KI-generierte E-Mails können die interessantesten, automatisiert gewonnenen Erkenntnisse aus einer Datenanalyse in kompakter Form enthalten und kommentieren. Wir zeigen eine mögliche Anwendung mit dem DeltaMaster Publisher.
KI-generierte E-Mails und DeltaMaster Publisher
Sie werden sicherlich bemerkt haben, dass bei Bissantz & Company KI-gestützte Anwendungen auf breiter Front eingeführt und ausgebaut werden.
Zum Einstieg empfehle ich die kürzlich stattgefundenen Webinare, in denen einige Anwendungen zu sehen sind.
Zusätzlich können Sie ein Whitepaper Business Intelligence mit künstlicher Intelligenz anfordern oder sich gleich von unseren Experten beraten lassen.
Heute werde ich ein kommendes Feature der DeltaMaster-Version 6.7.0 vorstellen, die am 10.4.2026 erscheinen wird. Da sich die endgültige Bedienung in Details noch ändern kann, werde ich an dieser Stelle nur das prinzipielle Vorgehen erläutern.
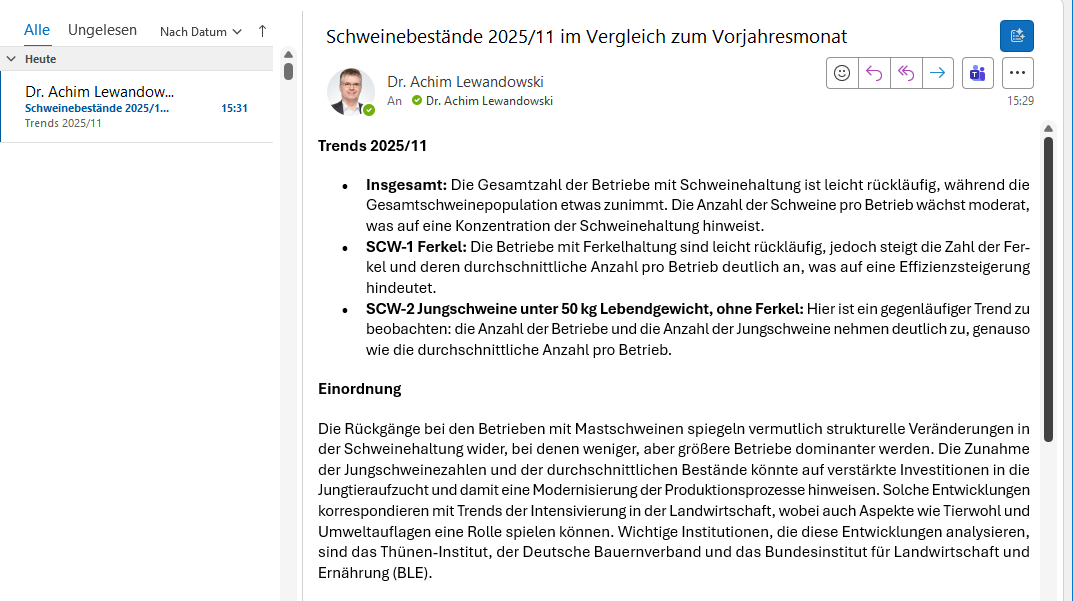
Post ist da: Trends bei den Schweinebeständen
Unter Einsatz des DeltaMaster Publishers, unserem Tool, mit dem wir Berichte automatisiert aktualisiert, in verschiedensten Formaten (z. B. PDF, Excel, PowerPoint, HTML, DeltaMaster-Sitzung) ausgeben und zielgruppenspezifisch über verschiedene Kanäle (Dateiablage, E-Mail, Druck, Repository usw.) verteilen, könnten Sie demnächst eine KI-generierte E-Mail – wie oben exemplarisch dargestellt – empfangen.
Bevor ich auf das eigentliche Thema – das Verschicken von KI-generierten E-Mails – eingehe, ein Wort zu den Daten.
