In diesem Blogbeitrag geht es um die Hybridplanung, eine von Bissantz & Company entwickelte Planungstechnologie. Mit ihr sind verschiedene Funktionen möglich, die wir in unserem Blogbeitrag vorstellen:
- Rückschreibung von Daten ohne Verwendung des SQL Servers,
- gleichzeitige Erfassung von Planungsdaten verschiedener User,
- Realisierung komplexer Logiken beim Rückschreiben von Planungseingaben und
- gewichtete Aggregation komplexer Kennzahlen.
Aggregationsverhalten bei Durchschnittsberechnung
Die Hybridplanung versteht sich als eine von Bissantz & Company entwickelte Planungstechnologie, bei welcher die Funktionalitäten des SQL Servers zum Rückschreiben von Daten nicht verwendet werden. Stattdessen erfolgt das Rückschreiben durch definierte Prozeduren direkt in die relationale Datenbank.
Im Rahmen eines aktuellen Planungsprojekts wurde durch den Einsatz der Hybridplanung die parallele Eingabe von Planzahlen auf unterschiedliche Datensätze durch mehrere User ermöglicht. Bei Verwendung der sogenannten OLAP-Planung, welche der SQL Server bereitstellt, ist dies nicht möglich, da bei jeder Planeingabe der gesamte Datenwürfel gesperrt wird.
Zudem konnten durch die Möglichkeit des Aufbaus individueller Stored Procedures im Rahmen der Hybridplanung auch komplexe Berechnungen im Rückschreibeprozess realisiert werden. Hierdurch wurden sowohl ein modifiziertes Splashing, als auch die Aggregation komplexer Kennzahlen korrekt umgesetzt. Eine Auswahl dieser Stored Procedures soll im Folgenden näher beleuchtet werden.
Als Beispiel einer komplexen Kennzahl soll der Verkaufspreisindex (VKI) dienen, über welchen die mengenabhängige Preisveränderung zwischen zwei Perioden ermittelt wird. Der VKI beantwortet die Frage, um wieviel Prozent sich der Umsatz geändert hat, wenn man den Umsatz der Vorperiode auf die Menge der aktuellen Periode korrigiert. Planeingaben des VKI sollen auf den Umsatz der aktuellen Periode zurückgeschrieben werden, während die Menge als fix betrachtet wird.
Zur Berechnung des VKI werden die vier relationalen Kennzahlen Umsatz, Umsatz_VP, Menge und Menge_VP benötigt, wobei das Suffix _VP jeweils auf die Vorperiode verweist. Kennzahlen, die auf die Vorperiode verweisen, sind eigentlich prädestiniert, um im CubeSkript berechnet zu werden. Aus der relationalen Anlage der Kennzahlen Umsatz_VP und Menge_VP resultiert ein Performancevorteil bei der Aktualisierung von Kennzahlen, welche Werte der Vorperiode zur Berechnung benötigen.
Nachfolgend die Formel zur Berechnung des VKI:
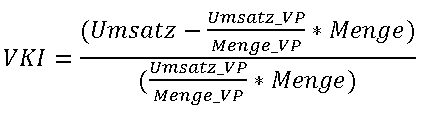
Zur Veranschaulichung dienen als Beispiel zwei Produkte A und B.
Von Produkt A wurden in der Vorperiode eine Menge von 100 Stück zu einem Preis von 5,00 €/Stück verkauft und somit ein Umsatz von 500 € erzielt.
In der aktuellen Periode hat Produkt A mit einer Menge von 95 Stück zu einem Preis von 6,00 €/Stück einen Umsatz von 570 € erzielt.
Der VKI für Produkt A berechnet sich wie folgt:
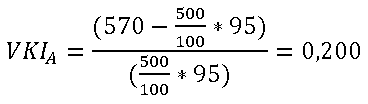
Für Produkt A ergibt sich somit eine mengenabhängige Preisveränderung von 20,0 %.
Für Produkt B gilt in der Vorperiode: Menge von 500 Stück zu einem Preis von 3,00 €/Stück. Daraus resultiert ein Umsatz von 1.500 €.
In der aktuellen Periode wurden von Produkt B eine Menge von 700 Stück zu einem Preis von 1,50 €/Stück verkauft. Der Umsatz beträgt somit 1.050 €.
Der VKI für Produkt B berechnet sich wie folgt:
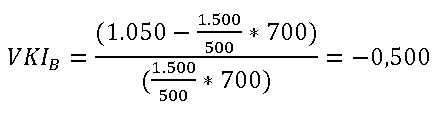
Für Produkt B ergibt sich somit eine mengenabhängige Preisveränderung von -50,0 %.
