Organigramme, Kontenschemata oder Kennzahlsysteme ad hoc selbst modellieren? In DeltaMaster lassen sich geeignete Parent-Child-Hierarchien im Selfservice schnell anlegen und nutzen. Wir zeigen heute anhand von Beispielanwendungen, wie das genau funktioniert.
Parent-Child-Hierarchien im Selfservice: Grundsätzliches
Keine Angst, dieser Beitrag beschäftigt sich zwar mit dem Thema Datenbankmodellierung, wird aber trotzdem nicht allzu technisch werden!
Mit unserer Business-Intelligence-Software DeltaMaster können wir für relationale Datenquellen Parent-Child-Hierarchien schnell und einfach im Selfservice modellieren. Dabei gibt es optional einige Stellschrauben, deren Bedeutung und Einfluss wir in diesem Beitrag genauer untersuchen werden.
Die Vor- und Nachteile der Modellierung mittels Parent-Child-Hierarchien sollen hier aber nicht Thema sein. Für uns genügt es zu wissen, dass es oft vorteilhaft sein kann, Parent-Child-Hierarchien einzusetzen, wenn bei Elementbeziehungen der Zusammenhang mit dem direkt übergeordneten Element betont wird.
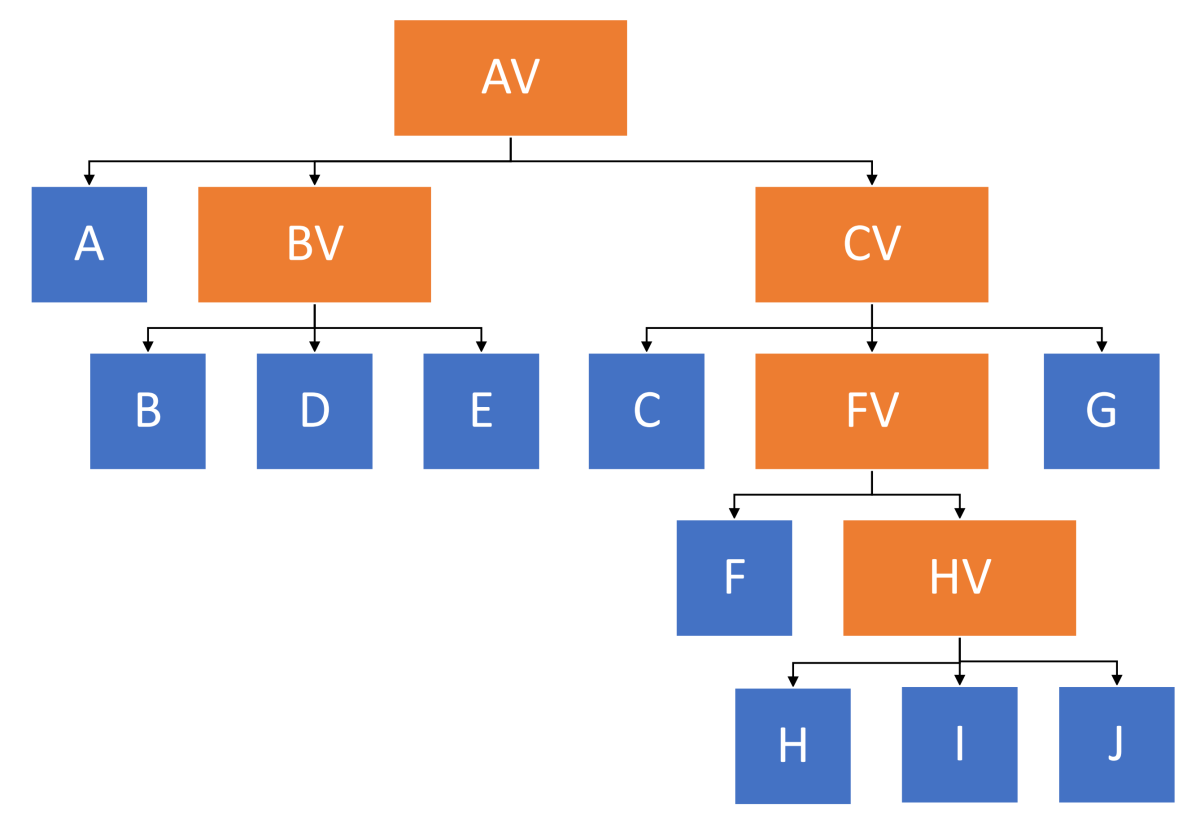
Wir wollen mit einer Parent-Child-Hierarchie dieses Organigramm abbilden
Solche Zusammenhänge trifft man beispielsweise bei Kontendimensionen oder Deckungsbeitragsrechnungen an. Zum Beispiel können Konten thematisch gruppiert werden und ein einzelnes Konto gehört dann einer Gruppe an. Bei der Deckungsbeitragsrechnung setzen sich etwa die Kosten aus einzelnen Kostenarten zusammen, die ihrerseits noch unterteilt sein könnten.