Demo-Daten von GENESIS zur Schweinehaltung
In meinem Szenario nehme ich an, dass ich in einer bestimmten Branche tätig bin – beispielsweise als Agripreneur – und öffentlich verfügbare Daten nutzen möchte, um besser über Trends informiert zu sein.
Zu Demonstrationszwecken habe ich mir einen Datensatz der von mir geschätzten GENESIS-Datenbank des Statistischen Bundesamts ausgesucht: Betriebe mit Schweinehaltung: Deutschland, Stichmonat, Schweinekategorien, zu finden unter Code 41313-0001.
Immer in den Monaten Mai und November jedes Jahres veröffentlicht das Statistische Bundesamt Anzahlen von Betrieben, die eine bestimmte Kategorie von Schweinehaltung betreiben. Die Kategorien sind hierarchisch aufgebaut und der entstehende Hierarchiebaum hat unterschiedlich lange Äste:
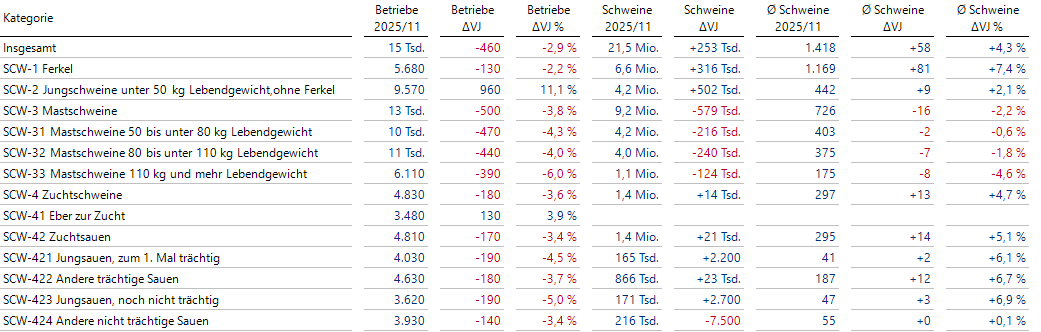
Grafische Tabelle als Datenmaterial für die KI-generierte E-Mail
Die Anzahl der gehaltenen Schweine ist additiv, aber möglicherweise ist die Hierarchie unvollständig, das heißt, die Anzahl in einem Knoten ergibt sich nicht zwingend als die Summe der Werte seiner Kinder.
Die Anzahl der Betriebe ist innerhalb des Hierarchiebaumes nicht additiv, da Betriebe verschiedene Kategorien von Schweinen gleichzeitig halten können.
Ich habe diese Elemente deshalb letztendlich als flache Liste modelliert, per Self-Service MDX Analytics. Nun kann ich mit benannten Mengen arbeiten, die sich gleich als nützlich erweisen werden.
Zusätzlich habe ich aus den zwei gegebenen Kennzahlen einen Quotientenwert der durchschnittlichen Anzahl Schweine pro Betrieb ermittelt, der nicht in den Daten enthalten war.
Übrigens bietet GENESIS Online eine Webservice-Schnittstelle an, sodass wir den Bezug von Daten und die Datenaufbereitung und -modellierung vollständig automatisieren könnten. Die Anzahl von Zugriffen ist begrenzt, um den entstehenden Datenverkehr unter Kontrolle zu halten.
Die Möglichkeiten der Schnittstelle werde ich in näherer Zukunft evaluieren. GENESIS Online stellt eine Webservices-Einführung als PDF zur Verfügung.
Analyse des Berichts in DeltaMaster
Ich habe mich auf die November-Monate der beiden Jahre 2024 und 2025 beschränkt.
Zunächst veranschauliche ich die Vorgehensweise bei der Analyse zu Fuß. Obiger Bericht mit den Vorjahresabweichungen zu 2024/11 dient nun im Monat 2025/11 als Grundlage.
Bei SCW-41 Eber zur Zucht lagen die Schweine-Anzahlen sowohl im Jahr 2025 als auch im Vorjahr 2024 nicht vor. Die Anzahl der Zuchteber war vorher (2023/11) mit ca. 15 Tsd. im Vergleich viel kleiner als die anderen angegebenen Bestände an Schweinen.
