Die Azure-Welt bringt viele Neuerungen für unsere Business-Intelligence-Systeme mit sich. Dabei verliert auch die klassische relationale Datenbank an Relevanz. Der Azure Data Lake Storage läuft ihr den Rang ab, allein aus Kostengründen. Die Datei im Data Lake nimmt den Platz der relationalen Tabelle ein. Am Ende der Architektur steht nach wie vor meist eine multidimensionale Datenbank, unter Azure allerdings lediglich die Tabular-Variante von Analysis Services. Dabei stellt sich die Frage, wie die Daten aus dem Azure Data Lake Storage in die Azure Analysis Services kommen und wie die Datenaufbereitung stattfindet.
Eine der vielen Möglichkeiten, um die beiden Services zu verbinden, ist Azure Synapse. Synapse kann in Azure Analysis Services direkt als Datenquelle angebunden werden, greift entweder per externer Tabelle oder per View auf den Data Lake zu und ist in Form der sogenannten „Serverless Pools“ auch günstig zu betreiben. Die Möglichkeiten und jeweiligen Vor- und Nachteile der unterschiedlichen Zugriffsformen von Synapse Serverless Pools auf den Azure Data Lake Storage Gen 2 sind Bestandteil dieses Beitrags.
BI-Architekturen im Vergleich: On-Premises vs. Azure