Auch Organigramme werden häufig durch eine natürliche Baumstruktur beschrieben, bei der die Einordnung einer Abteilung oder einer Person durch die Angabe der übergeordneten Abteilung erfolgt.
Parent-Child-Hierarchien weisen nicht notwendigerweise, aber doch sehr häufig die Eigenschaft auf, dass die hierarchische Baumstruktur der Elemente unausgewogen oder „schief“ ist. Verschiedene Äste können dann durchaus unterschiedliche Tiefen besitzen.
Der Baum wird somit aus lokalen Angaben konstruiert: Für jedes Element („Child“) muss der zugehörige direkte Elternknoten („Parent“) angegeben werden, unter dem das Kind eingeklinkt wird.
Während man nun normalerweise in einer bestimmten Tiefe einer Hierarchie Elemente eines festen Typs – zum Beispiel Produkte – antrifft und es dann auch sinnvoll ist, von der (Produkt-)Ebene zu sprechen, kann der Fall bei Parent-Child-Hierarchien anders liegen. Aber schauen wir dazu am besten auf das oben abgebildete Beispiel.
Fallbeispiel Organigramm
Daten zum Organigramm
Hier haben wir ein Organigramm, das aus Verwaltungseinheiten oder Verantwortungsbereichen (hier in Orange mit dem Zusatz „V“ dargestellt) besteht, und aus realen Personen (in Blau), die in die Hierarchie eingebunden sind. Jede Person ist somit einer Verwaltungseinheit zugeordnet.
In unserem Organigramm befindet sich etwa das Kind A direkt unter dem Elternelement AV. Andere Paarungen Child/Parent sind beispielsweise durch „D unter BV“ und „FV unter CV“ gegeben.
Wir nehmen an, dass jede natürliche Person zu einem Gesamtergebnis beiträgt. Stellen Sie sich dabei als Kennzahl Kundenkontakte, Supportfälle oder verkaufte Einheiten eines Produktes vor. Für jeden Verantwortungsbereich gebe es eine zuständige Person (z. B. sei A für den Bereich AV zuständig), die aber nicht nur führt und delegiert, sondern auch selbst bezüglich der Kennzahl aktiv ist und direkt zum Gesamtergebnis beiträgt.
Deshalb wird hier etwa Person A unterhalb der Einheit AV eingeklinkt, da A auch direkt zum Ergebnis der Abteilung AV einen Beitrag beisteuert.
Weiterhin sieht man sofort, dass z. B. Ebene 2 (als auch 3 und 4) sowohl aus realen Personen, als auch aus Verantwortungsbereichen besteht. Somit besitzen die Elemente dieser Ebene unterschiedliche Typen.
Das Ergebnis von BV und HV wird ausschließlich von natürlichen Personen generiert, bei AV, CV und FV steuern direkt auch untergeordnete Abteilungen zum Ergebnis bei. Indirekt handelt es sich immer um natürliche Personen, die das Ergebnis generieren.
Die natürlichen Personen befinden sich immer am Ende der unterschiedlich langen Äste und stellen somit die Blätter des Baumes dar.
Microsoft Excel/SQL Selfservice
Die Daten zur Struktur und die Fakten zur Kennzahl liegen hier nun als Tabellenblätter in Excel vor. In diesem Fall modellieren wir somit per Microsoft Excel/SQL Selfservice. Hierbei wird intern SQLite als Datenbank-Cache verwendet.
Als alternative relationale Datenquellen stünden auch Microsoft SQL Server, Oracle oder etwa SAP HANA (ab Version 2) zur Auswahl.
