdifferenzen an sich als Werte uninteressant sind, können diese Werte auf „nicht sichtbar“ gestellt werden.
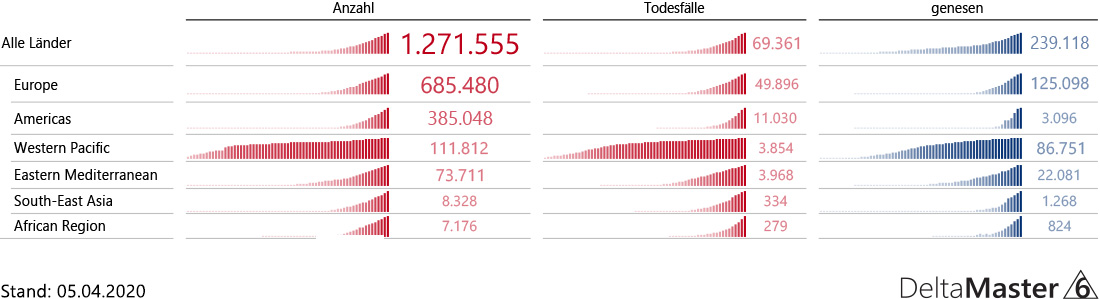 Abbildung 1: DeltaMaster ETL Kennzahl für historische Lagerbestandsmenge auf „nicht sichtbar“
Abbildung 1: DeltaMaster ETL Kennzahl für historische Lagerbestandsmenge auf „nicht sichtbar“
Ist das Modell aufbereitet, geht es mit dem Cube-Skript weiter.
Hier wird zunächst (sofern nicht bereits vorhanden) ein Kumulationselement benötigt, welches über alle Perioden kumuliert – es wird bezeichnet als kum_all:

CREATE MEMBER CURRENTCUBE.[Kumulation].[Kumulation].[kum_all]
AS
Aggregate(PeriodsToDate([Periode].[Periode].[(All)], [Peri-ode].[Periode].CurrentMember),[Kumulation].[Kumulation].[Kumulation].&[1])
,VISIBLE = 0;
Dieses Element wird in der Dimension Kumulation in DeltaMaster nicht benötigt, es ist für die Bestandsrechnung im Cube-Skript gedacht, daher kann es ebenfalls mit VISIBLE = 0 auf „nicht sichtbar“ gesetzt werden.
Die Berechnung der historischen Lagerbestandswerte ist nun denkbar einfach:

CREATE MEMBER CURRENTCUBE.[Measures].[Hist_Lagerbestandsmenge]
AS
([Kumulation].[Kumulation].[kum_all], [Measures].[Lagerbestandsmenge_Diff]),
VISIBLE = 1,
ASSOCIATED_MEASURE_GROUP = 'Lagerbestand_historisch';
Schauen wir uns nun die Werte in einer Analysesitzung an.
Im letzten importierten Monat, in welchem neben dem historischen Lagerbestand auch ein aktueller Lagerbestand vorzufinden ist, sollten beide Werte gleich sein. Der letzte befüllte Monat ist in dem Beispiel der September 2020.
In den zurückliegenden Monaten werden dagegen nur die historischen Lagerbestandswerte angezeigt, aktuelle gibt es hier nicht.
 Abbildung 2: Lagerbestandsmengen September 2020 im Vergleich aktuell zu historisch
Abbildung 2: Lagerbestandsmengen September 2020 im Vergleich aktuell zu historisch
Bis auf das Produkt „Hansen ZZ“ sind alle Werte, wie zu erwarten, gleich. Was ist bei diesem Produkt passiert?
Hierzu betrachtet man die Datensätze der Archivtabelle:
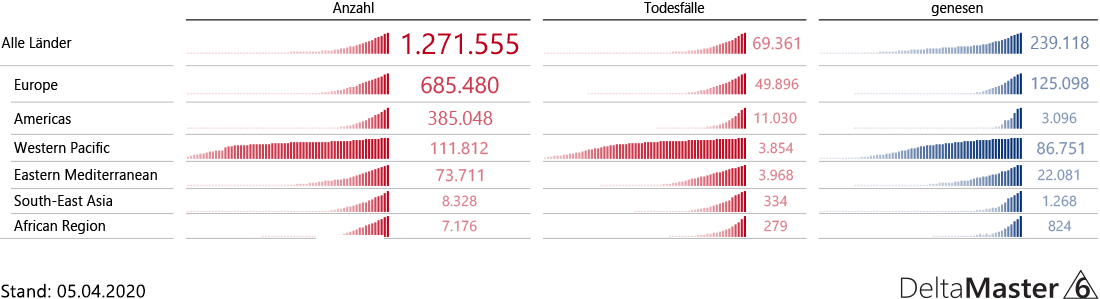
Abbildung 3: Daten Produkt „Hansen ZZ“ in Archivtabelle
Für September 2020 gibt es keinen Datensatz. Es werden somit keine Datensätze im aktuellen Lagerbestand geliefert, wenn das Lager aufgelöst oder der Bestand aus einem anderen Grund 0 beträgt. Wenn nun keine Tabelle mit Lagerbewegungen zur Verfügung steht, aus welcher dies hervorgehen würde, bleibt hier nur der Weg, Bestände, die im letzten Monat noch geliefert wurden und im aktuellen Monat nicht mehr, selbst auszubuchen.
Dafür wird die die oben aufgeführte Prozedur P_APP_Lagerbestand_Archiv um folgende Einträge ergänzt:


DECLARE @maxStichtag_Archiv date
SELECT
@maxStichtag_Archiv = MAX(Stichtag)
FROM dbo.T_Import_FACT_Lagerbestand_Archiv
-- Ausbuchen aktuell nicht mehr vorhandener Lagerbestände
-- Setzen des Lagerbestands auf 0
INSERT INTO T_Import_FACT_Lagerbestand_Archiv (Stichtag, ProductID, Lager_ID, Nettoge-wicht, Lagermenge)
SELECT
@Stichtag
, arc.ProductID
, arc.Lager_ID
, arc.Nettogewicht
, 0.0
FROM dbo.T_Import_FACT_Lagerbestand_Archiv arc
WHERE NOT EXISTS( SELECT * FROM dbo.T_Import_FACT_Lagerbestand_aktuell akt
WHERE akt.ProductID = arc.ProductID and akt.Lager_ID = arc.Lager_ID AND akt.PeriodeID = @Stichtag)
AND arc.Stichtag = @maxStichtag_Archiv
Hiermit werden Datensätze erzeugt, als hätte es einen Ausbuchungssatz mit der Menge = 0 für die entsprechenden Produkte im aktuellen Lagerbestand gegeben.
Wird das Produkt „Hansen ZZ“ im Lager Hamburg so ausgebucht, ergibt sich die erwartete Übereinstimmung der Lagerbestandsmengen aktuell und historisch im September 2020, dem letzten Monat mit befüllten Werten.

Abbildung 4: Lagerbestandsmengen September 2020 mit Ausbuchung für Produkt „Hansen ZZ“
Fazit
Das Ermitteln historischer Bestandsdaten als Differenz aus aktuellem Bestand und dem Bestand der vorhergehenden Periode ist eine effektive und Datenvolumen sparende Methode. Durch den Einsatz der Funktion Lag() wird diese Methode in der Umsetzung relativ einfach. Die Differenzen werden relational berechnet, ohne die Performance im Frontend negativ zu beeinflussen.
Gründliche Überlegungen im Vorfeld sind weiterhin notwendig, um Ausbuchungen oder auch die Periodizität der historischen Daten im Vorfeld zu definieren.