In der On-Premises-Welt des Microsoft SQL Server Frameworks haben sich die Architekturen in den letzten Jahrzehnten kaum geändert. Daten werden aus verschiedenen Vorsystemen in eine relationale Datenbank geladen und verarbeitet. Von hier werden die Daten von einer multidimensionalen Datenbank abgeholt und für die Analyse aufbereitet. Die Front-ends der Bissantz-Software greifen dann entweder auf die multidimensionale Datenbank zu oder auf die relationale Datenbank.
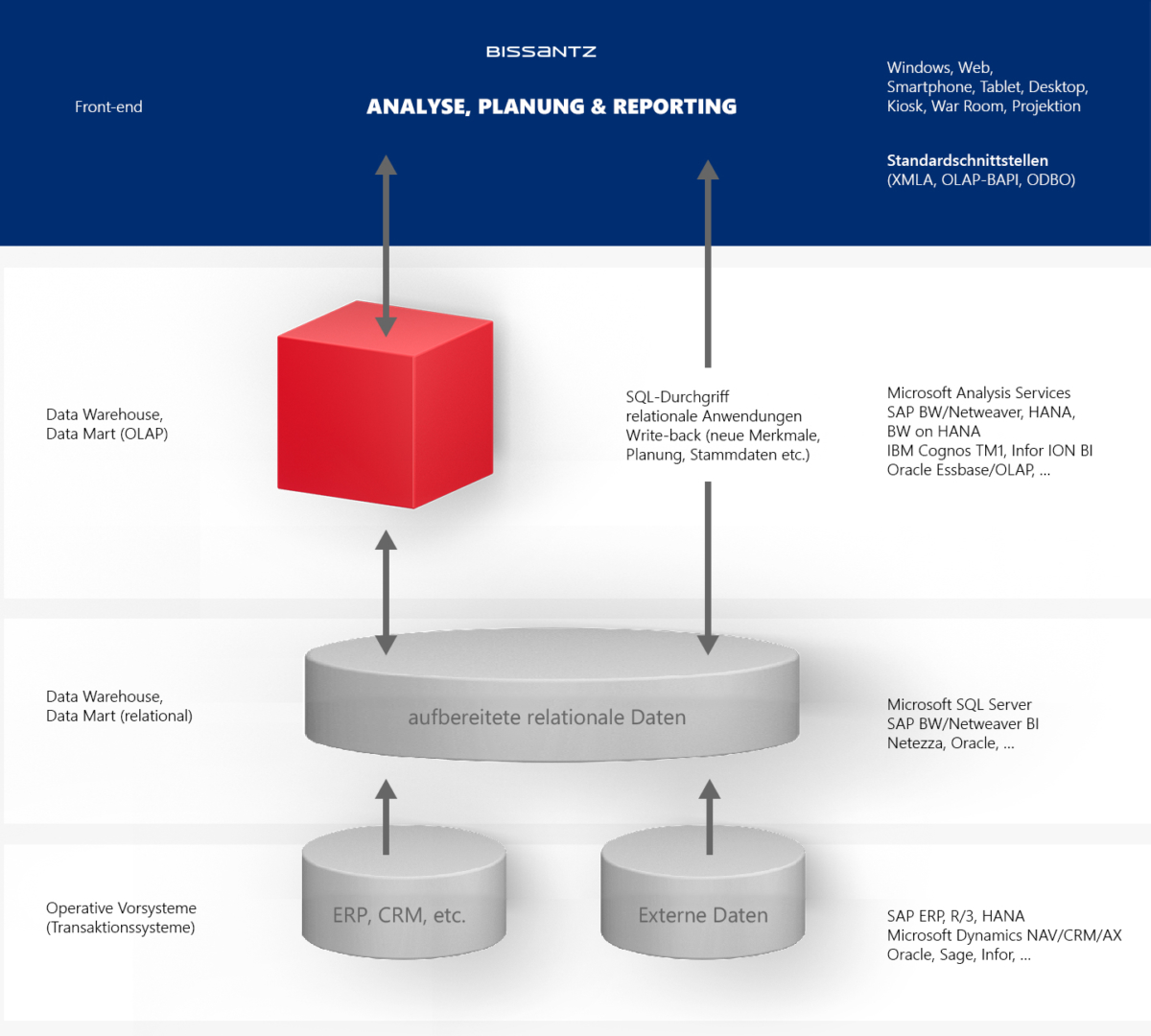
Abb. 1: On-Premises BI-Architektur
In Azure sieht die Welt etwas anders aus. Auch wenn es dort mit der Azure-SQL-Datenbank ein Pendant zum „alten“ SQL-Server gibt, ist die Architektur nicht eins zu eins übertragbar. Hauptgrund ist die Kostenstruktur in Microsoft Azure. Allein um Daten zu speichern, ohne sie zu verarbeiten, ist eine Azure SQL DB relativ teuer. Deutlich günstiger geht es mit dem Azure Data Lake Storage. Dort werden die Daten allerdings in Dateiform abgelegt, meist als Parquet- oder CSV-Datei. Leider können die Azure Analysis Services nicht direkt auf den Azure Data Lake Storage Gen 2 zugreifen. Daher ist eine Zwischenschicht nötig, um die Daten für die Analyseschicht bereitzustellen. Aus Kostengründen bietet sich hier Azure Synapse an. Im kompletten Framework von Azure Synapse gibt es zwar auch teure Komponenten (beispielsweise die Synapse Dedicated Pools), aber mit den Synapse Serverless Pools eben auch sehr kostengünstige Optionen. Sie schließen perfekt die Lücke in der gezeigten Architektur.