Für die Parent-Child-Hierarchie im Selfservice benötigen wir zwingend exakt zwei Spalten – die der Kinder und die ihrer Eltern. Übrigens ist der Ausdruck Eltern in der deutschen Sprache leicht irreführend, da es immer nur einen Elternknoten gibt. Das passende Gegenstück zu „Parent“ wäre „Elternteil“, aber das hört sich dann doch sehr sperrig an.
In der Excel-Datei sieht das dann folgendermaßen aus:
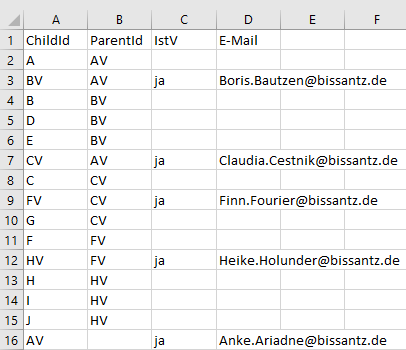
Die Bausteine des Organigramms in Excel
Weiterhin haben wir eine Spalte „IstV“ angelegt, die auf „ja“ steht, falls es sich bei einem Element um einen Verantwortungsbereich handelt. Außerdem existiert eine E-Mail-Adresse der verantwortlichen Person der Abteilung. Alle Namen sind frei erfunden und Übereinstimmungen mit real existierenden Personen wären rein zufällig. Die E-Mail-Adressen laufen somit ins Leere!
Beide Spalten werden als Elementeigenschaften der ChildId modelliert. Sie sind hier für die Anwendung nicht zwingend notwendig. Wir benötigen sie aber weiter unten für einen Exkurs zum Publisher!
Schauen wir auf die Spalten ChildId und ParentId, so stellen wir fest, dass hier jeder Knoten aus dem Organigramm in der ChildId-Spalte erscheint und die Spalte ParentId den direkten Vorgänger im Organigramm enthält. Wir sehen beispielsweise die bereits erwähnten Paarungen A/AV, D/BV und FV/CV.
Wichtig ist, auch den obersten Knoten AV, der ja keinen Vorgänger hat, hier zu erwähnen. Für diesen Knoten bleibt die ParentId-Spalte leer.
Parent-Child-Hierarchien im Selfservice modellieren
Im Modellieren-Modus deklarieren wir die ChildId-Spalte als Dimension:
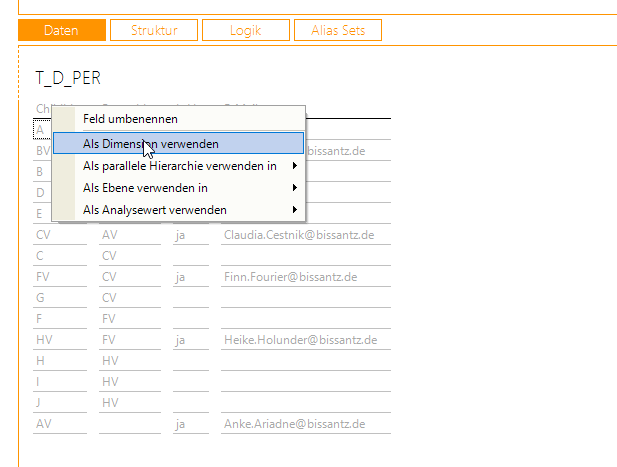
Die ChildId-Spalte wird als Dimension deklariert
Darauf aufbauend lässt sich jetzt die ParentId–Spalte als Eltern-Ebene definieren.
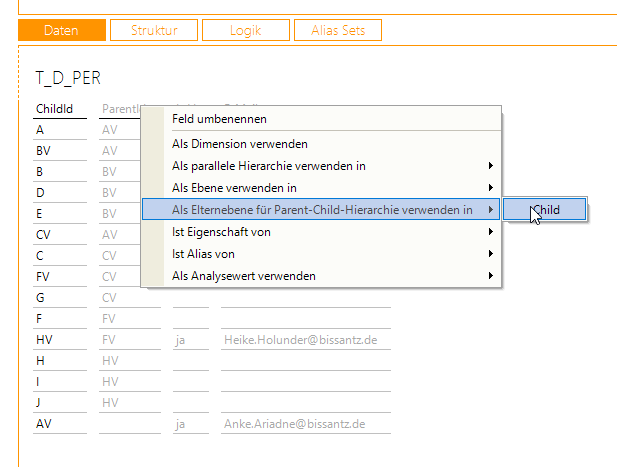
Anschließend können wir die ParentId–Spalte als Eltern-Ebene verwenden
Die verbleibende Spalten IstV und E-Mail modellieren wir als Elementeigenschaften von Child.