Es soll nun die Frage beantwortet werden, welche Entwicklungen auffällig sind.
Besserer Überblick mit Bissantz’Numbers
In DeltaMaster aktiviere ich deshalb zunächst Bissantz’Numbers, am besten mit spaltenweiser Skalierung, da sich Anzahl Betriebe und Anzahl Schweine um mehrere Größenordnungen unterscheiden:
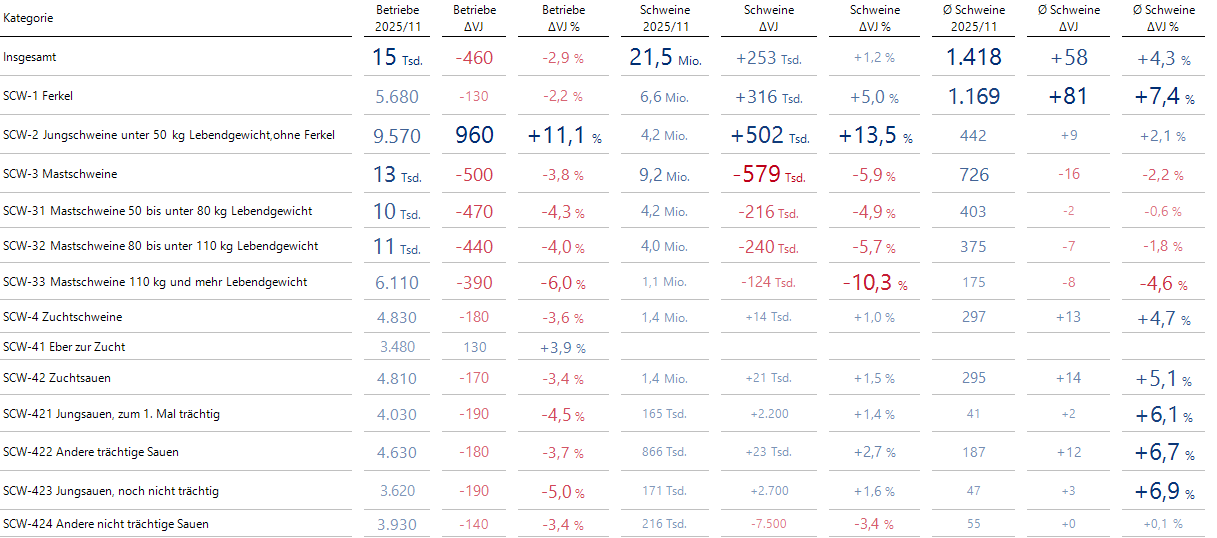
Bissantz’Numbers betonen auffällige Entwicklungen
Zum Überblick beschreibe ich zunächst die Gesamtentwicklung: Die Anzahl der Betriebe, die sich überhaupt mit Schweinehaltung beschäftigen, hat im Vergleich zum Vorjahr um 460 (2,9 %) abgenommen. Die Anzahl der Schweine hingegen hat mit +253 Tsd. leicht (+1,2 %) zugenommen.
Aus dieser Konstellation ergibt sich zwingend, dass die Anzahl der Schweine pro Betrieb zugenommen hat. Im konkreten Fall waren es +58 (+4,3%).
Dann gehe ich die einzelnen Kennzahlen durch und schaue auf große absolute oder relative Deltas, die herausstechen. Folgende Beobachtungen könnten unter anderem erwähnt werden:
- Mehr Betriebe (+11,1 %) haben SCW-2 Jungschweine unter 50 kg in ihr Portfolio aufgenommen
- Auch die Anzahl der Schweine insgesamt hat für SCW-2 Jungschweine unter 50 kg zugenommen.
- Die Anzahl der Schweine pro Betrieb hat für SCW-2 Jungschweine unter 50 kg leicht zugenommen
- Bei SCW-3 Mastschweinen hat es Rückgänge bei der Anzahl der Betriebe gegeben.