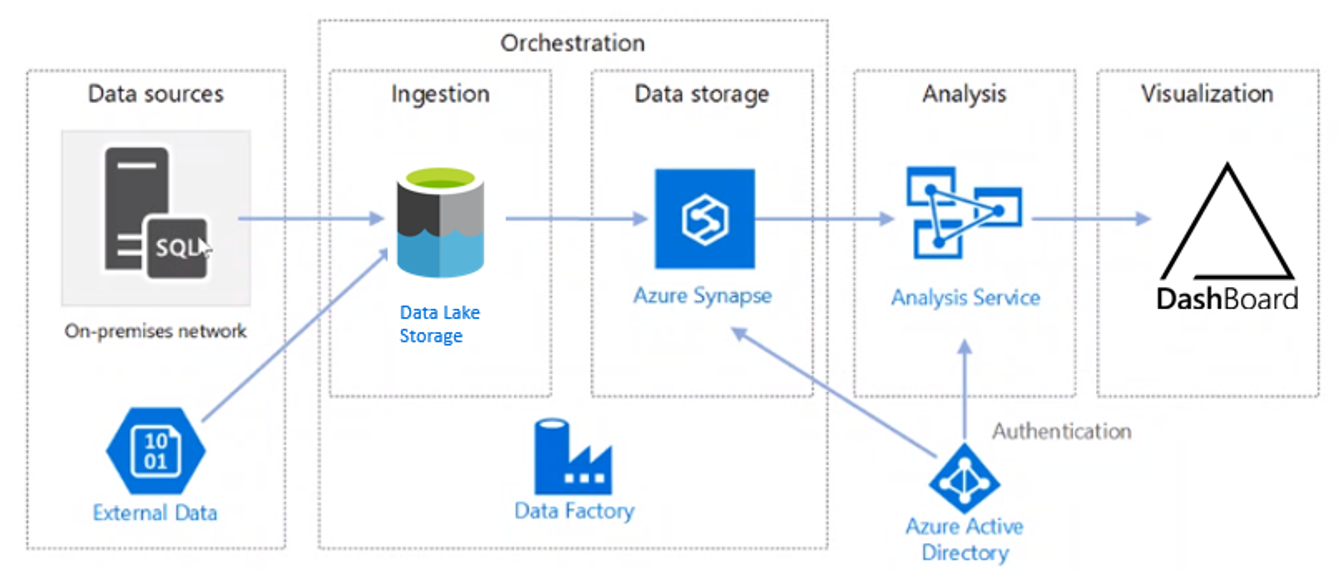
Abb. 2: BI-Architektur mit Microsoft Azure
Auch die Datenaufbereitung kann man innerhalb der Synapse Serverless Pools durchführen, beispielsweise per View, Prozedur oder Funktion. Dabei gibt zwar ein paar funktionale Einschränkungen im Vergleich zu einer herkömmlichen SQL-Datenbank, aber wenn mittelgroße Datenmengen und Aufbereitungsaufgaben ohne außergewöhnliche Komplexität erledigt werden müssen, reicht die kostengünstige Variante der Serverless Pools meist aus.
Zugriffsmöglichkeiten auf den Data Lake Storage
Wie schon erwähnt, gibt es innerhalb des Analyse-Frameworks von Azure Synapse gleich mehrere Komponenten, um eine Analyseumgebung aufzubauen. Auf der Datenebene existieren die Dedicated Pools (früher Azure SQL Data Warehouse), die in sehr großen und ressourcenintensiven Szenarios zum Einsatz kommen und verhältnismäßig teuer sind. Daneben sind die Serverless Pools eher günstig. Sie funktionieren wie eine virtuelle SQL-Datenbank und können in kleinen bis mittleren Szenarios zum Einsatz kommen. Technisch fühlen sich die Serverless Pools fast wie eine normale SQL-Datenbank an, mit dem Unterschied, dass es keine datenhaltenden Tabellen gibt. Der Zugriff erfolgt ausschließlich über externe Daten, zum Beispiel aus dem Data Lake. Verwaltung und Administration der Pools ähneln der Handhabung in den SQL-Server-Datenbanken. So kann man beispielsweise neben dem Front-end im Web auch wie gewohnt per Management Studio zugreifen und seine Objekte verwalten oder abfragen.
Abb. 3: Azure Synapse Serverless Pool im Management Studio
Innerhalb der Azure Synapse Serverless Pools gibt es verschiedene Möglichkeiten, auf den Data Lake Storage zuzugreifen. Dazu schauen wir uns im Folgenden zwei gängige Varianten an und bewerten ihre Vor- und Nachteile: externe Tabellen und Views.