Darüber hinaus binden wir eine Fakttabelle mit den Anzahlen der vergangenen drei Monate an, die von den natürlichen Personen generiert wurden. Hier sehen wir einen Ausschnitt im SQL-Durchgriff für den Februar 2021:
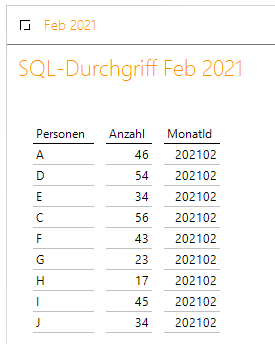
Nur natürliche Personen haben die Anzahlen generiert
Anwendung des Modells in DeltaMaster
Im Dimensionsbrowser (Modus Modellieren) entdecken wir nun unsere Parent-Child-Hierarchie wieder:
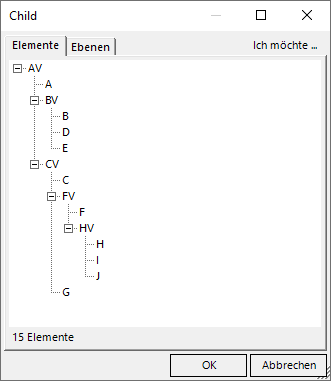
Die Parent-Child-Hierarchie wurde im Selfservice erfolgreich erstellt
Standardmäßig sortiert DeltaMaster die Kinder eines Knotens nach dem Elementschlüssel, also hier alphabetisch nach Kürzeln. Hier bedeutet das beispielsweise, dass die Kinder von AV auf der zweiten Ebene in der Reihenfolge A -> BV -> CV erscheinen. Unterhalb von CV befindet sich dann C vor FV vor G.
Wir können die Reihenfolge beeinflussen, indem wir für die Sortierung alternativ eine andere Spalte verwenden, die als Elementeigenschaft der Child-Spalte deklariert wird. Dazu später mehr, bei unserem zweiten Beispiel.
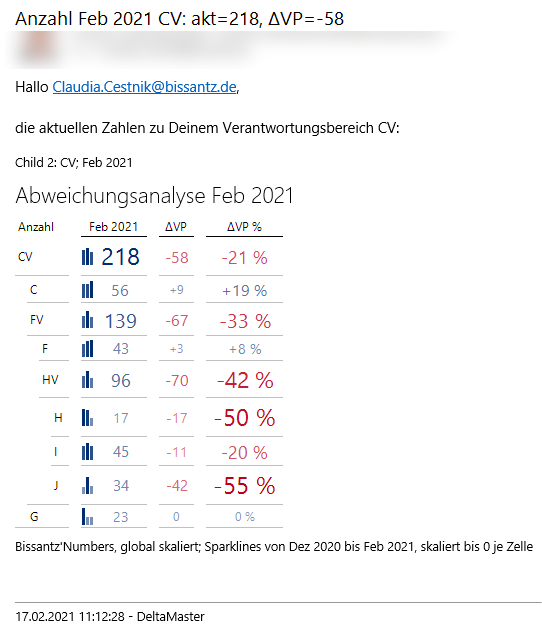
Legen wir nun eine Grafische Tabelle an, dann können wir zum Beispiel für das im Filter ausgewählte Element „CV“ einen Bericht mit einer Abweichungsanalyse zum Vormonat erstellen:
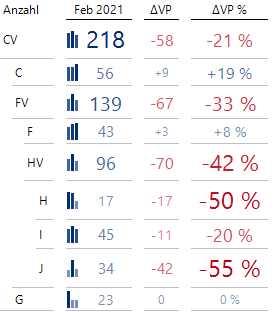
Die Abweichungsanalyse von Abteilung CV zum Vormonat
Zu jeder Abteilung gehörte ja eine E-Mail-Adresse, die mit dem Verantwortungsbereich verbunden ist. Hier bietet sich der Publisher zum automatisierten Versand an.