- Die Anzahl der Schweine hat bei SCW-3 Mastschweinen prozentual sogar noch stärker abgenommen, sodass die Anzahl der Schweine pro Betrieb ebenfalls sinkt.
- SCW-33 Mastschweine 110 kg und mehr ist mit -10,3 % relativ stark eingebrochen.
- Bei SCW-1 Ferkel ist die Anzahl der Betriebe zurückgegangen, aber die Anzahl der Schweine hat zugenommen.
- Im Sektor SCW-4 Zuchtschweine gab es eine Konzentration der Betriebe: Weniger Betriebe halten mehr Schweine.
Als generelles Fazit würde ich angeben, dass Betriebe mehr Engagement bei SCW-2 Jungschweinen unter 50 kg zeigen, dafür aber ihren Einsatz von SCW-3 Mastschweinen zurückgefahren haben. Bei SCW-1 Ferkel sinkt die Anzahl der Betriebe, aber die Anzahl der Schweine hat trotzdem zugenommen.
Die KI arbeitet nicht direkt mit der Ausgangstabelle!
Eine wichtige Tatsache müssen wir gleich festhalten: Wir lassen die KI nicht direkt auf die rohen Tabellendaten los.
Zwar kann ein LLM wie GPT-5.2 mit solchen Tabellen mit einfacher Kopfzeile und einfacher Kategoriespalte relativ gut direkt umgehen und tatsächlich habe ich in ca. 20 Durchläufen auch keine numerischen Fehler beobachtet, aber:
Bei längeren oder breiteren Tabellen oder bei mehreren verschachtelten Dimensionen auf der Zeilenachse oder verschachtelten Spaltenköpfen und anspruchsvolleren Aufgabenstellungen schleichen sich mit steigender Komplexität unweigerlich Fehler bei der Beantwortung von Fragen ein.
Wir setzen deshalb auf eine strikte Arbeitsteilung: In DeltaMaster berechnen wir auffällige Ergebnisse ohne Fehler und die KI in Form eines LLM bereitet die Ergebnisse textuell auf. Die KI kann dann aufgrund von Weltwissen oder weiteren zur Verfügung gestellten Kommentartexten eine Einordnung vornehmen.
Definition der auffälligen Ergebnisse
Natürlich gibt es verschiedene Möglichkeiten, Auffälligkeit zu definieren. Für dieses Beispiel habe ich mir folgende Kriterien überlegt:
- Für jede der 3 Kennzahlen soll die Entwicklung der Kategorie „Insgesamt“ immer zu sehen sein.
- Ich betrachte pro Kennzahl nur die absoluten und relativen Änderungen, nicht den Bestandswert.
- Für jede der zwei Größen pro Kennzahl berechne ich die Top-5-Kategorien der Beträge.
- Pro Kennzahl behalte ich den Schnitt der beiden Top-5-Mengen.
- In einer Zusammenfassung erwähne ich neben Insgesamt nur diejenigen Kategorien, die bei mindestens 2 Kennzahlen erwähnt wurden.
Für die Berechnung der jeweiligen Mengen definiere ich zunächst 6 Kennzahlen mit den jeweiligen Absolutbeträgen und bestimme dann jeweils die Top-5 der Kategorien (ohne Insgesamt). Bei der Anzahl der Betriebe sind bspw. zunächst diese beiden Tabellen relevant:
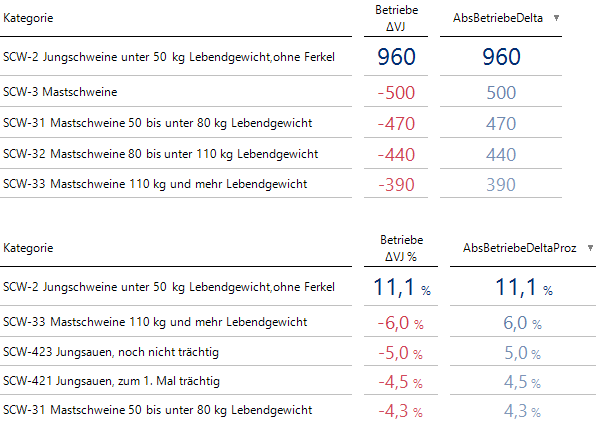
Auffällige Kategorien bei der Anzahl der Betriebe: absolut (oben) und relativ (unten)
Im Ranking habe ich jeweils die Top-5 nach dem Absolutwert der jeweiligen Abweichung berechnet und anschließend als benannte Menge abgespeichert. Unter Modellieren/Benannte Menge bearbeiten erstelle ich in einer neuen benannten Menge mit Intersect die Schnittmenge der beiden benannten Mengen (also der interessanten Kategorien) und füge mit Union noch das Insgesamt-Element am Anfang hinzu.