Wenn der durchschnittliche VKI über die Summe aus Produkt A und Produkt B mit oben gezeigter Formel im Cubescript berechnet werden soll, führt dies auf aggregierter Ebene zu einem ungewichteten durchschnittlichen VKI von -15,0 %. Ursache ist, dass bei diesem Vorgehen der VKI zunächst auf Produktebene berechnet wird und anschließend eine Aggregation der VKI über beide Produkte stattfindet. Auf aggregierter Ebene findet anschließend eine Berechnung des Durchschnitts über VKIA und VKIB statt:
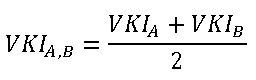
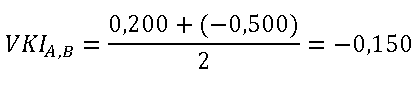
Die Berechnung eines gewichteten durchschnittlichen VKI auf aggregierter Ebene kann durch das Zerlegen des VKI in einen Zähler und einen Nenner erreicht werden. Zähler und Nenner werden als relationale Kennzahlen angelegt und wie folgt berechnet:
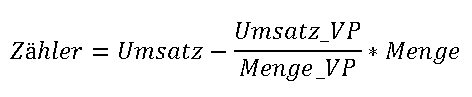
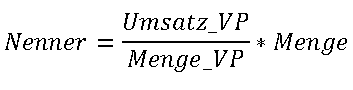
Die Berechnung des VKI im Cubescript unter Verwendung der relational vorberechneten Kennzahlen Zähler und Nenner führt auf aggregierter Ebene zu einem gewichteten durchschnittlichen VKI von -37,1 %:
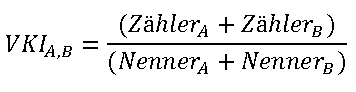
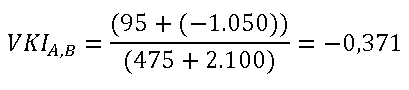
Relationale Vorberechnung von Zähler und Nenner
Die Kennzahlen Zähler und Nenner werden relational nach jeder Planeingabe aktualisiert, um den VKI entsprechend neu zu berechnen. Dies geschieht in der Prozedur P_WriteBackSQL_FACT_01_xxx_PostProcess. Mit Hilfe eines INNER JOIN auf die temporäre Tabelle #T_FACT (Die temporäre Tabelle #T_FACT enthält alle Eingabewerte inkl. der genauen Zellkoordinaten, welche durch die aktuelle Planeingabe bzw. die mit dieser Planeingabe verknüpften Wertweitergaben erzeugt werden.) über alle an die Measure Group angebundenen Dimensionen werden nur diejenigen Datensätze aktualisiert, welche von der aktuellen Planeingabe betroffen sind:
UPDATE p SET [Zähler] = CASE WHEN p.[Menge_VP] <> 0 THEN (p.[Umsatz] - (p.[Umsatz_VP] / p.[Menge_VP] * p.[Menge])) ELSE 0 END , [Nenner] = CASE WHEN p.[Menge_VP] <> 0 THEN (p.[Umsatz_VP] / p.[Menge_VP] * p.[Menge]) ELSE 1 END FROM [T_WriteBackSQL_FACT_01_Plan] AS p INNER JOIN #T_FACT AS d ON p.[MonatID] = d.[MonatID] AND p.[WertartID] = d.[WertartID] AND p.[PeriodenansichtID] = d.[PeriodenansichtID] AND p.[KumulationID] = d.[KumulationID] AND p.[KundeID] = d.[KundeID] AND p.[ProduktID] = d.[ProduktID] AND p.[StoffgruppeID] = d.[StoffgruppeID] AND p.[VertriebID] = d.[VertriebID]
Wertweitergabe und Anpassung Splashing
Angenommen, die Planeingaben bzgl. des VKI sollen per Wertweitergabe auf den Umsatz geschrieben werden. Die Kennzahl Menge soll durch eine Veränderung des VKI nicht betroffen sein. Hierzu werden im DeltaMaster zwei Wertweitergaben auf eine relationale Dummy Kennzahl DummyEingabe_VKI der aktuellen Periode und auf eine relationale Dummy Kennzahl DummyEingabe_VKI_VP der Folgeperiode implementiert, bei welchen jeweils der neue Eingabewert #new (Standardmäßig wird bei einer Wertweitergabe das Verhältnis aus neuem Eingabewert und altem Wert weitergegeben: #new/#old) weitergegeben wird:

Abbildung 1: Wertweitergabe VKI
Da die Eingabe auch auf aggregierter Ebene möglich sein soll, sind manuelle Anpassungen in der Prozedur P_WriteBackSQL_FACT_01_xxx nötig, um das Splashing innerhalb der beiden Dummy-Kennzahlen zu ermöglichen. Zunächst wird der proportional gesplashte Umsatz der aktuellen Periode im Kontext der Kennzahl DummyEingabe_VKI berechnet:
IF @MeasureName = 'DummyEingabe_VKI' BEGIN -- Berechnung des Umsatz der aktuellen Periode MERGE INTO dbo.T_WriteBackSQL_FACT_01_Plan AS tgt USING #T_FACT AS src ON tgt.[MonatID] = src.[MonatID] AND tgt.[WertartID] = src.[WertartID] AND tgt.[PeriodenansichtID] = src.[PeriodenansichtID] AND tgt.[KumulationID] = src.[KumulationID] AND tgt.[KundeID] = src.[KundeID] AND tgt.[ProduktID] = src.[ProduktID] AND tgt.[StoffgruppeID] = src.[StoffgruppeID] AND tgt.[VertriebID] = src.[VertriebID] WHEN MATCHED THEN UPDATE SET [Umsatz] = CASE WHEN tgt.[Umsatz_VP] <> 0 AND tgt.[Menge_VP] <> 0 THEN (tgt.[Umsatz_VP] / tgt.[Menge_VP]) * tgt.[Menge] * (1 + @MeasureValue) ELSE tgt.[Umsatz] END, [Locked] = 1, [TransactionID] = @TransactionID, [Deleted] = CASE WHEN @MeasureValue IS NULL THEN 1 ELSE tgt.[Deleted] END, [ZeroEntered] = CASE WHEN @MeasureValue = 0 THEN 1 ELSE tgt.[ZeroEntered] END, [LastChangeTime] = getdate(), [LastChangeUser] = @Username, [LastChangeTransactionID] = @TransactionID, [ChangeCount] = isnull(tgt.ChangeCount, 0) + 1 OPTION (MAXDOP 4); END
Die Kennzahl Umsatz der aktuellen Periode ist stets identisch zur Kennzahl Umsatz_VP der Folgeperiode. Die Aktualisierung der Kennzahl Umsatz_VP der Folgeperiode erfolgt im Kontext der Kennzahl DummyEingabe_VKI_VP. Die Kennzahl Umsatz_VP wird mit dem zunächst ermittelten Wert der Kennzahl Umsatz der aktuellen Periode überschrieben:
IF @MeasureName = 'DummyEingabe_VKI_VP'
BEGIN
-- Aktualisierung des Umsatz_VP der Folgeperiode
MERGE INTO dbo.T_WriteBackSQL_FACT_01_Plan AS tgt
USING
-- Ermittlung des Umsatz der aktuellen Periode (als Vorperiode der Folgeperiode)
( SELECT r.*
FROM T_WriteBackSQL_FACT_01_Plan r
INNER JOIN #T_FACT t
ON
CONVERT(VARCHAR(6),DATEADD(MONTH,1,CONVERT(DATE,r.[MonatID] + '01')),112)
= t.[MonatID] AND
r.[PeriodenansichtID] = t.[PeriodenansichtID] AND
r.[KumulationID] = t.[KumulationID] AND
r.[WertartID] = t.[WertartID] AND
r.[KundeID] = t.[KundeID] AND
r.[ProduktID] = t.[ProduktID] AND
r.[StoffgruppeID] = t.[StoffgruppeID] AND
r.[VertriebID] = t.[VertriebID]
) AS src
-- Aktualisierung des Umsatz_VP der Folgeperiode mit dem Umsatz der aktuellen Periode
ON
tgt.[MonatID] =
CONVERT(VACHAR(6),DATEADD(MONTH,1,CONVERT(DATE,src.[MonatID] + '01')),112) AND
tgt.[WertartID] = src.[WertartID] AND
tgt.[PeriodenansichtID] = src.[PeriodenansichtID] AND
tgt.[KumulationID] = src.[KumulationID] AND
tgt.[KundeID] = src.[KundeID] AND
tgt.[ProduktID] = src.[ProduktID] AND
tgt.[StoffgruppeID] = src.[StoffgruppeID] AND
tgt.[VertriebID] = src.[VertriebID]
WHEN MATCHED THEN
UPDATE
SET
[Umsatz_VP] = src.[Umsatz],
[Locked] = 1,
[TransactionID] = @TransactionID,
[Deleted] = CASE WHEN @MeasureValue IS NULL THEN 1 ELSE tgt.[Deleted] END,
[ZeroEntered] = CASE WHEN @MeasureValue = 0 THEN 1 ELSE tgt.[ZeroEntered] END,
[LastChangeTime] = getdate(),
[LastChangeUser] = @Username,
[LastChangeTransactionID] = @TransactionID,
[ChangeCount] = isnull(tgt.ChangeCount, 0) + 1
OPTION (MAXDOP 4);
END
Durch diese Implementierung ist bei Planeingabe des VKI eine Wertweitergabe auf die Kennzahl Umsatz möglich, welche in proportionaler Abhängigkeit zur Kennzahl Menge steht. Zudem wird sichergestellt, dass die Kennzahlen Umsatz der aktuellen Periode und Umsatz_VP der Folgeperiode stets den identischen Wert aufweisen.
Die Prozedur P_WriteBackSQL_FACT_01_xxx_PostProcess wird automatisch zum Abschluss jeder Planeingabe ausgeführt. Hierbei werden, wie in Kapitel 2 gezeigt, die Kennzahlen Zähler und Nenner aktualisiert. Der VKI wird anschließend als Quotient aus Zähler und Nenner im Cubescript berechnet. Dies führt zu einem gewichteten Durchschnitt des VKI auf aggregierter Ebene. Zudem ergeben sich Performancevorteile aufgrund der vereinfachten Berechnung des VKI zur Laufzeit.