Exkurs: Anwendung im Publisher
Wir möchten regelmäßig am Monatsende insgesamt 5 E-Mails mit dem oben dargestellten Bericht versenden. Der Empfänger soll jeweils nur den eigenen Bereich sehen. Wir legen einen neuen Job an und wählen unsere Sitzung aus. Als Berichtsformat nehmen wir „html“ und als Verteilungsart „mail“. Die Adresse erhält den Platzhalter „@IDA“, der später durch die jeweiligen E-Mail-Adressen ersetzt werden wird.
Im Fenster „Berichtsupdate“ wählen wir den gewünschten Monat „Februar 2021“ aus und im Fenster „Berichte und Ordner“ die Grafische Tabelle.
Um die E-Mail etwas ansprechender zu gestalten, verwenden wir den E-Mail-Editor und ändern den E-Mail-Betreff und fügen etwas E-Mail-Text hinzu:
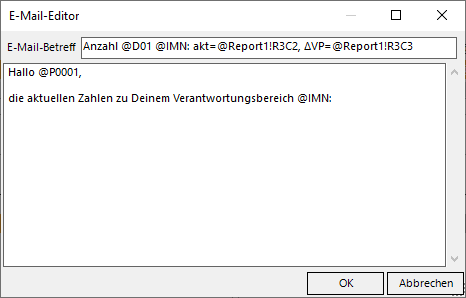
Aktion „Unsere E-Mail soll schöner werden“
Um unsere Liste der Empfänger abzuarbeiten, setzen wir den Berichtsgenerator ein:

Mit dem Berichtsgenerator wird die Liste der Adressaten erzeugt
Hier erzeugen wir mit „Select ChildId from [T_D_PER] where IstV=’ja'“ eine Liste der Bereiche, für die wir eine E-Mail verschicken wollen. Über die Elementeigenschaft „E-Mail“ wird eine E-Mail-Adresse verknüpft. Intern werden pro Ebene getrennte Elementeigenschaften erzeugt, die sich hier aber für den Anwender wie eine einzige verhalten.
Führen wir nun einmal den Job aus und schauen auf die E-Mail, wie sie bei der Verantwortlichen für Bereich CV ankommt:
Die E-Mail mit den neuesten Zahlen ist da!
Die Platzhalter, die im E-Mail-Editor sichtbar waren, wurden nun mit den konkreten Werten ersetzt:
- das Berichtsupdate-Element @D01 enthält den gewünschten Monat Februar 2021
- das Berichtgenerator-Element @IMN enthält die gerade bearbeitete ChildID „CV“
- mit @Report1!R3C2 und @Report1!R3C3 werden Werte direkt aus der Grafischen Tabelle eingesetzt (R(ow)3 steht für die dritte Zeile: Dies ist richtig, da die erste Zeile mit Hierarchienamen der Spalten im Bericht ausgeblendet wurde!)
- Für @P0001 wird der Inhalt aus der Elementeigenschaft „E-Mail“ eingesetzt, also hier die E-Mail-Adresse.
Der Publisher bietet hier noch weitere Möglichkeiten. Zum Beispiel lässt sich die HTML-Exportvorlage bearbeiten und an die eigenen Wünsche anpassen.
Parent-Child-Hierarchien im Selfservice: Fallbeispiel Deckungsbeitragsrechnung
Kennzahlen als Dimension modellieren
Wenn wir üblicherweise Berichte aus unserer Demo-Anwendung Chair zeigen, sind die KPI einer Deckungsbeitragsrechnung als unabhängige Kennzahlen definiert und ein Bericht über die Vorperiodenabweichung hat die folgende Gestalt:

Eine typische Deckungsbeitragsrechnung mit 6 Kennzahlen
Im vorliegenden Fall sind sämtliche Werte als eigenständige Kennzahlen definiert. Es gibt aber auch die Möglichkeit, eine Modellierung zu wählen, bei der die Kennzahlen in eine Kennzahldimension wandern und Elemente einer Hierarchie bilden. Zum Beispiel böte sich der folgende hierarchische Aufbau an:
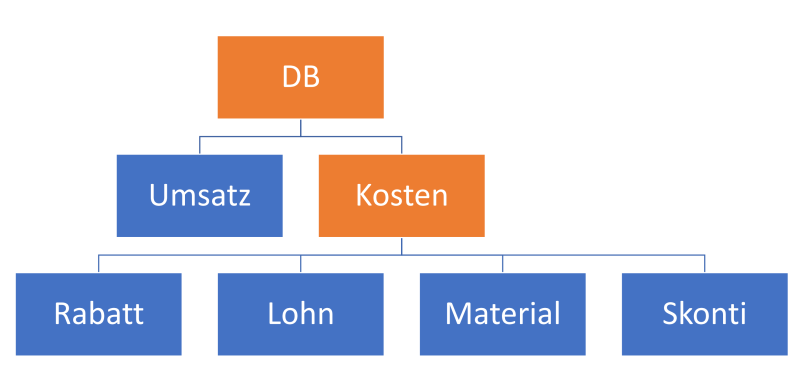
Deckungsbeitragsrechnung in einer Kennzahl-Hierarchie
In diesem Beispiel existiert noch eine zusätzliche, aggregierte Zwischenstufe „Kosten“, die alle vier Kostenarten Rabatt, Lohn, Material und Skonti zusammenfassen soll. DB ist eine Saldogröße aus Umsatz und Kosten.