Die erste Tabelle, die als Grundlage für die KI-generierte E-Mail verwendet werden soll, lautet deshalb:

Auffällige Kategorien bei der Anzahl der Betriebe
Wir sehen nun – neben Insgesamt – nur die Kategorien, die sowohl zu den auffälligen absoluten als auch zu den auffälligen relativen Entwicklungen gehören – immer im relativen Vergleich mit den anderen Kategorien. Bei Bedarf könnte man noch Filter aktivieren, die eine bestimmte Mindestgröße an absoluten oder relativen Änderungen verlangen.
Auffällige Ergebnisse für die Anzahl der Schweine und Schweine pro Betrieb
Wir gehen für die restlichen Kennzahlen analog vor.
Bei der Anzahl der Schweine sind die folgenden Kategorien erwähnenswert; die Kategorie Insgesamt ist gesetzt:

Auffällige Kategorien bei der Anzahl der Schweine
Ebenso sind die folgenden Kategorien (neben Insgesamt) bei der Beurteilung der Entwicklung der Anzahl von Schweinen pro Betrieb erwähnenswert:
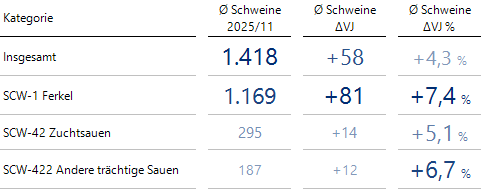
Auffällige Kategorien bei der Anzahl der Schweine pro Betrieb
Trends
Die letzten 3 Tabellen bilden die Grundlage für die in der KI-generierten E-Mail darzustellenden Tendenzen bei den einzelnen Kennzahlen.
Zusätzlich möchte ich eine Trends-Zusammenfassung erstellen. Dabei sollen nur Kategorien aufgeführt werden, die bei mindestens zwei Kennzahlen auftauchen.
Dies kann ich in MDX durch einen benutzerdefinierten Analysewert lösen, der über Konstruktionen wie count(intersect(Kategorie.currentmember,[namedset])) prüft, ob eine betrachtete Kategorie in einer benannten Menge enthalten ist. Die ursprüngliche Tabelle habe ich somit für die Trends auf die folgende eindampfen können:

Grundlage für die Beschreibung der Trends
Nur noch SCW-1 Ferkel und SCW-2 Jungschweine unter 50 kg sind relevant, da sie mindestens 2 interessante Kennzahlentwicklungen aufweisen.
KI-generierte E-Mails konfigurieren
Kommen wir nun zur Konfiguration des KI-Einsatzes.
Im Publisher kann ich demnächst (Release 6.7.0) festlegen, dass ein E-Mail-Inhalt KI-generiert sein soll. Ich wähle einen Job mit Berichtsformat message und Verteilungsart mail.
Die Adresse kann ich mit dem Parameter @IDA dynamisch verwenden und die zu übermittelnden Informationen an den Empfänger anpassen.
Im vorliegenden Fall gibt es nur einen Empfänger, aber man könnte sich vorstellen, dass jemand immer Informationen für Deutschland und zusätzlich sein eigenes Bundesland (in einem anderen Datensatz der GENESIS-Datenbank verfügbar) erhalten möchte.