Zugriff mit einer externen Tabelle
Externe Tabellen waren bereits Thema des Beitrags „Datenbankübergreifende Abfragen in Azure-SQL-Datenbanken“ und eine praktische Lösung für die damalige Herausforderung. Auf das gleiche Konzept greifen wir auch beim Zugriff auf den Data Lake Storage zurück, weil es diese externen Tabellen eben nicht nur in „normalen“ SQL-Datenbanken gibt, sondern auch in Synapse Serverless Pools.
Das initiale Anlegen der externen Tabellen kann im Serverless Pool auf verschiedene Wege passieren. Der einfachste ist die Anlage per Kontextmenü aus dem Azure Synapse Studio heraus (vgl. Abbildung 4).
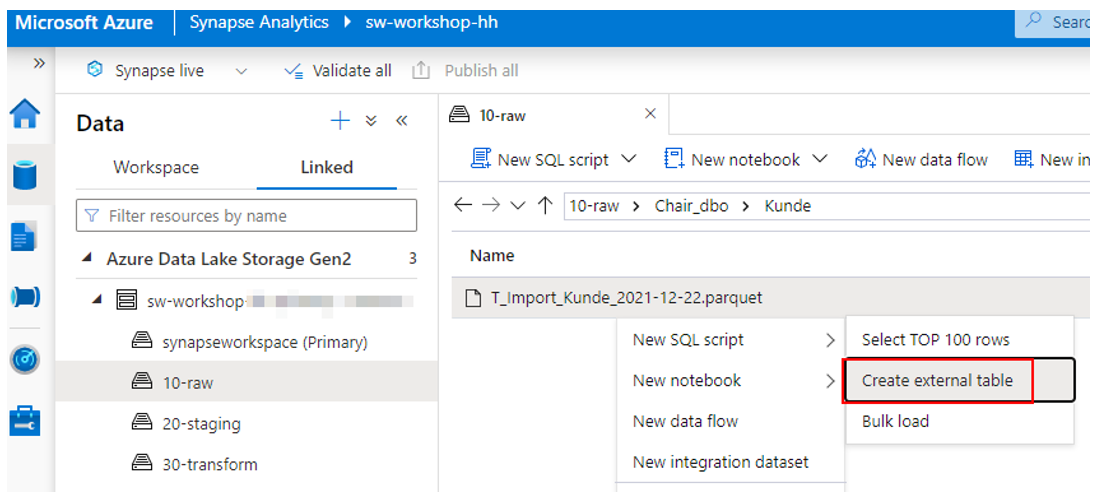
Abb. 4: Anlage einer externen Tabelle per Kontextmenü
In den darauffolgenden Dialogen müssen die maximale Zeichenkettenlänge (wenn in der Quelle Parquet-Dateien verwendet werden), der Ziel-Pool, die Ziel-Datenbank und der Name der anzulegenden Tabelle samt Schema definiert werden. Anschließend kann man die Tabelle entweder direkt anlegen oder mit folgendem Skript generieren:
IF NOT EXISTS (SELECT * FROM sys.external_file_formats WHERE name = 'SynapseParquetFormat')
CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat]
WITH ( FORMAT_TYPE = PARQUET)
GO
IF NOT EXISTS (SELECT * FROM sys.external_data_sources WHERE name = '10-raw_straccntworkshop_dfs_core_windows_net')
CREATE EXTERNAL DATA SOURCE [10-raw_straccntworkshop_dfs_core_windows_net]
WITH (
LOCATION = 'abfss://10-raw@straccntworkshop.dfs.core.windows.net'
)
GO
CREATE EXTERNAL TABLE TE_Import_Kunde (
[CustomerID] nvarchar(4000),
[TopID] int,
[DE_Top] nvarchar(4000),
[LandID] int,
[DE_L1] nvarchar(4000),
[RegionID] int,
[DE_L2] nvarchar(4000),
[GebietID] int,
[DE_L3] nvarchar(4000),
[DE_L4] nvarchar(4000),
[PLZID] int,
[DE_PLZ] nvarchar(4000),
[DE_PLZ_BEZ] nvarchar(4000),
[DE_PLZ5] nvarchar(4000),
[DE_Straße] nvarchar(4000),
[DE_Nr] nvarchar(4000),
[GGeoAddressMD5] varbinary(8000),
[GGeoStatusCode] int,
[GGeoAddressAccuracy] int,
[GGeoAddressLatitude] float,
[GGeoAddressLongitude] float,
--…
[WriteBack1] nvarchar(4000),
[WriteBack2] nvarchar(4000),
[ABCclass] nvarchar(4000),
[PortfolioSegment] nvarchar(4000),
[AnotherElementProperty] nvarchar(4000),
[ABCUmsatz] nvarchar(4000),
[BrancheID] int,
[BrancheBEZ] nvarchar(4000),