Sind die Werte der Blätter dieses Baumes (in Blau) bekannt, lassen sich somit die anderen Größen (in Orange) berechnen.
In DeltaMaster lässt sich nun einstellen, ob diese Aggregation von DeltaMaster übernommen werden soll, oder ob die aggregierten Werte bereits vorliegen und ausgelesen werden können. Dazu gibt es weitere Einstellungsmöglichkeiten, um die Darstellung an die eigenen Wünsche anzupassen.
Aufbau der Parent-Child-Hierarchie im Selfservice
In unserer Excel-Datei benutzen wir die ersten beiden Spalten, um wieder die Parent-Child-Hierarchie aufzubauen:
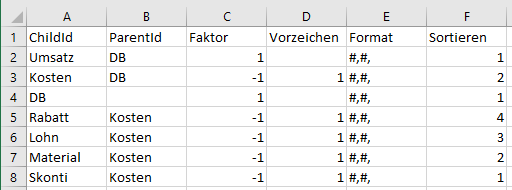
Deckungsbeitragsrechnung als Parent-Child-Hierarchie
Die restlichen Spalten werden als Elementeigenschaften von Child definiert. Ihre Bedeutung werden wir in Kürze kennenlernen.
Sortierung und Darstellung des Baumes
Schauen wir unsere Parent-Child-Dimension einmal an, sehen wir eine Darstellung (links), die wir gerne noch umstellen möchten:
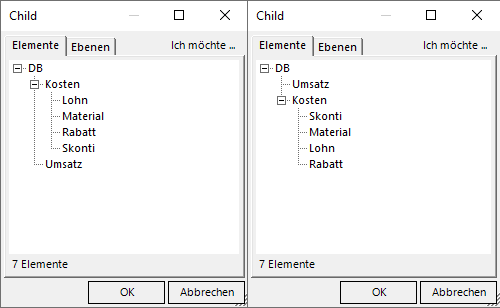
Wie können die Baumdarstellung nach Wunsch sortieren!
Standardmäßig sind die Kinder eines Knotens nach dem Elementschlüssel sortiert, also hier alphabetisch. Kosten kommt also vor Umsatz und Lohn vor Material.
Wir können die Sortierung aber in den Ebeneneigenschaften der obersten Ebene (hier Child1) beeinflussen:
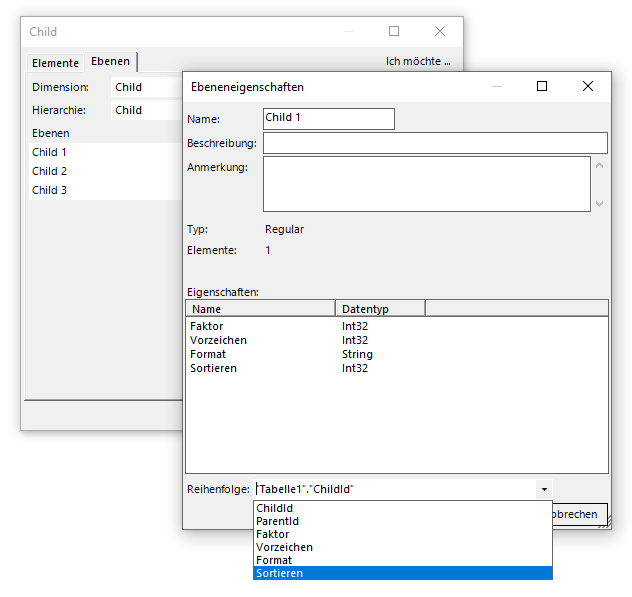
Die Elementeigenschaft Sortieren enthält die gewünschte Sortierung
Wählen wir hier die Elementeigenschaft „Sortieren“ aus, werden die Zahlen dieser Spalte aus dem Excel-Blatt zur aufsteigenden Sortierung herangezogen. Es ergibt sich die oben schon gezeigte Sortierung (in der Abbildung rechts).