Fängt der E-Mail-Text mit #Prompt an, wird der nachfolgende Text als Promptanweisung an das LLM interpretiert.
Hier muss ich nun hinterlegen, was ich von der Nachricht erwarte und wie der E-Mail-Text formatiert sein soll.
Die Inhalte meiner 4 relevanten Berichte – 3 für die individuellen Kennzahlberichte und 1 für die Trends – kann ich über die Report ID eines Berichtes ansprechen.
Da so ein Prompt etwas länger werden kann, zeige ich einmal ein paar typische Ausschnitte. Ich muss zum Beispiel die Aufgabe näher beschreiben:
## Aufgabe - Fasse die Entwicklungen aus den untenstehenden Angaben der Kennzahlen Anzahl von Betrieben mit Schweinehaltung, Anzahl Schweine und Anzahl der Schweine pro Betrieb (Ø Schweine) zusammen.
Hier gebe ich Anweisungen, dass zum Beispiel bei den Kennzahlberichten alle 3 verfügbaren Größen zu sehen sein sollen.
## Kennzahl-Abschnitte (mit Zahlen) - Gliedere nach Kennzahl (Betriebe mit Schweinehaltung, Anzahl Schweine und Schweine pro Betrieb) - Beginne je Kennzahl immer mit Insgesamt. - Beschreibe danach die genannten Kategorien. - Format je Bullet Point: Vollständiger Kategoriename: 1–2 Sätze mit absoluter Veränderung und dem aktuellen Stand, ergänzt um die relative Änderung.
Für die Trends erwarte ich, dass wieder Zeile für Zeile beschrieben wird, aber keine Zahlen erwähnt werden:
## Trends @D00 (ohne Zahlen, aber streng begrenzt) - Trends kommen zuerst im Text - Trends sind rein verbal, keine Zahlen/Prozente. - Trends enthalten immer zunächst Insgesamt und dann weitere Kategorien - Jede Trend-Erkenntnis als eigener Bullet Point in der Form: Vollständiger Kategoriename: 1–2 Sätze, qualitativ einordnen (z. B. „deutlich rückläufig“, „gegenläufig“, „treibend“).
Dann möchte ich, dass das LLM die Erkenntnisse mit seinem Weltwissen vergleicht und kommentiert:
## Einordnung (mit Quellen) - Nach Trends folgt unmittelbar die Einordnung. - Beziehe dich auf Weltwissen: mögliche Ursachen/Kontext zu den Erkenntnissen. - Wenn möglich: 1–3 konkrete Namen von Institutionen, die sich mit dem Thema intensiv beschäftigen.
Schließlich gebe ich die Form vor. Beispielsweise soll die Zusammenfassung „Trends“ in der E-Mail zuerst erscheinen, obwohl sie erst nach den Einzelanalysen der Kennzahlen abgeschlossen wurde:
## Form - Ausgabe vollständig in Markdown - Kein Betreff - Verwende keine Markdown-Überschriften (kein # oder ##) - Nutze fett gesetzte Abschnittstitel: Trends, Einordnung, Betriebe mit Schweinehaltung, Betriebe, Schweine pro Betrieb - Kategorienamen und Zahlenwerte immer fett schreiben - Prozentzahlen immer mit 1 Nachkommastelle, absolute Zahlen mit 0 Nachkommastellen. - Nenne Beträge > 1Mio. in Mio. mit jeweils 1 Nachkommastelle, Beispiel 56123432 als 56,1 Mio. - Einordnung folgt direkt auf Trends - Jede Erkenntnis als eigener Bullet Point - Kompakt und E-Mail-tauglich - Beende die E-Mail immer mit: Mit besten Grüßen Ihr ergebener Publisher
Einbindung der Berichte in die KI-generierte E-Mail
Der wichtigste Punkt im E-Mail-Text ist die Einbindung der Berichte mit den Auffälligkeiten über die Report-ID:
## Daten zu Anzahl von Betrieben mit Schweinehaltung @report9 ## Daten zu Anzahl Schweine @report10 ## Daten zu Anzahl der Schweine pro Betrieb (Ø Schweine) @report11 ## Daten zu Trends @report12 Erstelle nun die E-Mail gemäß diesen Vorgaben.