[VertriebskanalID] int,
[VertriebskanalBEZ] nvarchar(4000),
[Pfad_Kundenbilder] nvarchar(4000)
)
WITH (
LOCATION = 'Chair_dbo/Kunde/T_Import_Kunde_2021-12-22.parquet',
DATA_SOURCE = [10-raw_straccntworkshop_dfs_core_windows_net],
FILE_FORMAT = [SynapseParquetFormat]
)
GO
SELECT TOP 100 * FROM dbo.TE_Import_Kunde
GOZunächst legt Synapse ein externes Dateiformat für den Dateityp Parquet an, anschließend eine externe Datenquelle mit einem Verweis zum Data-Lake-Container (hier „10-raw“) in dem angelegten Speicherkonto (hier „straccntworkshop“). Beide Objekte werden dann im WITH-Block der externen Tabelle verwendet. Zusätzlich wird im WITH-Block die genaue Location der anzubindenden Datei in Form des kompletten Pfades sowie des Dateinamens angegeben. Statt des exakten Dateinamens könnte hier auch mit der Wildcard „*“ gearbeitet werden, um zum Beispiel alle Umsatzdateien aus dem Jahr 2021 in einer externen Tabelle anzubinden.
Nach Ausführung des Skripts findet man alle drei Objekte auch im Management Studio wieder (vgl. Abbildung 5).
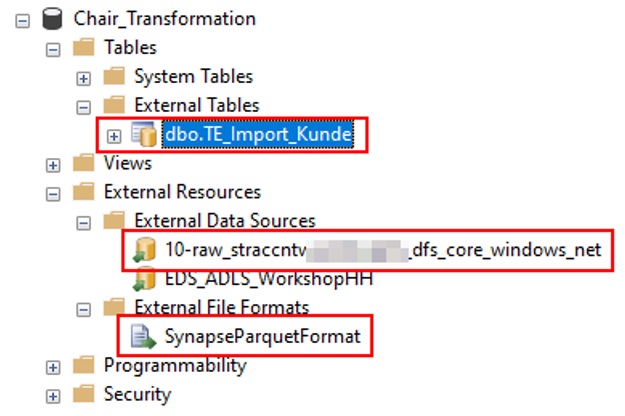
Abb. 5: Synapse Externe-Tabellen-Objekte in Management Studio
Hinweis: Auffällig im Skript sind die vielen nvarchar(4000)-Deklarationen der einzelnen Spalten. Das ist deshalb so, weil das Parquet-Dateiformat lediglich speichert, dass es sich bei einer Spalte um ein Textformat handelt, nicht aber, wie lang der Text ist. Daher musste man auch zu Beginn des Wizzards die Länge der Zeichenketten angeben. 4000 ist der Standard. Für eine optimale Performance wäre es besser, die Spalten exakt zu definieren.
Die externe Tabelle verhält sich, sobald sie erstellt ist, wie eine normale Tabelle und kann mit den üblichen Methoden abgefragt werden. Das macht die externe Tabelle sehr elegant: In der Verwendung merkt man kaum, dass man eigentlich auf dem Data Lake unterwegs ist. Sogar die Namensräume funktionieren hier hervorragend. Um den Unterschied überhaupt sichtbar zu machen, wurde lediglich dem T noch ein E nachgestellt. Das könnte man in einem Serverless Pool natürlich weglassen, weil es ohnehin keine „normalen“ Tabellen gibt. Einziges Manko der externen Tabellen ist, dass eine Veränderung der Tabelleninhalte per Insert, Update oder Delete nicht möglich ist.