Da Umsatz eine 1 und Kosten eine 2 besitzt, erscheint Umsatz nun vor Kosten. Es werden immer nur die unmittelbaren Kinder eines Knotens miteinander verglichen. Das heißt, es spielt für Skonti keine Rolle, welche Zahlen für Umsatz oder Kosten vergeben wurden. Nur die Zahlen der anderen drei Kostenarten sind relevant.
Auch Stringvariablen wären in der Sortierspalte erlaubt, aber am einfachsten und einprägsamsten lassen sich positive Zahlen für die Sortierreihenfolge nutzen.
Aggregieren lassen – ja oder nein?
Wir können bei Parent-Child-Hierarchien im Selfservice in Abhängigkeit von der Form der Daten entscheiden, ob wir für jeden Knoten des Baumes Werte liefern oder nur für die Blätter.
Im letzteren Fall kann DeltaMaster für uns aggregieren. Dies ist die Standardeinstellung, die wir auch beim Beispiel mit dem Organigramm genutzt haben.
Die zugehörige Checkbox ist in den Hierarchieeigenschaften der Parent-Child-Dimension zu finden:
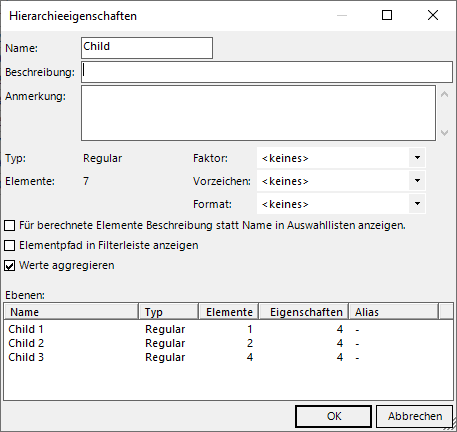
Werte aggregieren
Hier sehen wir auch schon die Auswahlmöglichkeiten „Faktor“, „Vorzeichen“ und „Format“, die bis jetzt noch nicht eingesetzt wurden.
Damit die automatische Aggregation funktionieren kann, müssen die Kosten in der Datenbank negativ verbucht sein, da sich der Deckungsbeitrag als Summe der Knoten Umsatz und Kosten ergibt. Schauen wir einmal auf den vollständigen Baum in einer Grafischen Tabelle:
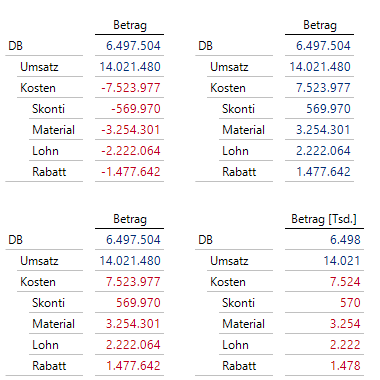
Auswirkungen von Vorzeichen, Faktor und Format
Links oben sehen wir nun den aktuellen Zustand. Kosten und DB wurden korrekt aggregiert, die warnende Farbe Rot stimmt, aber uns stören die negativen Vorzeichen.
Einfluss von Vorzeichen und Faktor
Im Excel-File haben wir mit einer 1 in der Spalte „Vorzeichen“ angegeben, welche Knoten einen Vorzeichenwechsel erfahren sollen. Eine 1 sehen wir bei allen vier Kostenarten, aber auch beim aggregierten Element „Kosten“. Auf Microsoft SQL Server kann der Typ hier ganzzahlig sein, z. B. Typ int mit Abfrage auf 1 funktioniert. Alternativ dürfen wir auch Boolean (TRUE) oder ein Zeichen „-“ verwenden.