Die 9 in @report9 ist die Report-ID eines Berichts, die ich bei gedrückter Alt-Taste und Mouseover über dem Namen in der Berichtsliste sehe. Beim Aufruf des Jobs wird hier nun der Tabellen-Text im JSON-Format eingesetzt, bevor der Prompt an das LLM übergeben wird.
In unserem Beispiel soll ein menschlicher Empfänger die wichtigsten Erkenntnisse lesen, aber genauso gut ist es prinzipiell möglich, einen erzeugten Text als Beitrag zu einer Wissensbasis der Marktentwicklungen oder als Kommentar zu einem Bericht zu verwenden.
In einem weiteren Schritt könnte eine automatisierte, KI-gestützte Handlungsempfehlung generiert werden, die natürlich außer weiteren externen Entwicklungen (Preise, unmittelbare Konkurrenz) den Status Quo der adressierten Person kennen muss.
Wenn zum Beispiel der Empfänger mit Mastschweinen > 80 kg arbeitet, könnte man ihn über Entwicklungen, die ihn direkter betreffen, bevorzugt informieren.
Inhalt der KI-generierten E-Mail
Starte ich einmal den Publisher-Job, erhalte ich nach ca. 15 Sekunden die generierte E-Mail:

Der komplette Inhalt der KI-generierten E-Mail
Die erwähnten Zahlenwerte stimmen durchgehend mit den Tabellen überein, bloß hat das LLM bei den Trends auch SCW-31 und SCW-33 erwähnt. Um das LLM zu überzeugen, dies nicht zu tun, habe ich den Trends-Abschnitt verschärft:
## Trends @D00 (ohne Zahlen, aber streng begrenzt) - Trends kommen zuerst im Text - Trends sind rein verbal, keine Zahlen/Prozente. - Trends enthalten exakt die Kategorien wie in den Daten zu Trends: immer zunächst Insgesamt und dann die weiteren Kategorien wie in den Daten aufgeführt. - Jede Trend-Erkenntnis als eigener Bullet Point in der Form: Vollständiger Kategoriename: 1–2 Sätze, qualitativ einordnen (z. B. „deutlich rückläufig“, „gegenläufig“, „treibend“). - Wichtig: Keine Kategorien erwähnen, die nicht in den Daten zu Trends vorkommen.
Außerdem wurde in diesem Durchlauf die Anweisung ignoriert, Kategorienamen fett zu schreiben. Hier muss der Job einige Male ausgeführt werden, um etwaige Probleme zu erkennen und im Normalfall hilft es, die entsprechenden Passagen im Prompt ausführlicher zu beschreiben.
In meinem Fall wurden in den nächsten 10 Durchläufen die Trends nach meinen Vorgaben gestaltet, die Formatierungsangaben der Zahlen wurden befolgt. Das einzige offene kleinere Problem war der gewünschte Fettdruck der Kategorienamen, der nicht in jedem Durchlauf beachtet wurde.
Ich könnte auch noch bei Bedarf fehlende Werte wie bei SCW-41 Eber zur Zucht erwähnen.
Quelle der Daten
Die Daten stammen aus der Datenbank GENESIS-Online des Statistischen Bundesamtes.
Datenquelle: Statistisches Bundesamt (Destatis), GENESIS-Online, Abrufdatum am 25.2.2026; Datenlizenz by-2-0; eigene Berechnungen/eigene Darstellung.
Die Daten stammen aus der Position mit dem Code 41313-0001 mit der Beschreibung „Betriebe mit Schweinehaltung: Deutschland, Stichmonat, Schweinekategorien“.
Für Korrektheit der gezeigten Werte und Berechnungen können wir leider keine Gewähr übernehmen.