Zugriff per View
Der Zugriff per View funktioniert ähnlich und bedient sich eines Konstrukts, das schon sehr lange in der On-Premises-Welt des SQL-Servers existiert: OPENROWSET. Hier gibt man ebenfalls den Pfad zu der Datei im Data Lake an. Es wird empfohlen, im OPENROWSET eine zuvor angelegte externe Datenquelle zum Data Lake anzugeben. Damit ist man später deutlich flexibler, wenn sich etwas an der Struktur der Data Lake Container ändert. Dann muss nicht jede View angepasst werden, sondern lediglich die Definition der externen Datenquelle.
Folgendes Skript erledigt den Job:
CREATE EXTERNAL DATA SOURCE [EDS_ADLS_Workshop] WITH (LOCATION = N'https://straccntworkshop.blob.core.windows.net')
GO
CREATE OR ALTER VIEW [staging_chair_dbo].[V_Kunde] AS
SELECT
kdn.*
FROM
openrowset(
BULK '10-raw/Chair_dbo/Kunde/*.parquet',
DATA_SOURCE = 'EDS_ADLS_Workshop',
FORMAT='PARQUET'
) kdn
GOIn diesem Beispiel wurde die externe Datenquelle über ein anderes Protokoll angelegt und nur auf Ebene des Speicherkontos; der Container wurde also bewusst weggelassen und wird nur im OPENROWSET-Befehl angegeben. Dadurch kann die gleiche externe Datenquelle für verschiedene Container im Azure Data Lake verwendet werden.
Die Objekte sind nach Skriptausführung ebenfalls im Management Studio sichtbar und können wie eine normale View verwendet werden:
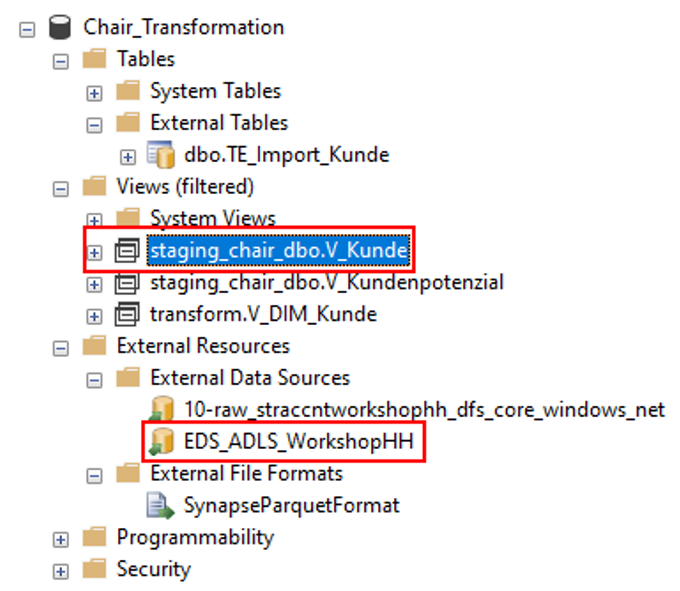
Abb. 6: Synapse View-Objekte im Management Studio
Obwohl das Skript für die View verlockend kurz ist, so ist dies nicht unbedingt die beste Variante der View-Erzeugung. Wir empfehlen auch hier der View die exakten Datentypen der Quellspalten mitzugeben. Andernfalls kann der interne Optimizer nicht den optimalen Ausführungsplan ermitteln, weil er von falschen Datentypen ausgeht.