Hier ist es wichtig zu wissen, dass die Aggregation durch diese Einstellungen nicht beeinflusst wird. Den Vorzeichenwechsel sollte man als Nachbearbeitung verstehen: Erst erfolgt die Aggregation und dann werden die Knoten bearbeitet. Dies bedeutet, dass der interne Zahlenwert für „Kosten“ weiterhin negativ bleibt, auch wenn wir für sämtliche Kinder das Vorzeichen gewechselt haben. Deshalb ist eine 1 auch für „Kosten“ notwendig.
Stellen wir somit in den Hierarchieeigenschaften den Auswahlpunkt Vorzeichen auf die hier gleichnamige Eigenschaft um, erhalten wir die Ansicht rechts oben.
Die vergebene Farbe richtet sich am – nach der Vorzeichenberücksichtigung! – sichtbaren Wert aus. Bei den Kosten sind die Zahlenwerte nun positiv, deshalb muss der Faktor für alle Kostenknoten auf -1 (= negativer Faktor) eingestellt werden, damit die positiven Zahlenwerte in Rot erscheinen.
In der Spalte Faktor legen wir somit mit -1 für alle Kostenknoten einen negativen Faktor fest, mit +1 einen positiven Faktor für den Rest. In den Hierarchieeigenschaften wird Faktor auf die gleichnamige Eigenschaft Faktor eingestellt. Die Ansicht links unten ist nun die erwünschte Ansicht.
Einfluss von Format
Wir haben es ja hier nur mit einer einzigen Kennzahl Betrag zu tun, für die wir normalerweise nur eine Art der Formatierung definieren können. Über die Formatspalte kann aber jedem Child-Element ein eigenes Format zugewiesen werden. Das hier bei jedem Element verwendete „#,#,“ bewirkt, dass alle Werte nur in Tausendern angegeben werden. Den Kennzahlnamen haben wir dazu passend geändert (Darstellung rechts unten).
Erlaubte .NET-Formatierungszeichenfolgen sind diejenigen, die auch sonst bei benutzerdefinierten Analysewerten möglich sind. Der bei Microsoft zu findende Überblick der möglichen Formatierungen hilft hier im Zweifel weiter.
Einstellungen bei vorberechneten Werten
Wird nicht aggregiert, müssen die Werte für die Knoten DB und Kosten schon in der Fakttabelle vorgehalten werden. Nehmen wir zunächst an, dass alle 5 Kostenpositionen weiterhin negativ verbucht sind, ändert sich nichts gegenüber den Einstellungen für Faktor und Vorzeichen, die wir eben vorgenommen haben.
Sind die Kostenpositionen hingegen als positive Werte verbucht, müssen wir nur über den Faktor bestätigen, dass Kostenknoten negativ besetzt sind. Der Vorzeichenwechsel entfällt und die zugehörige Spalte kann auf „<keines>“ verbleiben.
Parent-Child-Hierarchien im multidimensionalen Modell
Die hier beschriebenen Lösungen sind gedacht für Ad-hoc-Modellierungen im Selfservice, falls relationale Datenquellen vorliegen. Den Beispielen war gemein, dass sich die hierarchischen Strukturen im Zeitverlauf entweder gar nicht (DB-Rechnung) oder nur selten (Organigramm) ändern.
Manche Anwendung bezieht ihren Mehrwert aber aus der Tatsache, dass sich die Hierarchie ständig verändert. Ein Schwerpunkt liegt dann auf der Definition und Pflege der Strukturen. Zum Beispiel gehört das Projektmanagement zu dieser Kategorie, da hier fortlaufend neue Projekte mit ihren untergeordneten Teilschritten entstehen und auf ihren Fortschritt und Einhaltung der Termine überprüft werden müssen.
In unserem vom eigenen Consulting, aber auch von Kunden gern genutzten Modellierungs- und Automatisierungstool DeltaMaster ETL ist die mögliche Einbindung von Parent-Child-Strukturen auf dem Weg zum performanten Cube nur ein Schritt von vielen.
Mittels des Parent-Child-Editors, der hier als Solution eingebunden werden kann, lassen sich die Strukturen dann erstellen und aktualisieren. Auch über den Berichtstyp Parent-Child-Editor, der in DeltaMaster selbst vorliegt (wenn die dazu passende Planungslizenz vorhanden ist und einige notwendige Vorbereitungen auf der Datenbank durchgeführt worden sind) ist eine solche Pflege möglich. Lassen Sie sich am besten von uns beraten, welche Vorgehensweise in Ihrem Fall geeignet ist.