Die bessere Variante zur Erzeugung der View lautet:
CREATE OR ALTER VIEW [staging_chair_dbo].[V_Kunde] AS
SELECT
kdn.*
FROM
openrowset(
BULK '10-raw/Chair_dbo/Kunde/*.parquet',
DATA_SOURCE = 'EDS_ADLS_Workshop',
FORMAT='PARQUET'
)
WITH(
[CustomerID] [nvarchar](5),
[TopID] [int],
[DE_Top] [varchar](50),
[LandID] [int],
[DE_L1] [varchar](50),
[RegionID] [int],
[DE_L2] [varchar](50),
[GebietID] [int],
[DE_L3] [varchar](50),
[DE_L4] [varchar](50),
[PLZID] [int],
[DE_PLZ] [varchar](50),
[DE_PLZ_BEZ] [varchar](50),
[DE_PLZ5] [varchar](50),
[DE_Straße] [varchar](50),
[DE_Nr] [varchar](50),
[GGeoAddressMD5] [varbinary](50),
[GGeoStatusCode] [int],
[GGeoAddressAccuracy] [int],
[GGeoAddressLatitude] [float],
[GGeoAddressLongitude] [float],
--...
[WriteBack1] [varchar](50),
[WriteBack2] [varchar](50),
[ABCclass] [varchar](50),
[PortfolioSegment] [varchar](50),
[AnotherElementProperty] [varchar](50),
[ABCUmsatz] [varchar](10),
[BrancheID] [int],
[BrancheBEZ] [varchar](50),
[VertriebskanalID] [int],
[VertriebskanalBEZ] [varchar](50),
[Pfad_Kundenbilder] [varchar](255)
) AS kdn
GOHier sind alle Spaltendatentypen sauber definiert und der Optimizer findet alles, was er zum Optimieren braucht.
Fazit
Bei der Entscheidung für eine der beiden Varianten fallen zwei Argumente ins Gewicht, die für den Zugriff per View sprechen:
1. Views sind bei der späteren Bearbeitung flexibler. Sie bieten im Unterschied zur externen Tabelle die ALTER-Option – tatsächlich lassen sich externe Tabellen nämlich nicht mehr verändern. Bei Änderungen müsste die externe Tabelle gelöscht und neu erstellt werden. Das ist mit dem Kontextmenü zwar schnell möglich; hat man aber beispielsweise die Datentypen der Quellspalten (wie empfohlen) exakt definiert, müsste man dies ebenfalls erneut machen. Views können dagegen ganz normal per ALTER verändert werden. Alle Datentypdefinitionen bleiben damit erhalten und Änderungen sind jederzeit möglich.
2. Innerhalb von Views können Metadaten zu den Dateien abgefragt werden. Metadaten sind in produktiven Umgebungen teilweise sehr wertvoll für das Filtern oder Transformieren der Daten. Hier ein Beispiel der konkreten Anwendung (aus Gründen der Übersichtlichkeit ohne Datentypdefinition):
CREATE OR ALTER VIEW [staging_chair_dbo].[V_Kunde] AS
SELECT
kdn.*
,kdn.filepath() FilePath
,kdn.filepath(1) FileWildcard1
,kdn.filepath(2) FileWildcard2
,kdn.filename() FileName
FROM
openrowset(
BULK '10-raw/Chair_dbo/Kunde/*_Import_*.parquet',
DATA_SOURCE = 'EDS_ADLS_Workshop',
FORMAT='PARQUET'
) AS kdnDas Ergebnis findet man in Abbildung 7.
Die Wildcard-Spalten zeigen die gefundenen Ausprägungen, welche durch die Wildcard erfüllt werden. Die Option, Metadaten mittels Funktion abzufragen, bieten externe Tabellen nicht.

Abb. 7: View V_Kunde mit Metadaten
Damit geht die gute alte View als klarer Sieger aus dem Vergleich hervor und wird für die gezeigte BI-Architektur im aktuellen Azure-Implementierungsstand empfohlen. Natürlich nur unter Vorbehalt: Da die Azure-Welt sehr dynamisch ist, kann es durchaus sein, dass sich die Empfehlung in Zukunft ändert.
